
NB: This is a quick read. You can zoom through while waiting for a build to process. :)
Introduction
The concept of the Single Page Application (SPA) has emerged over the past few years - sometimes, you use it without even knowing it. A lot of the websites you visit frequently use the concept ... Office365, Gmail, Facebook and the Management console for Azure are a few that come to mind. The main change from the traditional mode of posting everything back to the server for page refreshes and new content, is that the single page application keeps the user 'on the same page', and aims to only swap out the interactive parts of the 'application' that change during the life cycle of the page. In the old regime, we didn't really have to worry too much about memory in the browser - I mean why would we? .. the user spent a very short time on each page before it was completely refreshed with a postback to the server which processed the data sent in and then served up a new fresh page to the user. #WhatMemoryLeak?
The single page application paradigm means that the user stays mostly on a single page, and only the individual 'bits of the dom' that they interact with, actually change. For example, is there really a need to do a full post-back to the server in order to show a 'compose message' form? ... can't we just make it modal over the inbox list instead to allow the user to keep moving quickly? ... thus the life-cycle of the page, and our entire relationship with the page life-cycle and the user experience has changed, and requires things to be thought through more carefully than before.
This article covers some general advice in relation to optimizing memory and the user experience when dealing with single page applications, and when using the SPA concept within hybrid mobile applications. The article hits some low hanging fruit, is not exhaustive, and I am sure some experienced readers will offer some additional suggestions that can be used to expand the article.
I have attached a basic MVC ASP.NET application that demonstrates some of the concepts. It is put together in VS 2015 community edition (if you don't have it already, go get it - it's free!)
Background
I was recently optimizing a hybrid mobile 'single page' application that started its life off nice and smooth from a performance point of view, but unfortunately was now starting to drag. As I guessed, it was a classic case of memory leak over time, caused by objects not being cleaned up carefully when they were finished with, and a few other things that were giving the app an undeserved bad rep. The degrading performance took place in a hybrid mobile application developed in Cordova with Visual Studio tools, which has been designed as a single page mobile application. It might just as well however be happening in an ASP.NET application running form a server in a standard browser. In addition to the memory leaks, some other things had crept into the application that were causing a less than optimal user experience. This article covers general advice handed out for the project in question, but is also very applicable to standard Single Page Apps. The project in question used JavaScript/JQuery and also KnockoutJS, so those are addressed here.
Article Scope
The application this article helped optimize, was a hybrid mobile application, using an SPA framework built using KnockoutJS, SammyJS as a router and JQuery/JavaScript as the core libraries. The topics here address those main items. The article is not intended to be very indepth, it is a quick overview of some things that helped in this particular project, and hopefully may help you get some quick wins if you have a similar project that's starting to drag a bit.
Click/Event Binding
The application in question used a combination of both Knockout bound events and standard JS/JQuery event binding / hooking.
For example:
$('#MyButton').click(
function(
{
alert('yeo');
}
)
)
Very simple and very common stuff. A problem can occur however if these event hooks build up and up over time and are not released correctly - they can end up being orphaned, and outside the scope of the Garbage Collector, thus staying around in memory and contributing to eventual slowdown. To keep on top of this so that it does not become an issue, we need to ensure that we have both a setup, and tear-down of all objects and their associated events in place.
JQuery
Example - setup
$('#MyButton').click(function() { return false; });
In JQuery < 1.7, the way to do this was to use the unbind method as follows - (teardown)
$('#MyButton').unbind('click');
What this actually does is remove all events that may be bound to the CLICK event of the button in question. Recently, JQuery > 1.7 has given us more precise control by using the 'off' API call - (teardown)
$('#MyButton').off('click');
If you want to have multiple different methods called from the OnClick event, you can use namespaces:
$('#MyButton').on('click.SomeNamespace', function() { });
$('#MyButton').on('click.SomeOtherNamespace', function() { });
$('#MyButton').off('click.SomeOtherNamespace');
Knockout
Depending on how the Knockout model is used, it needs to know if you are finished with bindings you create in Click events.
