Introduction
What I really love about consulting is the variety of projects that come my way. Recently, I was asked if we could create an application for a client which allowed them to fill in a PDF and store the data in a database.
Background
I looked around and found several different libraries for dealing with PDF files, I do not mean to say I did an exhaustive search or trial. Almost all these libraries touted their ease of use in creating PDF documents in code, many offered capabilities of reading the documents but almost all of them failed to load a document created with Adobe Acrobat, opening only older unencrypted PDF files.
The one exception I found was iTextSharp, a library from http://itextpdf.com/ which offers both a commercial version with iText support provided and an open source version available with a copy left AGPL license.
Using the Code
After downloading the code, you will need to use Nuget to download both the iTextSharp and SQLite packages. Please note the licensing requirements for each.
The project was developed on Visual Studio 2015, targeting .NET version 4.5 but has been tested using Visual Studio 2013 as well.
The included software was the solution which worked for our client. It is a Windows service which looks for PDF files to be dropped (using FileSystemWatcher) or modified to a certain location, reading both a form field collection and page content tokens.
The form field collection is saved as a key value pair in a SQLite database table, the name of the field as the key and its data as the value.
The project consists of four projects and a deployment project to help install:
SaveToDB – Contains the program runner, looking for files to be dropped and saved to the databaseDataClass – Supplies methods to read and write to the database, it supports both SQLite calls as well as Microsoft SQL Server. Use providerName="SQLite" in connection string to save to SQLite database, otherwise it will default to SQL ServerLoggerClass – Simplified logging routinesPDFScanner – A Windows service project which bootstraps a program runner and contains the installer for installutil.exe
(The logger and the configuration manager are instantiated here and injected into the runProgram function of the ProgramRunner class.)
NameValueCollection cfg = ConfigurationManager.AppSettings;
ProgramRunner pr = new ProgramRunner();
ILogger lg = new Logger((Logger.LogLevel)Enum.Parse
(typeof(Logger.LogLevel), cfg["LogLevel"]), cfg["LogLocation"], "logDB.txt");
pr.runProgram(lg, cfg);
The main processing is enclosed in a using statement, and processes for each file being dropped or changed in the folder.
PdfReader has twelve different overloads, the overload I chose was to open a file directly from disk. The using statement ensures all resources associated with the PdfReader will be closed and unallocated correctly.
foreach (string item in GetFilesToProcess())
{
string newFile = RenameFile(item);
using (PdfReader reader = new PdfReader(item))
{
}
}
While the PDF file is read, it is scanned for text and form fields. This section of code reads the first page, returning a StringBuilder object which can be matched with a Regular Expression for the form type saved in the database.
StringBuilder sb = new StringBuilder();
byte[] streamBytes = reader.GetPageContent(1);
PRTokeniser tokenizer = new PRTokeniser(new RandomAccessFileOrArray
(new RandomAccessSourceFactory().CreateSource(streamBytes)));
while (tokenizer.NextToken())
{
if (tokenizer.TokenType == PRTokeniser.TokType.STRING)
{
sb.Append(tokenizer.StringValue);
}
}
There is an option to scan the text using regular expressions, looking for matches to determine the form type. If there are no matches, it will look at the file name to determine the type and use the file name as the type.
Regex rx = new Regex(_cfg["FileTypeRegEx"]);
var group = rx.Match(sb.ToString()).Groups["one"];
string ftype = group.Value.ToString().Trim();
if (string.IsNullOrEmpty(ftype))
ftype = System.IO.Path.GetFileNameWithoutExtension(item);
I specify the search string in the application configuration file under the FileTypeRegEx key.
Because the configuration file is an XML document, characters which could be interpreted as tags must be escaped. Therefore:
“Number: (?<one>.+)Rev:” – find characters between Number: and Rev: and assign to group “one” must be re-written as - “Number: (?<one>>.+)Rev:”
<add key="FileTypeRegEx" value="Form Type: (?<one>\w+-\d+)" />
The AcroFields are read from the document and saved to the database using a parameterized query, AcroFields are across the whole document and are not referenced per page.
