Semantic databases are the up-and-coming thing. Here's the beginnings of an implementation using MongoDB as the supporting database back-end.
Introduction
As I've written previously:
Semantic databases are a new kind of database store. Because such a database engine does not yet exist, we have to build it on top of existing engines. In my previous articles, I discussed how a semantic database could be built on top of a SQL database. In this article, we will explore how a semantic database can be built on top of a NoSQL database, specifically MongoDB, and illustrate some of the advantages of using a NoSQL database.
With the advent in December 2015 of MongoDB version 3.2, this became much easier (and realistic) to do, because version 3.2 supports left outer joins with the $lookup aggregator.
This article covers creating basic CRUD operations in MongoDB for a semantic database.
Part II will cover a real world example and will undoubtedly uncover implementation flaws in this article. While Part I covers working with the relational hierarchy of a single semantic type, Part II will cover working with the relationships between semantic types.
Part III will be a surprise! 
Where's the Code?
The code can be found on GitHub at https://github.com/cliftonm/mongodbSemanticDatabase.
As this is an evolving effort, please download the latest code from there. For example, some of the use of Newtonsoft (particularly JObject) that exists in this article has already been replaced with BsonDocument in the latest implementation and tests.
The Foundational Concepts of a Semantic Database
Fundamentally, a semantic database captures relationships. There are two primary kinds of relationships::
- Static, implicit relationships that define the structure (give meaning) to a semantic term (a symbol). These are typically expressed with the same terms used in object oriented programming "has a" and "is a kind of."
- Static or dynamic explicit relationships, where the relationship itself has a meaning expressed in a semantic term and where dynamic relationships can change over time. In programming, these relationships are usually expressed implicitly in the code, for example, a dictionary or other key-value pair collections. Dynamic relationships often have a time frame -- a beginning and an ending.
I've written about explicit dynamic relationships in my series on Relationship Oriented Programming:
A semantic database actually combines the qualities of semantics and relationality, as we will demonstrate here.
An Example of a Static, Implicit Semantic Relationship
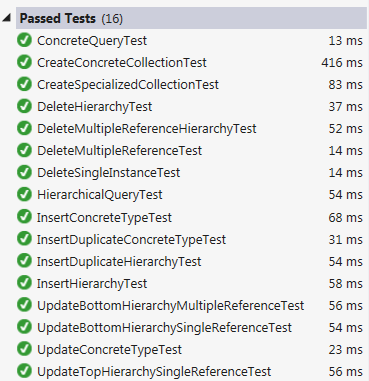
A person's name is a good example of implicit semantic relationships. People's names (but not in all cultures and of course, there are variances even within a culture) consist of a first name and last name. The symbols "first name" and "last name" are themselves specializations of the symbol "name". Finally, the symbol "name" is a specialization of the symbol (in this data type) "string." These are all "has a" and "is a kind of" relationships.
Examples of an Explicit Relationship
Relationships exist between specialized semantic types, and we can sub-categorize them into static and dynamic relationships.
Examples of a Static Relationship
Fixed relationships are those that never change over time. For example, a person always has a relationship to two other people, "mother" and "father." During a person's lifetime, there is a static relationship between the person and their birth sign (Leo, Gemini, etc.) Of course, the stars that make up that constellation are actually in a dynamic relationship.
Examples of a Dynamic Relationship
In contrast to a static relationship, not every person has a son or daughter. This relationship may come into existence, and when it does, it's associated with a particular timestamp. A person's name can be a dynamic relationship -- consider nicknames and aliases. Ownership, residence, marriage, religious affiliation, rap sheet, party affiliation -- these are are example of potentially dynamic relationships. Most relationships are dynamic, occurring (and possibly recurring) in a particular time interval.
Explicit Relationships are Themselves Semantic
Relationships such as "mother", "daughter", "Republican", "Buddhist" are semantic. They express either a relationship or a state, so that we can say:
"[X] is the [Y] of [Z]" -- expresses the relationship, as in, "Marc is the son of Elisabeth"
or
"[X] is a [Y]" -- expresses a relational state, as in, "Marc is an Anthroposophist"
or
"[X] [Y] [Z]" -- expresses an activity, as in "Marc owns a cat"
These are all semantically (haha) describing relationships. When we say something stateful, such as "[X] is a [Y]", we can convert this to a prepositional phrase to describe the relationship, becoming "[X] is [Z] with [Y]" or similar, though you may have to exercise your imagination a bit. For example, "Marc is a man", as a state of being, can be described relationally as "Marc is a human with male gender", or "Marc has the gender male." In either case, we've done something useful -- we've identified a class of state (gender) that lets us describe explicitly the relationship between Marc and a gender. Enough though with language semantics!
Structural Relationship and Symbol Relationship
A semantic database must capture both the hierarchy, the structure, of a symbol as well as the symbol's relationship to other symbols. If, for example, we have two symbols, one for a person's name and another for an address, we can easily query for atypical relationships: "give me all the people who's first names are also street names in the town they live in."
The Advantage of a NoSQL Database
While this is a query one can easily imagine in a SQL database, it assumes that the schema already exists in which to make this query. The advantage of a NoSQL database is that the schema itself is dynamic:
- The structure of implicit symbols change (think of how names and addresses vary among cultures.)
- New symbols can be easily added (simply add a new collection.)
- New relationships between symbols can be easily added (simply add a collection with two fields associating the IDs of two collections.)
In a SQL database, this would require manipulating the schema, whereas in a NoSQL database, this is unnecessary (though one still wants to pay attention to indexing for performance reasons.)
Using a NoSQL database eliminates a considerable amount of the work required in simulating a true semantic database, but as mentioned earlier, until the advent of the $lookup aggregator, doing so was relegated to the client-side implementation rather than the being handled by the server-side. Handling it on the client-side was not, in our opinion, a feasible solution because of the memory and bandwidth required to pull across all the records of one collection simply to eliminate many of them with a left join of another collection, which also had to be read fully into client-side memory. Happily, the MongoDB $lookup aggregator solves that problem.
