Goals
The intention of this article is to investigate what implications scalability requirements have on full-text search engines and how the project Strus meets these requirements.
Update
20th October 2017
The sources and the docker image of this article have been updated to the latest version of Strus and Python 3.x. The support of Python 2.7 has been dropped in Strus due to the change of the language bindings generator from Boost-Python to Papuga.
Background
Strus is a set of libraries and tools to build search engines. For tutorials that show how to build a search engine with Strus have a look at my previous code project articles:
-
Building a search engine with Strus:
This tutorial shows how to implement a simple PHP Webservice implementing search on a strus storage. Only the query part of the interface is implemented as Webservice. The test collection is inserted with command line tools.
-
Building a search engine with Python Tornado and Strus This tutorial shows how to implement a more complex search application with Python and Strus. Two query evaluation methods are implemented. One is a classical BM25. The other shows how complex query expressions can be built and how alternative information retrieval methods can be implemented, that weight extracted content instead of documents based on the query. If you have a closer look you will find out that Strus is an engine that can match patterns of regular languages (with terms and not characters as alphabet) by relating its expressions to iterable operations on the sets of postings:
{(d,p) | d:document number, p:position
The Strus interface documentation for Python3 can be found here (You can use PgUp,PgDown to navigate there).
Prerequisites
For running the examples in a docker image, you need docker installed.
Introduction
To cap administration costs of growing systems the economy favors configurationless systems, meaning that the software is completely instrumented with an API.
To scale in performance you need to be able to distribute your application on an arbitrary number of machines without system costs eating up the performance gain of using more machines. Furthermore it should be possible to add new machines anytime without a complete reconfiguration of the system.
The first requirement, a configurationless system, completely instrumentable with an API is fulfilled by Strus. You can check that on your own. Have a look at the previous articles and the API and the documentation with examples.
The second issue, distribution of a search index on an arbitrary number of machines and the capability to increase the number of processing nodes anytime is the main subject of this article. The article will not discuss fundamentals of distributed processing. Costs of sharing data, messaging and process synchronization should be familiar to the reader. The article will only explain what data is usually shared in a full-text search engine and discuss alternatives how to handle the consequential problems (as sharing data is always a problem in distributed systems). Then it will show the position of Strus in this landscape and help you to compare Strus with other search engines.
Note 1
We are talking about a distributed search index here and not about a distributed search. A distributed search would mean a distributed system, where queries are routed to the nodes that possibly can answer the query. For a search engine this means that nodes propagate their competence to answer a certain question in a P2P network to other nodes and the nodes use this information to route a query. Here we talk about distributing the search index of a full-text search engine that sends the query to all nodes (transitively in the case of a tree of nodes) and that merges their results to one result list.
Note 2
A search engine evaluates the best matching answers to a query with help of a database storing relations that bring a query into conjunction with a result. For a scalable search engine with a distributed index it is important that each node with a part of this split can calculate a part of the result completely so that it can make a decision about what is a candidate for the final result and what not. Preferably the number of items selected with this cut as candidates for the final result is small. This implies that the database has to be organized in a way that all information for weighting one document, the most common result of an information retrieval query, belongs to one node. The informations used for retrieval are therefore assumed to be grouped by document. There are cases of retrieval problems, where the items retrieved are not documents and where the cut cannot be made so easily.
Distributing the search index
A search engine usually assigns a weight to each result row. This weight is used to order the results. A search engine calculates the N results with the highest weight. For merging results from different nodes to one result, these weights must be comparable. If this is the case, then a search engine can delegate the calculation of the best results to each node and then take the best N results from the merge of the node results.
Many established weighting methods use statistical information that is accumulated from values distributed over the complete collection. One example is the df, the document frequency of a term. It gives a measure of how rare or how often a term appears in the collection. Many statistical methods use this number in the weighting formula used to calculate the weight of a document.
We can now make a distinction of cases of the relation of a node to such a piece of information from the point of view of a node and the consequences for our retrieval function and the system:
| 1
| The information is not provided: We implement only query evaluation schemes without global statistical data.
| This is a solution that scales. Unfortunately it is problematic from the information retrieval point of view. It looks like neither query expansion nor document assessments are able to outweigh missing statistical information. Well, at least according to my information. If you can solve your problem with this approach, then it is perfect.
|
| 2
| The information is implicitly provided: We use the probability of a random distribution of independent items to tend towards an equal distribution of the statistics. A mechanism is used that assigns the documents to nodes in a way that we can use the local values of statistics for calculation because they are with a high probability globally the same within an error range.
| This is a very pragmatic approach. We can scale in the number of documents we can insert, though we cannot simply add and remove nodes and organize them as we want. We can organize things only one way and this assignment is left to Mr. Random. The missing possibility to organize collections as we want is the strongest argument against this approach. Another problem is the high costs of reorganisation if the maximum number of documents (the decline of the search performance with the growth of the inserts sets the limit) is reached.
|
| 3
| Every node has access to the information: We use a mechanism to distribute the information to every node or we provide an interface for every node to access the information.
| Both approaches are a no go from system point of view. In the first case we get storms of messages when updating a node. So you can forget scalability. In the second case we get a system nightmare with the interface to access the information provided to the nodes. The self containment of nodes is lost and thus the scalability.
|
| 4
| The information is passed down with the query: We separate the information from the single node.
| This is a good approach, if the amount of information we have to pass down is not significantly complicating the query. We can handle the problem of accessing this information on its own. For example by using a key/value map as storage for this information. We know that we can scale in this aspect, because for key/value storages there exist solutions that scale. We have to find ways to fetch the information from the nodes accumulating it and put it into the global storage for the statistical information for the query.
But we also give something away with this solution. Queries that require statistical information of items that are taken from the documents retrieved, like for example fetching the statistically best terms from documents matching a query for relevance feedback, are only possible using local statistics. This is because the information we have to pass down with the query is potentially containing all statistical information in the whole collection or all information that possibly could be found in a document.
|
Solutions
You can find out on your own, how your favorite search engine software solves the problem of providing the information needed by the query for weighting the items retrieved in a way that search results are comparable.
For Strus we will not discuss the variant 1(the information is not provided) because it is trivial.
The variant 2(the information is implicitly provided) is left to the reader to think about.
The variant 3(every node has access to the information) is refused because it does not scale.
We will only have a look at variant 4 (the information is passed down with the query) and provide some example source code for it.
