This article looks at a simple parallel web crawler with GUI, in about 150 lines of code. We look at designing GUI, and then we concentrate on the webcrawler code.
Introduction
This article is using U++ framework. Please refer to Getting Started with Ultimate++ for an introduction to the environment.
U++ framework provides a HttpRequest class capable of asynchronous operation. In this example, we will exploit this capability to construct a simple single-threaded web crawler using up to 60 parallel HTTP connections.
Designing GUI
We shall provide a simple GUI to display the crawling progress:
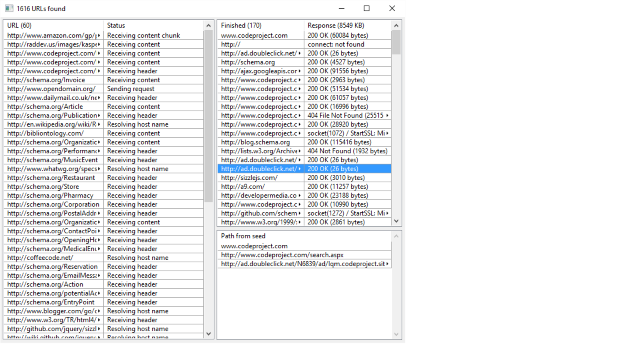
First of all, we shall design a simple GUI layout for our application. Here, the GUI is fairly simple, but it is still borderline worth to use the layout designer:

Layout consists of 3 ArrayCtrl widgets, which are basically tables. We shall use work to display progress of individual HTTP requests, finished to display result of HTTP requests that ended and, to have some fun and path that will show for any line of finished a 'path' of urls from the seed url to finished url.
Now let us use this layout and setup some things in the code:
#define LAYOUTFILE <GuiWebCrawler/GuiWebCrawler.lay>
#include <CtrlCore/lay.h>
struct WebCrawler : public WithCrawlerLayout<TopWindow> {
WebCrawler();
};
WebCrawler will be the main class of our application. The weird #include before it 'imports' designed layout into the code, namely it defines WithCrawlerLayout template class that represents our layout. By deriving from it, we add work, finished and path ArrayCtrl widgets as member variables of WebCrawler. We shall finish setting up things in WebCrawler constructor:
WebCrawler::WebCrawler()
{
CtrlLayout(*this, "WebCrawler");
work.AddColumn("URL");
work.AddColumn("Status");
finished.AddColumn("Finished");
finished.AddColumn("Response");
finished.WhenCursor = [=] { ShowPath(); }; finished.WhenLeftDouble = [=] { OpenURL(finished); };
path.AddColumn("Path");
path.WhenLeftDouble = [=] { OpenURL(path); }; total = 0;
Zoomable().Sizeable();
}
CtrlLayout is WithCrawlerLayout method that places widgets into designed positions. Rest of the code sets up lists with columns and connects some user actions on widgets with corresponding methods in WebCrawler (we shall add these methods later).
Data Model
Now with boring GUI stuff out of the way, we shall concentrate on the funny parts - webcrawler code. First, we will need some structures to keep track of things:
struct WebCrawler : public WithCrawlerLayout<TopWindow> {
VectorMap<String, int> url; BiVector<int> todo;
struct Work { HttpRequest http; int urli; };
Array<Work> http; int64 total;
VectorMap is an unique U++ container that can be thought of as a mix of array and map. It provides index based access to keys and value and a quick way to find the index of key. We will use url as a way to avoid duplicate url requests (putting url to key) and we shall put index of 'parent' url as value, so that we can later display path from the seed url.
Next we have a queue of urls to process. When extracting urls from html, we will put them to url VectorMap. That means each url has unique index in url, so we just need to have queue of indices, todo.
Finally, we shall need some buffer to keep our concurrent requests. Processing record Work simply combines HttpRequest with url index (just to know what url we are trying to process). Array is U++ container that is capable of storing objects that do not have any form of copy.
The Main Loop
We have data model, let us start writing the code. Simple things first, let us ask user about seed url:
void WebCrawler::Run()
{ String seed = "www.codeproject.com"; if(!EditText(seed, "GuiWebSpider", "Seed URL")) return;
todo.AddTail(0); url.Add(seed, 0);
Seed is the first url, so we know it will have index 0. We shall simply add it to url and todo. Now the real work begins:
Open(); while(IsOpen()) { ProcessEvents();
We shall be running the loop until user closes the window. We need to process GUI events in this loop. The rest of the loop will be handling the real stuff:
while(todo.GetCount() && http.GetCount() < 60)
{ int i = todo.Head(); todo.DropHead();
Work& w = http.Add(); w.urli = i; w.http.Url(url.GetKey(i)) .UserAgent("Mozilla/5.0 (Windows NT 6.1; WOW64; rv:11.0)
Gecko/20100101 Firefox/11.0") .Timeout(0); work.Add(url.GetKey(i)); work.HeaderTab(0).SetText
(Format("URL (%d)", work.GetCount())); }
If we have something todo and have less than 60 concurrent requests, we add a new concurrent request.
