Prolusion
Most of the software systems now have to support parallelism/concurrency, for speed, throughput, efficiency and robustness. For the same, a running process has to have multiple threads - some are spawned on demand, few are waiting for some message to do work, some are just waiting for other threads/processes (or other kernel objects), and some are just "on bench", participating in thread pool party for the process.
With advancements in multiprocessor and multicore technologies, the software programmer's work challenge has grown manifold. They need to design systems to efficiently support multithreaded environment, and their software must be able to handle latest multiprocessing advancements.
While there are many libraries available for concurrency/parallelism in multiple development environments, I would only cover Visual C ++ Concurrency Runtime. Conceptually, concurrency and parallelism are two different terms, in this article I would use them interchangeably. I assume the reader has fair knowledge about:
The programs given here will only compile in Visual C++ 2010 compiler.
Start-up program
Let's straightaway move to first parallel C++ program that uses Concurrency Runtime (from now on, I would use CR). The following code calculates the sum of all numbers in range 1 to 100,000:
int nSum = 0;
for(int nNumber=1;nNumber<=100000;++nNumber)
nSum += nNumber;
The parallel form of this code can be:
int nSum=0;
parallel_for(1, 100001, [&](int n)
{
nSum += n;
} );
Few points about this code:
parallel_for is not language construct or keyword, it is a function. - It is defined in
Concurrency namespace.
- The header file for parallel algorithms is
<ppl.h>
- This function takes three arguments:
- The index value to start from
- The index value plus one till it should run the parallel loop.
- The function argument, that can be function-pointer, class object having () operator, or a lambda expression.
- I have used lambda for the function which is capturing all local variables by reference.
- The lambda (within braces), is adding the number
- Note the last parenthesis after closing-brace, which is actually ending the function call!
The complete code would be:
#include <iostream>
#include <ppl.h>
int main()
{
using namespace Concurrency;
int nSum=0;
parallel_for(1, 100001, [&](int n)
{
nSum += n;
});
std::wcout << "Sum: " << nSum ;
}
What about the Library and DLL ?
Well, most of the CR code is in templates and gets compiled whenever template class/function is instantiated. Rest of the code is in MSVCR100.DLL, which is standard VC++ Runtime DLL for VC10; thus you need not to link with any library to use CR.
Operating System Requirements
The minimum operating system required for Concurrency Runtime is Windows XP SP3. It will run on both 32-bit and 64-bit versions of Windows XP SP3, Windows Vista SP2, Windows 7, Windows Server 2003 SP2 and Windows 2008 SP2, and higher versions, respectibely. On Windows 7 and Windows Server 2008 R2 version CR would use the latest advancements for scheduling. It would be discussed in this article.
For distribution of Visual C++ 2010 runtime, you may download redistributable (32-bit/64-bit) from Microsoft Download Center and distribute to your clients.
Does parallel_for spawns threads?
Simple answer would be Yes. But in general, it doesn't create threads by itself, but utilizes the feature of CR for parallelizing the task. There is CR Scheduler involved for the creation and management of threads. We will look up into Runtime Scheduler later. For now, all I can say is: parallel algorithms, tasks, containers, agents etc would finish the task concurrently - which may be needing only one thread, or the number of threads equaling the logical processor count, or even more than logical processor count. The decision is by the scheduler and by the concurrent routine you are calling.
In my Quad Core CPU, having 4 logical processors, before the code enters into parallel_for function, I see only 1 thread for the process. As soon as code enters parallel_for, I see the number of threads raised to seven! But it utilizes only 4 threads for the current task, as we can verify using GetCurrentThreadId function. The other threads created by CR is for scheduling purposes. As you would see more of CR features later, you would not complain about extra threads.
Well, the sum may be calculated incorrectly!
Absolutely! Since, more than one threads are modifying the same nSum variable, the accumulation is expected to be wrong. (if you aren't sure about sum being captures...). For example, if I calculate sum between 1 to 100, the correct sum would be 5050, but the following code produces different results on each run:
parallel_for(1, 101, [&](int n)
{
nSum += n;
});
The simple solution is to use InterlockedExchangeAdd:
LONG nSum=0; parallel_for(1, 101, [&](int n)
{
InterlockedExchangeAdd(&nSum, n);
});
Obviously, it defeats the whole purpose of putting the accumulation in concurrent execution. Well, CR provides efficient solution for this, but I will discuss it later.
With this Start-up Program I briefly elaborated CR. Let me discuss the Concurrency Runtime in more structured manner.
The Concurrency Runtime
Concurrency Runtime classifies following as its core components:
- Parallel Patterns Library
- Asynchronous Agents Library
- Task Scheduler
- Resource Manager
The following are concepts in Concurrency Runtime:
- Synchronization Data Structures
- Exception Handling in CR
- Cancellation in PPL (Parallel Patterns Library)
Do not get confused over the terms, I will explicate them!
The following diagram depicts how Runtime and its different components fits-in between Operating System and the Applications:
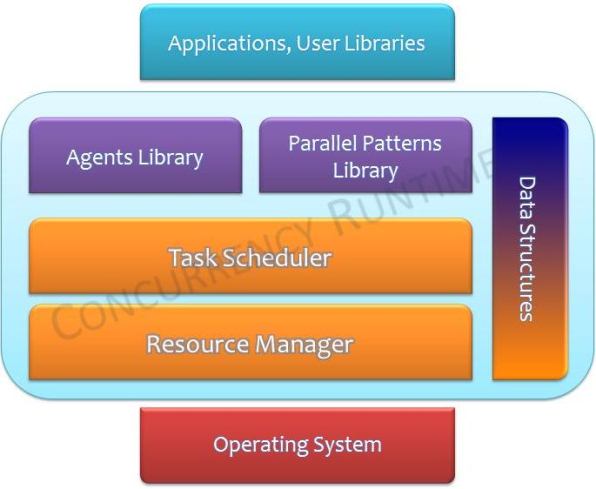
The Upper Layer in is in purple, which includes important and mostly used programming elements in Concurrency Runtime - The Agents Library and the Parallel Patterns Library, both are detailed here in this article. The orange components can be classified as Lower Layer elements of the Runtime. Only Task Scheduler is explained in this article. The purple-to-orange shaded component forms Synchronization Data Structures in Concurrency Runtime, and as you can see it plays vital role in both upper and lower layers of CR. Synchronization primitives are also elaborated in this article.
The flow of this article is as follows:
- Parallel Patterns Library
- Asynchronous Agents Library
- Synchronization Data Structures
- Exceptions in Concurrency Runtime
- Cancellation in PPL
- Task Scheduler
Parallel Patterns Library
The parallel_for function I discussed above falls in this category. The PPL has following classifications:
- Parallel Algorithms:
parallel_for parallel_for_each parallel_invoke
- Parallel Containers and Objects:
concurrent_vector Class concurrent_queue Class combinable Class
- Task Parallelism:
Parallel Algorithms
These three algorithms perform the given work in parallel, and wait for all parallelly executing tasks to finish. It is important to note that CR may schedule any task in any sequence, and thus, there is no guarantee which task (or part of it), would execute before or after other task. Also, one or more tasks may be executing in the same call-stack, same thread (i.e. 2 or more tasks in same thread, which may or may not be caller's call-stack/thread) or may execute inline.
Each algorithm may take function-pointer, object or a lambda expression (termed as 'function' in this article). The return/arguments type depend on algorithm and how they are called, as explained below.
parallel_for very similar to for construct. It executes the specified 'function' in parallel. It is not absolute replacement for for-loop. The simplified syntax of this function is:
void parallel_for(IndexType first, IndexType last, Function func);
void parallel_for(IndexType first, IndexType last, IndexType step, Function func);
Since this is a template function (not shown in syntax above), the IndexType can be any integral datatype. The first version of parallel_for would start from first, increment by 1, and loop till last - 1, calling the specified function at each iteration, parallelly. The current index would be passed to specified function as an argument.
