Introduction
Wouldn't it be nice if you could just copy and paste any code snippet you like into a CodeProject edit box without worries, and get your PRE tags for free, including the required language code? And get your < and > signs properly HTML-encoded, and while we're at it, also get your tabs reduced so the indentation is minimal? And, of course, get a literal paste when the clipboard holds regular text rather than code.
This article presents a way to identify the main programming language, if any, in a text snippet. It could be used in all CodeProject editor boxes, whether editing an article, a tip & trick, a quick answer question/answer, or a forum message. The article also provides a test bench so we can experience the ease of use, and judge the quality of language recognition.
Recognizing Programming Languages
Programmers don't have a difficult time telling a C# method apart from a VB.NET method or from a chapter of plain text; even a smaller code snippet is often sufficient to tell what language it is or is not. Compilers can easily parse source code in the language they support, and judge how well the source adheres to the required syntax, provided they are offered a compilation unit, i.e., an entire file, with proper include/using/Imports statements and everything, and without too many errors. Our goal is somewhat different though: we want to recognize snippets, not files.
Here are some of the issues that could arise, especially with buggy code that we encounter daily:
include/using/Imports may be missing (very likely);- declarations may be missing (very likely);
- parentheses, curly brackets, whatever should come in pairs, might not be matched properly;
- major syntax errors might be present;
- comments or string literals may contain code in a different language, e.g., a SQL command as a C# string literal; note that comment syntax is different in different languages, and the language is yet unknown;
- texts about programming could resemble a code snippet; in fact, my first attempts claimed most of the snippets I used for testing looked like VB!
As a result of a little research I did on this topic, I decided I would not go for one or several full parsers; instead, I would read the input once and tokenize it slightly, perform some statistical analysis, and use several criteria to determine the match or mismatch between the content of a snippet and the rules of each of a set of programming languages; each criterion is awarded some score, and gets normalized to be proportional to the number of lines in the snippet. Then, all partial scores are summed to get the final score for that language. These are the criteria I have chosen:
- Overall statistics on some special characters: A C/C++/Java/C# snippet is bound to contain some semi-colons and curly brackets, but so would a PHP or a CSS snippet; on the other hand, a VB.NET snippet wouldn't have many of those characters. I've decided to use the ratio of lines holding such special characters to the total number of lines. A "many" criterion would award positive points if a certain threshold gets reached, and negative when it is not; a "few" criterion would award positive points if another threshold is not reached, and negative points when it is. As the number of such rules varies for each language, their sum needs to get normalized too.
- Keywords: Most programming languages have a set of keywords; the set can be quite large, e.g., with the addition of LINQ in C#, a lot of SQL-like keywords got added; the problem here is a lot of keywords exist in many languages (e.g.,
for, if, else, while, ...); and the keywords could be case-sensitive (most languages) or case-insensitive (e.g., VB). The search for keywords starts at the left hand side of each line, and continues as long as the characters are members of a limited set (letters, digits, and a few specials that may arise in keywords in some languages, such as _ - $ #). As soon as some other character is encountered (such as parenthesis, equal sign, ...), the scan is suspended for that line. All identifiers up to that point typically should be keywords, except for the last one, which could be the name of a variable or method. Each such identifier that matches a keyword is awarded some positive points, which makes this score proportional to the size of the snippet. Example: in private int count=a*b;, we would discover three identifiers and expect the first two to be keywords. By the way, some languages, in particular VB.NET, have a different ordering, as in Dim count As Integer = 4, so we have to allow for that too. - Initial keywords: Some languages are more or less line-oriented, i.e., programmers usually start a new statement using a new line; such languages tend to have one or even two keywords to start a statement. So the leftmost words of every line are checked against the keyword list, and negative points get awarded for each mismatch. This criterion is disabled for languages that don't really know about lines, such as HTML, or about keywords, such as XML; on the other hand, it proves very useful at telling regular C-like or VB-like code apart from plain text.
- Popular words ("hotspots"): While not exactly a keyword, popular words are likely to pop up in code snippets for particular languages, e.g.,
varchar in a SQL snippet. These words are searched in the entire text, and awarded some points.
