Introduction
Of all the pieces in the .NET puzzle, I have always found ADO.NET to be the most puzzling. That’s probably because I like object-oriented programming. ADO.NET just doesn’t seem to fit in with an object-oriented approach, even though it has some object oriented features of its own. I could never really figure out how to incorporate ADO.NET into an object design.
And then one night, on my way to dinner with the family, I had an Epiphany. A voice from out of nowhere said “ADO.NET doesn’t work with object designs because it’s not supposed to work with objects!” Great, I thought, now I’m hearing voices. But it turns out it was just my wife, who is no slouch at .NET herself.
“ADO.NET is a continuation of the old VB6 way of doing things,” she said. “Visual Basic was a great way to slap things together in a hurry. And as long as those things weren’t very complicated, it worked pretty well. ADO.NET lets the same approach work with more complex problems, but it’s still pretty much a bolt-together technology. You’ll never build a Swiss watch with it, the way you can with objects.”
Well, that actually made a lot of sense to me. As we continued the conversation, we came to the conclusion that the best way to use ADO.NET in an object-oriented design is to not use it—or at least to use it as little as possible. After all, in Objectland, what do we really need ADO.NET for? Simply to get data from a database to our objects, and from the objects back to the database. That means we need about a tenth of what ADO.NET has to offer.
Okay, so we swear off datasets, strongly typed or otherwise, and vow to use ADO.NET as a thin transport layer between our objects and their data store. But we pay a price. .NET user interface controls are built around the notion of data-binding, and if we can use that, then the chores involved in wiring our object model to the rest of the app become a lot easier. What we’d like is the best of both worlds.
This article will show how to accomplish those goals—use ADO.NET as a thin data transport layer, while still taking advantage of the data-binding capabilities of .NET user interface controls. As it turns out, it’s pretty easy, and it can save object-oriented programmers from reading book after book in a futile attempt to figure out ADO.NET.
The AdoNetDemo Application
In this article, we are going to use an application called AdoNetDemo to illustrate the principles and techniques we will be discussing. AdoNetDemo is a bare bones application designed to demonstrate the interaction between ADO.NET and a simple object model, during typical CRUD (Create, Retrieve, Update, and Delete) operations.
AdoNetDemo is built on an object model that might be used by a project manager. The object model is built around a ProjectList object, which contains a collection of ProjectItem objects. Each ProjectItem has several native properties and a collection property called Steps. The Steps property is of type StepList, and it contains a collection of StepItem objects.
Here is a graphical view of ProjectList and its children:

Our emphasis in this article will be on CRUD operations, so we are going to take some liberties with object design to keep things simple. We won’t build a Data Access layer; to keep things simple, we are going to put all of our demonstration methods in Form1. Our user interface will be rather primitive—just enough to demonstrate the points we will be discussing.
And in the spirit of keeping things simple, we won’t take the usual security precautions one would expect. For example, we are going to use dynamic SQL queries, and we won’t bother escaping them. Obviously, in a production environment, you would want to use stored procedures, or at the least escape all query strings.
ADO.NET as a Query Engine
With that out of the way, let’s start with the basics. As object programmers, what do we really need to use ADO.NET for? We really only need it as a query engine, an object that will process our SQL queries. ADO.NET was designed to be a full-featured data manager. As such, it can organize data, maintain transactions, and the like. But, we, object programmers, encapsulate those capabilities in our business object models.
By the way, to learn how to do that, see RockyLhotka’s great Business Objects… books (there are both VB and C# versions).
What that means is that we don’t need, or even want, most of ADO.NET’s capabilities. They exist to support a data-driven approach to programming, rather than the object-oriented approach that we prefer. So let’s scrap the 80% of ADO.NET that we don’t need, and focus on the 20% that is useful to us. Since we only need a bare-bones data engine, we are going to strip ADO.NET down to its absolute basics. What we are left with, looks more like ADO from the old days.
For our purposes, here is how ADO.NET works:
- We want to connect to a database, so we will need a Connection object.
- We want to pass a SQL query to the database, so we will need a Command object.
- If our query returns a result set, we want a container for the records returned. So we will need either a
DataReader (for flat result sets) or a DataSet (for containment hierarchies).
- If we use a
DataSet, we will also need a DataAdapter object.
- Finally, if we are executing a command that doesn’t return a result set (like an
INSERT, UPDATE, or DELETE query), we don’t need the container or data adapter. We simply call an Execute method on the command itself.
In other words, we only need three or four objects in most cases. That’s really pretty simple.
And what we do with those objects is just as simple. We connect to a database, we get a DataReader or fill a DataSet, and then we close the connection. Or, we connect to a database, execute a command, and then close the connection. All in all, it’s really a straightforward model, and not much more complicated than good old ADO.