A NoSQL Database is Still Not a Semantic Database
There is still considerable work that needs to be done (as is also true for a SQL database), but that work is really only in the realm of:
- creating collections
- creating the queries dynamically at runtime
- maintaining a normalized database
- reference counting
- handling inserts so that data is not duplicated
- handling deletes so that data being referenced by other collections is not deleted until the number of references is 0
- handling updates so that data being referenced by other collections is maintained and only the parent reference changes
Normalized vs. Denormalized Data in a Semantic Database
A NoSQL database easily handles denormalized database--a sub-document within a document. It is, of course, easy to create a denormalized schema in a SQL database as well, which is the bane of most legacy databases. The golden rule with a semantic database is:
A semantic database relies on the fact that the data is normalized -- a relationship between two symbols is based on a many-to-many relationship collection. It is NOT built on comparing field values. Using the person name and street address example earlier, a typical SQL query would look like this:
select * from Person p
left join Address a on a.StreetName = p.FirstName
A semantic query looks like this (in SQL):
select * from Name n
left join FirstName fn on fn.NameId = n.Id
left join PersonName pn on pn.FirstNameId = n.NameId
left join Person p on p.Id = pn.PersonId
left join StreetName sn on sn.NameId = n.Id
left join AddressStreetName asn on asn.StreetNameId = sn.Id
left join Address a on a.Id = asn.AddressId
This looks horrid (and I'm not sure I even got it right), and it is, but it expresses both the semantic structure and the relationship between two otherwise unrelated symbols:
So What's the Point?

The point is that with a semantic database, relationships that are not explicit between two symbols can still be queried. One can, for example, ask of a semantic database:
- can I relate a
Person and an Address via the person's first name? - what are the ways I can relate a
Person and an Address other than an explicit relationship?
A semantic database can recurse through the semantic structure to discover (and validate) new ways of relating data! A non-semantic database (whether in SQL or NoSQL) simply cannot do that, because there is no discoverable path from "FirstName" to "StreetName".
A semantic database stand apart from the rest of the database world in its ability to discover new relationships based not on explicitly defined structural or dynamic relationships but on relationships that result in shared semantics..
Applications
Three applications come to mind immediately:
- Big Data
- Internet of Things
- Records Management
The analysis of Big Data ("data sets so large or complex that traditional data processing applications are inadequate" -- https://en.wikipedia.org/wiki/Big_data) is, in my uninformed opinion, still reliant on human beings explicitly determining the relationships between data sets. A semantic database could easily be queried for previously unknown relationships, as well as facilitating the association of disparate data sets with explicit relational meaning.
Second, as with Big Data, the Internet of Things is going to be generating vast amounts of data. In my opinion, the only way to successfully correlate that data into something that has meaning beyond the initial dataset is to make it semantic and store it in a semantic database.
Records Management (things like medical, emergency, criminal) is already a vast, messy, and uncorrelated system of information. Furthermore, it is always changing:
- in schema -- the information people want to track
- in lifecycle -- illnesses come (and hopefully go), fires are put out, people commit new crimes, etc.
- in relationship -- relationships between people and things are always changing
A semantic database is a solution to the critical problem of diverse, incompatible, and limited databases that currently hold our public and not-so-private information.
Implementation
As stated earlier, in a true semantic database, we could ask these "can I relate..." and "give me the intersection of ..." questions and have the server-side do the heavy lifting. But since a true semantic database doesn't exist, we have to do that heavy lifting ourselves. But first, we have to implement the core functionality. Part II will explore the more interesting things we can do with a semantic database.
What You'll Need
If you've never used MongoDB with C#, you'll need to:
- Download and install the MongoDB server
- Download and install the 2.2.0 or greater MongoDB .NET Driver
- Run the MongoDB server, mongod.exe, either in a console window or as a service
- The 3.2 64 bit version of mongod.exe is typically found in C:\Program Files\MongoDB\Server\3.2\bin
- Optionally download and install RoboMongo, so you can inspect your collections in a nice GUI.
Test Driven Development
This is a good usage of test driven development, as we can state a lot about the preconditions, functions, and post-conditions that we expect from a semantic database. As we implement each unit test, adding new behavioral requirements, and implementing the methods to get the test to pass, you'll notice that sometimes the previous tests and usually the implementation are frequently refactored. These are the tests, conceptually, that we want to perform (the term "collection" refers here to a NoSQL collection):
- Creation of a concrete semantic type collection
- Creation of a hierarchical semantic type, demonstrating how non-concrete specializations (sounds like an oxymoron) results in both concrete and many-to-many relationship collections
- Define relationships between semantic types with a many-to-many relationship collection
- Relationships:
- Be able to ask "what are explicit relationships of a semantic type?"
- Be able to ask "what are discoverable (implicit) relationships of a semantic type?"
- Be able to ask "what is the structure of this semantic type?"
- For both concrete and specialized semantic types:
Insert: Automatically creating the many-to-many relationship instance documents and concrete collection documentsUpdate:
- Updating a singleton document
- Decoupling a document with multiple references into two discrete documents and updating many-to-many references
Delete:
- Deleting a singleton document and its hierarchy
- Deleting hierarchy collections only when a document is referenced by more than one specialized semantic instance
Query:
- Query a concrete semantic type
- Query a specialized concrete type, auto-generating the joins to resolve down to the concrete instance
- Query two or more semantic types, auto-generating the joins to associate the semantic types
Naming Conventions
The following naming conventions are used:
- Collection and database names are Camel case (the first letter of an identifier is lowercase and the first letter of each subsequent concatenated word is capitalized)
- Collections are singular in name
- Field names are Camel case
- Many-to-many collections
- Singular name
- The two collection objects referenced are separated by an underscore
- The ID's binding the collections in the form:
- [collectionName1]Id
- [collectionName2]Id
Creation of a Concrete Semantic Type Collection
We'll start with creating some concrete semantic types. A concrete semantic type usually describes a single concrete type, so it's pretty basic. There is a always a question with regards to the extreme of creating a concrete type. For example, we can define a phone number:
PhoneNumber: string (or even number)
or:
phoneNumber
countryCode : intareaCode : intexchange :<sup> </sup>intsubscriberId : int
or:
phoneNumber
countryCode
areaCode
exchange
subscriberId
No, we will not break down "number" into bits 0-32! The last example represents over-specification. We can determine when we are over-specifying a semantic type by asking "are we moving from something specific back to something general?" For example:
- Phone number to country code, area code, exchange and subscriber ID is moving from general to specific.