Once all the languages have been scored, the highest score determines the result; and the distance between the topmost two scores is converted into a trust value (0=low trust, 99=high trust). If the highest score is too low, or the trust is too low, a recognition failure is signaled by returning null, which means "consider it text, not code"; otherwise, the best matching language is returned.
Supported Languages
Code
| Language
| Comments
|
cs
| C/C#/C++/C++-CLI/Java/JavaScript
| syntax is similar
|
vb
| VB/VB.NET/VBScript
| syntax is similar
|
xml
| XML/HTML/ASP.NET
| syntax is similar
|
sql
| SQL
| All keywords in T-SQL
|
midl
| MIDL
|
|
php
| PHP
| All keywords in PHP4 + PHP5
|
css
| CSS
| A few keywords only (no coloring on CP)
|
msil
| .NET IL
|
|
asm
| x86 assembly
| CP list (which is not complete)
|
Some Limitations
Some code snippets can not be identified to the exact language; e.g., the similarity between C, C++, Java, and C# is such that lots of code snippets would look identical in some or all of those languages. That is why we use some "language groups", which implies the keyword lists of those languages should be merged for syntax coloring; that is no big deal as those languages have very similar keyword sets anyway, so the worst that could happen is some identifier getting colored although not really a keyword in the actual language (e.g., int public = 4; in a C snippet).
The selected criteria seem to be sufficient for identifying the language or language group for most practical snippets. However, as we are using tokens and statistics rather than full parser trees, there may be ways to occasionally get a skewed result; to name a few:
- multi-line comments could screw up things considerably; an extreme example is this C# snippet that will be identified as a VB snippet:
int multiply(int a, int b) {
/*
If Me.InvokeRequired Then
Me.Invoke(logHandler, New Object() {threadID, s})
Else
listBox.Add("multiply")
End If
*/
return a*b;
}
Atypical code formatting could skew typical ratios and make recognition more difficult; here is a modest example that might be identified as VB as it has some C#/VB keywords but may lack a sufficient semi-colon ratio:
[System.FlagsAttribute()]
public enum DiffSectionType : byte
{
Copy = 0
,
Delete = 1
,
Insert = 2
,
Replace = 3
}
Another way to cause confusion is by using identifier names that are keywords in another language; when all table names and field names in a SQL snippet would correspond to assembly instructions, the outcome could well be assembly!
In the rare situation where code in one language gets recognized as code in some other language, the worst that can happen is that the syntax coloring will not be adequate, as it would be based on the wrong list of keywords. However, when that happens, the author can always edit the language code in the opening PRE tag to fix things. Remember, the logic presented here should be applied only while pasting; once pasted, the text can still be edited, e.g., HTML tags could be added to apply bold or italics to some parts of the pasted code.
In some cases, snippets have to be handled as text, even when they look like code, or vice versa. So, it is probably wise to provide a three-way choice (auto, code, text) to enforce a specific behavior; obviously, I would recommend "auto" as the default. "text" could be used to copy-paste an existing code block, with PRE tags, and possibly bold and italics tags, already present. And, "code" could be used for anything that does not get recognized as code, but deserves the background color and the non-proportional font that come with PRE tags.