The second overload behaves in similar fashion, taking on extra argument: step, the value by which each iteration should be incremented. This must be non-zero positive, otherwise CR would throw invalid_argument exception.
The degree of parallelism is determined by the runtime.
The following example counts the number of prime numbers between given range. For now, I am using InterlockedIncrement API; the combinable class provides better solution, which I will discuss later.
LONG nPrimeCount=0;
parallel_for(1, 50001, [&](int n)
{
bool bIsPrime = true;
for(int i = 2; i <= (int)sqrt((float)n); i++)
{
if(n % i == 0)
{
bIsPrime = false;
break;
}
}
if(bIsPrime)
{
InterlockedIncrement(&nPrimeCount);
}
});
wcout << "Total prime numbers: " << nPrimeCount << endl;
Let's ignore 1 and 2, and write more efficient routine to count this, passing 2 as step-value:
LONG nPrimeCount=0;
parallel_for(3, 50001, 2, [&](int n) {
bool bIsPrime = true;
for(int i = 3; i = (int)sqrt((float)n); i+=2) {...}
...
}
-
parallel_for_each Algorithm
This function is semantically equivalent, and syntactically same, to the for_each STL's function. It iterates through the collection in parallel, and like parallel_for function, the order of execution is unspecified. This algorithm, by itself, is not thread safe. That is, any change to the collection is not thread safe, only reading the function argument is safe.
Simplified syntax:
parallel_for_each(Iterator first, Iterator last, Function func);
The function must take the argument of the container's underlying type. For example if integer vector is iterated over, the argument type would be int. For the caller, this function has only one signature, but internally it has two versions: one for random access iterators (like vector, array or native-array) and one for forward iterators. It performs well with random access iterators.
(With the help of iterator traits, it finds which overload to call, at compile time).
The following code counts number of even numbers and odd numbers from an array:
const int ArraySize = 1000;
int Array[ArraySize];
std::generate(Array, Array+ArraySize, rand);
long nEvenCount = 0 , nOddCount = 0;
parallel_for_each(Array, Array+ArraySize, [&nEvenCount, &nOddCount](int nNumber)
{
if (nNumber%2 == 0)
InterlockedIncrement(&nEvenCount);
else
InterlockedIncrement(&nOddCount);
} );
As you can see, it is mostly same as parallel_for. The only difference is that the argument to function (lambda) is coming from the container (the integer array). Reiterating that the supplied function may be called in any sequence, thus the received nNumber may not be in same sequence as in original container. But all items (1000 array elements in this case), will be iterated by this parallel routine.
We can also call this routine with STL's vector. I am ignoring the vector initialization here (assume there are elements in it):
vector<int> IntVector;
nEvenCount = 0 , nOddCount = 0;
parallel_for_each(IntVector.begin(), IntVector.end(),
[&nEvenCount, &nOddCount](int n) {... });
Similarly, non random access container may also be used:
list<int> IntList;
parallel_for_each(IntList.begin(), IntList.end(), [&](int n) {... });
map<int, double> IntDoubleMap;
parallel_for_each(IntDoubleMap.begin(), IntDoubleMap.end(),
[&](const std::pair<int,double>& element)
{
It is important to note that, for parallel_for_each, random access container works more efficiently than non-random access containers.
- parallel_invoke Algorithm
This function would execute set of tasks in parallel. I will discuss later what task is, in CR realm. In simple terms a task is a function, function object or a lambda. parallel_invoke would call the supplied functions in parallel, and would wait until all of gives functions (tasks) are finished. This function is overload to take 2 to 10 functions as its tasks. Like other parallel algorithms, there is no guarantee in what sequence, set of functions would be called. Neither it guarantees how many threads would be put to work for completing the given tasks.
Simplified signature (for 2 function overload):
void parallel_invoke(Function1 _Func1, Function2 _Func2);
Using parallel_invoke is similar to creating set of threads and calling WaitForMultipleObjects on them, but it simplifies the task, as you need not to care about thread creation, termination etc.
Following example calls two functions parallelly, which computes the sum of evens and odds in the given range.
void AccumulateEvens()
{
long nSum=0;
for (int n = 2; n<50000; n+=2)
{
nSum += n;
}
wcout << "Sum of evens:" << nSum << std::endl;
}
void AccumulateOdds()
{
long nSum=0;
for (int n = 1; n<50000; n+=2)
{
nSum += n;
}
wcout << "Sum of odds:" << nSum << std::endl;
}
int main()
{
parallel_invoke(&AccumulateEvens, &AccumulateOdds);
return 0;
}
In example above, I have passed addresses to functions. The same can be done more elegantly with lambdas:
parallel_invoke([]
{
long nSum=0;
for (int n = 2; n<50000; n+=2)
{
nSum += n;
}
wcout << "Sum of evens:" << nSum << std::endl;
},
[]{
long nSum=0;
for (int n = 1; n<50000; n+=2)
{
nSum += n;
}
wcout << "Sum of odds:" << nSum << std::endl;
});
The choice of lambda and/or function-pointer/class-object depends on programmer, programming style and most importantly, on the task(s) being parallely performed. Of course, you can use both if them:
parallel_invoke([]
{
long nSum=0;
for (int n = 2; n<50000; n+=2)
{
nSum += n;
}
wcout << "Sum of evens:" << nSum << std::endl; }
,
&AccumulateOdds );
As mentioned before, parallel_invoke takes 2 to 10 parameters as its tasks - any of the given task may be function-pointer, lambda or a function-object. Whilst I would give more examples later, when I would cover more topics on CR; let me draw one more example for sake of examples, to impart more clarity on subject.
Let's calculate factorial of few numbers in parallel, using this function:
long Factorial(int nFactOf)
{
long nFact = 1;
for(int n=1; n <= nFactOf; ++n)
nFact *= n;
return nFact;
}
When you call parallel_invoke:
parallel_invoke(&Factorial, &Factorial);
You would be bombarded by compiler errors. Why? Well, parallel_invoke requires tasks to have void as argument and void as return type. Though return type can be non-void (as against documentation), but the arguments must be zero! We need to (can) use lambdas:
long f1, f2, f3;
parallel_invoke(
[&f1]{ f1=Factorial(12); },
[&f2]{ f2=Factorial(18); },
[&f3]{ f3=Factorial(24); }
);
Note that the lambda is of type void(void), and is capturing required variables by reference. Please read about lambdas...
Parallel Containers and Objects
The concurrency runtime provides concurrent container classes, for vector and queue, named concurrent_vector and concurrent_queue , respectively. Another class in parallel classes arena is combinable.
The concurrent container classes provides thread safe access and modifications to its elements, except few operations.
The concurrent_vector class is similar to std::vector class. It allows random access to its elements, but unlike vector, the elements are not stored in contagious memory (like array, vector). The access to elements along with insertions (push_back), is however, thread-safe. Iterator access (normal, const, reverse, reverse- const) is also thread-safe.
Since elements are not stored contagiously, you cannot use pointer arithmetic to directly access another element from some element (i.e. (&v[2] + 4) would be invalid).
As acknowledged by Microsoft (in concurrent_vector.h header), this class is based on original implementation by Intel for TBB's concurrent_vector.
For the examples, I could have used standard thread creation functions; but I prefer to use PPL's construct to illustrate concurrent_vector:
concurrent_vector<int> IntCV;
parallel_invoke([&IntCV] {
for(int n=0; n<10000; ++n)
IntCV.push_back(n);
},
[&IntCV] {
for(int n=0; n<1000;n++)
IntCV.push_back(n*2);
wcout << "Vector size: " << IntCV.size() << endl;
});
Here, two threads would be in action, both of them would insert few numbers into concurrent_vector. Method push_back is thread-safe, thus no synchronization primitive is required for the vector modification. Also, size method is also thread- safe.
At this point, if you couldn't understand any part from above' code, I would urge you to read on STL's vector, C++ lambdas and/or revisit parallel_invoke!