Note 3
We will intentionally overlook the fact, that this variant (4) potentially cannot solve problems like feature selection based on global term statistics. But there is still reason for optimism to find solutions for this kind of problems (For example to use the local statistics information to make a preselection and a cut and to calculate the real weights based on the global statistics outside). If you have a solution that scales but is missing the functionality, you'll have a big chance to solve your problem with some fantasy and some nice ideas. It is on the other hand nearly impossible to take a program, that solves a problem, and to make it scale with some fantasy and some nice ideas.
Example implementation with Strus
This demo provides a docker image to run the examples. But you can also download them and run on your own. The Python sources of this article are examples not intended for production or even a test application. There are no real transactions implemented and error handling is not involving recovery from all kind of errors. There are 3 servers implemented, each of them representing one component of the distributed search engine. You might think about the architecture on your own and find a suitable solution for your needs. Then you will implement the components needed from scratch. The examples here are just a scetch and a proof of concept. In this section we will introduce the components needed with an example. The following table gives you an overview.
The servers
| strusStatisticsServer.py
| A statistics server holds the global statistics. It might be implemented as interface to a distributed hashtable fed over persistent queues. But our example server holds the global statistics for each term in a dicitionary and the total collection size in variables in memory. Nothing is persistent and thus lost on shutdown.
The server is implemented as TCP/IP server with a proprietary protocol with two commands (put/get).
|
| strusStorageServer.py
| A storage server provides access to one storage. It is a node in our distributed search. It provides two commands, one for insert and one for query.
The insert will analyze and store the multipart document passed within one transaction. After the transaction commit it iterates on its global statistics updates, a set of increment/decrement operations. These operations (packed in chunks of data blobs) are sent to the statistics server. Currently there is no possibility to get the statistic updates before a commit. There is room for improvement here in Strus.
The query is passed as list of terms with their global statistics to a storage server. The storage server builds the query with the global term statistics and the global collection size, excutes it and sends the result back.
|
| strusHttpServer.py
| A strus HTTP server provides two operations insert and query.
The insert is a POST request with the port of the local storage server, where to insert the document in the URL and the multipart document in the request body. The insert command takes the document and forwards it to the storage server addressed with the command URL.
The query is a GET request with the query string and the result range as parameter. The query command analyzes the query to get the normalized query terms and sends them first to the statistics server to get the statistics for each term and the global collection size. The query with the statistics is packed and sent to each storage node. The results received from each server are merged into one result and rendered with tornado templates to an HTML page. For siplicity the example implements only a list of terms as query. It's left to the reader to think about how to analyze a query language, getting the statistics of the terms and serialize the query tree.
|
Some helper modules
| strusIR.py
| The strus information retrieval module provides an abstraction for accessing the storage and analyze the document. As we already noticed is the query analysis done outside in the HttpServer. In a decent design, the sources for query and document analysis would be at the same place because they belong together. But we don't look at a proper way of organizing the code in details we do not intend to bring into focus in this article.
|
| strusMessage.py
| The messaging module provides an abstraction for server and client used for the TCP/IP messaging of the storage and the statistics servers. It allows the client to open a session and send one or several requests to the server.
For simplicity we do not hold connections open.
|
The source code
strusStorageServer.py
#!/usr/bin/python3
import tornado.ioloop
import tornado.web
import tornado.gen
import tornado.iostream
import os
import sys
import struct
import collections
import optparse
import strusMessage
import binascii
import strusIR
# Information retrieval engine:
backend = None
# Port of the global statistics server:
statserver = "localhost:7183"
# IO loop:
pubstats = False
# Strus client connection factory:
msgclient = strusMessage.RequestClient()
# Call of the statustics server to publish the statistics of this storage on insert:
@tornado.gen.coroutine
def publishStatistics( itr):
# Open connection to statistics server:
try:
ri = statserver.rindex(':')
host,port = statserver[:ri],int( statserver[ri+1:])
conn = yield msgclient.connect( host, port)
except IOError as e:
raise Exception( "connection to statistics server %s failed (%s)" % (statserver, e))
for msg in itr:
try:
reply = yield msgclient.issueRequest( conn, b"P" + msg)
if (reply[0] == ord('E')):
raise Exception( "error in statistics server: %s" % reply[ 1:].decode('utf-8'))
elif (reply[0] != ord('Y')):
raise Exception( "protocol error publishing statistics")
except tornado.iostream.StreamClosedError:
raise Exception( "unexpected close of statistics server")
# Pack a message with its length (processCommand protocol)
def packedMessage( msg):
return struct.pack( ">H%ds" % len(msg), len(msg), msg.encode('utf-8'))
# Server callback function that intepretes the client message sent,
# executes the command and packs the result for the client:
@tornado.gen.coroutine
def processCommand( message):
rt = b"Y"
try:
messagesize = len(message)
