Introduction
One of the factors holding back adoption of the Command Query Responsibility Pattern (CQRS) and the related technology of event sourcing (ES) in the .NET community is the lack of tooling to generate and manipulate these models in a way that is familiar to users of Entity Framework - that is to say graphically by composition with the resulting model then turned into code.
This Visual Studio plug-in designer is an early attempt to bridge that gap. It allows you graphically to design domain models consisting of aggregate identifiers, events, projects, commands, queries and identity groups.
If you are not familiar with Event Sourcing, then I would suggest reading this article as a starting point, or if you have 45 minutes to spare, there is also this YouTube video.
Prerequisites
The designer library requires the use of the Visual Studio 2015 Visualization and Modelling SDK which is not installed by default - you will need to install it from here.

It also requires the following NuGet packages: "Microsoft.Net.Compilers", "Microsoft.CodeDom.Providers.DotNetCompilerPlatform", "System.Reflection" and "System.Runtime".
For Visual Studio 2017, you do not need to install the SDK separately from a link, but rather use the setup wizard to modify the install and add "Text Templating" and "Modelling" components under the "Extensibility" section.
Terminology
In the tool (and this article), the following terms are used. My usage may not map 100% to other CQRS documentation so a quick review of this is recommended before you proceed.
Aggregate Identifier
An aggregate identifier is a thing which can be uniquely identified and to which events can occur about which we are interested. This can correspond to a physical thing (like a car, office, person) or a logical entity in exactly the same way as an entity does in the entity relationship model.
Everything that happens is concerned with just one instance of just one type of aggregate identifier. In addition, every aggregate must have a unique identifier, or a system provided unique key (this could be an incremental integer or a GUID). This may be given a business-meaningful name if one exists or simply "Key" or "Identifier" if it does not.
An aggregate may have instance data members but in its purest form, these should only be related to identity (what the instance is) rather than any transitive state.
Event
An event is a record that something of interest happened to the object identified by the aggregate identifier.
Events are stored in order of occurrence and this allows for the most powerful aspects of event sourcing - the ability to recreate the state of your object as it was at any given point in time by replaying the events into it. (These views of the state of an aggregate when events are applied are generated by projections.)
Each event can only be linked to one aggregate identifier.
Each event type must have a unique name to be uniquely identifiable.
Behind the scenes, a sequence and timestamp property can be added to indicate the order in which events were recorded and the relation between this and real-world time.
Projection
A projection takes the stream of events that were recorded against a given aggregate identifier and uses them to create a view of the state of the object that the aggregate represents as at a given point in time.
A projection can only apply to one aggregation identifier. If you want to project the state of multiple aggregate identifiers, a separate projection must be run for each one but this is an entirely decoupled operation so can be performed in a highly parallel manner.
A projection can filter which events it does or does not process - events which have no impact on the state of the projection can be ignored. For events that are handled, the projection properties can be updated according to the properties of the event being handled.
Query definition / Query Handler
A query definition defines how you get information out of the system. The definition identifies the aggregate against which it will run, the return data type it will supply and any additional parameters to the query.
When designing the query definition, you should approach it from the user-experience point of view. In practice, this means concentrating on what (and how) the user wants to know and not what is available to tell them about.
When the code is generated for a query definition, separate classes are created for the definition and the handler. This allows the definition to be used as a model in an MVC (or MVVM) based application without it caring how the actual query processing occurs on the back end.
Command Definition / Command Handler
A command definition and handler is how you get information into the system or cause state changes to occur. The command has defined parameters that provide additional data payload to the system, and must uniquely identify the aggregate it is applied to.
Each command instance has a unique instance identifier which can be used to log the impact of the command.
Note that a command does not necessarily have to come from a human operative - anything that has intent to add an event or cause a state change can be expressed as a command.
When the code is generated for a command definition, separate classes are created for the definition and the handler. This allows the definition to be used as an input model in an MVC (or MVVM) based application without it caring how the actual command processing occurs on the back end.
Identity Group
An identity group is a business-meaningful grouping of zero or more aggregate identifier instances. Named identity groups are used so that query definitions and projections can be composed in a business centric manner.
For example, the identity group "Premier League" would identify a business meaningful collection of "Football team" instances, or the identity group "Non domiciled accounts" could identify a business meaningful collection of bank accounts.