Yes, you got it right. It is concurrent version of STL' queue class. Like concurrent_vector, important operations of concurrent_queue are thread- safe, except few operations. Important operations include enqueue (insert) and dequeue (pop) and the empty method. For inserting elements, we use push method. For dequeue operation, we use try_pop method.
It is important to note that concurrent_queue does not provide concurrency-safe iterator support!
(Aug-09 : Allow me some time to put example for concurrent_queue, though it would be almost same as concurrent_vector. For both of these concurrent classes, I would also list out methods that are concurrency-safe or not, and their comparison with equivalent STL' containers. Till then enjoy reading the new stuff below!)
TLS, or thread local storage, would be conceptually the nearest competitor of this class. The combinable class facilitates each running task or thread to have its own local copy for modification. When all tasks are finished, those thread-specific local copies can later be combined.
For example, in parallel_for example above, we calculated sum of all numbers in 1 to 100 range - for thread safety we need to use InterlockedExchangeAdd. But we know that all threads would be contending for the same variable to update (add) - thus defeating the positive purpose of parallelism. With combinable object, we let each thread have its own copy of variable to update. Let's see this in action:
combinable<int> Count;
int nSum=0;
parallel_for(1, 101, [&](int n)
{
int & ref_local = Count.local();
ref_local += n;
});
nSum = Count.combine(AddThem);
combinable is template class, we instantiated it for int. - The method,
combinable::local returns reference to local variable for this thread. For simplifying the example I stored it in int& variable
- The local reference variable is then updated to add current variable.
- That's it!
There would be no contention for the reference-variable, as each thread would get its own copy. The runtime does it for you. Finally we call combinable::combine method to combine the parts. combine method iterates through all thread specific variables and calls the specified function. It then returns the final result. I have used user-defined function, AddThem, which is this simple:
int AddThem(int n1, int n2)
{
return n1 + n2;
}
The combine requires any function, functor or lambda having this signature: T f(T, T); where T is the template argument type. For sure the arguments, can be const. Thus, the combine call can also be:
nSum = Count.combine([](int n1,int n2) { return n1+n2;} );
And this also:
plus<int> add_them;
nSum = Count.combine(add_them);
Like before, to gather more positive audience responses, I simplified it with declaring a local variable of type plus class, and then passed it to combine method! For those who don't know, plus is an STL class, which is a binary_function having () operator overloaded, which just calls operator + on them. Thus, we can also use plus directly, instead of creating object with a variable. Following also illustrates how other operations can be easily performed to combine (though, not all make sense):
combinable<int> Sum, Product, Division, Minus;
parallel_for(1, 11, [&](int n))
{
Sum.local() += n;
Product.local() *= n;
Division.local() /= n;
Minus.local() -= n;
});
wcout << "\nSum: " << Sum.combine(plus<int>()) ;
wcout << "\nProduct: " << Product.combine(multiplies<int>());
wcout<< "\nDivision (?): " << Division.combine(divides<int>());
wcout<< "\nMinus result: " << Minus.combine(minus<int>());
I have directly used combinable::local, to modify the thread-local variable. The I have used different classes to produce the final result.
Now... something goes weird, and interesting also. It's not into CR's parlance, but I discovered it, thus I must share it!
The result of multiplication and division would be zero. Don't ask why. Here is quick, non-efficient solution:
int & prod = Product.local();
if(prod == 0)
prod = 1;
else
prod *= n;
Similarly for division operation. Because, when CR allocates a thread specific variable for first time, it calls its default constructor (or the one provided in combinable's constructor). Now, the compiler' provide default constructor of int sets it to zero!
The code change made would not be optimal solution. We need to pass a constructor, and one approach is:
combinable<int> Product( []{return 1;});
When CR need to allocate new thread-local variable, it would call this so called constructor, which is returning 1. Documentation of combinable calls it initializer. Of course, this initializer can be a regular function or a function, returning the same type and takes zero argument (i.e.T f() ).
Remember that, the initializer is called only when a new thread specific local variable has to be allocated by the runtime.
When you use combinable with user-defined classes, your default constructor would anyways be called, also your combination operation would probably not be this trivial.
Task Parallelism
As annotated before, a task, conceptually, is nothing but a thread. The CR may execute a given task in same thread as the task initiator, or may use only one thread to execute more than one given tasks. Thus, task is not exactly same as thread.
A task can be expressed as functional division of work. For example, in previous examples, we used parallel algorithms to functionally divide the summation of numbers in a range, or to find some elements in a container. We, mostly, would not make several tasks; one of them waiting for user input, another responding to a client request via sockets and third one to read file as overlapped operation. All these operations are dissimilar, and does not form a logical task-group. Unless they form a pipeline for performing a work, in logically connected manner, they cannot be classified as task-group.
Reading from a file, counting number of lines/words, vowels, spelling mistakes etc. can be classified as different tasks, that can be classified as a task-group. Before I elaborate different types of tasks-groups, let me present you an example:
void DisplayEvens()
{
for (int n=0; n<1000;n+=2)
wcout<<n<<"\t";
}
void DisplayOdds()
{
for (int n=1; n<1000;n+=2)
wcout<<n<<"\t";
}
int main()
{
task_group tg;
tg.run(&DisplayEvens);
tg.run(&DisplayOdds);
tg.wait();
}
Albeit a bad example, I must exhibit it to make things simple.
The Concurrency::task_group is the class to manage set of tasks, execute them and wait for the tasks to finish. The task_group::run method schedules the given task and returns immediately. In sample above, run has been called twice to run different tasks. Both of the tasks would, presumably, parallelly in different threads. Finally, task_group::wait call is made to wait for tasks to finish. wait will block until all scheduled tasks are finished (or exception, cancellation happens in any of the tasks - we will see that later).
Another method, run_and_wait may be called to combine last two calls made. That is, it will schedule the task to run, and then wait for all tasks to finish. Of course, a lambda may also be used to represent a task:
tg.run([]
{
for (int n=0;n<1000;n++)
{
wcout << n << "\t";
}
});
tg.run_and_wait(&DisplayOdds);
There is no need to immediately wait for tasks to finish, the program may continue doing something else and wait later (if required). Also, more tasks may be scheduled, later, when needed.
The template class task_handle can be used to represent a task, which can take function-pointer, lambda or a functor. For example:
task_handle<function<void(void)>> task = &DisplayOdds;
Although you may not need to use task_handle class in your code, you may simplify the declaration using function make_task:
auto task = make_task(&DisplayOdds);
Before similar kind of alien stuff goes above your head, let me move ahead, which I believe would be more understandable!
There are two types of tasks-groups: structured and unstructured.
In PPL, a structured task group is represented by structured_task_group class. For small set of tasks, it performs better than unstructured task group. The algorithm parallel_invoke uses structured_task_group internally to schedule specified set of tasks:
structured_task_group _Task_group;
task_handle<_Function1> _Task_handle1(_Func1);
_Task_group.run(_Task_handle1);
task_handle<_Function2> _Task_handle2(_Func2);
_Task_group.run_and_wait(_Task_handle2);
Unlike, unstructured task group, you cannot wait on another thread for the completion of tasks. More comparison below.
The class named task_group represents unstructured task group. The class is mostly similar for spawning tasks, waiting for them etc. Unstructured task group allows you to create tasks in different thread (s) and wait for them in another thread. In short, unstructured task group gives you more flexibility than structured task groups, and it pays performance penalty for the same.
Remarkable differences between structured and unstructured tasks groups are:
- Unstructured task group is thread safe, structured task group isn't. That means for UTG, you can schedule tasks from different threads, and wait in another thread. But for STG, you must schedule all tasks and wait for the completion in same thread.
- After all tasks have been finished, STG object cannot be re-used to schedule more tasks, but you can reuse UTG object object to schedule more tasks.
- Since STG need not to synchronize between threads, it performs better than UTG.