- Country code to "
number" is moving from specific to general.
This gives us a clearly defined way of deciding when to stop the hierarchy of types.
Rules / Validation
Country codes, area codes, exchanges -- they all have certain rules, so even though they are integers, they have format rules, minimum and maximum length constraints, and so forth. We will eventually (but not in this article) want to associate a concrete type with a collection of rules from a rule table.
The more specific we define a semantic type, the more likely it is that we will run into representational conflicts, especially cultural ones. Not all countries comply with the North American Numbering Plan -- only 24 apparently do so.
Our first semantic types are therefore:
countryCodeareaCodeexchangesubscriberId
We observe that a semantic type then always terminates in a field we will call "value" and furthermore, we note that a concrete semantic type never has more than one value field. If it did, it would be a composite type, and we would want to break this down into its constituent sub-types. So here we have another rule:
a concrete semantic type often has only one value field.
This may, at first, seem very strange, counter-intuitive, and inefficient, but it allows us to fully express data semantically. Lookup collections (key-value pairs) are one exception to this rule.
A second thing that results from a semantic type is that there are often placeholder collections with no concrete values. I call these "abstract" collections, as they contain only references to child collections.

[TestMethod]
public void CreateConcreteCollection()
{
SemanticDatabase sd = Helpers.CreateCleanDatabase();
Assert.IsTrue(sd.GetCollections().Count == 0, "Collection should be 0 length.");
Schema schema = Helpers.InstantiateSchema("{name: 'countryCode'}");
sd.InstantiateSchema(schema);
List<string> collections = sd.GetCollections();
Assert.IsTrue(collections.Count == 1, "Expected 1 collection.");
Assert.IsTrue(collections[0] == "countryCode", "Collection does not match expected name");
}
The workhorse for this implementation is a ridiculous workaround because of a bug in 2.2.0 (this kind of bug really leaves a sour taste when it comes to open source projects):
public void CreateCollection(string collectionName)
{
var data = new BsonDocument(collectionName, "{Value : 0}");
var collection = db.GetCollection<BsonDocument>(collectionName);
collection.InsertOne(data);
var result = collection.DeleteOne(new BsonDocument
("_id", data.Elements.Single(el => el.Name == "_id").Value));
}}
Create a Hierarchical Semantic Type
Here, we test creating collections from a hierarchy:
[TestMethod]
public void CreateSpecializedCollection()
{
SemanticDatabase sd = Helpers.CreateCleanDatabase();
Assert.IsTrue(sd.GetCollections().Count == 0, "Collection should be 0 length.");
Schema schema = Helpers.InstantiateSchema(@"
{
name: 'phoneNumber',
subtypes:
[
{name: 'countryCode'},
{name: 'areaCode'},
{name: 'exchange'},
{name: 'subscriberId'},
]
}");
sd.InstantiateSchema(schema);
List<string> collections = sd.GetCollections();
Assert.IsTrue(collections.Count == 5, "Expected 5 collections.");
Assert.IsTrue(collections.Contains("phoneNumber"));
Assert.IsTrue(collections.Contains("countryCode"));
Assert.IsTrue(collections.Contains("areaCode"));
Assert.IsTrue(collections.Contains("exchange"));
Assert.IsTrue(collections.Contains("subscriberId"));
}}
Again, there's no magic here -- empty collections are created:
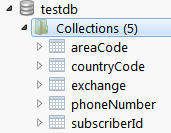
Because these are schema-less document collections, there of course are no field definitions.
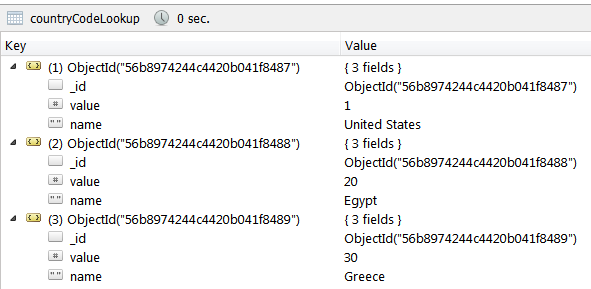
Insert Into a Concrete Semantic Type
Here, we test inserting records into a concrete semantic type. The backing implementation is very bare-bones, as we still have to write the more complicated, and interesting, insertion of a semantic hierarchy. But first, the basic test:
[TestMethod]
public void InsertConcreteTypeTest()
{
SemanticDatabase sd = Helpers.CreateCleanDatabase();
Assert.IsTrue(sd.GetCollections().Count == 0, "Collection should be 0 length.");
Schema schema = Helpers.InstantiateSchema(@"
{
name: 'countryCodeLookup',
concreteTypes:
{
value: 'System.Int32',
name: 'System.String'
}
}");
sd.InstantiateSchema(schema);
Assert.IsTrue(sd.GetCollections().Count == 1, "Collection should be length of 1.");
sd.Insert(schema, "{value: 1, name: 'United States'}");
sd.Insert(schema, "{value: 20, name: 'Egypt'}");
sd.Insert(schema, "{value: 30, name: 'Greece'}");
List<string> json = sd.GetAll("countryCode");
Assert.IsTrue(json[0].Contains("{ \"value\" : 1, \"name\" : \"United States\" }"));;
Assert.IsTrue(json[1].Contains("{ \"value\" : 20, \"name\" : \"Egypt\" }"));
Assert.IsTrue(json[2].Contains("{ \"value\" : 30, \"name\" : \"Greece\" }"));
}
and the basic implementation (note that it completely ignores the schema):
public void Insert(Schema schema, string json)
{
db.GetCollection<BsonDocument>(schema.Name).InsertOne(BsonDocument.Parse(json));
}
Insert Into a Semantic Hierarchy
Now, with regards to the above implementation, the astute reader may say, "well, isn't the country a semantic type?" Indeed so, so let's create a proper semantic hierarchy and write a test for inserting into a hierarchy:
The Name Collection
The collection "name" is a strange beast. It is a semantic generalization, but it also has a specific meaning -- it is the name of something. We humans are all about naming things, Arthur C. Clarke even wrote a short story about the human race being created solely for the purpose of listing all the names of God, after which the universe ended -- The Nine Billion Names of God. Therefore, "name" is a special collection in a semantic database, so that entities can be named.
