Introduction
A large portion of this article is introductory material to get the reader up to speed. If you are already familiar with the material you can skip ahead to the Skip Lists section.
Having a sorted data structure is one of the most needed requirements in a non-trivial application. The main advantage is how fast searching this data structure can be; which one is easier searching through the phone (an example of sorted data) or through some bunch or papers?
If the data is fixed then you just sort once and everything is good, but the situation is different when new data is constantly inserted or some of the old data is deleted, hence, extra work needs to be done to maintain the sort order. In general, we are interested in three operations on only data structure (insertion, deletion, searching) and the goal is to make them as fast as possible without making the implementation too complicated.
The Linked List
The linked list is the simplest dynamic data structure. It is a group of elements linked together; to find an element you start at the head of the list and move forward until the item is found or you reach the end of the list.
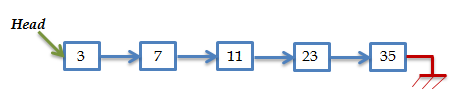
Similarly, to insert an item, you first find its position in the list and insert it there. For example, if we want to insert “19”. Starting at the head:
“19” > “3” ⇒ move forward
“19” > “7” ⇒ move forward
“19” > “11” ⇒ move forward
“19” < “23” ⇒ stop; insert “19” before “23”

The same idea applies for deletion; we must find the element first and join the elements before and after together. The next figure shows what would happen if we wanted to delete “11”.
It should be clear by now that the key operation here is searching. In the worst case, we have to go through all elements in the list (n) and on average we go through half the list (n/2). The complexity is O(n) for insertion, deletion and search.
The Binary Search Tree
O(n) is good but we want to do better and the idea of a binary tree was born. The idea is to keep the elements in a tree like structure and maintain the property “all elements to the left of a node are smaller while all elements to the right are bigger”
Finding an element is as simple as moving left or right depending on the node value. Also, insertion becomes easy we just need to find the right place. For example, to insert “19” starting at the head:
“19” < “23” ⇒ move to the left sub-tree
“19” > “7” ⇒ move to the right sub-tree
“19” > “11” ⇒ move to the right sub-tree
What about the cost? In a perfect world, each step we divide the elements to search in by half (we eliminate sub-tree each step). This maps to a complexity of O(logn). This seems pretty cool but consider this example, we want to insert “3”,”7”,”11”,”23”,”35” in that order, the data is already sorted we must be lucky :).
-To insert “3” the tree is empty so this becomes the head of the tree
-To insert “7” it is greater than “3” and so it goes into the right sub-tree
-To insert “11” it is greater than “3” and so it goes into the right sub-tree, also it is greater than “7” so it goes into it’s right sub-tree
If you continue this exercise you will end up with the following tree
Wait! What? We ended up with a linked list and we ended up with O(n) complexity. This is because we let the tree in one direction without keeping it balanced. One data structure that addresses this issue is an “AVL tree” which is a self-balancing binary search tree. It doesn’t let the tree get too unbalanced to keep the complexity at O(logn) but this comes at the price of the complexity of the balancing algorithm itself. AVL trees are very famous and I encourage you to read about them if you are not familiar with them already.
Today, I will discuss another alternative, we want the simplicity of the linked list (mental model and implantation details) and have the basic operations (insertion, deletion, search) cost O(logn). Let me introduce you to skip lists.
The Skip List
Imagine we have multi-level list. The 1st list contains all the elements. The 2nd list skips every other element in the 1st list. The 3rd list skips every other element in the 2nd list and so on. The next figure shows an example of a skip list.
We always start at the top most list and work our way down until we reach the element in the 1st list (contains all elements). For example, consider we want to find “7” in the example above.
Starting at the head (at top most list contains only “9”):
“7” < “9” ⇒ we moved too far, move down to the lower list
Now we are on the 2nd list (contains [“6”,”9” and “17”])
“7” > “6” ⇒ check to the right
“7” < “9” ⇒ we moved too far, move down to the lower list
Now we are on the 3nd list (contains all elements)
“7” > “6” ⇒ check to the right
“7” = “7” ⇒ the element is found
This is similar to the binary tree; at each step we cut the number of elements in half which gives us O(logn) for search. Insertion and deletion is a matter of finding the right position.
item Search(item) {
current = list.Header;
for (i = list.Level - 1; i >= 0; i--) {
while (x.Next[i] < item) {
current = current.Next[i];
}
}
current = current.Next[0];
if (item == current) return current;
else return null;
}
This is very good and it is very simple to understand and follow but how about the implementation. Can we make skip every other element from the previous list? Insuring this property required a lot of work and we are no different than AVL trees where each operation required balancing.