- If you pass
task_handle to run or run_and_wait methods; the task_group (i.e. unstructured) class would copy it. But for structured_task_group, you must ensure that task_handle doesn't get destroyed (goes out of scope, for example), since it does not copy it - it holds the reference to task_handle object you pass.
- Multiple STGs must follow FILO pattern. That means if
T1 and then T2 STGs are scheduled to run, the T2 must get destroyed (destructor called), before T1 object is destroyed. Example:
structured_task_group tg1;
structured_task_group tg2;
- (Continuation to above, for STG) If a task itself creates STG object(s), those nested/inner STGs must vanish before parent/outer STG finishes. Definitely, the inner objects must also follow FILO. Conceptual example:
structured_task_group outer_tg;
auto task = make_task([] {
structured_task_group inner_tg;
});
outer_tg.run_and_wait(task);
Agreed, STGs are not easy to use - so don't use them unless necessary. Use UTG (task_group), or use parallel_invoke. For more than 10 tasks, you can nest parallel_invoke itself.
As a final note, all operations of STG are not thread safe, except operations that involve task-cancellation. The method for requesting task-group cancellation is structured_task_group::cancel, which will attempt to cancel running tasks under the group. The method, structured_task_group::is_canceling, can be to check of TG is being canceled. We will look up into Cancellation in PPL, later.
Asynchronous Agents Library
When you need different threads to communicate with each other, you can use Asynchronous Agents Library (Agents Library), more elegantly than standard synchronization mechanisms: locks and events; message passing functions and writing a message-loop; or something similar.
You pass a message to another thread/task using a message passing function. The message passing function utilizes agents to send and receive messages between different parts of a program.
The Agents Library has following components:
- Asynchronous Message Blocks
- Message Passing Functions
- Asynchronous Agents
Few points before we begin:
- Agents Library components are in
Concurrency namespace
- This library is template based.
- The header file is
<agents.h>
- The library and DLL requirement is same as for PPL.
Message Blocks and Message Passing Functions
The two components are tightly coupled with each other, thus it is not possible to elaborate them one by one. Message-blocks are set of classes, which are used to store and retrieve messages. Message Passing functions facilitates passing the messages to/from the message-block classes.
First an example:
#include <agents.h>
int main()
{
single_assignment<long> AssignSum;
task_group tg;
tg.run([&AssignSum]
{
long nSum = 0;
for (int n = 1; n < 50000; n++ )
{
nSum += n;
}
Concurrency::send(AssignSum, nSum);
});
wcout << "Waiting for single_assignment...\n";
receive(AssignSum);
wcout << "Received.\n" << AssignSum.value();
}
In a nutshell, the above program is calculating a sum in different thread, and waiting for its completion in another (the main thread). It then displays the calculated value. I have used UTG, instead of STG to make this program short. For STG, we must use task_handle, as a separate local variable.
The single_assignment is one of the Agent's template class that is used for dataflow. Since I am calculating sum, I instantiated it for long. This class is write- once messaging-block class. Multiple readers can read it from it. Multiple writes can also write to it, but it will only obey the message of first sender. When you learn about more of dataflow messaging-block classes, you would understand it better.
Concurrency::send and Concurrency::receive are the Agent's functions used for message-transfer. They take a message-block and the message, and send or receive the data. With the statement,
receive(AssignSum);
we are actually waiting for the message to arrive on AssignSum message- block. Yes, you sensed it right, this function will block until the message arrives on the specified block. Then we use single_assignment::value method to retrieve what is received. The return value would be of long type, since we instantiated the class for long. Alternatively, we can straightaway call value method, which would wait and block if message wasn't received on this message-block.
The colleague function, Concurrency::send would write the message on specified block. This would wakeup, receive. For single_assignment class, the send would fail if called more than once (from any thread). In Agent's library terms, the single_assignment would decline the second message, thus send would return false. As you read more about this below, you would understand more.
(Though Concurrency::send and WinSock' send have same names, they are have different signatures - it is safe to call them without namespace specification. But for preventing possible bugs/errors, you should use fully qualified names)
Where can or should you use this message-block type?
Wherever one time information update is required, from one or more threads; and one or more threads are willing to read the desired information.
Before I explore more of Agent's classes, few points to impart:
- The act of sending and receiving a message is known as Message Propagation
- A message involves two components: a source and a target. A source is the endpoint which sends the message, and a target is the endpoint which receives a message.
- A message-block can be of type source, target or both. Message block classes inherit from either
Concurrency::ISource, Concurrency::ITarget or both to represent block-type.
- A message block can accept or decline a message. It can also defer/postpone the decision to accept or reject a message.
- A message may be sent synchronously or asynchronously. The functions,
send or asend can be used to send messages, respectively.
receive or try_receive can be used to read messages. - The data-type for which a message-block class is instantiated, is known as payload type for that class. For above' example,
long is the payload type.
Enough of theory! Let's have some more action.
The overwrite_buffer template class is similar to single_assignment class, with one difference - it can receive multiple messages (i.e. accepts more than one message). Like single_assignment class, it holds only one message. The last sent message would be the latest message. If multiple threads do send message, scheduling and timing of message reception determines what latest message would be. If no message has been sent, receive function or value method would block.
Example code:
int main()
{
overwrite_buffer<float> MaxValue;
task_group tg;
tg.run([&MaxValue]
{
vector<float> LongVector;
LongVector.resize(50000);
float nMax = 1;
int nIterations = 1;
generate(LongVector.begin(), LongVector.end(), [&nMax]
{ return (nMax++) * 3.14159f;});
nMax = -1.0f; for(auto iter = LongVector.cbegin(); iter != LongVector.cend();
++iter, ++nIterations)
{
if( *iter > nMax)
nMax = *iter;
if(nIterations % 100 == 0)
{
send(MaxValue, nMax);
Concurrency::wait(40); }
}
});
tg.run_and_wait([&MaxValue]
{
int nUpdates = 50;
while(nUpdates>0)
{
wcout << "\nLatest maximum number found: "
<< MaxValue.value();
wait(500); nUpdates--;
}
} );
}
What the code does:
Task 1: Generates 50000 float numbers, in ascending orders, puts them into vector. Now it tries to find out the maximum number in that array, updates the nMax variable. On each 100th iteration over vector, it updates the overwrite_buffer to reflect the latest value.
Task 2: Would list the 50 updates from the overwrite_buffer, which essentially means it shows the user the latest maximum value found in vector. Waits slightly longer before issuing a refresh.
Since task 1 would finish before task 2 lists all 50 updates, the last few maximums would be repeated (displayed). That is actually the highest number found. The output would be like:
...
Latest maximum number found: 75084
Latest maximum number found: 79168.1
Latest maximum number found: 82938
Latest maximum number found: 94876
Latest maximum number found: 98645.9
...
Latest maximum number found: 153938
Latest maximum number found: 157080
Latest maximum number found: 157080
Latest maximum number found: 157080
Latest maximum number found: 157080
...
The code says it all, I guess I need not to explain things. But in short. Payload type is float. The wait for messages is in another task, unlike single_assignment example, where main function (main thread) was waiting. The Concurrency::wait is self explanatory, which takes timeout in milliseconds.
Where can or should you use this message-block type?
Whenever, one or more threads would update a shared information, and one or more threads are willing to get the latest information. A Refresh from user is good example.
Multi-threading programmers, who would need producer and consumer pattern, where one thread generates a message and puts into some message queue, and another thread reads those messages in FIFO manner, would appreciate this class. Most of us have used PostThreadMessage function or implemented a custom, concurrency aware, message- queue class. We also needed to use events and some locks for the same. Now here is the boon!
As the name suggests, unbounded_buffer does not have any bounds - it can have any number of messages stored. The sending and receiving of messages is done in FIFO manner. When a message is received is it removed from the internal queue, thus the same message cannot be received twice. By this, it also means that if multiple threads (targets) are reading from same unbounded_buffer block, either of them would get a message and not the other. If a message is received by target A, target B will not be able to receive it. The receive call would block if there are no pending messages to receive. Multiple sources can send the message, and their order (among different sources) is not deterministic.