Notice that we're still inserting a flattened hierarchy. We'll look at resolving duplicate field names and hierarchical inserts later on.
[TestMethod]
public void InsertHierarchyTest()
{
SemanticDatabase sd = Helpers.CreateCleanDatabase();
Assert.IsTrue(sd.GetCollections().Count == 0, "Collection should be 0 length.");
Schema schema = Helpers.InstantiateSchema(@"
{
name: 'countryCode',
concreteTypes:
{
value: 'System.Int32',
},
subtypes:
[
{
name: 'countryName',
subtypes:
[
{
name: 'name',
concreteTypes:
{
name: 'System.String'
}
}
]
}
]
}");
sd.InstantiateSchema(schema);
Assert.IsTrue(sd.GetCollections().Count == 3, "Collection should be length of 3.");
sd.Insert(schema, JObject.Parse("{value: 1, name: 'United States'}"));
sd.Insert(schema, JObject.Parse("{value: 20, name: 'Egypt'}"));
sd.Insert(schema, JObject.Parse("{value: 30, name: 'Greece'}"));
Assert.IsTrue(json[0].Contains("{ \"name\" : \"United States\" }"));
Assert.IsTrue(json[1].Contains("{ \"name\" : \"Egypt\" }"));
Assert.IsTrue(json[2].Contains("{ \"name\" : \"Greece\" }"));
json = sd.GetAll("countryName");
Assert.IsTrue(json.Count==3);
json = sd.GetAll("countryCode");
Assert.IsTrue(json[0].Contains("{ \"value\" : 1"));;
Assert.IsTrue(json[1].Contains("{ \"value\" : 20"));
Assert.IsTrue(json[2].Contains("{ \"value\" : 30"));}}
Notice the hierarchy we are creating, and that the middle semantic type, "countryName", does not have any concrete values. Why do this? Because semantically, it allows us to query two different things:
- Give me all the names of things that have names
- Give me all the names of countries
Notice how the top level implementation has become a bit more complicated, recursing into the schema structure, removing concrete types as we recurse, and adding reference IDs to parent's JSON object.
public string nsert(Schema schema, JObject jobj)
{
string id = null;
if (schema.IsConcreteType)
{
id = Insert(schema.Name, jobj);
}
else
{
JObject currentObject = GetConcreteObjects(schema, jobj);
JObject subjobj = RemoveCurrentConcreteObjects(schema, jobj);
RecurseIntoSubtypes(schema, currentObject, subjobj);
id = Insert(schema.Name, currentObject);
}}
return id;
}
Insert Duplicates Tests
We next delve into some further complexity: in a semantic database, we never duplicate a record, regardless of where it is in the hierarchy. Instead, we increment a reference count.
In a semantic database, this fully normalizes the value associated with a specific semantic type, such that we are never need to compare the values between two semantic hierarchies because we rely on the normalization the data in the semantic schema to create the "joins" between different semantic structures. This works well when the entire schema for a database is well designed but does not prevent us from having to do value comparisons between two databases.
[TestMethod]
public void InsertDuplicateHierarchyTest()
{
SemanticDatabase sd = Helpers.CreateCleanDatabase();
Assert.IsTrue(sd.GetCollections().Count == 0, "Collection should be 0 length.");
Schema schema = Helpers.InstantiateSchema(@"
{
name: 'countryCode',
concreteTypes:
{
value: 'System.Int32',
},
subtypes:
[
{
name: 'countryName',
subtypes:
[
{
name: 'name',
concreteTypes:
{
name: 'System.String'
}
}
]
}
]
}");
sd.InstantiateSchema(schema);
Assert.IsTrue(sd.GetCollections().Count == 3, "Collection should be length of 3.");
sd.Insert(schema, JObject.Parse("{value: 1, name: 'United States'}"));
List<string> json;
json = sd.GetAll("name");
Assert.IsTrue(json.Count == 1);
Assert.IsTrue(json[0].Contains("\"name\" : \"United States\""));
json = sd.GetAll("countryName");
Assert.IsTrue(json.Count == 1);
json = sd.GetAll("countryCode");
Assert.IsTrue(json.Count == 1);
Assert.IsTrue(json[0].Contains("\"value\" : 1"));
sd.Insert(schema, JObject.Parse("{value: 1, name: 'United States'}"));
json = sd.GetAll("name");
Assert.IsTrue(json.Count == 1);
Assert.IsTrue(json[0].Contains("\"_ref\" : 2 }"));
json = sd.GetAll("countryName");
Assert.IsTrue(json.Count == 1);
Assert.IsTrue(json[0].Contains("\"_ref\" : 2 }"));
json = sd.GetAll("countryCode");
Assert.IsTrue(json.Count == 1);
Assert.IsTrue(json[0].Contains("\"_ref\" : 2 }"));
}
The insert method is refactored again to get this test to pass, but you should see a pattern emerging here between a concrete semantic instance insertion and a hierarchy insertion:
public string Insert(Schema schema, JObject jobj)
{
string id = null;
if (schema.IsConcreteType)
{
int refCount;
if (IsDuplicate(schema.Name, jobj, out id, out refCount))
{
IncrementRefCount(schema.Name, id, refCount);
}
else
{
JObject withRef = AddRef1(jobj);
id = Insert(schema.Name, withRef);
}
}
else
{
JObject currentObject = GetConcreteObjects(schema, jobj);
JObject subjobj = RemoveCurrentConcreteObjects(schema, jobj);
RecurseIntoSubtypes(schema, currentObject, subjobj);
int refCount;
if (IsDuplicate(schema.Name, currentObject, out id, out refCount))
{
IncrementRefCount(schema.Name, id, refCount);
}
else
{
JObject withRef = AddRef1(currentObject);
id = Insert(schema.Name, withRef);
}
}
return id;
}
Concrete Semantic Query Test
This Query call for the a concrete semantic type is really nothing more than a call to the GetAll() method, but we test it here anyways.