<button id='myButton' data-bind="click: doStuff">Click it</button>
The above tells KO to bind the OnClick of the element to a method called doStuff(). If this is hanging around for a while, it can just be reused. However, if we are explicitly tearing down that element (and a surrounding popup modal form let's say), then we need to tell KO about this so it can clean up for us:
The 'cleanNode' method will tell KO to remove any handlers attached to a node.
ko.cleanNode(element)
The 'removeNode' method will tell KO to remove any handlers attached to a node, and then also remove the node itself.
ko.removeNode(element)
The place for using a clean/remove node would be for example where we create a new modal popup, or a form, for user input, and are then finished with it. In this instance, we are done, so we should use clean/remove.
Working example:
var element = $('#myButton');
ko.cleanNode(element);
Examples
In order to demonstrate what can happen, I attached a small demo to the article.
(1) Correctly Tearing Down Hooked Events...
In the first part of the demo, we have a simple loop to create a stack of DIVs, and we then hook them up to events (in this case, using a class name).
$('#myButtonCreate').on('click', function (event) {
for (x = 1; x < 1000; x++) {
i++;
var html = "<div class='childObj'
id='obj" + i + "'>Object ID " + i + "</div>";
$("#divStack").prepend(html);
}
});
$('#myButtonEvents').click(
function () {
$('.childObj').click(function () {
alert('here at: ' + $(this).attr('id'));
});
}
);
After we create, we can count the number of nodes in the dom using a simple call:
$("*").length
This gives us an idea how things are looking.
When we remove only DIVs, using '.empty()', we are left with the events still present...
$('#myButtonRemoveOnlyDivs').click(
function () {
$('.childObj').empty();
}
);
when we remove the divs using '.remove()', this takes out the divs and their associated children and events...
$('#myButtonRemoveDivAndEvents').click(
function () {
$('.childObj').remove();
}
);
Now the count is down where it is expected (allowing for what events are also present apart from the test divs!)
(2) Creating Multiple Events on a Single Listener Using Namespaces
Setting up buttons to click for (1) adding 2 x events to a single button with namespaces (2) adding another button to remove one event from the namespace of the first button.
<h3>Use Namespaces to isolate discrete code in similar events</h3>
<input type="button" id="myNameSpaceEvents"
value="5 - Add namespace events" />
<input type="button" id="myNameSpaceEventsRemoveOne"
value="6 - Remove single namespace event" />
Setting up code that first adds 2 x events (alert X and Y) to the button, and secondly, code that selectively removes one of the events from the button click event using the namespace option.
$('#myNameSpaceEvents').on('click.NameSpaceX',
function () {
alert('NS X');
});
$('#myNameSpaceEvents').on('click.NameSpaceY',
function () {
alert('NS Y');
});
$('#myNameSpaceEventsRemoveOne').click(
function () {
$('#myNameSpaceEvents').off('click.NameSpaceX');
});
The above code is also demonstrated in the attached small demo MVC app.
Chrome Mem Stats
There is a very useful little piece of JavaScript code that only works with Chrome that is *well* worth your while checking out. In effect, it gives you the ability to track JavaScript memory live on your webpage, and see visually the impact of different things on JavaScript memory, without having to take heap snapshots or kill your screen real estate by having dev tools open as well, etc. It works really well to demonstrate how the code above effects memory usage (i.e.: adding divs and then removing them with/without removing events correctly).
Memory-stats.js is available on github. If you download the attached sample project (see top of article!), I have included it there so you can see how to utilise it in an ASP.NET Visual Studio project.
Setting It Up
To make use of the code, you *must* start Chrome using command line flags. I don't want to have to do this each time for the command line, so I add it to my Visual Studio 'Browse with' menu as follows:
- From the 'browser run' menu, click 'browse with'...
- In the popup menu, locate chrome.exe (generally in program files... Google .. Chrome .. application), and input the start parameters shown:
- A new browser-run type will now appear in your menu, all ready to display its goodness...
Using mem-Stats
There are a couple of steps to integrating memStats in your site.
import memory-Stats.js- Reference it in your cshtml file:
<script src="~/Scripts/memory-stats.js"></script>
- Include code to hook the library and display the graph. In this case, it displays at the bottom of the page.
- Declare as a
script variable:
var stats = new MemoryStats();
- Make a function that you can call:
function callStats(){
stats.domElement.style.position = 'fixed';
stats.domElement.style.right = '0px';
stats.domElement.style.bottom = '0px';
document.body.appendChild(stats.domElement);
requestAnimationFrame(function rAFloop() {
stats.update();
requestAnimationFrame(rAFloop);
}
)}
The above code sets the position of the graph, and calls the stats.update() function in a loop.