Each Identity Group has its own underlying event stream with two very simple events in it - an IdentityAdded event which adds the identified aggregate to the list and an IdentityRemoved event which adds or removes items from the group. This event stream can be played to regenerate the membership of the group at any given point in time.
Membership of an identity group is evaluated by a specialized form of a projection known as a Classifier. This runs over the event streams of the aggregate identifiers to decide if they are in or out of the identity group.
Designing the Domain Model
To create a new domain model, select the "Add new item" menu in Visual Studio and select "CQRS DSL".
At this point, you can set the model-level properties to describe the domain being modelled.
From the initial empty model, the only thing you can add are new aggregate identifiers (as everything else is linked to an aggregate identifier). You select the aggregate identifier tool from the toolbox and drag it onto the diagram pane.
Having done this, you can set the properties for that aggregate identifier. In particular, you will want to set the key data type to describe how instances of the aggregate are to be uniquely identified and if that identifier has some business meaning, then you will also want to set the key name to reflect this.
The notes and description will be used to generate the documentation for your domain model so it is a good idea to put some detail into them as well.
The next step is to start adding events to the aggregate identifier - what can happen to it and what information can we note when this event does happen.
Add as many events as you can think of, whether or not you think they will be directly useful at this stage. The analysis session that is useful for this stage is often known as "event storming".
It is good practice to give the events a past-tense active name, and to use business-meaningful terms rather than describing things that happen in the computer system.
Once you have a good set of events defined, the next step is to define some projections which can turn these events into a "view" of the state of the aggregate at any given point in time. To do this, drag a projection from the toolbox onto the aggregate and set its properties.
Then connect up the events that this projection will process by using the projection event connector tool.
You add properties to the projection to hold the output properties you want to see in this view and for each event handled, you need to set how the properties are impacted by the event.
Query definitions and command definitions are added to the model in the same way:
For a command definition, you need to add all the input parameters that will be passed into the system to cause a state change.
For a query definition, you need to define the input parameters (if any) that will be passed in and the output properties that will be returned. A query can either be set to return a single record or, if you set the "Multi Row Results" flag to true, to return a collection.
Queries can specify an "identity group" over which they are run. This allows you to restrict the aggregates you want to run a query over to only the members of a business meaningful set (which is known as an identity group).
To define a new identity group, drag an identity group icon onto the aggregate identifier you want it to be a grouping of.
An identity group can be set as being a global group (which returns all the known instances of the aggregate) or as an individual (which returns the specified instance if it exists) - or for more complicated scenarios a classifier can be attached to the group.
A classifier is a function that runs over the events stream of an aggregate and decides whether that instance should be in or out of the group, according to functions performed when events in that stream are processed.
In a similar fashion to the projection, the classifier has operations it performs when an event is encountered. These evaluations determine if the aggregate is in or out of the identity group.
Code Generation
(See Download generated source for an example of the code generated from the model.)
There are currently two possible target languages for code generation from this CQRS model - C# or VB.NET. The target language as well as the target source code folder are properties that can be set for the domain model.
The code generation part of this project is housed in a separate project in the CodeGeneration folder. This is to allow you to make any customizations as you wish without having to rebuild and redeploy the whole tool.
To make the code generation process run, right click on the diagram pane of your CQRS model and in the resulting context menu, select the option "Generate Code". The code will be generated according to the model settings you have set - code language in either C# or VB.NET.
You will immediately notice that a very large number of code files are created. This is because every object in the model (aggregate identifier, event, query definition, etc.) is generated first as an interface and then as a partial concrete class implementing that interface. The idea behind this is to allow for unit testing by quickly mocking up whichever classes you want to for your tests.