messageofs = 1
if (message[0] == ord('I')):
# INSERT:
# Insert documents:
docblob = message[ 1:]
nofDocuments = backend.insertDocuments( docblob)
# Publish statistic updates:
if (pubstats):
itr = backend.getUpdateStatisticsIterator()
yield publishStatistics( itr)
rt += struct.pack( ">I", nofDocuments)
elif (message[0] == ord('Q')):
# QUERY:
Term = collections.namedtuple('Term', ['type', 'value', 'df'])
nofranks = 20
collectionsize = 0
firstrank = 0
terms = []
# Build query to evaluate from the request:
messagesize = len(message)
messageofs = 1
while (messageofs < messagesize):
if (message[ messageofs] == ord('I')):
(firstrank,) = struct.unpack_from( ">H", message, messageofs+1)
messageofs += struct.calcsize( ">H") + 1
elif (message[ messageofs] == ord('N')):
(nofranks,) = struct.unpack_from( ">H", message, messageofs+1)
messageofs += struct.calcsize( ">H") + 1
elif (message[ messageofs] == ord('S')):
(collectionsize,) = struct.unpack_from( ">q", message, messageofs+1)
messageofs += struct.calcsize( ">q") + 1
elif (message[ messageofs] == ord('T')):
(df,typesize,valuesize) = struct.unpack_from( ">qHH", message, messageofs+1)
messageofs += struct.calcsize( ">qHH") + 1
(type,value) = struct.unpack_from( "%ds%ds"
% (typesize,valuesize), message, messageofs)
messageofs += typesize + valuesize
terms.append( Term( type, value, df))
else:
raise tornado.gen.Return( b"Eunknown parameter")
# Evaluate query with BM25 (Okapi):
results = backend.evaluateQuery( terms, collectionsize, firstrank, nofranks)
# Build the result and pack it into the reply message for the client:
for result in results:
rt += b'_D'
rt += struct.pack( ">I", result['docno'])
rt += b'W'
rt += struct.pack( ">f", result['weight'])
rt += b'I'
rt += packedMessage( result['docid'])
rt += b'T'
rt += packedMessage( result['title'])
rt += b'A'
rt += packedMessage( result['abstract'])
else:
raise Exception( "unknown command")
except Exception as e:
raise tornado.gen.Return( b"E" + str(e).encode('utf-8'))
raise tornado.gen.Return( rt)
# Shutdown function that sends the negative statistics to the statistics server (unsubscribe):
def processShutdown():
if (pubstats):
publishStatistics( backend.getDoneStatisticsIterator())
# Server main:
if __name__ == "__main__":
try:
# Parse arguments:
defaultconfig = "path=storage; cache=512M; statsproc=default"
parser = optparse.OptionParser()
parser.add_option("-p", "--port", dest="port", default=7184,
help="Specify the port of this server as PORT (default %u)" % 7184,
metavar="PORT")
parser.add_option("-c", "--config", dest="config", default=defaultconfig,
help="Specify the storage path as CONF (default '%s')"
% defaultconfig,
metavar="CONF")
parser.add_option("-s", "--statserver", dest="statserver", default=statserver,
help="Specify the address of the stat server as ADDR (default %s)"
% statserver,
metavar="ADDR")
parser.add_option("-P", "--publish-stats", action="store_true",
dest="do_publish_stats", default=False,
help="Tell the node to publish the own storage statistics "
"to the statistics server at startup")
(options, args) = parser.parse_args()
if len(args) > 0:
parser.error("no arguments expected")
parser.print_help()
myport = int(options.port)
pubstats = options.do_publish_stats
statserver = options.statserver
backend = strusIR.Backend( options.config)
if (statserver[0:].isdigit()):
statserver = '{}:{}'.format( 'localhost', statserver)
if (pubstats):
# Start publish local statistics:
print( "Load local statistics to publish ...\n")
publishStatistics( backend.getInitStatisticsIterator())
# Start server:
print( "Starting server ...")
server = strusMessage.RequestServer( processCommand, processShutdown)
server.start( myport)
print( "Terminated\n")
except Exception as e:
print( e)
strusStatisticsServer.py
p, li { white-space: pre-wrap; }
<!--StartFragment-->#!/usr/bin/python3
import tornado.ioloop
import tornado.web
import optparse
import os
import sys
import binascii
import struct
import strus
import collections
import strusMessage
# [1] Globals:
# Term df map:
termDfMap = {}
# Collection size (number of documents):
collectionSize = 0
# Strus statistics message processor:
strusctx = strus.Context()
# [2] Request handlers
def packedMessage( msg):
return struct.pack( ">H%ds" % len(msg), len(msg), msg)
def termDfMapKey( type, value):
return "%s~%s" % (type,value)
@tornado.gen.coroutine
def processCommand( message):
rt = b"Y"
try:
global collectionSize
global termDfMap
if (message[0] == ord('P')):
# PUBLISH:
statview = strusctx.unpackStatisticBlob( message[1:])
collectionSize += statview[ "nofdocs"]
for dfchg in statview[ "dfchange"]:
key = termDfMapKey( dfchg['type'], dfchg['value'])
if key in termDfMap:
termDfMap[ key ] += int( dfchg['increment'])
else:
termDfMap[ key ] = int( dfchg['increment'])
elif (message[0] == ord('Q')):
# QUERY:
messagesize = len(message)
messageofs = 1
while (messageofs < messagesize):
if (message[ messageofs] == ord('T')):
# Fetch df of term, message format
# [T][typesize:16][valuesize:16][type string][value string]:
(typesize,valuesize) = struct.unpack_from( ">HH", message, messageofs+1)
messageofs += struct.calcsize( ">HH") + 1
(type,value) = struct.unpack_from(
"%ds%ds" % (typesize,valuesize), message, messageofs)
messageofs += typesize + valuesize
df = 0
key = termDfMapKey( type, value)
if key in termDfMap:
df = termDfMap[ key]
rt += struct.pack( ">q", df)
elif (message[ messageofs] == ord('N')):
# Fetch N (nof documents), message format [N]:
messageofs += 1
rt += struct.pack( ">q", collectionSize)
else:
raise Exception( "unknown statistics server sub command")
else:
raise Exception( "unknown statistics server command")
except Exception as e:
raise tornado.gen.Return( b"E" + str(e).encode('utf-8'))
raise tornado.gen.Return( rt)
def processShutdown():
pass
# [5] Server main:
if __name__ == "__main__":
try:
# Parse arguments:
parser = optparse.OptionParser()
parser.add_option("-p", "--port", dest="port", default=7183,
help="Specify the port of this server as PORT (default %u)" % 7183,
(options, args) = parser.parse_args()
if len(args) > 0:
parser.error("no arguments expected")
parser.print_help()
myport = int(options.port)
# Start server:
print( "Starting server ...")