A simple example:
int main()
{
unbounded_buffer<int> Numbers;
auto PrimesGenerator = [&Numbers]
{
for(int nPrime=3; nPrime<10000; nPrime+=2)
{
bool bIsPrime = true;
for(int nStep = 3; nStep<sqrtl(nPrime); nStep+=2)
{
if(nPrime % nStep==0)
{
bIsPrime=false;
break;
}
}
if (bIsPrime)
{
send(Numbers, nPrime);
}
}
wcout << "\n**Prime number generation finished**";
send(Numbers, 0); };
auto DisplaySums = [&Numbers]
{
int nPrimeNumber, nSumOfPrime;
for(;;)
{
nPrimeNumber = receive(Numbers);
if(nPrimeNumber == 0) break;
wcout<<"\nNumber received: "<<nPrimeNumber;
nSumOfPrime=0;
for(int nStep = 1; nStep<=nPrimeNumber; ++nStep)
nSumOfPrime += nStep;
wcout<<"\t\tAnd the sum is: "<<nSumOfPrime;
}
wcout << "\n** Received zero **";
};
parallel_invoke(PrimesGenerator, DisplaySums);
}
Recollect parallel_invoke, which executes set of tasks in STG? I stored two lambdas in variables, viz. PrimesGenerator and DisplaySums. Then parallelly called both of them to do the work.
As you can easily understand, the generator lambda is finding prime numbers, and putting into unbounded_buffer message-block, which is inherently a message-queue. Unlike previous two message-buffer classes, this class would not replace the contents of message with a new one. Instead it would put them into queue. That is why, generator is able to pile them up in Numbers message-block. No message will be lost or removed, unless received by some target.
The target, in this case, is DisplaySums, which is receiving numbers from the same message-block. The receive would return the first message inserted (i.e. in FIFO mode), and would remove that message. receive would block if no pending messages are in message-queue. This program is designed in such a way, where a zero (0) value indicates end of messages. In case you need just to check if message is available, you can use try_receive function. try_receive can be used with other target oriented message blocks, no just unbounded_buffer (i.e. any message-block inherited from ITarget).
In simple terms, call class acts like a function pointer. It is a target only block; that means it cannot be used with receive function, but only with send function. When you use send function, you are actually calling the function pointer (or say using the SendMessage API). First a simple example.
int main()
{
call Display([](int n)
{
wcout << "The number is: " << n;
} );
int nInput;
do
{
wcout << "Enter string: ";
wcin >> nInput;
send(Display, nInput);
} while (nInput != 0);
}
It takes a number from user, and calls the Display call-block. It should be noted that send will block till Display finishes, since Display is only being the target. Unlike other target blocks, where runtime just puts data for them to process later (via receive function).
But it should be noted that, call is multi-source oriented message-block. Meaning that, it can be called (via send or asend) from multiple tasks/threads. The runtime will put the messages in queue just like unbounded_buffer. Since send is synchronous function to send message to a message-block, it will wait until it finishes. Using send with call message-block is very similar to SendMessage API.
To send a message asynchronously, we can use Concurrency::asend function. It will only schedule the message for sending to given target block. Message will eventually be delivered to target as per runtime's scheduling. Using asend with call is similar to using PostMessage API.
Since it is only target oriented message-block, using receive or try_receive will simply result in compiler errors. Reason is simple: it doesn't inherit from ISource interface, the receive functions expect message blocks which are inherited from ISource. No, you need not to about these interfaces (at least not now) - I just mentioned for your knowledge.
To see the different in send and asend, just change the lambda as follows:
call Display([](int n)
{
wcout << "\nThe number is: " << n;
wait(2000); } );
If you call it with send, it will simple block your input (since send won't return for 2 seconds!). Now just change send to asend, and enter few numbers in quick succession. You'd see those number are eventually received by call message-block. Your input is not blocked, and messages are also not lost!
Definitely, you can use asend with other target oriented message blocks. Any proficient programmer can tell you that you cannot use asend on every occasion. Find the reason, if you don't know!
The transformer class is both source and target oriented message block. And, as the name suggests, it transforms one data to another data. It takes two template parameters, thus it makes it possible to transform one data type to another. Since it is logically able to transform one data to another, it needs a function/lambda/functor, just like call class. First just a basic declaration:
transformer<int, string> Int2String([](int nInput) -> string
{
char sOutput[32];
sprintf(sOutput, "%d", nInput);
return sOutput;
});
I assume you do understand the -> expression in lambda! Everything else is implicit, since you are reading and understanding some good stuff in C++.
As with transformer construction, first template parameter is its input type and second one is output type. You see that it is almost same as call, the only difference is that it returns something.
Now let's transform something:
send(Int2String, 128);
auto str = receive(Int2String);
I just sent an integer (128) to transformer message-block, and further retrieved the transformed message from it (in string form). One interesting thing you have noticed is the smart use of auto keyword - The Int2String is templatized, the receive function takes ITarget<datatype> reference, and returns datatype - Thus the type of str is smartly deduced!
Clearly, you would not use transformer class just to convert from one datatype to another. It can efficiently be used as a pipeline to transfer data between components of an application. Note that, unbounded_buffer class can also be used for transferring data from one component to another, but that acts only as a message-queue, and it must be backed by some code. The class call can be used as message-buffer where the code is the target (the receiver), the runtime and call class itself, manages multiple senders to send message to it, and put them in internal queue (in FIFO manner). But unlike, unbounded_buffer class, call cannot be used with receive (i.e. it is single target, multiple source). Finally, call cannot be used to forward the message to other component, by itself.
NOTE: Remember that all these classes have internal message queues. If the target doesn't receive input or doesn't process a message, they would be kept into queue. No message will be lost. The send function puts the message into queue synchronously, and doesn't return until message is accepted, or acknowledged for reception or denied by the message-block. Similarly, asend puts the message into queue of message-block, asynchronously. All this pushing and popping happens in thread-safe manner.
The transformer class can be used to form a message pipeline, since it takes input and emits output. We need to link multiple transformer objects to form a pipeline. The output of one object (say, Left) would be the input of another object (say, Right). The datatype of output from Left must be same as input of Right. Not only transformer message-block, but other input/output message block can be linked.
How to link message-blocks?
We need to use link_target method to link the target (the right side object). Somewhat gets complicated, but I must mention: link_target is actually a method of source_block abstract class. source_block class inherits from ISource interface. Therefore, all the source message-blocks classes actually inherits from source_block class.
Sigh! Too much of text to read, before actually seeing a code? Now it's time to see some code! First let's rewrite the Int2String lambda:
transformer<int, string> Int2String([](int nInput) -> string
{
string sDigits[]={"Zero ", "One ", "Two ", "Three ",
"Four ", "Five ", "Six ", "Seven ", "Eight ",
"Nine "};
string sOutput;
do {
sOutput += sDigits [ nInput % 10 ];
nInput /= 10;
} while (nInput>0);
return sOutput;
});
It would simply transform 128 to "Eight Two One". To actually convert number to displayable user string, see this article.
Let's write another transformer, which would count number of consonants and vowels out of this string and return it as std::pair:
transformer<string, pair<int,int>> StringCount(
[](const string& sInput) -> pair<int,int>int />
{
pair<int,int> Count;
for (size_t nPos = 0; nPos < sInput.size(); ++nPos)
{
char cChar = toupper(sInput[nPos]);
if( cChar == 'A' || cChar == 'E' || cChar == 'I' ||
cChar == 'O' || cChar == 'U')
{
Count.first++;
}
else
{
Count.second++;
}
}
return Count;
} );
For some readers, using pair in above' code might make it slightly hard to read; but believe me, its not that hard. The first component of pair would contain vowel counts, and second would store consonants (and others) count.