For example, the code generated for an event definition would be:
Option Strict Off
Option Explicit On
Imports CQRSAzure
Imports CQRSAzure.Aggregation
Imports CQRSAzure.EventSourcing
Imports Football_League.Team
Namespace Football_League.Team.eventDefinition
Partial Public Class GamePlayed
Inherits Object
Implements IGamePlayed
#Region "Private members"
Private _Venue As String
Private _HomeTeamScore As Integer
Private _AwayTeamScore As Integer
#End Region
Sub New()
MyBase.New
End Sub
Sub New(ByVal GamePlayedInit As IGamePlayed)
MyBase.New
_Venue = GamePlayedInit.Venue
_HomeTeamScore = GamePlayedInit.HomeTeamScore
_AwayTeamScore = GamePlayedInit.AwayTeamScore
End Sub
Sub New(ByVal Venue_In As String,
ByVal HomeTeamScore_In As Integer,
ByVal AwayTeamScore_In As Integer)
MyBase.New
_Venue = Venue_In
_HomeTeamScore = HomeTeamScore_In
_AwayTeamScore = AwayTeamScore_In
End Sub
Public ReadOnly Property Venue() As String
Get
Return _Venue
End Get
End Property
Public ReadOnly Property HomeTeamScore() As Integer
Get
Return _HomeTeamScore
End Get
End Property
Public ReadOnly Property AwayTeamScore() As Integer
Get
Return _AwayTeamScore
End Get
End Property
End Class
End Namespace
The code for a projection includes the property operations you defined which update the projection properties when a given event is handled by the projection:
Option Strict Off
Option Explicit On
Imports CQRSAzure
Imports CQRSAzure.Aggregation
Imports CQRSAzure.EventSourcing
Imports Herd.Cow
Imports Herd.Cow.eventDefinition
Namespace Herd.Cow.projection
Partial Public Class Location
Inherits Object
Implements ILocation
#Region "Private members"
Private _In_Shed As Boolean
Private _Location As String
#End Region
Public ReadOnly Property In_Shed() As Boolean Implements ILocation.In_Shed
Get
Return _In_Shed
End Get
End Property
Public ReadOnly Property Location() As String Implements ILocation.Location
Get
Return _Location
End Get
End Property
Public Overloads Sub HandleEvent(ByVal eventToHandle As IMoved_To_Field) _
Implements CQRSAzure.EventSourcing.IHandleEvent(Of IMoved_To_Field).HandleEvent
_In_Shed = False
_Location = eventToHandle.Moved_To
End Sub
Public Overloads Sub HandleEvent(ByVal eventToHandle As IMoved_To_Shed) _
Implements CQRSAzure.EventSourcing.IHandleEvent(Of IMoved_To_Shed).HandleEvent
_In_Shed = True
_Location = eventToHandle.Shed_Name
End Sub
End Class
End Namespace
In addition, the description and notes settings you filled in on your diagram (if not blank) are added to the class as code tag comments so that they will go in the remarks section if you use a tool to generate documentation from the comments.
You can also specify that one of the date properties for an event is the effective date which means that this property can be used when performing any "as of a given point in time" queries over that event stream. This gets tagged onto the generated code for the event as an attribute:
[CQRSAzure.EventSourcing.EventAsOfDateAttribute()]
public System.DateTime Date_Closed
{
get
{
return _Date_Closed;
}
}
Event Serialization
In order to allow for properties to be added to or removed from an event definition over the lifetime of a project, I have added an incremental version number property that the developer can set to indicate that the definition has changed.
This version number is used in the filename of a partial class file that is generated which in turn can be used to control how older events are deserialized into newer versions of the event definition.
There are also two distinct types of code generation relating to event serialization. The first is to serialize to or from a binary stream which is what you would typically use to save your event stream in a binary file. For data stores such as NoSQL tables or for human-readable files, the event serialize also generates code that can serialize the event to or from a dictionary as name::value pairs.
Documentation Generation
(See Download Documentation.zip for an example of the generated documentation.)
The documentation generation part of this project is also housed in a separate project in the DocumentationGeneration folder. This is to allow you to make any customizations as you wish without having to rebuild and redeploy the whole tool.
The documentation is intended to help the non-programmers understand the effective model that the system is based upon. It is generated as (very basic looking) HTML with a rudimentary cascading style sheet which you can modify to suit your company standards.
Implementation
Once you have generated the code that describes your domains, you need to put them on top of the infrastructure code. All the generated code refers to the underlying infrastructure components by interfaces allowing you to wire this up as you would like.
In order to separate the business domain classes from the actual specifics of the implementation (as far as is possible), I have implemented the event stream using the concept of "wrapped events".
In a wrapped event, the business specific event data that was designed using the CQRS designer is wrapped in a class that provides the instance identity (basically, the sequence number of the event in the event stream) which in turn is wrapped in a class that provides the event context (the username, timestamp and any other information you want to store about an event that is not the business data of the event).