server = strusMessage.RequestServer( processCommand, processShutdown)
server.start( myport)
print( "Terminated\n")
except Exception as e:
print( e)
<!--EndFragment-->
<!--EndFragment-->
<!--EndFragment-->
strusHttpServer.py
p, li { white-space: pre-wrap; }
<!--StartFragment-->#!/usr/bin/python3
import tornado.ioloop
import tornado.web
import tornado.websocket
import tornado.gen
import os
import sys
import struct
import binascii
import collections
import heapq
import optparse
import signal
import strus
import strusMessage
# [0] Globals and helper classes:
# The address of the global statistics server:
statserver = "localhost:7183"
# Strus storage server addresses:
storageservers = []
# Strus client connection factory:
msgclient = strusMessage.RequestClient()
# Query analyzer structures (parallel to document analyzer definition in strusIR):
strusctx = strus.Context()
analyzer = strusctx.createQueryAnalyzer()
analyzer.addElement( "word", "text", "word", ["lc", ["stem", "en"], ["convdia", "en"]])
# Query evaluation structures:
ResultRow = collections.namedtuple(
'ResultRow', ['docno', 'docid', 'weight', 'title', 'abstract'])
# [1] HTTP handlers:
# Answer a query (issue a query to all storage servers and merge it to one result):
class QueryHandler( tornado.web.RequestHandler ):
@tornado.gen.coroutine
def queryStats( self, terms):
rt = ([],0,None)
try:
statquery = b"Q"
for term in terms:
ttype = term['type'].encode('utf-8')
tvalue = term['value'].encode('utf-8')
statquery += b'T'
typesize = len( ttype)
valuesize = len( tvalue)
statquery += struct.pack( ">HH", typesize, valuesize)
statquery += struct.pack( "%ds%ds" % (typesize,valuesize), ttype, tvalue)
statquery += b'N'
ri = statserver.rindex(':')
host,port = statserver[:ri],int( statserver[ri+1:])
conn = yield msgclient.connect( host, port)
statreply = yield msgclient.issueRequest( conn, statquery)
if (statreply[0] == ord('E')):
raise Exception( "failed to query global statistics: %s" % statreply[1:])
elif (statreply[0] != ord('Y')):
raise Exception( "protocol error loading global statistics")
dflist = []
collsize = 0
statsofs = 1
statslen = len(statreply)
while (statsofs < statslen):
(statsval,) = struct.unpack_from( ">q", statreply, statsofs)
statsofs += struct.calcsize( ">q")
if (len(dflist) < len(terms)):
dflist.append( statsval)
elif (len(dflist) == len(terms)):
collsize = statsval
else:
break
if (statsofs != statslen):
raise Exception("result does not match query")
rt = (dflist, collsize, None)
except Exception as e:
rt = ([],0,"query statistic server failed: %s" % e)
raise tornado.gen.Return( rt)
@tornado.gen.coroutine
def issueQuery( self, serveraddr, qryblob):
rt = (None,None)
ri = serveraddr.rindex(':')
host,port = serveraddr[:ri],int( serveraddr[ri+1:])
result = None
conn = None
try:
conn = yield msgclient.connect( host, port)
reply = yield msgclient.issueRequest( conn, qryblob)
if (reply[0] == ord('E')):
rt = (None, "storage server %s:%d returned error: %s"
% (host, port, reply[1:]))
elif (reply[0] == ord('Y')):
result = []
row_docno = 0
row_docid = None
row_weight = 0.0
row_title = ""
row_abstract = ""
replyofs = 1
replysize = len(reply)-1
while (replyofs < replysize):
if (reply[ replyofs] == ord('_')):
if (row_docid != None):
result.append( ResultRow(
row_docno, row_docid, row_weight, row_title, row_abstract))
row_docno = 0
row_docid = None
row_weight = 0.0
row_title = ""
row_abstract = ""
replyofs += 1
elif (reply[ replyofs] == ord('D')):
(row_docno,) = struct.unpack_from( ">I", reply, replyofs+1)
replyofs += struct.calcsize( ">I") + 1
elif (reply[ replyofs] == ord('W')):
(row_weight,) = struct.unpack_from( ">f", reply, replyofs+1)
replyofs += struct.calcsize( ">f") + 1
elif (reply[ replyofs] == ord('I')):
(docidlen,) = struct.unpack_from( ">H", reply, replyofs+1)
replyofs += struct.calcsize( ">H") + 1
(row_docid,) = struct.unpack_from( "%us" % docidlen, reply, replyofs)
replyofs += docidlen
elif (reply[ replyofs] == ord('T')):
(titlelen,) = struct.unpack_from( ">H", reply, replyofs+1)
replyofs += struct.calcsize( ">H") + 1
(row_title,) = struct.unpack_from( "%us" % titlelen, reply, replyofs)
replyofs += titlelen
elif (reply[ replyofs] == ord('A')):
(abstractlen,) = struct.unpack_from( ">H", reply, replyofs+1)
replyofs += struct.calcsize( ">H") + 1
(row_abstract,) = struct.unpack_from(
"%us" % abstractlen, reply, replyofs)
replyofs += abstractlen
else:
rt = (None, "storage server %s:%u protocol error: "
"unknown result column name" % (host,port))
row_docid = None
break
if (row_docid != None):
result.append( ResultRow(
row_docno, row_docid, row_weight, row_title, row_abstract))
rt = (result, None)
else:
rt = (None, "protocol error storage %s:%u query: "
"unknown header %c" % (host,port,reply[0]))
except Exception as e:
rt = (None, "storage server %s:%u connection error: %s"
% (host, port, str(e)))
raise tornado.gen.Return( rt)
@tornado.gen.coroutine
def issueQueries( self, servers, qryblob):
results = None
try:
results = yield [ self.issueQuery( addr, qryblob) for addr in servers ]
except Exception as e:
raise tornado.gen.Return( [], ["error issueing query: %s" % str(e)])
raise tornado.gen.Return( results)
# Merge code derived from Python Cookbook (Sebastien Keim, Raymond Hettinger and Danny Yoo)
# referenced in from http:
def mergeResultIter( self, resultlists):
# prepare a priority queue whose items are pairs of the form (-weight, resultlistiter):
heap = []
for resultlist in resultlists:
resultlistiter = iter(resultlist)
for result in resultlistiter:
# subseq is not empty, therefore add this subseq pair
# (current-value, iterator) to the list
heap.append((-result.weight, result, resultlistiter))
break
# make the priority queue into a heap
heapq.heapify(heap)
while heap:
# get and yield the result with the highest weight (minus lowest negative weight):
negative_weight, result, resultlistiter = heap[0]
yield result
for result in resultlistiter:
# resultlists is not finished, replace best pair in the priority queue
heapq.heapreplace( heap, (-result.weight, result, resultlistiter))
break
else:
# subseq has been exhausted, therefore remove it from the queue
heapq.heappop( heap)
def mergeQueryResults( self, results, firstrank, nofranks):
merged = []
errors = []
itrs = []
maxnofresults = firstrank + nofranks
for result in results:
if (result[0] == None):
errors.append( result[1])
else:
itrs.append( iter( result[0]))
ri = 0
for result in self.mergeResultIter( itrs):
if (ri == maxnofresults):
break
merged.append( result)
ri += 1
return (merged[ firstrank:maxnofresults], errors)
@tornado.gen.coroutine
def evaluateQueryText( self, querystr, firstrank, nofranks):