Loading Flat Data
Let’s start with a simple case: we want to load a single table into a collection of objects—a ‘flat’ data load. Open AdoNetDemo, and click the Flat ‘Select’ Query button. Here is what you should see:
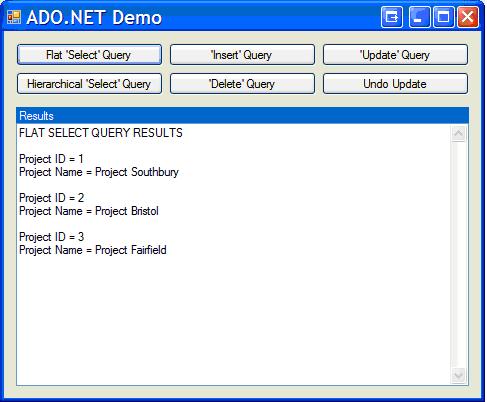
The app is showing that it loaded three projects from the database into the ProjectList collection. The Results box shows the ID and name of each project. Note that it doesn’t show the steps for each project. That’s because we didn’t load them—we simply did a flat data load of the projects themselves.
Here is what the flat data load looks like in code:
public ProjectList GetProjects()
{
ProjectList projects = new ProjectList();
string sqlQuery = "Select * from Projects";
SqlConnection connection = new SqlConnection(m_ConnectionString);
connection.Open();
SqlCommand command = new SqlCommand(sqlQuery, connection);
SqlDataReader dataReader = command.ExecuteReader();
if (dataReader.HasRows)
{
while (dataReader.Read())
{
ProjectItem project = new ProjectItem();
project.ID = dataReader.GetInt32(0);
project.Name = dataReader.GetString(1);
projects.Add(project);
}
}
command.Dispose();
connection.Close();
connection.Dispose();
return projects;
}
First, the method creates a ProjectList to hold our projects. Then, it creates a simple SQL query to fetch all projects. Next, it creates a Connection object and opens it to connect to the database.
Note that in AdoNetDemo, the connection string is stored as a member variable in the Declarations section of the Form1 code. In a production app, you would want to read the connection string from a config file, with appropriate security.
Now that we have a query and a connection to the database, the method uses these items to create a Command object. Then, the method calls that object’s ExecuteReader() method, which returns a DataReader object.
A DataReader is a forward-only dump of the records that match the SQL query attached to the Command object. It is often referred to as a ‘firehose cursor’, which is pretty descriptive of what it does. It has the advantage of being very fast, and not very greedy about the resources it uses. That makes it well-suited for a simple transfer of records to an object collection.
DataReaders are generally processed using a while loop, instead of a foreach loop. That’s because a DataReader doesn’t have an iterator or a rows collection. All it can do is march through a result table one line at a time, from top to bottom. When it reaches the last row, its Read() method will be set to false.
The rest of the method is straightforward code to create an object for each row and load field values from the row into the object. After the row has been read in, the new project is added to the project list. After the last row is added, the code closes the Connection object and disposes of it and the Command object we used.
This ‘Close-and-Dispose’ step is very important, particularly if you plan to load a lot of tables into a lot of collections. Connection and Command objects are unmanaged objects, and they must be explicitly closed and disposed of, so that the garbage collector can free up the resources they use.
Note that, to keep the code simple, we did not wrap it in a try-catch block. In a production environment, you should always do so. Wrap the transfer code in a ‘try’ block, and wrap error-handling code in a ‘catch’ block. Finally, wrap the close-and-dispose code in a ‘finally’ block. That way, you know the connection is released, whether the fetch succeeded or failed.
Loading Hierarchical Data
So, how do we load a containment hierarchy? The projects by themselves won’t do us much good—we really want each project and its steps. This is where some of the data management capabilities built into ADO.NET come in handy.
To see the results of a hierarchical data load, open AdoNetDemo and click on the Hierarchical ‘Select’ Query button. You should see results similar to the flat data load, but with each project’s steps listed below the project.
Loading a containment hierarchy from a database used to be a painful chore. Basically, I would load the projects into the ProjectList. Then I would iterate the ProjectList; for each project in the list, I would run a query against the database to load each project’s steps. That meant a different query to run on the database for each project in the list. At one point, I tried writing ‘hierarchical queries’ under ADO, but that was a frustrating exercise, at best.