Public Interface IEvent(Of TAggregate As CQRSAzure.EventSourcing.IAggregationIdentifier)
Inherits IEvent
End Interface
Public Interface IEventIdentity_
(Of TAggregate As CQRSAzure.EventSourcing.IAggregationIdentifier)
Function GetAggregateIdentifier() As String
ReadOnly Property Sequence As UInteger
ReadOnly Property EventInstance As IEvent(Of TAggregate)
End Interface
Public Interface IEventContext
Inherits IEventInstance
ReadOnly Property Who As String
ReadOnly Property Timestamp As Date
ReadOnly Property Source As String
ReadOnly Property SequenceNumber As Long
ReadOnly Property Commentary As String
End Interface
In some cases such as where you build the event stream on top of an SQL database, it is likely that every event will need to store the identity and context data in with the event but in other cases, you may be able to derive the identity and context from another source. When storing events in Azure Blob storage, I would create one blob per aggregate and maybe use the binary offset of the start of each event record as its identity thus reducing the amount of actual data that needs to be stored.
Worked Example: A Bank Account
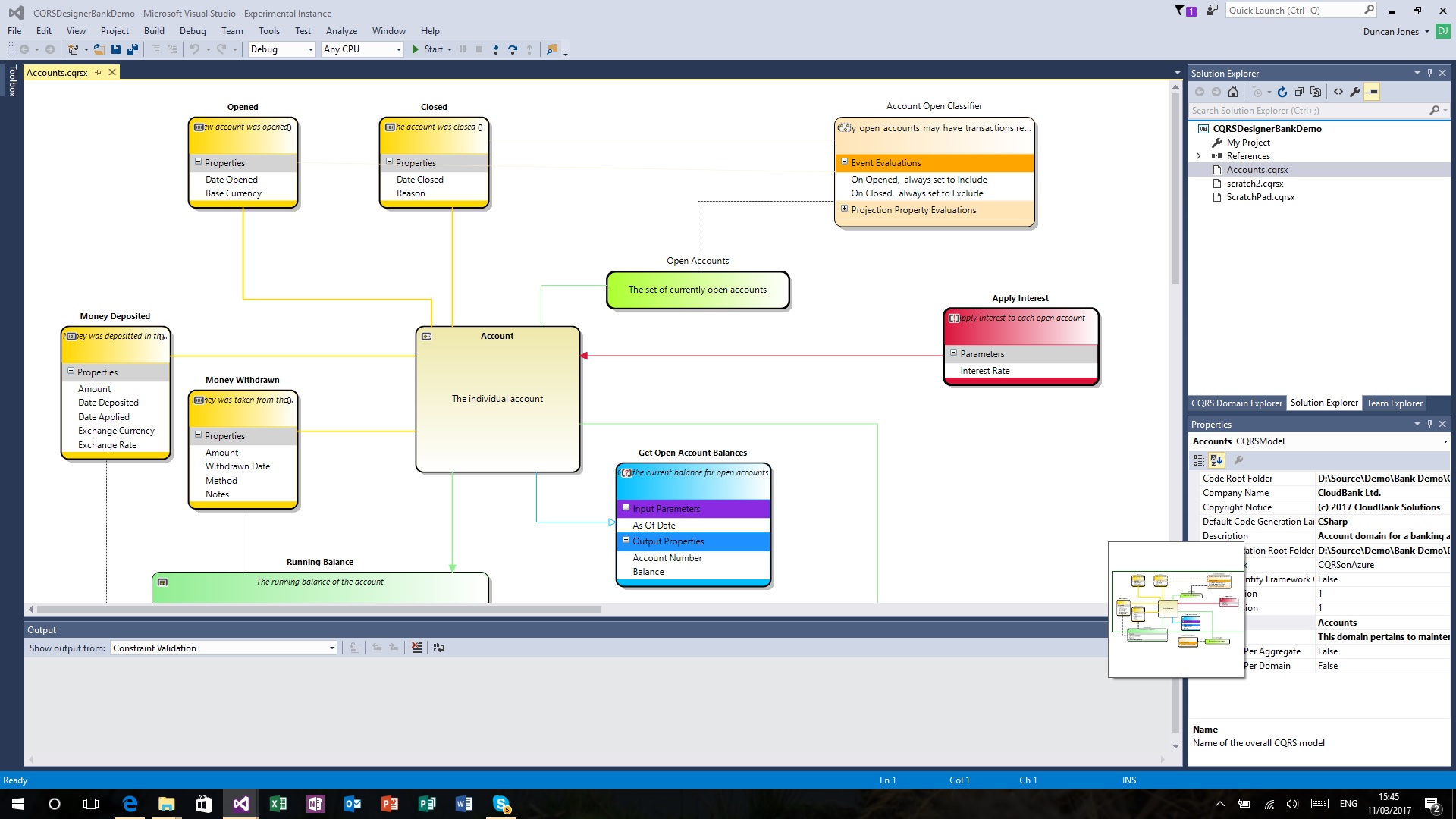
In order to show how this fits within an application architecture in a familiar hello-world style, what follows is a very basic bank account example developed using this designer:
At the centre of this domain is the bank account - the aggregate (entity) that events can occur to. In the existing bank business domain, each account is already given an unique bank account number which we are storing as a string. The event stream for each bank account is uniquely identified by its bank account number key.