Now let's implement the final message-block in this data pipeline. Since it ends the pipeline, it need not to be transformer. I am using call, to display the pair:
call<pair<int,int>> DisplayCount([](const pair<int,int>& Count)
{
wcout << "\nVowels: " << Count.first <<
"Consonants: " << Count.second;
});
The DisplayCount message-block object displays the pair. Hint: You can make code simpler to read by typedefing the pair:
typedef pair<int,int> CountPair;
Finally now we connect the pipeline!
Int2String.link_target(&StringCount);
StringCount.link_target(&DisplayCount);
Now send the message to first message-block in this pipeline, and wait for entire pipeline to finish.
send(Int2String, 12345);
wait(500);
wait, at the end, is used to ensure that pipe line finishes before the main function exits, otherwise one or more pipeline message-blocks won't get executed. In actual program, we can use synchronization with single_assignment, standard Windows events or CRs events we would learn later. That all depends on how pipelining is implemented, and how the pipeline should terminate.
When you paste entire code in main, starting from Int2String declaration, and run it. It will display following:
Vowels: 9 Consonants: 15
You may like to debug the program by yourself, by placing breakpoints. Breakpoints would be needed, since the flow isn't simple and sequential. Or you may put console outputs in lambdas.
- Data Flow and Control Flow
The Agents classes I have discussed till now are based on data-flow model. In dataflow model, the various components of a program communicate each other by sending and receiving messages. The processing is done when data is available on message-block, and data gets consumed.
Whereas, in control flow model, we design program components to wait for some events to occur in one or more message blocks. For control-flow, though, the dataflow components (i.e. message-blocks) are used, but we don't need or read the data itself, but the event that some data has arrived on message block. Thus, we define an event, for one or more message blocks on which data would arrive.
Though, in many cases, single_assignment, overwrite_buffer or unbounded_buffer classes may also be used for control flow (ignoring the actual data). But they allow us only to wait on one data-arrived event, and secondly, they aren't made for control-flow mechanism.
The three classes mentioned below are designed for control flow. They can wait for multiple- message blocks' data-arrived event. Conceptually, they resemble WaitForMultipleObjects API.
The choice can wait for 2 to 10 message blocks, and would return the index of first message block on which message is available. All the given message blocks can be different types, including the message block's underlying type (template argument of message-block). We generally don't declare a choice object directly (it's awfully dangerous!). Instead we need to use helper function make_choice:
single_assignment<int> si;
overwrite_buffer<float> ob;
auto my_choice = make_choice(&si,&ob);
Here the choice object, my_choice, is created to wait on one of the two given message blocks. The make_choice helper function (hold your breath!) instantiates following type of object (with help of auto keyword, you are spared from typing that stuff):
choice<tuple<single_assignment<int>*,overwrite_buffer<float>*>> my_choice(tuple<single_assignment<int>*,overwrite_buffer<float>*> (&si,&ob));
A word about tuple class: Similar to std::pair class. This class can take up to 2 to 10 template arguments, and be a tuple for those data types. This class is new VC++ 10 (and in C++0x). The fully qualified name would be std::tr1::tuple. This is the reason why choice can have 2 to 10 message-blocks to wait. I will soon write an article on new features of STL!
Let's move ahead with choice class. Following code is simplest example of choice class:
send(ob, 10.5f);
send(si, 20);
size_t nIndex = receive(my_choice);
We sent messages to both message-blocks, and then waited for my_choice object to return. As mentioned previously, choice class would return the zero based index of message-block in which data is available. Therefore, the underlying type for reception from choice is size_t.
For code above' the nIndex would be 0, since it finds the message in first message- block. It all depends on how choice object is constructed - the order in which message- blocks are passed to constructor of choice. If we comment the second line above, the return value would be 1. It does not matter on which message block the message was sent first; only the order the choice was initialized, matters. If we comment both of the send calls, the receive would block.
Thus, we see that choice class resembles WaitForMultipleObjects API, with bWaitAll parameter set to false. It returns the index of any of the message-block in which message is found (as per the sequence passed in constructor).
Instead of using receive function, we can also use choice::index method to determine which message-block has message. The method, choice::value, which needs a template argument, would return the message that was consumed (i.e. the message that triggered choice). It would be interesting to know that all three approaches (receive, index and value):
- Would block if no message is available
- Would refer to same index/message that was received on first reception.
- Would inherently consume the message (for eg, remove message from
unbounded_buffer)
Please note that, one reception is done, using either approaches, that choice object cannot be re-used. The consumed message is consumed (logically, since not all message-block class would remove the message), and the same message/message-block would always be referred. Any other send call would not convince choice to receive another message from same/another message block! The following code snippet illustrates this (comment at the end is the output):
send(ob, 10.5f);
size_t nIndex = receive(my_choice);
wcout << "\nIndex : " << nIndex;
send(si, 20);
nIndex = my_choice.index();
wcout << "\nIndex (after resending) : " << nIndex;
float nData = my_choice.value<float>(); wcout << "\nData : " << nData;
Conceptually, the join class is very similar to choice class. The only essential difference is that it resembles WaitForMultipleObjects with bWaitAll parameter set to true. Something in action is pasted below:
int main()
{
join<int> join_numbers(4);
bool bExit = false;
single_assignment<int> si_even, si_odd, si_div5;
overwrite_buffer<int> si_div7;
si_even.link_target(&join_numbers);
si_odd.link_target(&join_numbers);
si_div5.link_target(&join_numbers);
si_div7.link_target(&join_numbers);
task_group tg;
tg.run([&] {
int n;
while(!bExit)
{
wcout << "Enter number: ";
wcin >> n;
if(n%2==0)
send(si_even, n);
else
send(si_odd, n);
if(n%5==0)
send(si_div5,n);
if(n%7==0)
send(si_div7,n);
}
});
receive(join_numbers);
wcout << "\n**All number types received";
bExit = true;
tg.wait();
}
About code:
join object is instantiated for int type. It would work for any ITarget<int> objects. Remember, only for int target message-blocks. The parameter in join's constructor specifies how many message blocks it has to handle. - Three
single_assignment and one overwrite_buffer message-blocks for int type. Via join, we will wait for messages in all these four message- blocks. overwrite_buffer is used just to illustrate that any target-block of same type (int) can be used.
- Used
link_target (ISource::link_target) method to set targets of all four message blocks to this join object.
- Ran a task group which would ask few numbers from user. Depending on number, it would send message to that message-block.
- The
main function waits for join_members, which would only return when all four message blocks receive input.
bExit is set to true, which would trigger the task to exit. But note that it would/may still ask one more number (take it as a bug, but ignore it).
Thus you see that with choice and join classes, and receive function, you achieve same functionality facilitated by WaitForMultipleObjects. The only difference among two classes is selecting all or selecting any. join has deviations, though, which I would describe shortly.
What about the time-out parameter?
For long we have been using the receive function, passing only the message-block as argument. That way, the function blocks indefinitely. The receive function takes one more argument - Timeout parameter - it is the default argument. The default timeout is infinite (defined as COOPERATIVE_TIMEOUT_INFINITE). The receive function itself is overload, but all versions take timeout, and all versions have it as last defualt argument. The timeout is in milliseconds. So, to wait for 2 minutes before all number types have been received, in previous example, we can change the receive function call as:
receive(join_numbers, 1000 * 2 * 60);
As you can implicitly understand that receive function, with timeout paramter, can be used with all message block types.
What if receive function timeouts?
It would throw Concurrency::operation_timed_out exception, which is derived from std::exception. I would elaborate Exceptions in Concurrency Runtime, later.
You might have noticed that choice class allows any type of message-block, having message-block's underlying type to be different. But join class accepts message block of only same underlying type. Well, choice operates on top of tuple; whereas join works on top of vector. For the same reason, choice is limited to 10 message-blocks to wait upon, but join can take any number of message blocks. I have not tested join till highest range, but definitely more than WaitForMultipleObject's 64 handles limit! (If you can/have tested, let me know).
