Introduction
First, a warning: These are undocumented and unsupported features in SQL Server so use at your own risk!
In Oracle, there is a pseudo column for each row called ROWID which reveals the physical address of a row in the database file. This column can be used to identify a single row even when a row doesn't have a key. Based on documentation, SQL Server seems to lack this kind of functionality but that's not quite true since SQL Server also has a mechanism to identify the physical address of a row. In SQL Server 2008, this is called %%physloc%%, and in SQL Server 2005, %%lockres%%. This article tries to describe the basic usages of this pseudo column in SQL Server 2008.
How is it used
First, let's create a table to test this feature. In order to test different usages, we'll need a table with several rows.
CREATE SCHEMA PhysLocTest;
GO
IF OBJECT_ID ( 'PhysLocTest.SeveralRows', 'U' ) IS NOT NULL
DROP TABLE PhysLocTest.SeveralRows;
GO
CREATE TABLE PhysLocTest.SeveralRows (
Id int NOT NULL IDENTITY(1,1)PRIMARY KEY,
InsertTime date NOT NULL DEFAULT (GETDATE()),
Category varchar(2) NOT NULL
);
GO
SET NOCOUNT ON
DECLARE @counter int;
BEGIN
SET @counter = 0;
WHILE @counter < 100000 BEGIN
INSERT INTO PhysLocTest.SeveralRows (Category)
VALUES (CONVERT(varchar, ROUND( RAND(), 1) * 10 ));
SET @counter = @counter + 1;
END;
END;
After the table is created and filled, you can try the %%physloc%% pseudo column:
SELECT TOP(5)
a.%%physloc%% AS Address,
a.*
FROM PhysLocTest.SeveralRows a
ORDER BY a.Id;
Address Id InsertTime Category
0xFB0D000001000000 1 2011-02-19 3
0xFB0D000001000100 2 2011-02-19 2
0xFB0D000001000200 3 2011-02-19 4
0xFB0D000001000300 4 2011-02-19 2
0xFB0D000001000400 5 2011-02-19 1
At this point, you'll see that each row has a unique address. The address actually contains information about the file, page, and the slot the row is in. However, the hexadecimal value isn't very easy to interpret, so SQL Server has a function called sys.fn_PhysLocFormatter to better visualize the location of the row.
Using sys.fn_PhysLocFormatter
This function takes the physical address as a parameter and formats the address to text to show the location of a row.
SELECT TOP(5)
a.%%physloc%% AS Address,
sys.fn_PhysLocFormatter(a.%%physloc%%) AS AddressText,
a.*
FROM PhysLocTest.SeveralRows a
ORDER BY a.Id;
Address AddressText Id InsertTime Category
0xFB0D000001000000 (1:3579:0) 1 2011-02-19 3
0xFB0D000001000100 (1:3579:1) 2 2011-02-19 2
0xFB0D000001000200 (1:3579:2) 3 2011-02-19 4
0xFB0D000001000300 (1:3579:3) 4 2011-02-19 2
0xFB0D000001000400 (1:3579:4) 5 2011-02-19 1
So now you have the physical address in clear format. Based on the output, row with ID 3 is located in the file 1 on page 3579 and in slot 2. Now you can, for example, identify the actual data file the row is located in using the system view sys.database_files.
SELECT df.type_desc,
df.name,
df.physical_name
FROM sys.database_files df
WHERE df.file_id = 1;
type_desc name physical_name
ROWS Test02 C:\Program Files\Microsoft SQL Server\Inst1\MSSQL\DATA\test02.ndf
If you want to go further, you can dump the contents of the block using DBCC PAGE. In order to view information from DBCC PAGE, trace flag 3604 has to be set on. The DBCC PAGE command takes the following parameters:
- Database name or database ID
- Number of the file
- Number of the page
- Level of detail in the output
- 0 = header
- 1 = header and hex dump for rows
- 2 = header and the page dump
- 3 = header and detail row information
DBCC TRACEON(3604)
DBCC PAGE (Test, 1, 3579, 1)
DBCC TRACEOFF(3604)
PAGE: (1:3579)
BUFFER:
BUF @0x0000000084FD4200
bpage = 0x00000000848B0000 bhash = 0x0000000000000000 bpageno = (1:3579)
bdbid = 15 breferences = 0 bcputicks = 0
bsampleCount = 0 bUse1 = 5565 bstat = 0xc0010b
blog = 0xbbbbbbbb bnext = 0x0000000000000000
PAGE HEADER:
Page @0x00000000848B0000
m_pageId = (1:3579) m_headerVersion = 1 m_type = 1
m_typeFlagBits = 0x4 m_level = 0 m_flagBits = 0x0
m_objId (AllocUnitId.idObj) = 365 m_indexId (AllocUnitId.idInd) = 256
Metadata: AllocUnitId = 72057594061848576
Metadata: PartitionId = 72057594056081408 Metadata: IndexId = 1
Metadata: ObjectId = 1746821285 m_prevPage = (0:0) m_nextPage = (1:3582)
pminlen = 11 m_slotCnt = 384 m_freeCnt = 10
m_freeData = 7414 m_reservedCnt = 0 m_lsn = (78:1213:16)
m_xactReserved = 0 m_xdesId = (0:0) m_ghostRecCnt = 0
m_tornBits = 0
Allocation Status
GAM (1:2) = ALLOCATED SGAM (1:3) = NOT ALLOCATED
PFS (1:1) = 0x60 MIXED_EXT ALLOCATED 0_PCT_FULL DIFF (1:6) = CHANGED
ML (1:7) = NOT MIN_LOGGED
DATA:
Slot 0, Offset 0x60, Length 19, DumpStyle BYTE
Record Type = PRIMARY_RECORD Record Attributes = NULL_BITMAP VARIABLE_COLUMNS
Record Size = 19
Memory Dump @0x000000001613A060
0000000000000000: 30000b00 01000000 ea330b03 00000100 † 0.......ê3......
