This is a step-by-step guide to implementing Machine Learning, namely blending and stacking.
Introduction
Blending and stacking are model fusion approaches rather than traditional machine learning algorithm. Blending is utilized by the top-performers in Netflix, which is considered to be a form of stacking. Blending is more like an engineering method, thus, there are few equations in this article.
Blending Model
Blending Architecture
There are two layers in general blending model. In the first level, we create a small holdset from the original training set. The remaining training data are used to generate model to give a prediction for the holdset. In the second layer, employ the holdset as the training set to train the model in the second layer. The whole process of blending is shown below:
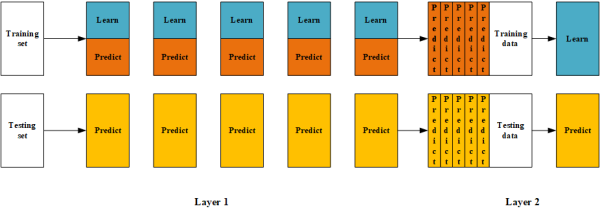
Figure 1. Blending architecture
Blending Implement
In the first layer of blending, there are several individual classifiers, which can be different or the same. All the classifiers generate a model using the blue data shown in Figure 1. Then, the trained models give predictions for the orange data, which will be employed as the training data in the second layer. The code of the first layer is shown below:
train_data1, train_data2, train_label1,
train_label2 = train_test_split(train_data, train_label, test_size=0.5, random_state=2019)
train_predict_feature = np.zeros((train_data2.shape[0], self.k))
trained_model = []
for j, clf in enumerate(self.classifier_set):
print(j, clf)
clf.train(train_data1, train_label1)
train_predict_feature[:, j] = clf.predict(train_data2)[:, 0]
trained_model.append(clf)
In the second layer, we use a single layer perceptron as the classifier. We train the classifier with the training data generated in the first layer, the code of which is shown below:
layer2_clf = PerceptronClassifier()
layer2_clf.train(train_predict_feature, train_label2)
Blending Classify
For the testing process of blending, they also have two layers. In the first layer, the testing set are inputted into the trained classifier in the first layer, namely, classifiers trained with the blue data. In the second layer, the predict results are input into the trained classifier in the second layer, namely, classifiers trained with the orange data. Then, the output is the final prediction. The testing code is shown below:
test_predict_feature = np.zeros((test_data.shape[0], self.k))
for j, clf in enumerate(self.layer1_classifier_set):
test_predict_feature[:, j] = clf.predict(test_data)[:, 0]
probability = self.layer2_classifier.predict(test_predict_feature)
Stacking Model
Stacking Architecture
Like blending, there are also two layers in a stacking model. In the first layer, the model are trained with cross-validation and give a prediction for a fold of data. In the second layer, all fold predictions are concatened as the prediction for the whole dataset. The predictions for each of the classifiers are fused to get the final prediction.

Figure 2. Stacking architecture
Stacking Implement
In the first layer of stacking, the training set is generated by cross-validataion. For a training set T, it will be divided equally into several subsets, namely, T ={t1, t2, ..., tk} . In the cross-validation process, each machine learning algorithm trains a submodel with (T - ti) as the blue data in Figure 1 and gives prediction for ti. Thus, for a k-fold cross-validation and n types of machine learning algorithm, there are a total of n x k submodels. Moreover, for each machine learning algorithm, it will give a prediction for the whole training set by concating each fold prediction. Thus, we can get a total of n predictions. The code of the first layer is shown below:
for j, clf in enumerate(self.classifier_set):
subtrained_model = []
for (train_index, test_index) in skf.split(train_data, train_label):
X_train, X_test = train_data[train_index], train_data[test_index]
y_train, y_test = train_label[train_index], train_label[test_index]
clf.train(X_train, y_train)
subtrained_model.append(clf)
prediction_feature[test_index, j] = clf.predict(X_test)[:, 0]
trained_model.append(subtrained_model)
Stacking Classify
In the second layer of blending, we use a classifier to fuse the predictions from the first layer. I perfer to introduce another fuse approach here rather than using a classifier again. There are some simple methods to fuse the predictions called Averaging, Voting and Weighing. Averaging is to calculate the average of the predictions as the final prediction. Voting is to choose the majority of the predictions as the final prediction. Weighing is to assign weights to difference source and calculate the weighted sum as the final prediction.
pre_prediction = np.zeros((test_data.shape[0], self.n_folds))
for j, sub_model in enumerate(self.trained_classifier_set):
sub_prediction_feature = np.zeros((test_data.shape[0], self.n_folds))
i = 0
for clf in sub_model:
sub_prediction_feature[:, i] = clf.predict(test_data)[:, 0]
i = i + 1
pre_prediction[:, j] = sub_prediction_feature.mean(1)
test_num = test_data.shape[0]
prediction = np.zeros([test_num, 1])
probability = np.zeros([test_num, 1])
if self.fusion_type == "Averaging":
probability = pre_prediction.mean(1)
elif self.fusion_type == "Voting":
probability = np.sum(pre_prediction, axis=1)/self.k
elif self.fusion_type == "Weighing":
w = [i/i.sum() for i in pre_prediction]
probability = np.sum(np.multiply(pre_prediction, w), axis=1)
prediction = (probability > 0.5) * 1
Conclusion and Analysis
Blending and stacking are different fusion methods, whose performance is affected by the chosen classifier. Thus, it's necessary to spend time on it. In this article, we use the below classifier set:
clfs = [PerceptronClassifier(), PerceptronClassifier(),
LogisticRegressionClassifier(), LogisticRegressionClassifier()]
Blending detection performance:
Stacking detection performance:
The detection performance is shown above. It is easy to learn that the detection performance is better than the others while the runtime is a little larger.
The related code and dataset in this article can be found in MachineLearning.
History
- 24th May, 2019: Initial version