rt = None
try:
maxnofresults = firstrank + nofranks
terms = analyzer.analyzeTermExpression( ["text", querystr])
if len( terms) > 0:
# Get the global statistics:
dflist,collectionsize,error = yield self.queryStats( terms)
if (error != None):
raise Exception( error)
# Assemble the query:
qry = b"Q"
qry += b"S"
qry += struct.pack( ">q", collectionsize)
qry += b"I"
qry += struct.pack( ">H", 0)
qry += b"N"
qry += struct.pack( ">H", maxnofresults)
for ii in range( 0, len( terms)):
qry += b"T"
type = terms[ii]['type'].encode('utf-8')
typesize = len( type)
value = terms[ii]['value'].encode('utf-8')
valuesize = len( value)
qry += struct.pack( ">qHH", dflist[ii], typesize, valuesize)
qry += struct.pack( "%ds%ds" % (typesize,valuesize), type, value)
# Query all storage servers and merge the results:
results = yield self.issueQueries( storageservers, qry)
rt = self.mergeQueryResults( results, firstrank, nofranks)
except Exception as e:
rt = ([], ["error evaluation query: %s" % str(e)])
raise tornado.gen.Return( rt)
@tornado.gen.coroutine
def get(self):
try:
# q = query terms:
querystr = self.get_argument( "q", None)
# i = firstrank:
firstrank = int( self.get_argument( "i", 0))
# n = nofranks:
nofranks = int( self.get_argument( "n", 20))
# Evaluate query with BM25 (Okapi):
result = yield self.evaluateQueryText( querystr, firstrank, nofranks)
# Render the results:
self.render( "search_bm25_html.tpl", results=result[0], messages=result[1])
except Exception as e:
self.render( "search_error_html.tpl", message=e)
# Insert a multipart document (POST request):
class InsertHandler( tornado.web.RequestHandler ):
@tornado.gen.coroutine
def post(self, port):
try:
# Insert documents:
conn = yield msgclient.connect( 'localhost', int(port))
cmd = b"I" + self.request.body
reply = yield msgclient.issueRequest( conn, cmd)
if (reply[0] == ord('E')):
raise Exception( reply[1:].decode('UTF-8'))
elif (reply[0] != ord('Y')):
raise Exception( "protocol error server reply on insert: %c" % reply[0])
(nofDocuments,) = struct.unpack( ">I", reply[1:])
self.write( "OK %u\n" % (nofDocuments))
except Exception as e:
self.write( "ERR " + str(e) + "\n")
# [3] Dispatcher:
application = tornado.web.Application([
# /query in the URL triggers the handler for answering queries:
(r"/query", QueryHandler),
# /insert in the URL triggers the post handler for insert requests:
(r"/insert/([0-9]+)", InsertHandler),
# /static in the URL triggers the handler for accessing static
# files like images referenced in tornado templates:
(r"/static/(.*)",tornado.web.StaticFileHandler,
{"path": os.path.dirname(os.path.realpath(sys.argv[0]))},)
])
def on_shutdown():
print('Shutting down')
tornado.ioloop.IOLoop.current().stop()
# [5] Server main:
if __name__ == "__main__":
try:
# Parse arguments:
usage = "usage: %prog [options] {<storage server port>}"
parser = optparse.OptionParser( usage=usage)
parser.add_option("-p", "--port", dest="port", default=80,
help="Specify the port of this server as PORT (default %u)" % 80,
metavar="PORT")
parser.add_option("-s", "--statserver", dest="statserver", default=statserver,
help="Specify the address of the statistics server "
"as ADDR (default %s" % statserver,
metavar="ADDR")
(options, args) = parser.parse_args()
myport = int(options.port)
statserver = options.statserver
if (statserver[0:].isdigit()):
statserver = '{}:{}'.format( 'localhost', statserver)
# Positional arguments are storage server addresses,
# if empty use default at localhost:7184
for arg in args:
if (arg[0:].isdigit()):
storageservers.append( '{}:{}'.format( 'localhost', arg))
else:
storageservers.append( arg)
if (len( storageservers) == 0):
storageservers.append( "localhost:7184")
# Start server:
print( "Starting server ...\n")
application.listen( myport )
print( "Listening on port %u\n" % myport )
ioloop = tornado.ioloop.IOLoop.current()
signal.signal( signal.SIGINT,
lambda sig, frame: ioloop.add_callback_from_signal(on_shutdown))
ioloop.start()
print( "Terminated\n")
except Exception as e:
print( e)
<!--EndFragment-->
strusIR.py
p, li { white-space: pre-wrap; }
<!--StartFragment-->import strus
import itertools
import heapq
import re
import utils
class Backend:
# Create the document analyzer for our test collection:
# Create the document analyzer for our test collection:
def createDocumentAnalyzer(self):
rt = self.context.createDocumentAnalyzer( {"mimetype":"xml"} )
# Define the sections that define a document (for multipart documents):
rt.defineDocument( "doc", "/list/item")
# Define the terms to search for (inverted index or search index):
rt.addSearchIndexFeature( "word", "/list/item/title()",
"word", ("lc",("stem","en"),("convdia","en")))
rt.addSearchIndexFeature( "word", "/list/item/artist()",
"word", ("lc",("stem","en"),("convdia","en")))
rt.addSearchIndexFeature( "word", "/list/item/note()",
"word", ("lc",("stem","en"),("convdia","en")))
# Define the terms to search for (inverted index or search index):
rt.addForwardIndexFeature( "orig", "/list/item/title()", "split", "orig")
rt.addForwardIndexFeature( "orig", "/list/item/artist()", "split", "orig")
rt.addForwardIndexFeature( "orig", "/list/item/note()", "split", "orig")
# Define the document attributes:
rt.defineAttribute( "docid", "/list/item/id()", "content", "text")
rt.defineAttribute( "title", "/list/item/title()", "content", "text")
rt.defineAttribute( "upc", "/list/item/upc()", "content", "text")
rt.defineAttribute( "note", "/list/item/note()", "content", "text")
# Define the document meta data:
rt.defineMetaData( "date", "/list/item/date()",
("regex","[0-9\-]{8,10} [0-9:]{6,8}"),
[("date2int", "d 1877-01-01", "%Y-%m-%d %H:%M:%s")]);
# Define the doclen attribute needed by BM25:
rt.defineAggregatedMetaData( "doclen",("count", "word"))
return rt
# Create a simple BM25 query evaluation scheme with fixed
# a,b,k1 and avg document lenght and title with abstract
# as summarization attributes:
def createQueryEvalBM25(self):
rt = self.context.createQueryEval()
# Declare the sentence marker feature needed for abstracting:
rt.addTerm( "sentence", "sent", "")
# Declare the feature used for selecting result candidates:
rt.addSelectionFeature( "selfeat")
# Query evaluation scheme:
rt.addWeightingFunction( "BM25", {
"b": 0.75, "k1": 1.2, "avgdoclen": 20, "match": {"feature":"docfeat"} })
# Summarizer for getting the document title:
rt.addSummarizer( "attribute", { "name": "docid" })
rt.addSummarizer( "attribute", { "name": "title" })
# Summarizer for abstracting:
rt.addSummarizer( "matchphrase", {
"type": "orig", "windowsize": 40,
"matchmark": '$<b>$</b>', "match": {"feature":"docfeat"} })
