If you are not very good at something, then make yourself write about to really know it.
Big O Notation is a way of expressing the upper-bound complexity of an algorithm. Seemingly minor changes can have major affects on an algorithms performance. At the surface level, these differences can seem insignificant but when time is of essence and every millisecond matters, say in a stock trading application, or when crunching large quantities of data, those minor changes can have huge affects. Whether your team mentions big O notation regularly, just in interviews, or never it is part of the fundamentals that can mean the difference between being a pretty good coder and a great software engineer.
If you are a visual learner like me, then this will speak volumes about how little change can have big results:
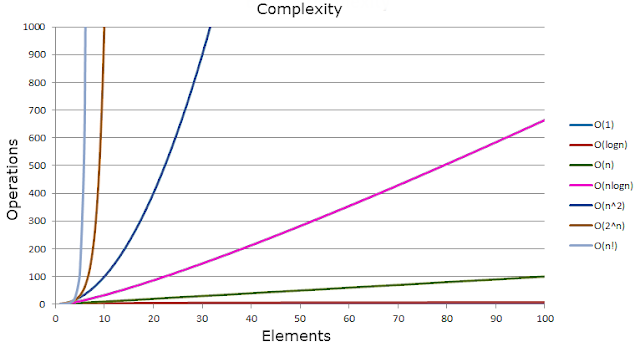
Scalability in Words Not Pictures
An O(1) algorithm scales the best and scales better than an O(log N) algorithm,
which scales better than an O(N) algorithm,
which scales better than an O(N log N) algorithm,
which scales better than an O(N2) algorithm,
which scales better than an O(2N) algorithm.
Examples of Big-O scalability
O(1) has no growth curve. An O(1) algorithm's performance is independent of the size of the data set on which it operates. So this implies a constant speed which doesn't necessarily mean fast depending on what the algorithm is doing.
O(N) says that the performance is directly related to the size of the data set such as searching a linked list but since Big-O is the worst case, the element you are trying to find is at the end. If someone talks about O(2N), they are talking more about the implementation details vs the growth curve.
O(N+M) is a way of saying that two data sets are being accessed and that their combined size determines performance.
O(N2) says that the algorithm's performance is proportional to the square of the data set size. This happens when the algorithm processes each element of a set, and that processing requires another pass through the set such as the famous bubble sort is O(N2).
O(N*M) indicates that two data sets are involved but processing each element requires the processing of the second data set. Don't get sloppy and use O(N2) if the data sets are about the same size.
O(N3) and beyond means lots of inner loops.
O(2N) means you have an algorithm with exponential time behavior. There's also O(100N), etc. In practice, you don't need to worry about scalability with exponential algorithms, since you can't scale very far unless you have a very big hardware budget.
O(log N) and O(N log N) might seem a bit scary, but they're really not. These generally mean that the algorithm deals with a data set that is iteratively partitioned, like a balanced binary tree.
Don't be scared of the Big-O
Talk of Big-O notation can be of the tactics employed by hot shot programmers who are trying to increase their credibility. Big-O isn't something to be scared of it is just another tool and once you understand the tool, you can wield it like a Jedi using her lightsaber.
Big-O isn't just about the CPU
While it is true the vast majority of time Big-O is discussed, it is in regards to computing cycles, disk usage or memory consumption can also be referenced by Big-O notation. However unless otherwise stated speed, raw CPU horsepower, is what people are referring to.
Big-O embarrasses the worst case
When Big-O is discussed, it is assumed you are talking about the worse case scenario of hitting the upper-bound complexity. For example, there is really no point in worrying about the CPU time it would take to sort and already sorted list but a list in reverse order is a different matter entirely. In interviews, it can't hurt to mention "worst case complexity to add to your credibility.
Big-O doesn't have time for little numbers
In Big-O, you really don't care about the lower ordered values because as N gets larger enough those lower ordered terms get less significant. Constants are also irrelevant want talking about Big-O. A one time call that takes 20 seconds for a response may seem like a big deal when the entire operation takes 23 seconds to process 300 data elements but when you are talking about 3,000,000 elements that one time 20 seconds call becomes trivial.
What is Big-O good for?
So what is all this Big-O stuff good for besides intimidating and strutting your computer science chops around? Performance. Time is money. If something is slower, it can hurt the user experience. If something is slower, you need more servers, more powerful, or more and more powerful servers to keep the run time in a reasonable time frame. Features are generally what sells but performance keeps users. Startups will often worry about features first and then performance but as they mature that performance concern becomes greater and greater. Discussing and thinking about Big-O notation and the complexity of algorithms will help train your mind to think performance even when focusing on features.
Some keys to a successful Software Engineering hunting
CodeProject