NOTE: None of the Agents Library classes/function uses the Windows synchronization primitive (mutex, critical sections, events etc). It however, uses timers, timer-queues and interlocked functions.
Joins can be greedy or non-greedy, which is explained under multitype_join class.
Yes, as the name suggests, multitype_join can wait on message blocks of multiple types (including message-block underlying type). Since it takes multiple types, you either fiddle with template and tuple to instantiate the multitype_join object or use make_join helper function. Functionally, it is same as join class, except that is limits the source message block to be limited to 10. Example to create a multitype_join object:
single_assignment<int> si_even, si_odd;
overwrite_buffer<double> si_negative_double;
auto join_multiple = make_join(&si_even, &si_odd, &si_negative_double);
receive(join_numbers);
Greediness of Joins: Both join types can be greedy or non-greedy. Their greediness is in effect when you attempt to receive information from them. While creating the object we specify greedy or non-greedy mode:
join_type::greedy - Greedy joins are more efficient but may lead to live-lock (kind of deadlock, see here), or they may block indefinitely (even without deadlock). On receive request, they would receive message from all message-blocks, and would wait until all messages have been received. Once it receives message from any block, it will not return back. join_type::non_greedy
We create greedy and non-greedy join object as:
join<int, greedy> join_numbers(411);
join<int, non_greedy> join_numbers(411);
Default creation mode for join object is non-greedy.
We can use make_join to make non-greedy multitype_join, and use make_greedy_join to create greedy multitype_join object.
The timer class produces given message at given interval(s). This is source-only message-block, meaning that you cannot use send with it, but only receive function. The send functionality is the timer itself, which gets fired at regular intervals. The firing of message can be one time or continuously. In general, you would not call receive, but attach another message-block as the target of message. For example:
int main()
{
call<int> timer_target([](int n)
{
wcout << "\nMessage : " << n << " received...";
})
timer<int> the_timer(2000, 50, &timer_target, true);
the_timer.start();
wcout << " ** Press ENTER to stop timer** ";
wcin.ignore();
the_timer.stop();
wcout << "\n\n** Timer stopped**";
}
The constructor of timer is self explanatory. Following methods are important with timer:
timer::start - Timer doesn't start automatically, you must start the timer by calling this method. If timer is non-repeating, it would execute only once (after given timeout). If it is repeating, it would repeat continuously on given timeout value. timer::stop- Does exactly as the name suggests. Has no effect if timer is not already running. timer::pause - For non-repeating timer, it is same as calling stop method. For repeating timers, it pauses timer, which can be resumed by calling start again.
The target of timer can be any target-messaging block. For example, if we change the type of timer_target as follows,
unbounded_buffer<int> timer_target;
it will simply fill up this unbounded_buffer object, until timer is stopped!
Here we come to the end of message-blocks classes. Summary of message-block classes I have discussed:
| Class |
Propagation |
Source limit |
Target limit |
Remarks |
single_assignment |
Source and Target, both.
They can be receiver as well as sender.
|
Unlimited
|
Unlimited
|
Write-once message-block. Rejects any other message. On reception, first message is returned. |
overwrite_buffer |
Write-many, but read one message-block. Overwrites new message sent. Does not remove message. |
unbounded_buffer |
Write-many, read-many message-block which maintains FIFO order. Removes message once received, receive call would block if no message available. |
transformer |
Only 1 receiver allowed.
See Remarks.
|
Converts from one message to another message type. Useful in forming pipeline. link_target used to connect destination. transformer is created with lambda/function. Only one target is applicable, otherwise raises exception (not discussed till now). |
join |
Simulates WaitForMultipleObjects with wait-for- all principle. Only one receiver can be active at a time, otherwise raises exception (exceptions in CR is discussed below). Based on vector, allows any number of message- blocks to be waited on. |
multitype_join |
10
|
Same as above but for varied underlying message-block type. Based on tuple class. Raises exception on simultaneous waits. |
choice |
Simulates wait-for-any waiting principle. Based on tuple class, thus limits message-blocks to only 10. No multiple simultaneous waits allowed. |
call |
Target only |
Unlimited
|
-N/A-
|
Models the function-pointer mechanism. Constructor needs a function/lambda to act as the message-target. Template based, the lambda/function receives the same type. Multiple senders allowed. Keeps pending message in FIFO. Function/Lambda call received means message consumed/removed. |
timer |
Source only |
-N/A-
|
1
|
Sends message to specified message-block target, at regular intervals/once. Note that it runs on top of Windows timer-queue timers. |
Asynchronous Agents
Asynchronous Agent (or Agent) can be used to specialize a task in more structured and Object-oriented manner. It has set of states (life cycle): created, runnable, started, done and canceled. The agent runs asnychronously with other tasks/threads. In simple terms, an agent facilicates you to write a thread as a separate class (MFC programmers may resemble the same with CWinThread).
The Agents Library has an abstract base class Concurrency::agent. It has one pure virtual function named run, which you implement in your derived class. You instantiate your class and then call agent::start method. That's correct guess - the Runtime calls (schedules) your run method.
Sample derivation:
class my_agent : public agent
{
void run()
{
wcout << "This executes as a separate task.";
done();
}
};
Since run is a virtual function, which is called by CR, it doesn't matter if you put your implementation in public or private section.
And here is code to make it work:
int main()
{
my_agent the_agent;
the_agent.start();
agent::wait(&the_agent);
}
And now the description:
agent is the abstract class, having run as pure virtual function. - I inherited it on
my_agent class, implemented the required run method, which is nothing but void run(void).
- Called
agent::done method to let runtime know that it has finished. It sets the state of this agent to agent_done. More on this below.
- In
main, created an object named the_agent, and started it with agent::start method. The start method essentially schedules the agent to run asynchronously - i.e. as a separate task/thread.
- Then I waited form agent to finish with static method,
agent::wait. Other variations on waiting also exist, which we will see soon.
Life Cycle of an Agent
An agent would have its life cycle from its initial state to terminal state, as illustrated in following diagram (taken from MSDN):
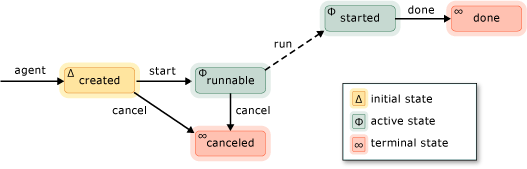
As you can see, agent has five stages. The solid lines and the function names represent the programmer's calls, and the dotted line represents the call made by runtime. An agent would not follow all these life-cycle stages, as it may terminate at some stage. The following enumeration members (of type agent_status enum) describes each stage of agent:
| Agent State |
Meaning of state |
agent_created |
The agent object is created, and is not scheduled yet. |
agent_runnable |
The agent is scheduled to run, but has not started execution. The start method would do this. |
agent_started |
The agent has started, and is running. The runtime would do it, asnychronously, after start method is called. |
agent_done |
The agent has successfully finished its execution. The overridden run method would explicitly call this done method for this state. |
agent_canceled |
The agent was canceled, before it would move to started stage. It would happen if other agent/task has called agent::cancel method. |
It is important to note that once agents enters started stage, it cannot be canceled. It would run!
You might wonder why you need to explicitly call agent::done method? Isn't it sufficient that run function returns, and runtime would know of its completion?
Well, the run override is just a method where agent can start its own work. It may have one or more message-blocks to send, receive and wait upon. For example a call message-block is schedule to take input from other sources, and call done (or conditionally call done). It is not mandatory that you call done from within the run method, but you call it when agent has finished. agent::wait (and other wait functions) would return only when done has been called on the waited agent.