return rt
# Constructor. Initializes the query evaluation schemes and the query and
# document analyzers:
def __init__(self, config):
# Open local storage on file with configuration specified:
self.context = strus.Context()
self.storage = self.context.createStorageClient( config )
self.documentAnalyzer = self.createDocumentAnalyzer()
self.queryeval = self.createQueryEvalBM25()
# Insert a multipart document:
def insertDocuments( self, content):
rt = 0
docs = self.documentAnalyzer.analyzeMultiPart( content,
{"mimetype":"xml", "encoding":"utf-8"})
transaction = self.storage.createTransaction()
for doc in docs:
docid = doc['attribute']['docid']
transaction.insertDocument( docid, doc)
rt += 1
transaction.commit()
return rt
# Query evaluation scheme for a classical information retrieval query with BM25:
def evaluateQuery( self, terms, collectionsize, firstrank, nofranks):
queryeval = self.queryeval
query = queryeval.createQuery( self.storage)
if len( terms) == 0:
# Return empty result for empty query:
return []
selexpr = ["contains"]
for term in terms:
selexpr.append( [term.type, term.value] )
query.addFeature( "docfeat", [term.type, term.value])
query.defineTermStatistics( term.type, term.value, {'df' : int(term.df)} )
query.addFeature( "selfeat", selexpr)
query.setMaxNofRanks( nofranks)
query.setMinRank( firstrank)
query.defineGlobalStatistics( {'nofdocs' : int(collectionsize)} )
# Evaluate the query:
results = query.evaluate()
# Rewrite the results:
rt = []
for result in results['ranks']:
content = ""
title = ""
docid = ""
for attribute in result['summary']:
if attribute['name'] == 'phrase':
if content != "":
content += ' ... '
content += attribute['value']
elif attribute['name'] == 'docid':
docid = attribute['value']
elif attribute['name'] == 'title':
title = attribute['value']
rt.append( {
'docno':result['docno'],
'docid':docid,
'title':title,
'weight':result['weight'],
'abstract':content })
return rt
# Get an iterator on all absolute statistics of the storage
def getInitStatisticsIterator( self):
return self.storage.getAllStatistics( True)
# Get an iterator on all absolute statistics of the storage
def getDoneStatisticsIterator( self):
return self.storage.getAllStatistics( False)
# Get an iterator on statistic updates of the storage
def getUpdateStatisticsIterator( self):
return self.storage.getChangeStatistics()
strusMessage.py
<style type="text/css">p, li { white-space: pre-wrap; }</style><!--StartFragment-->import tornado.ioloop
import tornado.gen
import tornado.tcpclient
import tornado.tcpserver
import signal
import os
import sys
import struct
import binascii
class TcpConnection( object):
def __init__(self, stream, command_callback):
self.stream = stream
self.command_callback = command_callback
@tornado.gen.coroutine
def on_connect(self):
try:
while (True):
msgsizemsg = yield self.stream.read_bytes( struct.calcsize(">I"))
(msgsize,) = struct.unpack( ">I", msgsizemsg)
msg = yield self.stream.read_bytes( msgsize)
reply = yield self.command_callback( msg)
yield self.stream.write( struct.pack( ">I", len(reply)) + reply);
except tornado.iostream.StreamClosedError:
pass
class RequestServer( tornado.tcpserver.TCPServer):
def __init__(self, command_callback, shutdown_callback):
tornado.tcpserver.TCPServer.__init__(self)
self.command_callback = command_callback
self.shutdown_callback = shutdown_callback
self.io_loop = tornado.ioloop.IOLoop.current()
def do_shutdown( self, signum, frame):
print('Shutting down')
self.shutdown_callback()
self.io_loop.stop()
@tornado.gen.coroutine
def handle_stream( self, stream, address):
connection = TcpConnection( stream, self.command_callback)
yield connection.on_connect()
def start( self, port):
host = "0.0.0.0"
self.listen( port, host)
print("Listening on %s:%d..." % (host, port))
signal.signal( signal.SIGINT, self.do_shutdown)
self.io_loop.start()
class RequestClient( tornado.tcpclient.TCPClient):
@tornado.gen.coroutine
def issueRequest( self, stream, msg):
blob = struct.pack( ">I", len(msg)) + msg
stream.write( blob);
replysizemsg = yield stream.read_bytes( struct.calcsize(">I"))
(replysize,) = struct.unpack( ">I", replysizemsg)
reply = yield stream.read_bytes( replysize)
raise tornado.gen.Return( reply)
<!--EndFragment-->
Running the example
Start the docker image and create the document collection
The dataset used in this article is from MusicBrainz (musicbrainz.org).
Please respect the license of this dataset !
The docker image is started with
docker run -p 40080:80 -t -i patrickfrey/strus-ub1604-torndist:v0_15 /bin/bash
and you a prompt like this
root@3810f0b27943:/home/strus#
The following shell commands are executed in the docker image.
The document collection used in the examples is from musicbrainz. It contains a list of music recordings.
To download and prepare the documents you run the shell script
./prepare.sh
We see that a directory data has been created that contains some files and directory. One subdirectory created is 'doc'. We type
ls data/doc/
to see its content
0.xml 12.xml 15.xml 18.xml 20.xml 23.xml 26.xml 29.xml 31.xml 3.xml 6.xml 9.xml
10.xml 13.xml 16.xml 19.xml 21.xml 24.xml 27.xml 2.xml 32.xml 4.xml 7.xml
11.xml 14.xml 17.xml 1.xml 22.xml 25.xml 28.xml 30.xml 33.xml 5.xml 8.xml
We have a look at the multipart document 0.xml. Later we will make a very unbalanced collection split with one storage server containing the documents of this file, another server containing the documents of the file 1.xml and 2.xml and the third server containing the rest of the documents. We will show that the weighting of the result documents is the same as if we would have used one server only. The goal is to show that strus allows us to distribute the search index arbitrarily without affecting weighting, because in both cases we use the same statistics for weighting.
First we chose an entry in the first document that we want to have within the best matches. This way we show that the weighting is also stable for the smallest sub-collection.
less data/doc/0.xml
It shows us the following list (only 3 items displayed here)
<?xml version="1.0" encoding="UTF-8" standalone="yes" ?>;
<list>
<item><id>25</id><title>Dead Love Songs</title><artist>The Black</artist><date>2008-11-25 05:43:04.124028+00</date><upc></upc><note></note></item>
<item><id>46</id><title>Music of India - Volume 1 (SANTOOR)</title><artist>Musenalp</artist><date>2008-11-25 17:31:54.456355+00</date><upc></upc><note></note></item>
<item><id>2616</id><title>Vianoce</title><artist>Sklo</artist><date>2008-12-19 20:49:47.115832+00</date><upc></upc><note></note></item>
....