[TestClass]
public class QueryTests
{
[TestMethod]
public void ConcreteQueryTest()
{
SemanticDatabase sd = Helpers.CreateCleanDatabase();
Assert.IsTrue(sd.GetCollections().Count == 0, "Collection should be 0 length.");
Schema schema = Helpers.InstantiateSchema(@"
{
name: 'countryCodeLookup',
concreteTypes:
{
value: 'System.Int32',
name: 'System.String'
}
}");
sd.InstantiateSchema(schema);
Assert.IsTrue(sd.GetCollections().Count == 1, "Collection should be length of 1.");
sd.Insert(schema, JObject.Parse("{value: 1, name: 'United States'}"));
List<JObject> records = sd.Query(schema);
Assert.IsTrue(records.Count == 1);
Assert.IsTrue(records[0].Contains("{\"value\":1,\"name\":\"United States\""));
}
}
Hierarchical Semantic Query Test
Client-Side
This query returns flattened records (so much for a document database!) of a semantic instance at the specified hierarchy.
[TestMethod]
public void HierarchicalQueryTest()
{
SemanticDatabase sd = Helpers.CreateCleanDatabase();
Assert.IsTrue(sd.GetCollections().Count == 0, "Collection should be 0 length.");
Schema schema = Helpers.InstantiateSchema(@"
{
name: 'countryCode',
concreteTypes:
{
value: 'System.Int32',
},
subtypes:
[
{
name: 'countryName',
subtypes:
[
{
name: 'name',
concreteTypes:
{
name: 'System.String'
}
}
]
}
]
}");
sd.InstantiateSchema(schema);
Assert.IsTrue(sd.GetCollections().Count == 3, "Collection should be length of 3.");
sd.Insert(schema, JObject.Parse("{value: 1, name: 'United States'}"));
sd.Insert(schema, JObject.Parse("{value: 20, name: 'Egypt'}"));
sd.Insert(schema, JObject.Parse("{value: 30, name: 'Greece'}"));
List<BsonDocument> json;
json = sd.Query(schema);
Assert.IsTrue(json.Count == 3);
Assert.IsTrue(json[0].ToString().Contains("\"value\" : 1, \"name\" : \"United States\""));
Assert.IsTrue(json[1].ToString().Contains("\"value\" : 20, \"name\" : \"Egypt\""));
Assert.IsTrue(json[2].ToString().Contains("\"value\" : 30, \"name\" : \"Greece\""));
}
We can refactor the query for a client-side implementation:
public List<BsonDocument> Query(Schema schema, string id = null)
{
List<BsonDocument> records = new List<BsonDocument>();
records = GetAll(schema.Name, id);
foreach (BsonDocument record in records)
{
record.Remove("_ref");
foreach (Schema subtype in schema.Subtypes)
{
string childIdName = subtype.Name + "Id";
string childId = record[childIdName].ToString();
record.Remove(childIdName);
List<BsonDocument> childRecords = Query(subtype, childId);
if (childRecords.Count == 1)
{
childRecords[0].Elements.ForEach(p => record.Add(p.Name, childRecords[0][p.Name]));
}
}
}
return records;
}
Server-Side
Conversely, we could build a MongoDB query to run the query server-side. In the Mongo console, it would look like this:
db.countryCode.aggregate(
{$lookup: {from: "countryName", localField:"countryNameId",
foreignField: "_id", as: "countryName"} },
{$unwind: "$countryName"},
{$lookup: {from: "name", localField:"countryName.nameId", foreignField: "_id", as: "name"} },
{$unwind: "$name"},
{$project: {"value": "$value", "name": "$name.name", "_id":0} }
)
See my article on Working with MongoDB's $lookup Aggregator to learn more about how to use $lookup for joining collections.
We'll extend our test to test server-side as well:
json = sd.QueryServerSide(schema);
Assert.IsTrue(json.Count == 3);
Assert.IsTrue(json[0].ToString().Contains("\"value\" : 1, \"name\" : \"United States\""));
Assert.IsTrue(json[1].ToString().Contains("\"value\" : 20, \"name\" : \"Egypt\""));
Assert.IsTrue(json[2].ToString().Contains("\"value\" : 30, \"name\" : \"Greece\""));
We execute a server-side query, building the aggregators by inspecting the schema:
public List<BsonDocument> QueryServerSide(Schema schema, string id = null)
{
var collection = db.GetCollection<BsonDocument>(schema.Name);
List<string> projections = new List<string>();
List<string> pipeline = BuildQueryPipeline(schema, String.Empty, projections);
pipeline.Add(String.Format
("{{$project: {{{0}, '_id':0}} }}", String.Join(",", projections)));
var aggr = collection.Aggregate();
pipeline.ForEach(s => aggr = aggr.AppendStage<BsonDocument>(s));
List<BsonDocument> records = aggr.ToList();
return records;
}
and:
protected List<string> BuildQueryPipeline
(Schema schema, string parentName, List<string> projections)
{
List<string> pipeline = new List<string>();
schema.ConcreteTypes.ForEach(kvp => projections.Add
(String.Format("'{0}':'${1}'", kvp.Key, parentName + kvp.Key)));
foreach (Schema subtype in schema.Subtypes)
{
pipeline.Add(String.Format("{{$lookup: {{from: '{0}', localField:'{2}{1}',
foreignField: '_id', as: '{0}'}} }},", subtype.Name, subtype.Name + "Id", parentName));
pipeline.Add(String.Format("{{$unwind: '${0}'}}", subtype.Name));
List<string> subpipeline = BuildQueryPipeline(subtype, subtype.Name + ".", projections);
if (subpipeline.Count > 0)
{
pipeline[pipeline.Count - 1] = pipeline.Last() + ",";
pipeline.AddRange(subpipeline);
}
}
return pipeline;
}
Delete Tests
Delete Concrete Instance Test
Here, we test deleting a concrete instance:
[TestMethod]
public void DeleteSingleInstanceTest()
{
SemanticDatabase sd = Helpers.CreateCleanDatabase();
Assert.IsTrue(sd.GetCollections().Count == 0, "Collection should be 0 length.");
Schema schema = Helpers.GetSimpleTestSchema();
sd.InstantiateSchema(schema);
Assert.IsTrue(sd.GetCollections().Count == 1, "Collection should be length of 1.");
sd.Insert(schema, JObject.Parse("{value: 1, name: 'United States'}"));
sd.Insert(schema, JObject.Parse("{value: 20, name: 'Egypt'}"));
