Introduction
This article presents a generic solution, called ConcurrentPartitionedDictionary, which completes the previously posted article named ParititonedDictionary.
The presented solution creates a dictionary by adding KVPs to dedicated partitions. Such design achieves the following advantages:
- Less chances of OOM errors during dictionary resize operation.
- Capacity to hold even bigger KVP sets in memory which is otherwise not possible with C# ConcurrentDictionary.
- Less runtime memory consumption (partitions resize re-allocates lesser memory).
- Ability to define partition count at construction time (min value: 2, max value =
int.MaxValue). - In built Serialization/Deserialization capability (based on DataContractSerializer).
- Faster concurrent data population/reading/removing (based on some simulation on my laptop, however, users must perform such tests before going into production).
Background
I have listed most of the information in my previous article, please refer to Creating ParititonedDictionary. However, in this solution, I have changed the partitioning approach. The idea behind this new design is based on the following thoughts:
- Concurrent access to dictionary must not lock whole dictionary.
- If different keys accessed/inserted/removed by different threads, then creating memory-partitions will increase the speed as only the corresponding block of memory will be locked.
- Dictionary resize will be performed on individual partitions which are smaller than the whole dictionary itself, thus, achieving speed during such operations.
- Creation and use of this dictionary must be similar to .NET dictionary.
- User must not be bothered about how to design a good partitioned scheme based on the nature of possible key values.
- User must have the liberty to choose number of partitions a dictionary can have, to fine tune the performance based on his dataset.
This new design obviates the need of partition function, however, ambitious developer may like to have the ability to insert their own partitioning scheme and I would be happy to hear from them. And if they could prepare another such article with new design, I would appreciate their effort. Of course, what better than sharing new ideas.
Achieving Partitions
In the world of C#, object class is the mother of all. Exploiting this fact and the availability of GetHashCode() function makes things a bit easier. As GetHashCode() always returns int, creating number of required partitions is achieved by modulo operation. To make things simple, let's consider an example:
Let's say someone requires the dictionary to be partitioned into 10 parts and dictionary key type is TKey. Once I have an instance of TKey (say defined by variable name key), all I would do is: ((uint)key.GetHashCode()) % 10. Where % is modulo operator and uint casting is required due to negative int values.
Thus, the Ctor of ConcurrentPartititonedDictionary is O(n) operation (as Ctor creates n dictionaries), where n is number of partitions required. In the proposed solution, I have imposed a minimum limit of 2 on partitions, otherwise, better to have a C# ConcurrentDictionary than to have proposed dictionary with single partition.
Code Dissection
The Ctor of ConcurrentPartitionedDictionary is written as follows (please find comments in code block for each operation):
public ConcurrentPartititonedDictionary(int totalParititonRequired = 2,
int initialCapacity = 0,
IEqualityComparer<TKey> keyEqualityComparer = null)
{
_totalPartition = Math.Max(2, totalParititonRequired);
_internalDict = new Dictionary<TKey, TValue>[_totalPartition];
initialCapacity = Math.Max(0, initialCapacity);
if (initialCapacity != 0)
{
int initCapa = (int)Math.Ceiling(((double)initialCapacity) / _totalPartition);
Parallel.For(0, _totalPartition, i =>
{
_internalDict[i] = new Dictionary<TKey, TValue>(initCapa, keyEqualityComparer);
});
}
else
{
Parallel.For(0, _totalPartition, i =>
{
_internalDict[i] = new Dictionary<TKey, TValue>(keyEqualityComparer);
});
}
}
Following dictionary related operations are implemented in the solution:
public bool TryAdd(TKey key, TValue value);
public bool TryRemove(TKey key, out TValue value);
public bool TryGetValue(TKey key, out TValue value);
public TValue GetOrAdd(TKey key, TValue value);
public bool TryUpdate(TKey key, TValue newValue, TValue comparisonValue);
public TValue this[TKey key] { get; set; }
public bool ContainsKey(TKey key);
public void Clear();
public long Count { get; }
public bool TryAdd(KeyValuePair<TKey, TValue> item);
public IEnumerable<KeyValuePair<TKey, TValue>> GetEnumerable();
In order to fulfill the need of serialization/deserialization, the solution provides instance methods named Serialize and DeserializeAndMerge. The implementation of these methods is DataContractSerializer based, however, one can easily modify these methods to adopt other possible means for such operation. In its current form, these methods are capable to serialize/deserialize data either as XML or as JSON. The implementation of Serialize is shown below:
public void Serialize(FileInfo serialFile,
SerializationType serialType = SerializationType.Json)
{
serialFile.Refresh();
if (!serialFile.Exists)
{
serialFile.Directory.Create();
}
for(int i = 0; i< _totalPartition; i++)
{
Monitor.Enter(_internalDict[i]);
}
if (serialType == SerializationType.Xml)
{
using (var writer = new FileStream(serialFile.FullName, FileMode.Create, FileAccess.Write))
{
var ser = new DataContractSerializer(_internalDict.GetType());
ser.WriteObject(writer, _internalDict);
}
}
else
{
using (var writer = new FileStream(serialFile.FullName, FileMode.Create, FileAccess.Write))
{
var ser = new DataContractJsonSerializer(_internalDict.GetType());
ser.WriteObject(writer, _internalDict);
}
}
for(int i = 0; i< _totalPartition; i++)
{
Monitor.Exit(_internalDict[i]);
}
}
DeserializeAndMerge method after deserializing the data, merges all KVP pairs to the current instance. Merging of data is important because GetHashCode() return values may change (Object.GetHashCode Method) which will change the partition of KVP. Is such a situation, even if the KVP exists, TryGetValue will return false and indexer property will throw errors. One can also develop DeserializeAndMergeWithUpdate method if required, in order to update exiting key values. For such function, instead of calling TryAdd, one needs to call Indexer set property. Anyway, the current implementation of this method is as follows:
public void DeserializeAndMerge(FileInfo serialFile,
SerializationType serialType = SerializationType.Json)
{
serialFile.Refresh();
if (!serialFile.Exists)
{
throw new FileNotFoundException("Given serialized file doesn't exist!");
}
Dictionary<TKey, TValue>[] deserialDict;
if (serialType == SerializationType.Xml)
{
using (var reader = new FileStream(serialFile.FullName, FileMode.Open, FileAccess.Read))
{
var ser = new DataContractSerializer(_internalDict.GetType());
deserialDict = (Dictionary<TKey, TValue>[])ser.ReadObject(reader);
}
}
else
{
using (var reader = new FileStream(serialFile.FullName, FileMode.Open, FileAccess.Read))
{
var ser = new DataContractJsonSerializer(_internalDict.GetType());
deserialDict = (Dictionary<TKey, TValue>[])ser.ReadObject(reader);
}
}
Parallel.For(0, deserialDict.Length, index =>
{
Parallel.ForEach(deserialDict[index], kvp => TryAdd(kvp));
});
}
One must note the following points:
- If during serialization, total partitions were
N and while calling DeserializeAndMerge, total partitions are M, the data will be merged to this M partitioned dictionary without any error. Thus, one can also see these methods pairs as partition resizing operation (NOTE: Do not change the TKey and TValue types, of course it won't work). - If
TKey and/or TValue are custom classes/struct or any other complex DataType, then to avoid any error during serialization/deserialization, one must prudently make use of DataContract and DataMember attributes and if required, KnownTypeAttribute. Below are some useful links to understand how DataContractSerialization works.
Comparision with C# ConcurrentDictionary
The code below not only shows the use of ConcurrentPartitionedDictionary but also does some performance tests against C# ConcurrentDictionary (CD). To perform these tests:
- First, I created a shuffled array of integer values between 0 and 10M.
- Then, I created
ConcurrentPartitionedDictionary<int, int> with 10 partitions and a normal ConcurrentDictionary<int, int>. - Using
Parallel.ForEach loop, I added these 10M shuffled values as Keys and Values, lookup all keys using get Indexer and finally deleting all KVPs. - For each such operation, I used
Stopwatch to measure time in milliseconds. - In addition, using
GC.GetTotalMemory(true), I measured memory consumption before and after dictionary creation to find out the memory consumed by the dictionary instance. - All these statistics are then printed to the console blackboard.
The code snippet to perform above mentioned steps is as follows:
using System;
using System.Collections.Generic;
using System.Collections.Concurrent;
using System.Diagnostics;
using System.Linq;
using System.Threading;
using System.Threading.Tasks;
using PartitionedDictionary;
namespace Test
{
class Program
{
private const int totalRandomValues = 10000000;
static void Main(string[] args)
{
var totalPartition = 10;
var partitionedDictionary = new ConcurrentPartititonedDictionary<int, int>(totalPartition);
var concurrentDictionary = new ConcurrentDictionary<int, int>();
Console.WriteLine("Preparing Random Array of 10M values...please wait...");
var randomGenerator = new Random();
var listForShuffledArray = new List<KeyValuePair<double, int>>(totalRandomValues);
foreach (var i in GetInt())
{
listForShuffledArray.Add
(new KeyValuePair<double, int>(randomGenerator.NextDouble(), i));
}
Console.WriteLine("Array is ready...suffling it...please wait...");
var arr = listForShuffledArray.AsParallel().OrderBy
(x => x.Key).Select(x => x.Value).ToArray();
