Introduction
Parsing HTML documents is a task that may be needed sometimes to be done in applications, but it is (somehow) a tedious task. In this tip, I will show how easy it could be using NSoup and ExCSS libraries.
NSoup is a HTML parser. As described in its website, its main features include:
- jQuery-like CSS selectors for finding and extracting data from HTML pages
- Sanitize HTML sent from untrusted sources
- Manipulate HTML documents
At the time of writing this tip, the current version is 0.7.1 but this version has some serious issues so I downloaded and compiled its source code (which is 0.8.0.0). This version does not have the issues I faced when using the previous one.
The second library is ExCSS (Pronounced Excess). It is a CSS 2.1 and CSS 3 parser for .NET. Its website mentioned "The goal of ExCSS is to make it easy to read and parse stylesheets into a friendly object model with full LINQ support".
We use ExCSS to extract CSS rules and classes from HTML documents.
Using the Code
To add NSoup to our project, we have to add a reference to NSoup.dll. There is not a NuGet package available yet so the process in manual. Unlike NSoup, ExCSS has NuGet package. Using the following command in Visual Studio Package Manager Console window, we can add it to our project:
install-package excss
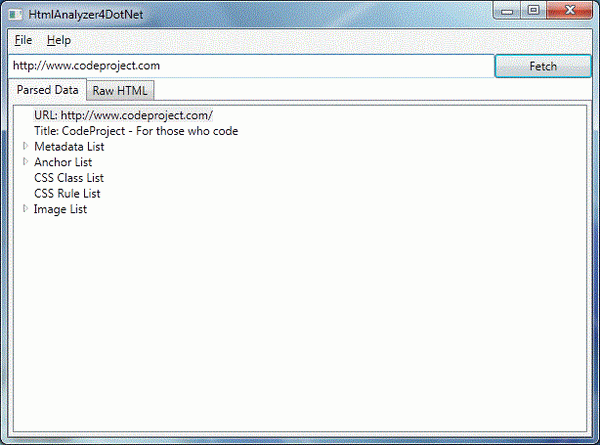
When the used libraries are set up, the fun part begins (CODING!!!). The corresponding project (HtmlAnalyzer4DotNet) is a WPF application that takes a URL, fetches its HTML document and extracts different types of data from the HTML document. It is developed and tested using Visual Studio 2012 and Microsoft .NET 4.5.
To begin, we have to declare a simple class that holds extracted pieces of data:
public class HtmlData
{
public string Url { get; set; }
public string RawHtml { get; set; }
public string Title { get; set; }
public List<string> MetadataList { get; set; }
public List<string> AnchorList { get; set; }
public List<string> ImageList { get; set; }
public List<string> CssClassList { get; set; }
public List<string> CssRuleList { get; set; }
public HtmlData()
{
MetadataList = new List<string>();
AnchorList = new List<string>();
ImageList = new List<string>();
CssClassList = new List<string>();
CssRuleList = new List<string>();
}
public void Clear()
{
Url = null;
RawHtml = null;
Title = null;
MetadataList.Clear();
AnchorList.Clear();
ImageList.Clear();
CssClassList.Clear();
CssRuleList.Clear();
}
}
The main part is done inside Fetch method. The method is a member method of class MainWindow (It can be found inside MainWindow.xaml.cs).
The operation begins with connecting to the specified URL and fetching the HTML data:
IConnection connection = NSoupClient.Connect(txtUrl.Text);
connection.Timeout(30000);
Document document = connection.Get();
The first line connects to the server which is specified by txtUrl.Text property and a connection object is returned. The second line sets the time to wait (in milliseconds) for fetching data before a timeout exception is raised. In our example, we wait 30 seconds to receive data.
The last line fetches data and creates a Document object. This object contains all pieces of information we need.