The second entry with id 46 contains the words "Music" and "India". This will be our example query terms. As ground truth we will first insert the whole collection into one storage. The resulting ranklist of one server for the query "Music India" will be our reference ranklist.
Create the document storage
We create the storage with command line tools. We could also create it with the strus API, but commands to create a storage are not part of the example implementation of this article. The storage is created with the following command:
strusCreate -s "path=storage; metadata=doclen UINT16, date UINT32"
Start the servers
We first start the statistics server:
./strusStatisticsServer.py &
and we get
Starting server ...
Listening on 0.0.0.0:7183...
Then we start one storage server.
./strusStorageServer.py -P &
and we get
Starting server ...
Listening on 0.0.0.0:7184...
Then we start the HTTP server.
./strusHttpServer.py &
and we get
Starting server ...
Listening on port 80
Insert all documents into one storage
Now we use cURL to insert the collection. We use a prepared script for this. The script looks as follows:
if [ "$#" -lt 2 ]; then
echo "Usage: $0 <server-port> <start-range> [<end-range>]" >&2
exit 1
fi
port=`expr 0 \+ $1`
start=`expr 0 \+ $2`
if [ "$#" -lt 3 ]; then
end=$start
else
end=`expr 0 \+ $3`
fi
for i in $(seq $start $end)
do
curl -X POST -d @data/doc/$i.xml localhost:80/insert/$port --header "Content-Type:text/xml"
done
The script takes the HTTP server port and the range of documents to insert as argument. The call to insert the complete collection looks as follows:
./insert_docs.sh 7184 0 34
and we get a list of 34 replies with the number of documents inserted with each call of cURL that looks like this:
OK 5090
OK 5513
OK 8560
OK 9736
OK 9708
OK 9751
....
Issue the example query (one storage)
Now you can issue the query "Music India" with your favorite browser with the following URL:
http:
You get the following results. The document we seletected from the first file is marked in the ranklist: 
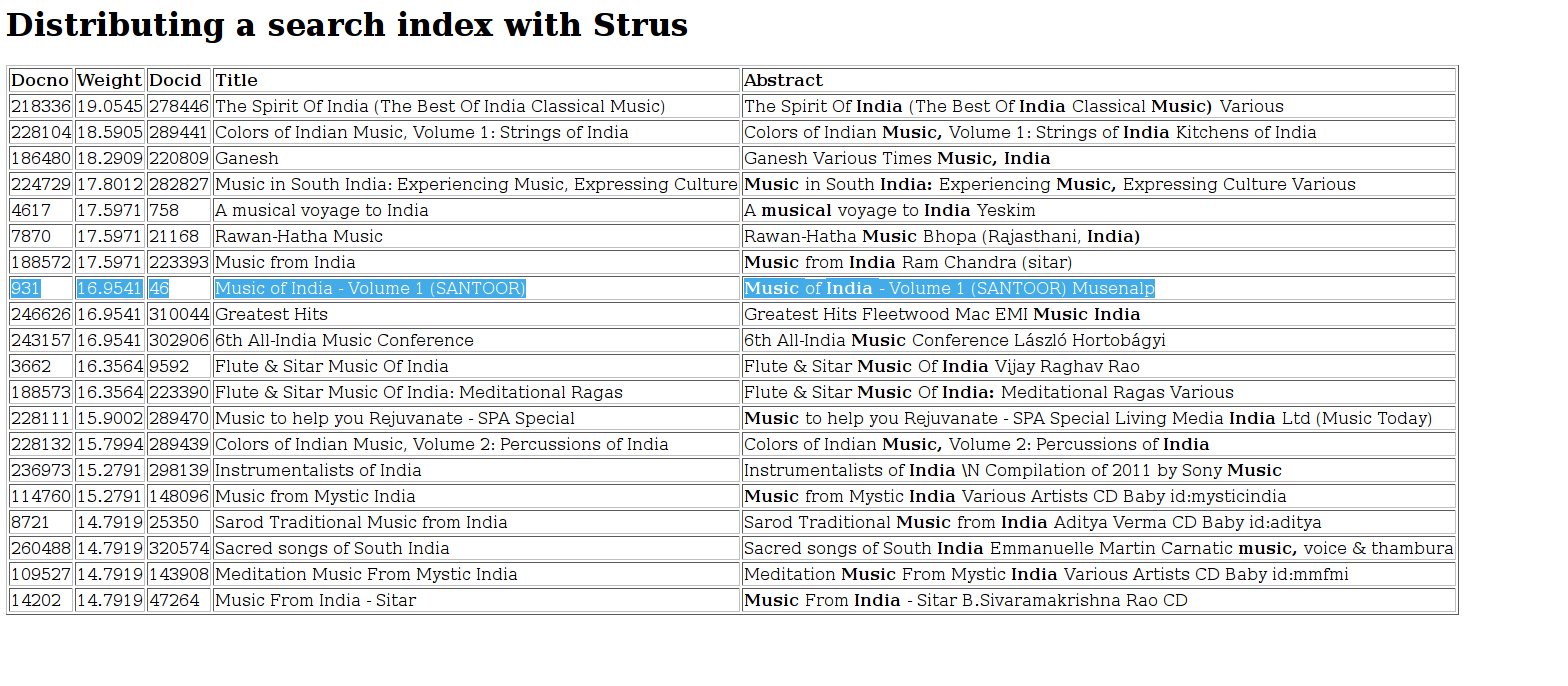
Distribute the search index
Now we build the same collection on three storage nodes. We first shutdown all servers:
ps -fe | grep python | grep strus | awk '{print $2}' | xargs kill -s SIGTERM
and we create 3 search indexes (we include the server port in the file name):
strusCreate -s "path=storage7184; metadata=doclen UINT16, date UINT32"
strusCreate -s "path=storage7185; metadata=doclen UINT16, date UINT32"
strusCreate -s "path=storage7186; metadata=doclen UINT16, date UINT32"
and we get
storage successfully created.
storage successfully created.
storage successfully created.
Now we restart all servers again, but this time with 3 storage servers on port 7184,7185 and 7186. First we start the statistics server:
./strusStatisticsServer.py -p 7183 &
and we get
Starting server ...