0000000000000010: 130033† † † † † † † † † † † † † † † † † † † † † † † † † † † † † † † ..3
...
Can this be used to speed up fetches
In Oracle, ROWID is sometimes used to speed up fetches (although it's not advisable). Since the ROWID is the physical location of the row, there's no need to locate the row, for example, using an index if the ROWID is already known. Does the same apply to SQL Server? The answer is simply no. %%physloc%% acts more like a function so if it is used in the WHERE clause of a SQL statement, SQL Server needs to scan the row locations and then pick up the matching location. To test this, let's try to select a single row from the test table using both ID (primary key) and the location.
SELECT a.%%physloc%% AS Address,
a.*
FROM PhysLocTest.SeveralRows a
WHERE a.Id = 4321
Address Id InsertTime Category
0x641E000001006100 4321 2011-02-19 8
Table 'SeveralRows'. Scan count 0, logical reads 2, physical reads 0,
read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
And the visual execution plan (total cost 0,0032831, estimated number of rows from index seek = 1):
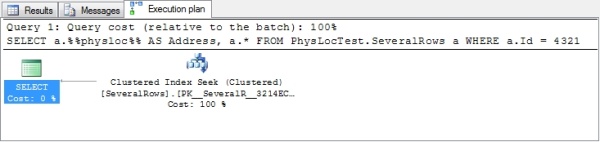
That was quite efficient. When using the ID column in the condition, it's clearly seen in both execution plan and the statistics that SQL Server is using the primary key index to fetch the row. Now what happens if the physical location is used instead?
SELECT a.%%physloc%% AS Address,
a.*
FROM PhysLocTest.SeveralRows a
WHERE a.%%physloc%% = 0x641E000001006100
Address Id InsertTime Category
0x641E000001006100 4321 2011-02-19 8
Table 'SeveralRows'. Scan count 1, logical reads 29, physical reads 0,
read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
And the visual execution plan (total cost 0,323875, estimated number of rows from index scan = 100'000):

Now SQL Server has to scan the clustered primary key index in order to find the correct physical address. Scan count is 1 and 29 pages are read. Not very good choice from a performance point of view. So we can safely say that using physical location does not provide any kind of performance improvement if used.
Identifying a row without a key
One use-case for physical location is to identify a single row in a table even when the table does not have a key defined on it. A quite common issue is: How can I delete duplicate rows when I don't have a key to use? There are several possibilities to do that. One is to add a key to the table and use it for deletion or perhaps to create a temporary table, load unique rows with the DISTINCT keyword into the temp table, truncate the original table, and reload the distinct data back. Both of these approaches work, but they have a few issues one should think of.
In the first solution (add a key), the table structure is changed, actually the row is widened. Changing the structure is something that should naturally be avoided when simple DML operations (SELECT, INSERT, UPDATE) are used. In the second solution (reload using a temp table), all the data is deleted and then added back to the original table. This may cause problems and inconsistent data if there are, for example, triggers on the original table.
In our test table, there was a primary key, but let's forget that for a moment. What if I want to delete all duplicate rows so that only one row is left for each category? If the random number generator worked well, there should be 11 categories in the table, values 0-10. So basically, I have to create a delete statement which excludes one row for each category based on the physical location. In the following example, I decided to leave the smallest location for each category and delete the rest. Note: The smallest location isn't necessarily the firstly added row, which could be an easy misunderstanding.
DELETE
FROM PhysLocTest.SeveralRows
WHERE PhysLocTest.SeveralRows.%%physloc%%
NOT IN (SELECT MIN(b.%%physloc%%)
FROM PhysLocTest.SeveralRows b
GROUP BY b.Category);
SELECT *
FROM PhysLocTest.SeveralRows a
ORDER BY a.Category;
Id InsertTime Category
9 2011-02-19 0
5 2011-02-19 1
6 2011-02-19 10
2 2011-02-19 2
1 2011-02-19 3
3 2011-02-19 4
21 2011-02-19 5
14 2011-02-19 6
10 2011-02-19 7
17 2011-02-19 8
16 2011-02-19 9
(11 row(s) affected)
Task accomplished, duplicates have been removed.
Conclusions
The %%physloc%% pseudo column helps to locate a physical row and dump the contents of the page. This is handy if you want to investigate the structure of the block or you want to find out the actual row where the data is stored. This pseudo column also helps in situations where you have to identify a single row even if you don't have a key defined on the table. In normal SQL Server usage, this column does not provide any improvements that could be used, for example, in programming. So never ever store the value of the physical location in a variable and try to use the value afterwards. No performance is gained, actually vice versa.
When migrating an application from Oracle, %%physloc%% can be used to replace ROWID, but some other approach, most likely a key, should be implemented as soon as possible in order to have decent response times.
Also keep in mind that the physical location of a row can change, for example, when clustered index is rebuilt. And of course, since this is an undocumented and unsupported feature, it may disappear in the next release of SQL Server.
History
- February 20, 2011: Created.