Next thing to do is to progress all active HTTP requests. HttpRequest class does this with method Do. This method, in nonblocking mode, tries to progress connection request. All we need to do is to call this method for all active requests and then read the status.
However, even if it would be possible to do this without waiting for actual sockets events in 'active' mode, well-behaved program should first wait until either it is possible to write or read from socket, to save system resources. U++ provides class SocketWaitEvent exactly for this:
SocketWaitEvent we; for(int i = 0; i < http.GetCount(); i++)
we.Add(http[i].http);
we.Wait(10);
The only problem here is that SocketWaitEvent waits only on sockets and we have the GUI to run. We workaround this by specifying the maximum wait limit to 10 ms (we know that at this time, at least periodic timer event would happen that should be processed by ProcessEvents).
With this issue cleared, we can go on to actually process requests:
int i = 0;
while(i < http.GetCount()) { Work& w = http[i];
w.http.Do(); String u = url.GetKey(w.urli); int q = work.Find(u); if(w.http.InProgress()) { if(q >= 0)
work.Set(q, 1, w.http.GetPhaseName()); i++;
}
else { String html = w.http.GetContent(); total += html.GetCount(); finished.Add(u, w.http.IsError() ? String().Cat() << w.http.GetErrorDesc()
: String().Cat() << w.http.GetStatusCode()
<< ' ' << w.http.GetReasonPhrase()
<< " (" << html.GetCount() << " bytes)",
w.urli); finished.HeaderTab(0).SetText(Format("Finished (%d)", finished.GetCount()));
finished.HeaderTab(1).SetText(Format("Response (%` KB)", total >> 10));
if(w.http.IsSuccess()) { ExtractUrls(html, w.urli); Title(AsString(url.GetCount()) + " URLs found"); }
http.Remove(i); work.Remove(q); }
}
This loop seems complex but most of the code deals with updating the GUI. HttpRequest class has handy GetPhaseName method to describe what is going on in the request. InProgress is true until request is finished (either as success or some kind of failure). If the request succeeds, we use ExtractUrls to get new urls to test from html code.
Getting New URLs
For simplicity, ExtractUrls is quite a naive implementation, all we do is scan for "http://" or "https://" strings and then read next characters that look like url:
bool IsUrlChar(int c)
{ return c == ':' || c == '.' || IsAlNum(c) || c == '_' || c == '%' || c == '/';
}
void WebCrawler::ExtractUrls(const String& html, int srci)
{ int q = 0;
while(q < html.GetCount()) {
int http = html.Find("http://", q); int https = html.Find("https://", q); q = min(http < 0 ? https : http, https < 0 ? http : https);
if(q < 0) return;
int b = q;
while(q < html.GetCount() && IsUrlChar(html[q]))
q++;
String u = html.Mid(b, q - b);
if(url.Find(u) < 0) { todo.AddTail(url.GetCount()); url.Add(u, srci); }
}
}
We put all candidate urls to url and todo to be processed by the main loop.
Final Touches
At this point, all the hard work is done. The rest of the code is just two convenience functions, one that opens url on double clicking finished or path list:
void WebCrawler::OpenURL(ArrayCtrl& a)
{
String u = a.GetKey(); WriteClipboardText(u); LaunchWebBrowser(u); }
(We put the url on clipboard too as bonus.)
Another function fills path list to show path from the seed url to url in finished list:
void WebCrawler::ShowPath()
{ path.Clear();
if(!finished.IsCursor())
return;
int i = finished.Get(2); Vector<String> p;
for(;;) {
p.Add(url.GetKey(i)); if(i == 0) break;
i = url[i]; }
for(int i = p.GetCount() - 1; i >= 0; i--) path.Add(p[i]);
}
Here, we are using 'double nature' of VectorMap to traverse from child url back to seed using indices.
The only little piece of code missing now is MAIN:
GUI_APP_MAIN
{
WebCrawler().Run();
}
and here we go, simple parallel web crawler with GUI, in about 150 lines.
Useful Links
History
- 5th May, 2020: Initial version
- 7th May, 2020: ExtractUrls now scans for "https" too
- 20th September, 2020: Crosslink with "Getting started" article