Listening on 0.0.0.0:7183...
then the storage servers
./strusStorageServer.py -P -p 7184 -c "path=storage7184; cache=512M; statsproc=default" &
./strusStorageServer.py -P -p 7185 -c "path=storage7185; cache=512M; statsproc=default" &
./strusStorageServer.py -P -p 7186 -c "path=storage7186; cache=512M; statsproc=default" &
and we get
Starting server ...
Listening on 0.0.0.0:7184...
Load local statistics to publish ...
Starting server ...
Listening on 0.0.0.0:7185...
Load local statistics to publish ...
Starting server ...
Listening on 0.0.0.0:7186...
Load local statistics to publish ...
The HTTP server is started with the ports of the storage servers as arguments. When we started it without argument, it used the default storage server port as only server to access.
./strusHttpServer.py 7184 7185 7186 &
and we get
Starting server ...
Listening on port 80
As explained in the beginning, we insert one multipart document into the storage (7184), two of them into the second (7185) and the rest into the third (7186). We do this with our insert_docs command:
./insert_docs.sh 7184 0 0 &
./insert_docs.sh 7185 1 2 &
./insert_docs.sh 7186 3 34 &
When all scripts are finished, we verify, that the documents went really to different servers. For this we check the index sizes:
ls -lh storage718* | grep total
and we see that the storage index sizes are really different:
total 1.9M
total 5.9M
total 97M
Issue the example query (distributed index)
Now we issue the same query "Music India" again:
http:
And we get the following results. The document we seletected from the first multipart document inserted is marked in the ranklist as in the result for one server:

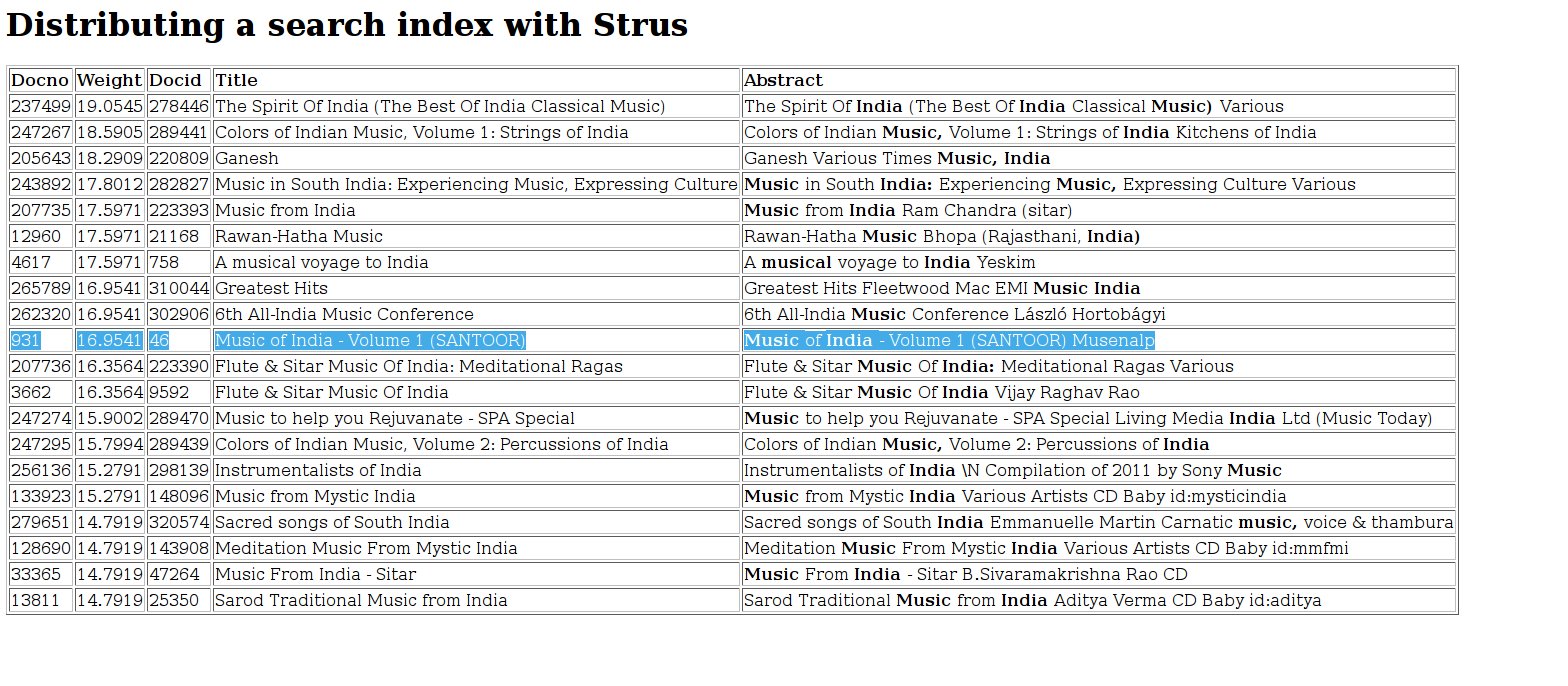
We see that the ranklists with one or three servers are the same with the following exeptions:
-
The document numbers are different. Document numbers are not shared and local for each server. Document numbers should not be used as identifier for a document because of this. Use the document id instead.
-
Results with the same weight are ordered differently because the document number is taken as order criterion, if two weights are the equal. This is due to stability reasons that are important for browsing the results.
Resume
In my previous articles I have shown that it is possible to build simple as well as complex search applications with Strus. The model of Strus allows to match regular language patterns (with terms as alphabet) and extract tuples of tokens related to matches. You can implement classical information retrieval weighting documents as well as alternative retrieval methods that are accumulating content from documents for presentation or further processing.
Strus has a competitive performance that allows you to feed a single storage node with millions of documents within a day, and to query such collections with an immediate response. The Wikipedia demo substantiates this. In this article we saw that you can build scalable search engines with Strus. It could potentially run on a cluster with thusands of machines providing search on a collection of billions of documents.
Conclusion
Strus matches regular patterns with help of search index and allows to weight documents containing the matches and extract tuples related to matches for further processing. Nothing more. If this can provide you a brick for building solutions, you maybe think about using Strus.
The IT world got very competitive in the last decade. Software ecomomy wants to profit by this competition.
The Strus core needed less than one man year of development and the data storage is based on 3rd party software (LevelDB or alternatives). This opens it to competition. It is up to you to decide, wheter it is worth a try or not.