Testing with mem-Stats - Setup
In our example, I created a new pair of buttons - one to show the stats graph (you might like to hide/show this as required), and another to generate lots of sample garbage memory usage.
<h3>Use Chrome Memory memStats Monitor</h3>
<input type="button" id="chromeStats" value="Show monitor" />
<input type="button" id="garbageGen" value="Generate garbage" />
These are hooked into click events that call the relevant methods.
$('#chromeStats').click(
function(){
callStats();
});
$('#garbageGen').click(
function(){
generateGarbage();
});
The Results
Let's now look at how it works in practice.
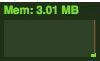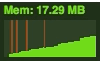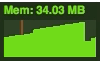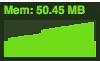
| Before we start | |
After adding 100k div objects | |
After adding OnClick events to the 100k div objects | |
After removing the DIVs, but not the associated events | |
After removing the DIVs and associated events | |
It's very easy to see how without cleaning out objects and events after use, they could easily creep up and up and ultimately have a negative impact on performance. So, if you set it up, don't forget to tear it down!
Careful with Knockout Observables...
Observables are a key aspect of Knockout, giving the ability to have two way binding between form fields, data and the model data, and more. However, one has to be extremely careful only to use them where necessary. It is very easy to fall into the trap of having long linked chained observables that cascade one into the other and cause the application to slow down badly.
Observables can have the same effect in a large model as index maintenance in SQL ... for updating/importing large volumes of data, it may be better to turn off indexes, import the data, the turn your indexes back on.
For this tip, go through your code, and models, and ensure that you are only using an observable where it is absolutely needed. For example, if a KO Model Object member is not being used for data binding, or is not absolutely required to be observed by other members but is simply a storage object, then there is no need for it to be observable and this attribute should be changed. Enough changes on this level can be significant overall.
Consider actually if you need observables at all in certain places of your application, or if you can maintain a separate JS object to represent your data. This means that you lose some of the KO goodness, but have more control over the cascade observable effect and related overhead.
You can also turn off the cascade notifications in the model - see here for details:
Break Up Your Knockout Modal
It can often be the case that an original Knockout Model used in a SPA can grow to be extremely large over time. Due to this, the internal overhead of the automation of observables, computed values etc also grows, and ultimately, makes the overarching application less efficient and speedy than it could be. Initial designs may have been based on the premise of a lightweight application with limited screens, however, the complexity of the screens and interactions between objects naturally grows considerably from the first iteration. The main problem is when we need to do something to one discrete part of the model, we effectively update the entire thing. This can cause the application to drag and requires some redesign.
Break out your heavy, integrated model, into smaller chunks, from this...
to this...
In addition to the internals of a complex model causing things to move slower than they used to when you started, it can also cause a large knock-on effect when you have a very complex/large model with a corresponding amount of data-bindings. Let's face it, is the user really capable of working with all of your data-bound HTML objects at one time? ... the answer is most likely no. Therefore, only bind to what the user can deal with at one time, and save the automation for Knockout/JS objects that operate under the hood.
To explain this more clearly - here is a UI pattern in a project that grew over time...
The model represented a user in the organisation. To start with, it was a simple "User details" (simple information), and a 1->M observable array of security roles the user was participating in:
In the user security roles table, it showed a list of roles (admin, general, IT...), and was snappy, fast, and did its job efficiently. Over time, the complexity of the project grew, and the number of pieces of information, and linked/observable/data-bound arrays that were loaded *each and every time the page or model was loaded* got bloated out of proportion...
Sure, everything in the bloated tab control was valid form a business process point of view, but complaints about usability and speed were starting to come in - something had to change.
The high level solution for managing a problem like this, is to break out any large single models into a number of small, related, but not connected models. To do this, break each component part, from the top down, into discrete models. Where cascading updates are required on changes, create a JS method that in the observable or computed event of change, calls a relevant method in the related/linked model, but only for dirty deltas. Always keep in the back of your mind 'does the user need this data right now, or can it wait, can I pull/show it on demand...'.
So ... to revisit ... here's the problem:
and without changing the UI, here is the solution...
