I think that the debate “C vs C++” will end when the two languages die, and each one has its advantages and inconveniences, the choice of one instead of another depends on the application context.
Recently, I read a famous linus torvalds opinion about C++, where he wrote:
“C++ is a horrible language. It’s made more horrible by the fact that a lot of substandard programmers use it, to the point where it’s much much easier to generate total and utter crap with it. Quite frankly, even if the choice of C were to do *nothing* but keep the C++ programmers out, that in itself would be a huge reason to use C.”
I decide to do a quick analysis of Linux using CppDepend and try to understand the Linus opinion.
CppDepend can analyse Visual Studio projects without any configuration, but if the build process is described by another build processing system like Makefile, SCONS, CMake or others, the solution is to use the ProjectMaker to describe the project to be analyzed.
For Linux, we can use ProjectMaker to describe projects to analyze.
Linux code source contains many directories, and to have a clear vision of code source, we will associate each directory to a project.
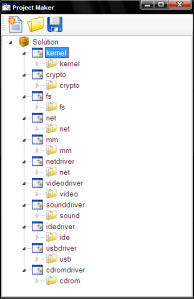
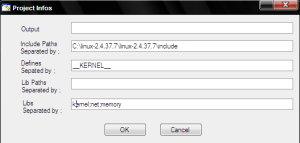
And for each project, we can specify other information:
C vs C++ Comparison
Modularity: Physical vs Logical
Modularity is a software design technique that increases the extent to which software is composed from separate parts, you can manage and maintain modular code easily.
We can modularize a project with two approaches:
- Physically: by using directories and files, this modularity is provided by the operating system and can be applied to any langage
- Logically: by using namespaces, component, classes, structs and functions, this technique depends on the language capabilties.
When we develop with C, and to package our code, we use essentially physical modularity, for example, for Linux, each module is isolated in directory and each file contains structs, variables and methods relative to a specific functionality.
This dependency graph shows relation between some linux directories:
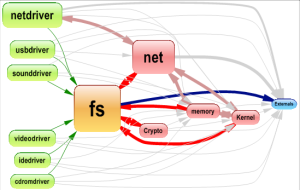
C++ instead of C can use namespaces and classes to modularize the code, those types are provided by the language, and for the previous graph, we can use namespaces to modularize our code instead of directories.
C++ provides an efficient way to modularize the code base, but why namespaces artifacts are not enough used? For example, only some C++ open source projects use it, maybe it’s due to historical reason or maybe we use “C with Classes” where the C habits are all the time present instead of modern C++.
What the Difference between the Two Approaches?
Lisibility: the logical approch is better, because we can understand and use easily the code, and we don't need to know the physical emplacement of a code element.
Managing changes: a good design need in general many iterations, and for the physical approach, the impact of design changements can be very limited than logical one, indeed we need only to move function or variable from a file to another, or move file from directory to another.
However for C++, it can impact a lot of code because the logical modularity is implemented by the langage artifacts and a code modification is needed.
Encapsulation: Class vs File
For C++, the encapsulation is defined as the process of combining data and functions into a single unit called class. Using the method of encapsulation, the programmer cannot directly access the data. Data is only accessible through the functions present inside the class.
For C, we can have an encapsulation but using also a physical approach as described in the modularity section, and a class can be a file containing functions and data used by them, and we can limit the accessibility of functions and variables by using “static” keyword.
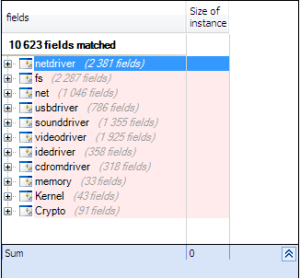
Linux uses this technique to hide functions and variables, to discover that we can search for static function:
SELECT METHODS WHERE IsStatic
and also, we can search for static variables:
SELECT FIELDS WHERE IsStatic
Lisibility: Using C++ encapsulation mechanism improves the understanding and lisibility of code, C is low level and uses a physical approach rather than logical.
Managing changes: If we have to change the place where variable or function are encapsulated, it can be very easy for C, but for C++, it can impact a lot of code.
Polymorphism vs Selection Idiom
Polymorphism means that some code or operations or objects behave differently in different contexts.
This technique is very used in C++ projects, but what about C?
For procedural languages, the selection techniques by using the keywords “switch”, “if” or maybe “goto” can simulate the polymorphism behavior, but this technique tends to increase cyclomatic complexity of code.
Let’s search for complex function and see if the polymorphism can minimize the complexity.
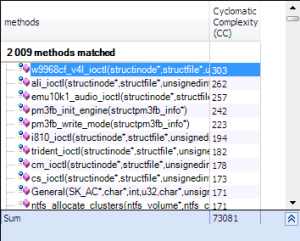
The more complex function w9968cf_v41_ioctl uses a big switch to differentiate a behavior that depends on a specific command, with C++ we can use polymorphism and command pattern to minimize the complexity of this code.
Lisibility: Using Polymorphism permits the isolation of a specific behavior to a class, it improves the visibility of the code.
Managing changes: Adding another behavior with polymorphism can imply the adding of another class, however with selection idiom, you can add only another case under the switch statement.
Inheritance vs Agregation
Linux uses essentially structs to define data manipulated by functions.
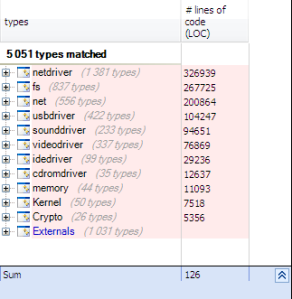
Let’s search for all structs used:
SELECT TYPES WHERE IsStructure
but what happened when struct has a common data as another, for example, many structs can be considered as “inode” with adding some other fields, in this case, the aggregation is used instead of inheritance, let’s search for structs using “inode”.
SELECT TYPES WHERE IsDirectlyUsing "inode"
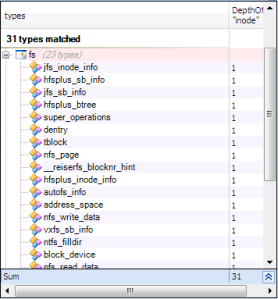
Some structs using inode can be inherited from it, but the aggregation technique is used instead.
Lisibility: Using inheritance can improve the understanding of data, but we have to be careful when using it, it's used only for the “Is” relation.
Managing changes: Inheritance implies a high coupling so any changes can impact a lot of code.
Conclusion
C++ provides a better lisibility but any changes or refactoring can be difficult, and Linus talks about this idea of design changement in the same post:
“inefficient abstracted programming models where two years down the road you notice that some abstraction wasn’t very efficient, but now all your code depends on all the nice object models around it, and you cannot fix it without rewriting your app.”
But doing refactoring needs to understand the existing code and design before making changes, and C program is very difficult to understand but easy to change, however C++ can be more lisible than C but needs some effort when making changes.
How we can limit the impact of changes for C++?
The good solution to limit the impact of changements is to use patterns, especially low coupling concept to isolate changements only in a specific place, Irrlicht as explained in the previous post is a good example of using low coupling.