In order for NSoup types to be recognized, its namespaces must be imported at the beginning of the file:
using NSoup;
using NSoup.Nodes;
Now we have to parse HTML data to extract data we are looking for. We have created an instance of HtmlData class called parsedData. To fill Url, RawHtml and Title properties, nothing special is required:
parsedData.Url = document.BaseUri;
parsedData.RawHtml = document.Html();
parsedData.Title = document.Title;
To find HTML tags inside the document, you can use your CSS skills. Document class contains a useful method called Select which accepts CSS-selector queries and returns a collection of matching elements. Each item of the collection is of type Element. To find all <meta> tags, we can write the following code line:
var metaTagList = document.Select("meta");
Now to add all meta tags to parsedData object, the following code snippet is used:
foreach (Element meta in document.Select("meta")) parsedData.MetadataList.Add(meta.OuterHtml());
Element.OuterHtml() methods returns the entire HTML code related to the element (including opening and closing tags) so the preceding loop adds all HTML meta tags to parsedData object.
Similarly, we can find all image and anchor tags:
foreach (Element image in document.Select("img"))
parsedData.ImageList.Add(image.Attr("src"));
foreach (Element anchor in document.Select("a"))
parsedData.AnchorList.Add(anchor.Attr("href"));
Element.Attr() returns the value of a certain attribute.
So far so good. Now let's do something a bit more challenging. Let's gather CSS information. We will gather two types of CSS-related data:
- CSS classes (those which start with a dot)
- CSS rules (everything else)
To do so, we have to first find all HTML <style> tags and parse their inner HTML code using ExCSS parser object.
To use ExCSS, an instance of Parser class must be created. Parser class has a method called Parse(). The method accepts a string which must be a CSS document and returns an object of type StyleSheet. By using StyleSheet properties, different sorts of data can be retrieved from the parsed CSS document.
We iterate over CSS rules. Each rule which is a simple selector and starts with a "." is a CSS class.
Parser parser = new Parser();
foreach (Element style in document.Select("style"))
{
foreach (StyleRule rule in parser.Parse(style.Html()).StyleRules)
{
if (rule.Selector is SimpleSelector && rule.Value.StartsWith("."))
parsedData.CssClassList.Add(rule.ToString());
else
parsedData.CssRuleList.Add(rule.ToString());
}
}
So far, we have collected everything we were interested about. Now it is time to populate the UI with the data. There is a TextBox (txtRawHtml) that should display the raw HTML document. Then there is a TreeView (treeParseData) which should display other pieces of data. Tree items that contain images, must act as a link to display their images in a popup window when the user clicked on them. The following code snippet shows how to fill the UI:
txtRawHtml.Text = parsedData.RawHtml;
treeParseData.Items.Add("URL: " + parsedData.Url);
treeParseData.Items.Add("Title: " + parsedData.Title);
treeParseData.Items.Add(new TreeViewItem
{ Header = "Metadata List", ItemsSource = parsedData.MetadataList });
treeParseData.Items.Add(new TreeViewItem
{ Header = "Anchor List", ItemsSource = parsedData.AnchorList });
treeParseData.Items.Add(new TreeViewItem
{ Header = "CSS Class List", ItemsSource = parsedData.CssClassList });
treeParseData.Items.Add(new TreeViewItem
{ Header = "CSS Rule List", ItemsSource = parsedData.CssRuleList });
TreeViewItem imageList = new TreeViewItem { Header = "Image List" };
foreach (string imageUrl in parsedData.ImageList)
{
TreeViewItem item = new TreeViewItem { Header = imageUrl, Cursor = Cursors.Hand };
item.MouseDoubleClick += (sender1, e1) =>
{
new ImageViewerWindow(
imageUrl.StartsWith("/") ? parsedData.Url.Remove(parsedData.Url.Length - 1) +
imageUrl : imageUrl
).ShowDialog();
};
imageList.Items.Add(item);
}
treeParseData.Items.Add(imageList);
Summary
In this tip, I tried to introduce you to NSoup and ExCSS libraries that I found useful when it is needed to deal with HTML documents. As you can probably guess, what we did was just scratching the surface. Both libraries have more capabilities than what we discussed in this short tip. For example, you can also manipulate HTML documents using NSoup.