Saving Data
In an SPA, we can save data for a number of reasons ... two of these would be as backup in case something goes wrong and the user is working with large amounts of data, and to push as a CRUD update to server. It is not uncommon to keep a large object model in memory, and serialize this each and every time the user makes a change. This is not efficient - you should only really be saving the change delta that has occurred.
The objective of optimizing in this area, is to ensure that where possible, we only change what has changed, not entire models. For example, if we add a new task to say, a to-do list, there is no need to add this to the Object model, then save the entire model. Instead, by all means, push it to the model (if needed), but then only save the delta, that is, the actual part that has been added/changed, as a standard JS object represented as a string.
This pattern makes sense as many times, when the data is brought back to the server, it is decomposed into row level structures. Deltas changes can be encapsulated in a series of payload packets that are sent to the server, and then used to feed CRUD as needed.
Example data packet:
- DateTime: 22FEB2016Z13:45:23
- PacketID: ABC123
- DeviceInfo: {json data}
- UserInfo: {json data}
- RecordID: 3736354456
- Action: Update
- Type: Task.TodoList.Note
- Payload: {json data}
As the user progresses through the application, any number of the above packets can be constructed and placed in a bus queue. On sync, instead of sending the entire model, we send a series of micro packet bursts (these could be batched) to the server, which updates the relevant table data as appropriate.
This pattern also gives us a solid method of tracking user actions from a data point of view, allowing storage of packets to act as a versioning system if required.
Controls That Load Data
It is common when not using a framework like say Ionic for Hybrid mobile, or bootstrap for desktop, to start off with one style of user interface, and end up with something that is ... well, let's be kind and say 'less than optimal'.
In some cases, the original choice of controls is either wrong, or the controls are not implemented in an optimal manner that promotes an efficient, timely and responsive experience for the user. An example of this is where you use a predictive/scroller plugin to display client names. It may have started out with 30 entries, and seemed snappy and great at the time, but when it gets pushed with a live list of 2500+ clients, it becomes a heavy overhead not only on the application, but also the user, and the experience should be redesigned. In general, you should aim to serve up just the bare minimum that can be dealt with by the user at one time. In data entry situations, users tend to mostly put in a very close approximation of what they are searching for, so loading/reloading frequently is not a pattern that occurs. Instead of putting 'all of the data' in front of the user, we should instead present them with 'just enough' to get the job done.
Data Presentation
User cognition cannot deal with more than a handful of objects at a time - therefore, we should only present what can be seen/used at that moment. Instead of using an infinite predictive scroller, consider using other approaches such as restricted paged data that loads on a callback, or 'smart' predictive loaders.
Smart Loading Of Data
Think about how data is loaded, and think about how to load the minimum possible. here are two examples:
-
When loading into a paged list, clearly we are only loading the amount of data we need to fit into that list. If the number of display items in the list is set at 10, and there are 15 results, then we should be getting the count of the total (15), but only loading the 10 results in the page being viewed.
-
Caching data is a smart way of giving a more performant user experience whilst at the same time only loading the bare minimum you need. For example, consider an infinite scroller - when the user swipes they see scrolling past, perhaps 10 items. Instead of with the paging example, only loading the 10 items, we load the ten for the current swipe, plus another ten in preparation for the next swipe. As soon as that next ten enters the frame, we immediately go off and get the next ten, etc. Let's not forget the data we have just swiped - just as its good to cache data about to be viewed, we should get rid of data we have seen (depending on the content, etc.) so we are not left with a rapidly filled up memory stack.
Less Means More
When trying to speed up applications and make them quicker, we should not only address the issue of speed, but also user perception of speed, and usability. While there is a temptation to cram as many functions into a screen as one can, usually, less is more. Instead of continuously throwing buttons at a screen, strongly consider how often a particular function/piece of data/button is *really* going to be used/required, and consider moving such things, if they are needed in that place, under an 'advanced' button or side-swipe 'extra info/functionality' swipe panel. To make progress in this area, go through each of the screens with your business team to determine where you can de-clutter.
History
- 22nd February, 2016 - Version 1
- 23rd February, 2016 - Version 2 - Added code sample and notes on same
- 4th March, 2016 - Version 3 - Added section on chrome memStats (v.useful!), added updated
SampleCode for download