The events that can occur to the bank account are that the account is opened, that money is deposited, that money is withdrawn and that the bank account is closed. As the business analysis phase continues, you would probably find more events to add to your bank account aggregate relating to (for example) interest payments, changes of ownership and so on.
The projection "running balance" gives us a point-in-time view of how much money is in the bank account by running over the bank account's event stream and responding to the events "money deposited" and "money withdrawn". In the former event, the amount deposited is added to the current balance and in the latter event, the amount withdrawn is deducted from the balance amount. You will notice that there is no business rule applied in a projection (for example, dealing with overdrawn accounts) as a projection is just a view of the events that have occurred. If there are business rules to be applied, they should prevent the event from occurring rather than being triggered when the event is being used in a projection.
There are also two identity groups in the model - the group "accounts open" is any account that has not been closed and the group "accounts in credit" is those accounts where the balance is greater than zero. The first identity group is populated by a simple classifier which just handles the "account opened" and "account closed" events to derive if an account is in or out of that group. For the accounts in credit identity group, the projection "running balance" is executed and then a rule is applied to include account where the resulting balance is greater than zero.
The query definition "get open account balances" runs over all accounts in the identity group "accounts open" and executes the projection "running balance" over them, returning a collection of the account number and current balance amount.
There is also a command defined "Apply interest" which runs over the identity group "accounts open" and will apply an amount of interest based on the current balance. This business domain would also need commands for opening the account, adding funds, withdrawing funds and closing the account but these are not illustrated for simplicity purposes.
The resulting code generated from this model is then applied to the different tiers of the application. The command and query definitions would belong in the front end layer (the user interface), the identity groups and projects would live in a business layer and the event definitions and aggregate identifier (and the resulting persisted event streams) would live in the data layer - in rather a similar fashion as is currently done with a database backed application.
Using the Code
There are two steps you need to perform before you can run the code attached to this article. The first is to set the startup project to "DSLPackage" if it isn't already set to that. (This setting seems to get stored on a per-user basis so may be different for you when you open the solution.)
The next step is to set the debugging command line to point at where you have the dummy solution file stored (or you can make a new solution yourself and change the debug parameter to point at it):
Next Steps
Next steps for the project are to build an example of this infrastructure on an Azure Storage and Azure Queues basis... and to incorporate any feedback on this initial version of the designer.
Troubleshooting
There are a couple of fiddly aspects to getting this code to compile so the following are worth checking:
- Make sure "
DslPackage" is set as the start-up project (for some reason, that can change to the wrong library) - Make sure the relative path to the test project (above) is set correctly
- Compile each component in turn - sometimes the
CodeGeneration project won't compile because the version of the Roslyn compilers has changed so you need to catch that in the act.
History
- 29th December, 2015 - Initial release for comment/testing. This release is not yet "production ready" but should be considered a proof of concept level. (I have posted it early so as to get any feedback and other ideas before I get too far down the rabbit-hole.)
- 20th March, 2016 - Added code to generate serialisers for each event definition, to allow the implementation code to cope with different version numbers in the event definition
- 7th April, 2016 - Added the code generation options into the model itself so the language to be used and sub-folder settings are saved into the DSL model
- 25th August, 2016 - Added troubleshooting section
- 31st October, 2016 - *breaking changes* Added properties to the model to allow you to designate one date property for an event definition as the "effective date" property, thus allowing for "as of date" style query definitions
- 12th January, 2017 - Added worked example to explain how the different components of the resulting model fit together and how to knit that code into your application
- 11th March, 2017 - Added zoom and thumbnail functionality to make it easier to work with large domain models
- 14th January, 2018 - Added serialization code generation for much faster serializing/deserializing of events