sd.Insert(schema, JObject.Parse("{value: 30, name: 'Greece'}"));
List<BsonDocument> bson = sd.GetAll("countryCodeLookup");
Assert.IsTrue(bson.Count == 3);
sd.Delete(schema, JObject.Parse("{value: 1, name: 'United States'}"));
bson = sd.GetAll("countryCodeLookup");
Assert.IsTrue(bson.Count == 2);
Assert.IsTrue(bson[0].ToString().Contains("\"value\" : 20, \"name\" : \"Egypt\""));
Assert.IsTrue(bson[1].ToString().Contains("\"value\" : 30, \"name\" : \"Greece\""));
}
The implementation for a deletion is very similar to an insert, where we decrement the reference count if greater than 1, otherwise we delete the collection record:
protected string Delete(Schema schema, BsonDocument doc)
{
string id = null;
if (schema.IsConcreteType)
{
int refCount = GetRefCount(schema.Name, doc, out id);
if (refCount == 1)
{
Delete(schema.Name, id);
}
else
{
DecrementRefCount(schema.Name, id, refCount);
}
}
else
{
BsonDocument currentObject = GetConcreteObjects(schema, doc);
BsonDocument subjobj = RemoveCurrentConcreteObjects(schema, doc);
DeleteRecurseIntoSubtypes(schema, currentObject, subjobj);
int refCount = GetRefCount(schema.Name, currentObject, out id);
if (refCount == 1)
{
Delete(schema.Name, id);
}
else
{
DecrementRefCount(schema.Name, id, refCount);
}
}
return id;
}
Since the above was so similar to the insert process, I decided to write the entire implementation first, then the additional tests!
Delete Multiple Reference Test
[TestMethod]
public void DeleteMultipleReferenceTest()
{
SemanticDatabase sd = Helpers.CreateCleanDatabase();
Assert.IsTrue(sd.GetCollections().Count == 0, "Collection should be 0 length.");
Schema schema = Helpers.GetSimpleTestSchema();
sd.InstantiateSchema(schema);
Assert.IsTrue(sd.GetCollections().Count == 1, "Collection should be length of 1.");
sd.Insert(schema, JObject.Parse("{value: 1, name: 'United States'}"));
sd.Insert(schema, JObject.Parse("{value: 20, name: 'Egypt'}"));
sd.Insert(schema, JObject.Parse("{value: 30, name: 'Greece'}"));
sd.Insert(schema, JObject.Parse("{value: 1, name: 'United States'}"));
List<BsonDocument> bson = sd.GetAll("countryCodeLookup");
Assert.IsTrue(bson.Count == 3);
sd.Delete(schema, JObject.Parse("{value: 1, name: 'United States'}"));
bson = sd.GetAll("countryCodeLookup");
Assert.IsTrue(bson.Count == 3);
Assert.IsTrue(bson[0].ToString().Contains("\"value\" : 1, \"name\" : \"United States\""));
Assert.IsTrue(bson[1].ToString().Contains("\"value\" : 20, \"name\" : \"Egypt\""));
Assert.IsTrue(bson[2].ToString().Contains("\"value\" : 30, \"name\" : \"Greece\""));
sd.Delete(schema, JObject.Parse("{value: 1, name: 'United States'}"));
bson = sd.GetAll("countryCodeLookup");
Assert.IsTrue(bson.Count == 2);
Assert.IsTrue(bson[0].ToString().Contains("\"value\" : 20, \"name\" : \"Egypt\""));
Assert.IsTrue(bson[1].ToString().Contains("\"value\" : 30, \"name\" : \"Greece\""));
}
Delete Hierarchy Test
[TestMethod]
public void DeleteHierarchyTest()
{
SemanticDatabase sd = Helpers.CreateCleanDatabase();
Assert.IsTrue(sd.GetCollections().Count == 0, "Collection should be 0 length.");
Schema schema = Helpers.GetTestHierarchySchema();
sd.InstantiateSchema(schema);
Assert.IsTrue(sd.GetCollections().Count == 3, "Collection should be length of 3.");
sd.Insert(schema, JObject.Parse("{value: 1, name: 'United States'}"));
sd.Insert(schema, JObject.Parse("{value: 20, name: 'Egypt'}"));
sd.Insert(schema, JObject.Parse("{value: 30, name: 'Greece'}"));
List<BsonDocument> bson;
bson = sd.Query(schema);
Assert.IsTrue(bson.Count == 3);
sd.Delete(schema, JObject.Parse("{value: 1, name: 'United States'}"));
bson = sd.Query(schema);
Assert.IsTrue(bson.Count == 2);
Assert.IsTrue(bson[0].ToString().Contains("\"value\" : 20, \"name\" : \"Egypt\""));
Assert.IsTrue(bson[1].ToString().Contains("\"value\" : 30, \"name\" : \"Greece\""));
}
Delete Multiple Reference Hierarchy Test
[TestMethod]
public void DeleteMultipleReferenceHierarchyTest()
{
SemanticDatabase sd = Helpers.CreateCleanDatabase();
Assert.IsTrue(sd.GetCollections().Count == 0, "Collection should be 0 length.");
Schema schema = Helpers.GetTestHierarchySchema();
sd.InstantiateSchema(schema);
Assert.IsTrue(sd.GetCollections().Count == 3, "Collection should be length of 3.");
sd.Insert(schema, JObject.Parse("{value: 1, name: 'United States'}"));
sd.Insert(schema, JObject.Parse("{value: 20, name: 'Egypt'}"));
sd.Insert(schema, JObject.Parse("{value: 30, name: 'Greece'}"));
sd.Insert(schema, JObject.Parse("{value: 2, name: 'United States'}"));
List<BsonDocument> bson;
bson = sd.Query(schema);
Assert.IsTrue(bson.Count == 4);
sd.Delete(schema, JObject.Parse("{value: 2, name: 'United States'}"));
bson = sd.Query(schema);
Assert.IsTrue(bson.Count == 3);
Assert.IsTrue(bson[0].ToString().Contains("\"value\" : 1, \"name\" : \"United States\""));
Assert.IsTrue(bson[1].ToString().Contains("\"value\" : 20, \"name\" : \"Egypt\""));
Assert.IsTrue(bson[2].ToString().Contains("\"value\" : 30, \"name\" : \"Greece\""));
}
The Missing Test
There is an important test that is missing:
In terms of a "master schema", since a NoSQL database is schema-less, this isn't necessarily easy to extract from the database itself, however tools like Variety, a schema analyzer, look like a really good start. Of course, to determine the schema, the tool has to actually inspect the records in each collection. Ideally, we should have a separate master schema, but I haven't implemented that at the time of this writing.