ADO.NET reduces all this to a pretty simple matter of loading the parent and child tables into a dataset and creating a ‘data relation' between the tables. Here is what it looks like in code:
public ProjectList GetProjectsAndSteps()
{
ProjectList projects = new ProjectList();
string sqlQuery =
"Select * from Projects; Select * from Steps";
DataSet dataSet = new DataSet();
using (SqlConnection connection =
new SqlConnection(m_ConnectionString))
{
SqlCommand command = new SqlCommand(sqlQuery, connection);
SqlDataAdapter dataAdapter = new SqlDataAdapter(command);
dataAdapter.Fill(dataSet);
}
dataSet.Tables[0].TableName = "Projects";
dataSet.Tables[1].TableName = "Steps";
DataColumn parentColumn =
dataSet.Tables["Projects"].Columns["ProjectID"];
DataColumn childColumn =
dataSet.Tables["Steps"].Columns["ProjectID"];
DataRelation projectsToSteps =
new DataRelation("ProjectsToSteps",
parentColumn, childColumn);
dataSet.Relations.Add(projectsToSteps);
ProjectList projectList = new ProjectList();
ProjectItem nextProject = null;
StepItem nextStep = null;
foreach (DataRow parentRow in dataSet.Tables["Projects"].Rows)
{
nextProject = new ProjectItem();
nextProject.ID = Convert.ToInt32(parentRow["ProjectID"]);
nextProject.Name = parentRow["Name"].ToString();
DataRow[] childRows =
parentRow.GetChildRows(dataSet.Relations["ProjectsToSteps"]);
foreach (DataRow childRow in childRows)
{
nextStep = new StepItem();
nextStep.ID = Convert.ToInt32(childRow["StepID"]);
nextStep.Date = Convert.ToDateTime(childRow["Date"]);
nextStep.Description = childRow["Description"].ToString();
nextProject.Steps.Add(nextStep);
}
projectList.Add(nextProject);
}
dataSet.Dispose();
return projectList;
}
The code starts off much like the previous sample. It creates a ProjectList, and a SQL query to populate the list. But the SQL query is a bit different—it is actually two independent queries (note the semicolon in the middle of the query string that separates the two queries). As we will see, this query reads both the Projects table and the Steps table from the database into a DataSet, which is also declared at the top of the method. These tables remain separate in the DataSet; they are mirrors of their counterparts in the database.
The data read is set up a little differently than the first example. As before, we declare a standard SQL Server connection string. But the following line is new:
using (SqlConnection connection = new SqlConnection(m_ConnectionString))
This ‘using’ statement tells .NET that we are going to be using the declared connection for everything that occurs between the braces. .NET will open the connection automatically, and perform an automatic close-and-dispose of the connection and command objects used when it’s done, even if the fetch throws an exception.
Since we have multiple tables, we are going to use a DataSet object to hold the result set. A DataSet does not have a built-in means of connecting to a database, so we create a DataAdapter object, in addition to Connection and Command objects, to make the connection. We use the data adapter to ‘fill’ the data set.
At the end of the ‘using’ block, the dataset is disconnected from the database, and the Connection, Command, and DataAdapter objects we used are automatically closed and disposed of by .NET. That’s one of the principal benefits of using a ‘using’ block. Now, we can take our disconnected DataSet and configure it for a hierarchical read.
The first thing we need to do is name the DataSet tables. For some reason, ADO.NET does not automatically map database table names to a dataset, nor does it provide an option to specify automatic mapping. Instead, it names the first table ‘Table’, the second table ‘Table1’, and so on. We could certainly use these default names when configuring the DataSet, but our code is going to be more readable if we map the database table names to the dataset tables. So, we set these names manually.
Once we have named the dataset tables, we are ready to create a DataRelation object. A data relation does a lot more than a SQL ‘Join’ clause—it creates a parent-child relationship between two tables. Once I have created a data relation, I can view all the child rows of a particular parent row. In other words, I can walk through the Projects table and see the steps that belong to each Project, without having to run a separate query.
That’s exactly what we do in the latter part of the code. We walk through the Projects table, creating a new ProjectItem for each row in the table. Once we have populated the native properties of the ProjectItem, we get the project’s child rows, (from the Steps table) courtesy of the data relation. We create and populate a new StepItem for each child row and add it to the project’s StepList. After we finish adding steps to the project, we add it to the project list. After we add the last project to the project list, we return the list. No muss, no fuss, and we hardly work up a sweat!
You might have noticed a couple of differences between the DataSet in this example and the DataReader we used in the previous example. For one thing, we were able to use a ‘foreach’ loop to iterate through the DataSet. For another, we were able to refer to table columns by name, instead of by index number:
newStep.Description = childRow["Description"].ToString();
As you might imagine, both of these capabilities require resources. And yes, a DataSet is an unmanaged object with a Dispose() method. The ‘using’ block can’t take care of close-and-dispose on the dataset, because it lives on past the ‘using’ block. So, call Dispose() whenever you finish with a dataset, so the .NET garbage collector can recover those resources.