The good news is Skip lists don’t enforce strict balancing but follows a probabilistic balancing which makes the implementation much simpler than an AVL tree.
Let’s Talk Numbers
Up until now we have one must have rule (the 1st list contains all elements) and one nice to have rule (every list skips every other element from the lower list). Because the 1st list contains all elements; the probability of an element being in the 1st list is 100%.
The 2nd list contains approximately half the elements in the 1st. every element has a 50-50 chance of being promoted to the 2nd list. The 3rd list contains half the elements in the 2nd list (25% of all elements). Every element in the 2nd list has a 50-50 chance of being promoted.
The 4th list contains half the elements in the 3rd list and 12.5% of all elements with each element having a 50-50 chance of being chosen. It should be clear that an element not in the 2nd list cannot make it to the 3rd list and an element in a higher list must be in all lower lists. i.e. an element in the 4th list means it is in the 1st, 2nd and 3rd lists as well.
For example, let the maximum level in our skip list be MaxLevel, on insertion of a new element we want to determine the highest level this element will reach. Every element gets promoted to the next level with probability p (in our discussion p = ½)
Insertion and deletion is a search operation followed by updating some links.
public void Insert(T item)
{
Count++;
var current = _head;
var update = new Node<T>[MaxLevel];
for(int i = _topLevel - 1 ; i >= 0; i--)
{
while(Compare(current.Next[i], item) < 0)
{
current = current.Next[i];
}
update[i] = current;
}
var level = RandomLevel();
if(level > _topLevel)
{
for(int i = _topLevel; i < level; i++)
{
update[i] = _head;
}
_topLevel = level;
}
var node = new Node<T>{ Value = item, Next = new Node<T>[MaxLevel]};
for(int i = 0; i < level; i++)
{
node.Next[i] = update[i].Next[i];
update[i].Next[i] = node;
}
}
public bool Remove(T item)
{
var current = _head;
Node<T>[] update = new Node<T>[MaxLevel];
for(int i = _topLevel - 1 ; i >= 0; i--)
{
while(Compare(current.Next[i], item) < 0)
{
current = current.Next[i];
}
update[i] = current;
}
if(Compare(current, item) == 0)
{
for(int i = 0; i < _topLevel; i++)
{
if (update[i].Next[i] != current)
break;
update[i].Next[i] = current.Next[i];
}
while(_topLevel > 1 && _head.Next[_topLevel - 1] == null)
{
_topLevel--;
}
Count--;
return true;
}
return false;
}
Probabilistic Analysis
Some of the readers requested more analysis on Skip Lists. In this section I will try to address some of these questions without going into too much probability.
Maximum Height
In our earlier discussion we said that each element gets selected for the next level by probability (p = 1/2). For example, the probability that an element is on level 3 is the probability of the element being promoted to level 2 and being also promoted to level 3 i.e. ½ * ½ =1/4
To generalize, the probability of element being on the level (i) is . Hence, the probability the level (i) contains (n) elements is (summation of probability of element being on certain level (n) times). We can think of this probability as the probability of having any elements on level (i)
Probability of having elements at level (h) , let ,then
This means that the probability that there are elements above level () is -. In other words, the probability that the maximum height of skip list is O(logn) is
Space Requirements
There is some extra space required to store the forward pointer. We just proved that the probability that level (i) contains (n) elements is . To look at it another way, the expected number of elements in level (i) is . (elements are stored only once, we just add pointers in higher levels). For a skip list of height (h), the expected total number of elements
The expected space requirement of the Skip list is O(n).
Worst Case Search Time
At any point in the search, after performing the current comparison we could move to the next level with probability p = ½ or we could stay on the same level with probability p = ½
Let’s look at the problem backwards, we start at the target element and we want to reach the top most level. The steps are still the same we either continue on the same level or climb up one level.
Let C(j) be the expected cost of a search path that climbs j levels. The “1” is for the current step, we either remain on the current step or move to another level.
We already proved that skip list height is logn, C(h) = 2*logn + C(0), hence the worst case search cost is O(logn).
Implementation Issues
For a list of (N) elements the maximum level will be log(N). in the provided implementation I capped MaxLevel at 32 which is appropriate for up to 232 elements. Also, the elements in the list have to be comparable to each other. This can be solved by using a delegate that handle the comparison between the list element and it is up to the user of the data structure to define the comparison logic.
Conclusion
Skip lists are fascinating and here is the link to the original publication on skip lists for the interested reader.