Update Tests
Updates are the most complicated / interesting:
- The complete set of values for the original semantic type must be provided as well as the new values -- we can't actually just update a value based on some primary key.
- If there are no other references to the semantic type, the concrete types can simply be updated.
- If there are other references:
- the reference count for the current type must be decremented
- a new instance of the type must be inserted
- the super-type's "foreign key" reference must be updated
- this process needs to recurse upwards through the hierarchy
Point #1 is one of the most distinguishing features of a semantic database as compared to a typical relational database.
Update a Concrete Semantic Type Test
This is the simplest test, where a concrete semantic type (one with no sub-types) is updated:
[TestMethod]
public void UpdateConcreteTypeTest()
{
SemanticDatabase sd = Helpers.CreateCleanDatabase();
Assert.IsTrue(sd.GetCollections().Count == 0, "Collection should be 0 length.");
Schema schema = Helpers.GetSimpleTestSchema();
sd.InstantiateSchema(schema);
Assert.IsTrue(sd.GetCollections().Count == 1, "Collection should be length of 1.");
sd.Insert(schema, BsonDocument.Parse("{value: 1, name: 'United States'}"));
sd.Insert(schema, BsonDocument.Parse("{value: 20, name: 'Egypt'}"));
sd.Insert(schema, BsonDocument.Parse("{value: 30, name: 'Greece'}"));
List<BsonDocument> bson = sd.GetAll("countryCodeLookup");
Assert.IsTrue(bson.Count == 3);
sd.Update(schema, BsonDocument.Parse("{value: 1, name: 'United States'}"),
BsonDocument.Parse("{value: 1, name: 'United States of America'}"));
bson = sd.GetAll("countryCodeLookup");
Assert.IsTrue(bson.Count == 3);
Assert.IsTrue(bson[0].ToString().Contains
("\"value\" : 1, \"name\" : \"United States of America\""));
Assert.IsTrue(bson[1].ToString().Contains("\"value\" : 20, \"name\" : \"Egypt\""));
Assert.IsTrue(bson[2].ToString().Contains("\"value\" : 30, \"name\" : \"Greece\""));
}
Update the Bottom of a Semantic Hierarchy Test
Here, we do a very similar test as above, except this time we test updating the bottom element of a hierarchy:
[TestMethod]
public void UpdateBottomHierarchySingleReferenceTest()
{
SemanticDatabase sd = Helpers.CreateCleanDatabase();
Assert.IsTrue(sd.GetCollections().Count == 0, "Collection should be 0 length.");
Schema schema = Helpers.GetTestHierarchySchema();
sd.InstantiateSchema(schema);
Assert.IsTrue(sd.GetCollections().Count == 3, "Collection should be length of 3.");
sd.Insert(schema, BsonDocument.Parse("{value: 1, name: 'United States'}"));
sd.Insert(schema, BsonDocument.Parse("{value: 20, name: 'Egypt'}"));
sd.Insert(schema, BsonDocument.Parse("{value: 30, name: 'Greece'}"));
List<BsonDocument> bson;
bson = sd.Query(schema);
Assert.IsTrue(bson.Count == 3);
sd.Update(schema, BsonDocument.Parse("{value: 1, name: 'United States'}"),
BsonDocument.Parse("{value: 1, name: 'United States of America'}"));
bson = sd.Query(schema);
Assert.IsTrue(bson.Count == 3);
Assert.IsTrue(bson[0].ToString().Contains
("\"value\" : 1, \"name\" : \"United States of America\""));
Assert.IsTrue(bson[1].ToString().Contains("\"value\" : 20, \"name\" : \"Egypt\""));
Assert.IsTrue(bson[2].ToString().Contains("\"value\" : 30, \"name\" : \"Greece\""));
}
Update the Top of the Hierarchy Test
Here, we test updating a concrete value at the top of the semantic type hierarchy:
[TestMethod]
public void UpdateTopHierarchySingleReferenceTest()
{
SemanticDatabase sd = Helpers.CreateCleanDatabase();
Assert.IsTrue(sd.GetCollections().Count == 0, "Collection should be 0 length.");
Schema schema = Helpers.GetTestHierarchySchema();
sd.InstantiateSchema(schema);
Assert.IsTrue(sd.GetCollections().Count == 3, "Collection should be length of 3.");
sd.Insert(schema, BsonDocument.Parse("{value: 1, name: 'United States'}"));
sd.Insert(schema, BsonDocument.Parse("{value: 20, name: 'Egypt'}"));
sd.Insert(schema, BsonDocument.Parse("{value: 30, name: 'Greece'}"));
List<BsonDocument> bson;
bson = sd.Query(schema);
Assert.IsTrue(bson.Count == 3);
sd.Update(schema, BsonDocument.Parse("{value: 1}"), BsonDocument.Parse("{value: 3}"));
bson = sd.Query(schema);
Assert.IsTrue(bson.Count == 3);
Assert.IsTrue(bson[0].ToString().Contains("\"value\" : 3, \"name\" : \"United States\""));
Assert.IsTrue(bson[1].ToString().Contains("\"value\" : 20, \"name\" : \"Egypt\""));
Assert.IsTrue(bson[2].ToString().Contains("\"value\" : 30, \"name\" : \"Greece\""));
}
Update Multiple Reference Test
Here, we test updating the bottom of the hierarchy when a concrete value is referenced by two separate semantic instances:
[TestMethod]
public void UpdateBottomHierarchyMultipleReferenceTest()
{
