Introduction
Let us consider a simple thing: use some worker thread to compute a value. In the source code, it can look like that:
std::thread t([]() { auto res = perform_long_computation(); });
We would like to obtain the result when it is completed of course. But how to do it efficiently?
A shared variable can be used:
MyResult sharedRes;
std::thread t([&]() { sharedRes = perform_long_computation(); });
But that way, we need to know that the thread t is finished and sharedRes contain computed value; A lot of constructions can be used here: atomics, mutexes, condition variables, etc. but maybe there is a better and simpler way of doing that?
Let us have a look at this code:
auto result = std::async([]() { return perform_long_computation(); });
MyResult finalResult = result.get();
Isn't that simpler? But what actually happened there?
The Future
In C++11 in the Standard Library, we have all sorts of concurrency features. As usual, we have threads, mutexes, atomics, etc. Fortunately for us, the library went further and added some higher level structures. In our example, we need to look at future and async.
If we do not want to get into much details, all we need to know is that std::future<T> holds a shared state and std::async allow us to run the code asynchronously. In our case, we can rewrite it to:
std::future<MyResult> result = std::async([]() { return perform_long_computation(); });
MyResult finalResult = result.get();
Thus result is not a direct value computed in the thread but it is some form of a guard that makes sure the value is ready when we call .get() method. All the magic (synchronization) happens underneath. Often it will simply block the calling thread and wait for the data (or exception).
This opens some interesting possibilities and we can start with Task Based Parallelism. We can now build some form of a pipeline where data flows from one side to the other, but in the middle computation can be distributed among several threads. Such constructions definitely deserve more investigation!
Below, there is a simple idea of the mentioned approach: you divide your computation into several separate parts, call them asynchronously and at the end collect the final result. It is up to the system/library to decide if each part is called on a dedicated thread (if available), or just run it on only one thread. This makes the solution more scalable.
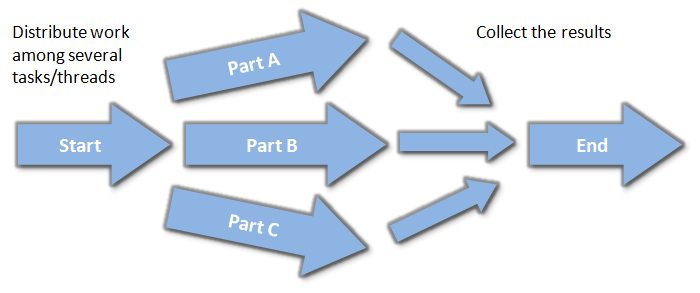
Notes
.get() can be called only once! The second time we will get exception. If you want to fetch the result from several threads or several times in single thread, you can use std::shared_future.std::async can run code in the same thread as the caller. Launch Policy can be used to force truly asynchronous call - std::launch::async or std::launch::deferred- when there is an exception in the future (inside our lambda or function), this exception will be propagated and rethrown in the
.get() method.
References
- See The C++ Standard Library: A Tutorial and Reference (2nd Edition), chapter 18.1 for a great introduction to the concurrency in
std. - See The C++ Programming Language, 4th Edition , chapter 41
- C++ Concurrency in Action: Practical Multithreading
History
- 14th October 2014 - added an image with Task Based Parallelism idea
- 20th January 2014 - minor changes
- 17th January 2014 - Initial version
Tip based on the original post at my site.