listForShuffledArray.Clear();
listForShuffledArray = null;
GC.Collect();
GC.WaitForPendingFinalizers();
Console.WriteLine("");
Console.WriteLine
("#########################################################################");
Console.WriteLine
("########################## Concurrent Dictionary ########################");
Console.WriteLine
("#########################################################################");
Console.WriteLine("");
var sizeBeforeDictPopulation = GC.GetTotalMemory(true);
var sw = Stopwatch.StartNew();
Parallel.ForEach(arr, i =>
{
concurrentDictionary[i] = i;
});
Console.WriteLine("Total millisecs to populate 10M KVPs: " + sw.Elapsed.TotalMilliseconds);
Console.WriteLine("Count after KVP adding: " + concurrentDictionary.Count);
var dictSize = GC.GetTotalMemory(true) - sizeBeforeDictPopulation;
sw = Stopwatch.StartNew();
Parallel.ForEach(arr, i =>
{
int l;
concurrentDictionary.TryGetValue(i, out l);
});
Console.WriteLine("Total millisecs to read 10M KVPs: " + sw.Elapsed.TotalMilliseconds);
sw = Stopwatch.StartNew();
Parallel.ForEach(arr, i =>
{
int l;
concurrentDictionary.TryRemove(i, out l);
});
Console.WriteLine("Total millisecs to remove 10M KVPs: " + sw.Elapsed.TotalMilliseconds);
Console.WriteLine("Total MB used: " + (dictSize >> 20));
concurrentDictionary = null;
GC.Collect();
GC.WaitForPendingFinalizers();
Console.WriteLine
("#########################################################################");
Console.WriteLine("");
Console.WriteLine("");
Console.WriteLine
("#########################################################################");
Console.WriteLine
("########################## Partitoned Dictionary ########################");
Console.WriteLine
("#########################################################################");
Console.WriteLine("");
sizeBeforeDictPopulation = GC.GetTotalMemory(true);
Console.WriteLine("Total Partitions: " + totalPartition);
sw = Stopwatch.StartNew();
Parallel.ForEach(arr, i =>
{
partitionedDictionary[i] = i;
});
Console.WriteLine("Total millisecs to add 10M KVPs: " + sw.Elapsed.TotalMilliseconds);
Console.WriteLine("Count after KVP adding: " + partitionedDictionary.Count);
dictSize = GC.GetTotalMemory(true) - sizeBeforeDictPopulation;
sw = Stopwatch.StartNew();
Parallel.ForEach(arr, i =>
{
int l;
partitionedDictionary.TryGetValue(i, out l);
});
Console.WriteLine("Total millisecs to read 10M KVPs: " + sw.Elapsed.TotalMilliseconds);
sw = Stopwatch.StartNew();
Parallel.ForEach(arr, i =>
{
int l;
partitionedDictionary.TryRemove(i, out l);
});
Console.WriteLine("Total millisecs to remove 10M KVPs: " + sw.Elapsed.TotalMilliseconds);
Console.WriteLine("Total MB used: " + (dictSize >> 20));
Console.WriteLine("Count after KVP removal: " + partitionedDictionary.Count);
Console.WriteLine
("#########################################################################");
Console.ReadLine();
}
public static IEnumerable<int> GetInt(int i = 0, int j = totalRandomValues)
{
while (i < j)
{
yield return i++;
}
}
}
}
Following is the config of my poor laptop running on Windows 7:

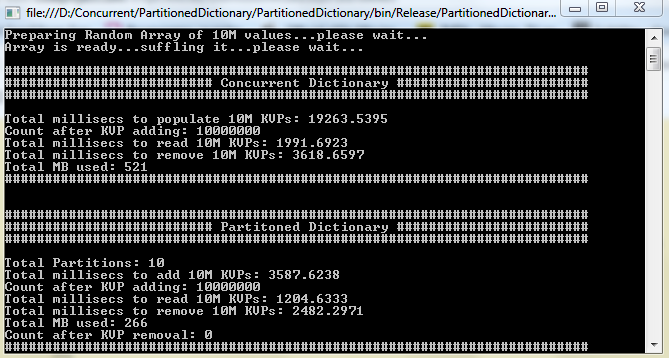
Below is the snapshot of the program output. Following points can be noted:
- Memory consumption was 266MBytes (
PartitionDictionary) Vs 521MBytes (ConcurrentDictionary) - KVP population time was 3.587 Secs (
PartitionDictionary) Vs 19.263 Secs (ConcurrentDictionary) - KVP lookup time was 1.204 Secs (
PartitionDictionary) Vs 1.991 Secs (ConcurrentDictionary) - KVP removal time was 2.482 Secs (
PartitionDictionary) Vs 3.618 Secs (ConcurrentDictionary)
However, one must not forget that these stats are based on the runtime randomness in the inserted KVPs. As we say, every good programmer MUST always be suspicious about any performance claim and must do her/his part of due diligence before accepting such claims (what about adding sorted data? Hmm!!!).
Points of Interest
In this article, we learnt that dividing dictionary into smaller ones (I call those partitions, as I was inspired by ORACLE DB partitioning based on TIMESTAMP and was looking for something similar to use in C# but bit more generic. As a matter of fact, I was recently working on a project in which we need to hold several huge KVP sets in the memory during app runtime as the app was extremely performance critical and time to time we were recording OOM errors in our logs). And we see (hope users of this lib will also make an accord), that such design can be beneficial performance wise, also, it can help reducing memory consumption (specially when either memory is costly for you or your app is designed for x86 platforms and you have no choice than keeping runtime memory limited to mere 2-2.5 GBytes, LA aware, else 1-1.5 GBytes only).
I am all ears to all the folks out there who might show their interest in reading the plethora above. Please do let me know any suggestion/correction in the code above, I would sincerely appreciate your efforts.
History
- This is V1 of the suggested solution.

