Introduction
The article implements a Base62 encoding algorithm to utilize Base64 schema.
Background
The Base62 encoding is usually used in URL Shortening, which is a conversion between a Base 10 integer and its Base 62 encoding. Base62 has 62 characters, 26 upper letters from A to Z, 26 lower letters from a to z, 10 numbers from 0 to 9, it is simliar with Base64, except it excludes +, / and =, which are used in Base62 as value 62, 63 and padding.
Most of the online resources of Base62 encoding is for URL Shortening conversion, which is only one number conversion, this article does not refer to that algorithm, it actually converts a binary bytes array and its Base62 encoding characters array as Base64 does.
Here is the Base64 encoding schema:
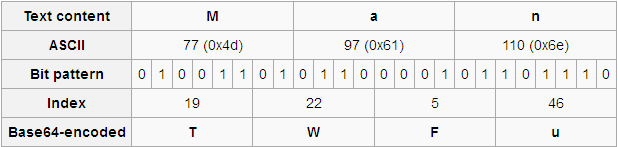
The Base62 uses same one. Base64 uses 6 bits as grouping because 6 bits maximum value is 64, but Base62 seems not be able use 6 bits becasue value 62 is between maximum 5 bits value 32 and maximum 6 bits value 64. To overcome this, a special character is chosen from the 62 code charcters as a prefix flag, here we use the last one '9' as the special character, '9' is used as the special prefix flag to indicate its following character is one of 6 bits value 61, 62 and 63. In summary, for any 6 bits value in [0, 63]:
0~60 : One Character from "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz012345678"
61 : Two Character '9A'
62 : Two Character '9B'
63 : Two Character '9C'
The encoding binary data to plain characters usually has a side effect, the encoded context has bigger bytes size, the reason is that the mapping from a byte to a Base16, Base32, Base64, etc. is actually a mapping from 256 values to 16, 32 or 64 values, for example, to express a byte, at least need two HEX codes (Base16).
To illuminate this, a 4 bits Base62 encoding test is attached in the download package (folder EncodeTest4Bits), which will produce double size encoded plain text file. Here is the 4 bits Base62 encoding table:
String[] Base62EncodeTable = {
"00","01","02","03","04","05","06","07","08","09","0a","0b","0c","0d","0e","0f","0g","0h",
"0i","0j","0k","0l","0m","0n","0o","0p","0q","0r","0s","0t","0u","0v","0w","0x","0y","0z",
"0A","0B","0C","0D","0E","0F","0G","0H","0I","0J","0K","0L","0M","0N","0O","0P","0Q","0R",
"0S","0T","0U","0V","0W","0X","0Y","0Z","10","11","12","13","14","15","16","17","18","19",
"1a","1b","1c","1d","1e","1f","1g","1h","1i","1j","1k","1l","1m","1n","1o","1p","1q","1r",
"1s","1t","1u","1v","1w","1x","1y","1z","1A","1B","1C","1D","1E","1F","1G","1H","1I","1J",
"1K","1L","1M","1N","1O","1P","1Q","1R","1S","1T","1U","1V","1W","1X","1Y","1Z","20","21",
"22","23","24","25","26","27","28","29","2a","2b","2c","2d","2e","2f","2g","2h","2i","2j",
"2k","2l","2m","2n","2o","2p","2q","2r","2s","2t","2u","2v","2w","2x","2y","2z","2A","2B",
"2C","2D","2E","2F","2G","2H","2I","2J","2K","2L","2M","2N","2O","2P","2Q","2R","2S","2T",
"2U","2V","2W","2X","2Y","2Z","30","31","32","33","34","35","36","37","38","39","3a","3b",
"3c","3d","3e","3f","3g","3h","3i","3j","3k","3l","3m","3n","3o","3p","3q","3r","3s","3t",
"3u","3v","3w","3x","3y","3z","3A","3B","3C","3D","3E","3F","3G","3H","3I","3J","3K","3L",
"3M","3N","3O","3P","3Q","3R","3S","3T","3U","3V","3W","3X","3Y","3Z","40","41","42","43",
"44","45","46","47"
};
Using the Code
To encode a byte array:
byte[] buf = new byte[rFileLength];
String encodedStr = Base62.base62Encode(buf);
To decode a char array:
char[] chars = new char[len];
byte[] decodedArr = Base62.base62Decode(chars);
Here is the Base62 class to implement the algorithm. The encoding function is mainly from the Base64 reference code. The difference is there is no padding in Base62, and the special flag charater '9' is prefixed for value 61, 62 and 63.