SemanticDatabase sd = Helpers.CreateCleanDatabase();
Assert.IsTrue(sd.GetCollections().Count == 0, "Collection should be 0 length.");
Schema schema = Helpers.GetTestHierarchySchema();
sd.InstantiateSchema(schema);
Assert.IsTrue(sd.GetCollections().Count == 3, "Collection should be length of 3.");
sd.Insert(schema, BsonDocument.Parse("{value: 1, name: 'United States'}"));
sd.Insert(schema, BsonDocument.Parse("{value: 20, name: 'Egypt'}"));
sd.Insert(schema, BsonDocument.Parse("{value: 30, name: 'Greece'}"));
sd.Insert(schema, BsonDocument.Parse
("{value: 40, name: 'United States'}"));
List<BsonDocument> bson;
bson = sd.Query(schema);
Assert.IsTrue(sd.GetAll("name").Count == 3);
Assert.IsTrue(bson.Count == 4);
sd.Update(schema, BsonDocument.Parse("{value: 40, name: 'United States'}"),
BsonDocument.Parse("{value: 40, name: 'Romania'}"));
bson = sd.Query(schema);
Assert.IsTrue(sd.GetAll("name").Count == 4);
Assert.IsTrue(bson.Count == 4);
Assert.IsTrue(bson[0].ToString().Contains("\"value\" : 1, \"name\" : \"United States\""));
Assert.IsTrue(bson[1].ToString().Contains("\"value\" : 20, \"name\" : \"Egypt\""));
Assert.IsTrue(bson[2].ToString().Contains("\"value\" : 30, \"name\" : \"Greece\""));
Assert.IsTrue(bson[3].ToString().Contains("\"value\" : 40, \"name\" : \"Romania\""));
}
Implementation
The high level implementation is a recursive process in which we determine whether a record's fields can be updated (there is only one reference) or whether the reference count needs to be decremented and a new instance created, which percolates back up the hierarchy. We also have a special case handler for partial semantic types -- one in which the flattened data does not extend down to the lowest sub-type, as is the case in the "update the top of the hierarchy" test above. Notice the complexity of this operation and the reliance on the _id for each record as we drill into the hierarchy, which is necessary to determine whether, on unwinding from the recursion, a super-type's reference needs to be updated.
protected string Update(Schema schema, BsonDocument docOriginal,
BsonDocument docNew, string schemaId)
{
string id = null;
if (schema.IsConcreteType)
{
int refCount = GetRefCount(schema.Name, docOriginal, out id);
if (refCount == 1)
{
Update(schema.Name, id, docOriginal, docNew);
}
else
{
DecrementRefCount(schema.Name, id, refCount);
id = InternalInsert(schema, docNew);
}
}
else
{
BsonDocument currentOriginalObject = GetConcreteObjects(schema, docOriginal);
BsonDocument record = null;
if (schemaId == null)
{
if (currentOriginalObject.Elements.Count() == 0)
{
throw new SemanticDatabaseException("Cannot update the a semantic type
starting with the abstract type " + schema.Name);
}
record = GetRecord(schema.Name, currentOriginalObject);
if (record == null)
{
throw new SemanticDatabaseException("The original record for the semantic type " +
schema.Name + " cannot be found.\r\nData: " + currentOriginalObject.ToString());
}
}
else
{
record = GetRecord(schema.Name, new BsonDocument("_id", new ObjectId(schemaId)));
if (record == null)
{
throw new SemanticDatabaseException("An instance of " +
schema.Name + " with _id = " + schemaId + " does not exist!");
}
}
BsonDocument subOriginalJobj = RemoveCurrentConcreteObjects(schema, docOriginal);
if (subOriginalJobj.Elements.Count() == 0)
{
id = record.Elements.Single(el => el.Name == "_id").Value.ToString();
int refCount = record.Elements.Single(el => el.Name == "_ref").Value.ToInt32();
if (refCount == 1)
{
BsonDocument currentNewObject = GetConcreteObjects(schema, docNew);
Update(schema.Name, id, record, currentNewObject);
}
else
{
DecrementRefCount(schema.Name, id, refCount);
id = InternalInsert(schema, docNew);
}
}
else
{
BsonDocument currentNewObject = GetConcreteObjects(schema, docNew);
BsonDocument subNewJobj = RemoveCurrentConcreteObjects(schema, docNew);
UpdateRecurseIntoSubtypes(schema, record, currentOriginalObject,
subOriginalJobj, currentNewObject, subNewJobj);
id = record.Elements.Single(el => el.Name == "_id").Value.ToString();
int refCount = record.Elements.Single(el => el.Name == "_ref").Value.ToInt32();
if (refCount == 1)
{
Update(schema.Name, id, record, currentNewObject);
}
else
{
DecrementRefCount(schema.Name, id, refCount);
id = InternalInsert(schema, docNew);
}
}
}
return id;
}
Conclusion
So far so good -- although there are some TODOs and gaps in the path testing, this is sufficient to move forward with Part II. I realize the ideas presented here are probably crazy, and this article is somewhat boring because it's basically just unit tests. However, things should get a bit more exciting in Part II, and certainly in Part III!
History
- 12th February, 2016: Initial version