The following field data is saved in the database if the field has data:
File name, Field name, Field value, Field type, File type
foreach (var field in fields.Fields)
{
string fvalue = fields.GetField(field.Key.ToString()).ToString();
if (!string.IsNullOrEmpty(fvalue.Trim()))
{
_locallog.Log("insert data", "storage", Logger.LogLevel.Info);
while (!dbstuff.execCmdsNonQuery(sqldb, "insert into tstorage
(FileName,FieldName,FieldValue,FieldType,FileType) values
(@file,@field,@value,@type,@filetype)",
new SqlParameter[] { new SqlParameter("@file", newFile),
new SqlParameter("@field", fields.GetTranslatedFieldName(field.Key)),
new SqlParameter("@value", fvalue),
new SqlParameter("@type", fields.GetFieldType(field.Key).ToString()),
new SqlParameter("@filetype", ftype) }))
;
}
}
The table was defined using the following schema:
CREATE TABLE "TStorage" (
`FileName` TEXT NOT NULL,
`FieldName` TEXT NOT NULL,
`FieldValue` TEXT NOT NULL,
`FieldType` TEXT NOT NULL,
`FieldProcessed` INTEGER DEFAULT 0,
`FileType` TEXT,
PRIMARY KEY(FileName,FieldName)
)
The FileName field contains the name of the file AFTER it has been made unique by adding a timestamp (newFile).
FieldName is derived using fields.GetTranslatedFieldName(field.Key) and is the field name assigned in the PDF when the document was created.
FieldValue is the value filled in the field on the PDF, it is read using the method fields.GetField(field.Key.ToString()).ToString().
I have an extra field on the table which I use to help synchronize with other processes which might be reading from the database. FieldProcessed defaults to zero when inserting records and is updated to 1 using a set based update by file name when all records have been written for the file.
That way, another process cannot read partial loads. In addition afterwards, another process can mark the field with 2 to indicate the row is no longer needed and the service will delete them using a set base delete.
FieldType can be one of eight values and defines the type of field the data represents.
Pushbutton = 1, Checkbox = 2, Radiobutton = 3, Text = 4, List = 5, Combo = 6, Signature = 7 and None = 0.
The fileType is defined as text in the document itself. All of our PDFs included a form number which we used a regular expression to determine.
An Example of a PDF and What is Generated
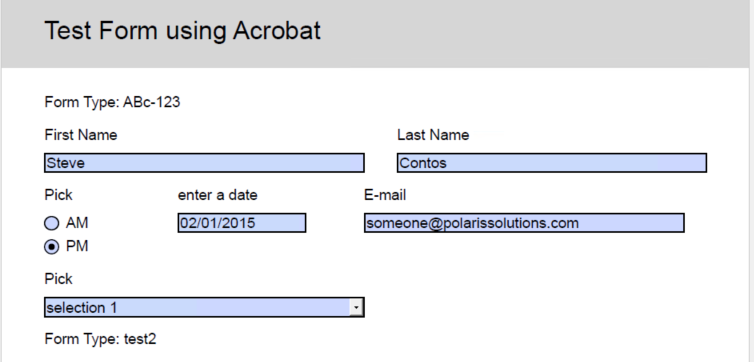
Creates the following set of records:

Each row specifying a field in the form. If you wanted a columnar representation, you would need to pivot the rows:
A second file of the same type will produce another line as such.
Notice, since I did not fill in the last name field, a row was not written and the column now returns NULL.
Points of Interest
Using iTextSharp was very easy, it has a plethora of helpful articles and examples and worked as expected the very first time. The effort was very successful and I hope this adds to the repository of useful examples of how to use this excellent package and that it might help in your endeavors.
The software for this example uses iTextSharp under the left AGPL license, I have included the requisite notifications, modifications and AGPL license file and location to get source code.
You will need to get packages using NuGet.
A commercial license provides advantages not available with the open-source AGPL license. Specific benefits include:
- Indemnification in the event of IP (intellectual property) or patent infringement
- Release from the requirements of the copyleft AGPL license, which include:
- distribution of all source code, including your own product (even for web-based applications)
- licensing of your own product under the AGPL license
- prominent mention and inclusion of the iText copyright and the AGPL license
- disclosure of modifications
- Release from the requirement to not change the PDF Producer line in the generated PDF properties
- Only commercial licensees have access to commercial iText support
History