Following example illustrates this:
class generator_agent : public agent
{
call<int> finish_routine;
public:
single_assignment<int> finish_assignment;
generator_agent() : finish_routine([this](int nValue) {
wcout << "\nSum is: " << nValue;
done(); })
{
}
void run()
{
wcout <<"\nGenerator agent started...\n";
finish_assignment.link_target(&finish_routine);
}
};
Albeit a slightly complicated implementation of agent, it exemplifies how to hide internal details of an agent, and still communicate with other agents/tasks in program. This example is not good, but only put here for illustration. Here the call is responsible for calling done. The single_assignment sets call as its target via link_target function. Below I mention, why I put finish_assignment in public area.
class processor_agent : public agent
{
ITarget<int>& m_target;
public:
processor_agent(ITarget<int>& target) : m_target(target) {}
void run()
{
wcout << "\nEnter three numbers:\n";
int a,b,c;
wcin >> a >> b >> c;
send(m_target, a+b+c);
done();
}
};
The processor_agent would take an object of type ITarget<int> as reference. The run method is straightforward. It sends message to specified target (that was setup on construction). The processor_agent has no knowledge about the other agent (or target), it just needs an ITarget of subtype int. To accept any sub type for ITarget, you can make the processor_agent templatized class.
Below is the main function, which uses both agents to communicate and further uses agent::wait_for_all function to wait for both agents to finish. The constructor of processor_agent needs a ITarget<int> object, and thus generator.finish_assignment is passed to it.
int main()
{
generator_agent generator;
processor_agent processor(generator.finish_assignment);
generator.start();
processor.start();
agent* pAgents[2] = {&generator, &processor};
agent::wait_for_all(2, pAgents); }
This paragraph lets know know that upper layer of Concurrency Library discussion is finished. It compromises of Parallel Patterns Library and Asynchronous Agents Library. The lower layer of CR contains Task Scheduler and Resource Manager. I would only discuss Task Scheduler. One more component that fits in separately, is Synchronization Data Structures, which I discuss below before I elaborate Task Scheduler.
Synchronization Data Structures
Concurrency Runtime facilitates following three synchronization primitives, which are Concurrency Aware. They work in alliance with the Cooperative Task Scheduler of CR. I would discuss Task Scheduler, after this section. In short, a cooperative scheduling does not give away the computing resource (i.e. CPU cycle) to other threads in system, but uses them for other tasks in the Scheduler. Following types are exposed for data synchronization in CR:
- Critical Sections -
critical_section class
- Reader/Writer Locks -
reader_writer_lock class
- Events -
event class
Header File: concrt.h
Unlike standard Windows synchronization primitives, the critical section and reader/writer locks are not reentrant. It means that if a thread already locks/own an object, an attempts to re-lock the same object would raise an exception of type improper_lock.
Represents the concurrency aware Critical Section object. Since you are reading this content, I do believe you know what Critical Section is. Since is is non-reentrant, it would yield the processing resources to other tasks, instead of preempting them. The critical_section class does not use CRITICAL_SECTION Windows datatype. Following are the methods of critical_section class:
| Method |
Description |
Remarks |
lock |
Acquires the lock for current thread/task. If critical section is locked by another thread/task, the call would block. |
If critical section is already acquired by current thread/task, improper_lock exception would be raised by runtime. |
try_lock |
Attempts to lock the critical section, without blocking. Would not raise exception even if CS is already locked by same thread.
|
Returns true if successful, false otherwise. |
unlock |
Unlocks the acquired critical section object. |
Would raise improper_unlock, if object was not locked by current task/thread. |
Since above mentioned method are not safe when function has multiple return points, raises some exception, or programmer misses to unlock the critical section - the critical_section embodies a subclass named critical_section::scoped_lock. The scoped_lock class is nothing but RAII wrapper around the parent class, critical_section. This class doesn't have anything except constructor and destructor. The following sample illustrates it:
Unreliable scheme:
critical_section cs;
void ModifyOrAccessData()
{
cs.lock();
cs.unlock();
}
Reliable scheme, backed by RAII:
void ModifyOrAccessData()
{
critical_section::scoped_lock s_lock(cs);
}
It should be noted that if lock is already held by same thread/task, and scoped_lock is used for that, improper_lock would occur. Similarly, if scoped_lock already acquires a lock successfully, and you explicitly unlock it, the destructor of scoped_lock would raise improper_unlock exception. For code snippet shows both:
void InvalidLock()
{
cs.lock(); ...
critical_section::scoped_lock s_lock(cs); }
void InvalidUnlock()
{
critical_section::scoped_lock s_lock(cs);
...
cs.unlock();
}
As said before, blocking lock would not preempt the processing resource, but would attempt to give it to other tasks. More on this later.
Suppose you have a data or data-structure that is being accessed and modified by multiple threads in your program. An array of arbitrary data-type, for example. For sure, you can control the access to that shared data using critical section or other synchronization primitive. But, that shared data is mostly used for reading and not for update/write operations. In that scenario, a lock for reading would mostly be futile.
The reader_writer_lock class allows multiple readers to read simultaneously, without blocking other threads/tasks that are attempting to read the shared data. The write-lock, would however be allowed only for one thread/task. Before I present code and list out methods, few points to know:
- Like
critical_section class, the reader_writer_lock class is also non-reentrant. Once a lock is acquired (of any type) by a thread, and attempt to re-acquire lock (any type) from same thread would cause exception.
- Since this class is also concurrency aware, it doesn't give-away the processing resources, but utilizes for other tasks.
reader_writer_lock class is write-preference class. It gives priority to writers, and readers may starve. The request, however, is served in FIFO order (separate queues of requests is maintained for both lock types). - A read-only lock cannot be upgraded to writer-lock, unless you release read-only lock. Similarly, a writer-lock cannot be downgraded to read-only lock, unless writer-lock is released.
NOTE: If the shared data involves substantially more frequent writes than reads, it is recommended that you use other locking mechanism. This class would give optimum performance for read-mostly context.
The reader_writer_lock does not use Slim Reader/Writer Locks which is available in Windows Vista and higher versions. SRW Locks and reader_writer_lock have following notable differences:
- SRW is neither read-preference nor write preference - the order of granting locks is undefined.
- For scheduling, SRW is uses preemptive model, and RWL uses cooperative model.
- Since the size of SRW is quite small (size of pointer), and doesn't maintain queue of requests, it grants locks faster than RWL. But, depending on program design, SRW may perform less efficient than RWL.
- SRW depends on OS (for API), RWL depends only on Concurrency Runtime.
Methods exhibited by reader_writer_lock class:
| Method |
Description |
Remarks |
lock |
Acquires writer (i.e. reader+writer) lock. Blocks until it gains writer-lock.
|
If writer lock is already acquired by current thread/task, improper_lock exception would be raised by runtime. (Also, see table below) |
try_lock |
Attempts to acquire writer-lock, without blocking.
|
Returns true if successful, false otherwise. (See table) |
lock_read |
Acquires read-only lock and blocks until it gains it. |
Raises improper_lock, only if writer-lock is already acquired. Otherwise continues. See table below. |
try_lock_read |
Attempts to acquiwriter-lock, without blocking.
|
Returns true if successful, false otherwise. (See table) |
unlock |
Release the lock (whichever type of lock was acquired) |
Raises improper_unlock, if no lock is acquired.
The writer-lock requests are chained. Thus, runtime would immediately choose next pending writer-lock and would unblock it.
|
...
This article is still being written. There is lot to add. But I am anyway posting it. Since this is new topic, I need time to read and try out the concepts. This is less than 80% of what I expect to explain in this article. More examples, source files and external links would for sure be added; and mistakes in writing would be corrected!
- Amendment 1 (Aug 10): Class combinable explained
- Amendment 2 (Aug 13): Task Groups elaborated
- Amendment 3 (Aug 15): Asynchronous Library. Few concepts and classes explained.
- Amendment 4 (Aug 18): Class transformer illustrated.
- Amendment 5 (Aug 19): Class choice explained.
- Amendment 6 (Aug 21): Joins elaborated and timer explained. Summary provided.
- Amendment 7 (Aug 25): Critical Sections, Reader/Writer locks explicated.
- Amendment 8 (Sept 2): Sample Projects added
Practical examples would be given soon, and sample project(s) would have good number of them!