The encoding part processes 3 bytes group in sequence for the input bytes, for the major part of binary input, it regularly converts 3 bytes to 4 characters, each character is corresponding to a 6 bits unit in the 3 bytes group. For the ending part of binary input, either the third char is the last one, or the second char is the last one.
The decoding part processes 4 characters group in sequence for the input characters, the 4 characters group does not count in the CODEFLAG '9'. For example, the first 4 characters group is 'CAjC' which is from the group '9C9Aj9C'. For major part of characters input, each 4 charaters group converts to 3 bytes binary. After main loop, the tail characters less than 4 characters are processed.
Finally, the famous Lena is used for the test to recall some good old time. :)
Base62.Java
import java.util.ArrayList;
import java.util.Map;
import java.util.HashMap;
public class Base62
{
private static final String CODES =
"ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789";
private static final char CODEFLAG = '9';
private static StringBuilder out = new StringBuilder();
private static Map<Character, Integer> CODEMAP = new HashMap<Character, Integer>();
private static void Append(int b)
{
if(b < 61)
{
out.append(CODES.charAt(b));
}
else
{
out.append(CODEFLAG);
out.append(CODES.charAt(b-61));
}
}
public static String base62Encode(byte[] in)
{
out.setLength(0);
int b;
for (int i = 0; i < in.length; i += 3) {
b = (in[i] & 0xFC) >> 2;
Append(b);
b = (in[i] & 0x03) << 4;
if (i + 1 < in.length) {
b |= (in[i + 1] & 0xF0) >> 4;
Append(b);
b = (in[i + 1] & 0x0F) << 2;
if (i + 2 < in.length)
{
b |= (in[i + 2] & 0xC0) >> 6;
Append(b);
b = in[i + 2] & 0x3F;
Append(b);
}
else
{
Append(b);
}
}
else
{
Append(b);
}
}
return out.toString();
}
public static byte[] base62Decode(char[] inChars) {
CODEMAP.put('A', 61);
CODEMAP.put('B', 62);
CODEMAP.put('C', 63);
ArrayList<Byte> decodedList = new ArrayList<Byte>();
int[] unit = new int[4];
int inputLen = inChars.length;
int n = 0;
int m = 0;
char ch1 = 0;
char ch2 = 0;
Byte b = 0;
while (n < inputLen)
{
ch1 = inChars[n];
if (ch1 != CODEFLAG)
{
unit[m] = CODES.indexOf(ch1);
m++;
n++;
}
else
{
n++;
if(n < inputLen)
{
ch2 = inChars[n];
if(ch2 != CODEFLAG)
{
unit[m] = CODEMAP.get(ch2);
m++;
n++;
}
}
}
if(m == 4)
{
b = new Byte((byte) ((unit[0] << 2) | (unit[1] >> 4)));
decodedList.add(b);
b = new Byte((byte) ((unit[1] << 4) | (unit[2] >> 2)));
decodedList.add(b);
b = new Byte((byte) ((unit[2] << 6) | unit[3]));
decodedList.add(b);
m = 0;
}
}
if(m != 0)
{
if(m == 1)
{
b = new Byte((byte) ((unit[0] << 2) ));
decodedList.add(b);
}
else if(m == 2)
{
b = new Byte((byte) ((unit[0] << 2) | (unit[1] >> 4)));
decodedList.add(b);
}
else if (m == 3)
{
b = new Byte((byte) ((unit[0] << 2) | (unit[1] >> 4)));
decodedList.add(b);
b = new Byte((byte) ((unit[1] << 4) | (unit[2] >> 2)));
decodedList.add(b);
}
}
Byte[] decodedObj = decodedList.toArray(new Byte[decodedList.size()]);
byte[] decoded = new byte[decodedObj.length];
for(int i = 0; i < decodedObj.length; i++) {
decoded[i] = (byte)decodedObj[i];
}
return decoded;
}
}
Points of Interest
The current method simply uses a fixed index value group 61, 62, 63 as the special character index. This can be improved with applying a statistical analysis on the input for which 3 bytes group have minimum distribution with a 6 bits grouping, then use that 3 bytes group instead current one, by this way, the encoding size inflation rate will be most down to close the Base64 encoding.
To verify if the decoded image is identical with the original image, I recomment using Notepad++ HEX editor plugin.
History
- 3rd Feburary, 2016: Initial date
Reference