Inserting Data
Inserts are pretty straightforward. About the only trick to them is that we generally want to get the Identity value (the record ID) of the new record we add to the database.
There are several approaches one can take when creating a new object that will ultimately be persisted to a database. For example, one might create the object, and then insert a new record into the database when the object is modified and saved. AdoNetDemo creates a new record when the new object is created, and populates the record and the object with default data.
Open AdoNetDemo and click on the ‘Insert’ Query button. The app will add a new step to the first project on the list. The new step will be at the end of the list, and it will have the description “[New List]”.
Here is how the ‘Insert’ query works:
public StepItem CreateStep(int projectID)
{
string sqlQuery = String.Format("Insert into Steps (ProjectID, "
+ "Description, Date) Values({0}, '[New Step]', '{1}'); “
+ “Select @@Identity",
projectID, DateTime.Today.ToString("yyyy-MM-dd"));
SqlConnection connection = new SqlConnection(m_ConnectionString);
connection.Open();
SqlCommand command = new SqlCommand(sqlQuery, connection);
int stepID = Convert.ToInt32((decimal)command.ExecuteScalar());
command.Dispose();
connection.Close();
connection.Dispose();
StepItem newStep = new StepItem();
newStep.ID = stepID;
newStep.Date = DateTime.Today;
newStep.Description = "[New Step]";
return newStep;
}
As before, the method starts out by building a SQL query to perform the task we need to get done. And, as in our second example, the query string contains two queries, which are separated by a semicolon.
The first query is a routine SQL ‘Insert’ query. The second query deserves some explanation:
Select @@Identity
This query will return the Identity value of the last record added to the database. We need to pass this value to the companion object we create for this database, so the object knows which record to update when it is saved.
Normally, a Select query returns a result set, which means we would need a DataReader or a DataAdapter to get the results. But, since the “Select @@Identity” query returns a scalar value, we can use the Command.ExecuteScalar() method to perform the update, get the identity, and return the identity value to us.
There is one quirk associated with the “Select @@Identity” query—its result is returned as a SQL decimal value (with no decimal!). So, we cast the result as a decimal, then convert it to an int for our stepID variable.
Updating Data
Updating data is similar to inserting data—we need to execute an action query, rather than a query that returns a result set. Open AdoNetDemo and click the ‘Update’ Query button. The app will change the name of the first project from “Project Southbury” to “Project NameChanged”. You can change the project name back by clicking the Undo Update button.
The code that performs the update is pretty simple:
public void UpdateProjectItem(ProjectItem project)
{
string sqlQuery =
String.Format("Update Projects Set Name = '{0}' "
+ "Where ProjectID = {1}",
project.Name, project.ID);
SqlConnection connection =
new SqlConnection(m_ConnectionString);
connection.Open();
SqlCommand command = new SqlCommand(sqlQuery,
connection);
command.ExecuteNonQuery();
command.Dispose();
connection.Close();
connection.Dispose();
}
There are no real tricks here, and by now, the pattern should feel pretty familiar. We build a query, create and open a Connection, create a Command object and configure it with the query, execute the command, and close-and-dispose. By now, you can probably do it in your sleep.
Deleting Data
And at last, that brings us to our final operation, a delete. It’s nothing more than a different action query that gets executed in pretty much the same way as the Update query we just looked at.
To see what AdoNetDemo does, open it and click the ‘Delete’ Query button. The app will delete any new records you have added to the database and report back the number of records deleted. If it reports that zero records were deleted, it means you haven’t added any records.
This code is also very straightforward:
public int DeleteNewSteps()
{
string sqlQuery = "Delete from Steps" +
" Where Description = '[New Step]'";
SqlConnection connection =
new SqlConnection(m_ConnectionString);
connection.Open();
SqlCommand command = new SqlCommand(sqlQuery, connection);
int numRowsDeleted = command.ExecuteNonQuery();
command.Dispose();
connection.Close();
connection.Dispose();
return numRowsDeleted;
}
This code follows an almost identical pattern as the previous example. The only differences are in the query, and in the fact that we make use of the value returned by ExecuteNonQuery(). This function always returns the number of rows affected by the query it executed.
Conclusion
That’s it for Part One. If all you need to know is how to move data back and forth between a database and an object model, you should have just about all you will need.
In Part Two, we will dig into data binding in a .NET user interface, which can dramatically reduce the amount of plumbing code you have to write to connect a user interface to your object model. And we will look at the ‘DAO Pattern’, which is today’s most widely used pattern for data access. We will refactor the code that we wrote in Part One to make it more object-oriented, flexible, and easier to maintain.