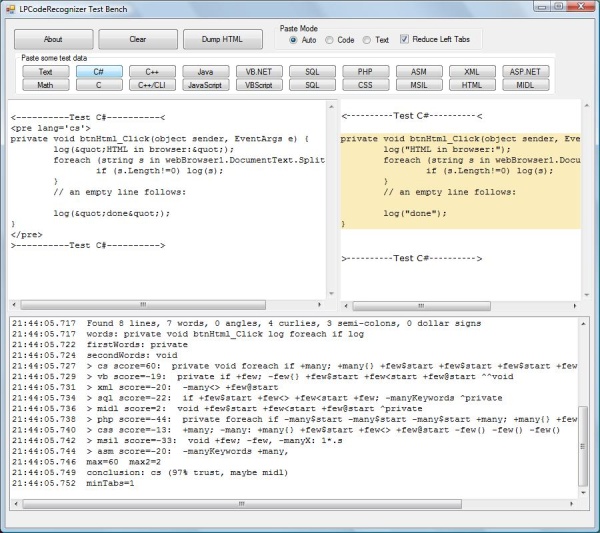
The Test Bench
The environment used is the Microsoft .NET Framework (version 2.0 or above) and the C# programming language. The test bench consists of a Form with:
- A row of
Buttons at the top; most of them mimic a paste action of some built-in code snippets, which I used during development and testing. - A
TextBox in the middle left; this is where you can type text, as well as paste snippets from the Clipboard. The typing is handled directly by the TextBox; "CTRL/V" is the one exception as it gets intercepted and passes the clipboard text to the LPCodeRecognizer class, and either simply pastes (when null gets returned, indicating no recognition), or adapts the text like this:
- adds PRE tags with the proper language attribute;
- optionally reduces the number of tabs to the left of the lines;
- HTML-encodes special characters such as < > &
- A
WebBrowser in the middle right; this is where the content of the TextBox is shown; it acts like a preview window, as it gets updated once a second as long as the TextBox content is being changed. - A
ListBox at the bottom; here, all log messages get displayed, so we can see how a snippet scores for each of the supported programming languages.
Note: the major controls can easily be resized as they are anchored to a couple of SplitContainers.
The Code
The major parts of the code are:
- Language classes: each of the
LanguageXxx classes that inherit from the base class Language holds the characteristics of a single programming language or a group of languages with similar syntax; a static List AllLanguages keeps track of all instances, and a public CreateAllLanguages() method creates and initializes those instances. From a user's perspective, and assuming all required languages have been provided, all that is relevant is the Name property which returns a string with the language name, such as "cs" for C#. - Class
LPCodeRecognizer: a static class with one important method:
// Gets the Language used in some text.
// (input) string text: the text or code snippet,
// with line breaks (any of \r, \n, \r\n), not HTML-encoded.
// (input) List languages: the language descriptions.
// (output) int trust: a number in the range [0,100]
// indicating how trustworthy the result is
// (return) Language: the Language describing the main programming language,
// or null when unknown/undecided
public static Language Recognize(string text, List<language> languages,
out int trust);
Most of the code is simple character and string manipulation; Regular Expressions are not used as I needed a lot of state, and wouldn't know how to handle that efficiently using the Regex class.
An Untabber.ReduceLeftTabs() method is optionally called before text gets pasted into the TextBox. It checks the text line by line, and determines how many tabs could be removed at the left hand side, then removes them. It ignores empty lines, and does not remove any spaces, as it does not know how many spaces correspond to a tab in the original source. The net result is typical code snippets get moved as far to the left as possible, reducing the overall width when pasted inside PRE tags. The test bench has a checkbox to optionally disable this feature.An HtmlConverter.ToHtmlDocument() method converts the TextBox content to an HTML document for display in the WebBrowser and optional dumping with the "Dump HTML" button. The converter mimics to some extent what a CodeProject editor window does; most importantly, it turns newline characters into break tags. It does not filter unacceptable words or HTML tags, nor does it deal with smileys or hyperlinks. Its only purpose is to give a simple preview in the WebBrowser.
Conclusion
A few simple rules suffice to give an extremely good text/code decision and a good estimate as to what the main programming language is in a code snippet. Applying LPCodeRecognizer to the paste action in a message editor can yield fully automated code pasting: adding PRE tags added, recognizing the language, HTML encoding, etc., are all automated. And, whenever the author isn't satisfied, he can still edit the text or code afterwards.
Let us hope something like this gets built into all the CodeProject editors (starting with the forum editor), and missing PRE tags will soon become a thing of the past!
History
- Version 1.0 (11-Dec-2009): Original version.
- Version 2.0 (05-Jan-2010): Some languages grouped together; improved criteria; more samples; better results.
- Version 2.1 (07-Jan-2010): Bug fix: single-line snippets must always be considered text.
- Version 2.2 (22-Feb-2010): Support for C# 3.0; relevant lines versus real lines; counting semi-colons + comma's.

