Introduction
In working with data, we frequently need to decipher unfamiliar files and tables and often we have the need for a high level understanding of our existing datasets. When these situations arise, a data profiling tool can come in very handy. The script I present here generates dynamic SQL to provide column level measures for Avg/Min/Max length (character data) or value (numeric and date data), distinct value counts and null value counts. The schema/table names analyzed can be controlled by simply changing the WHERE clause for the database schema selection. An example output follows:
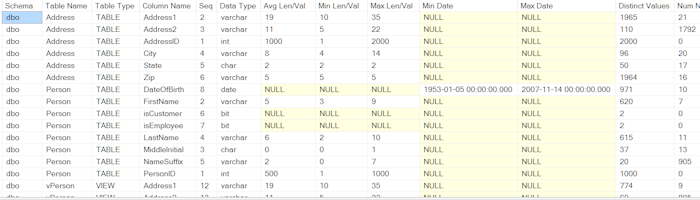
Using the code
The script uses a cursor against the INFORMATION_SCHEMA views to loop through the selected schemas, tables and views to construct and execute a profiling SELECT statement for each column. The SELECT statement is constructed based on the generic data type of the column. Predefined strings exist for each data type and contain the arbitrary string of “@@replace” which is substituted with the correct column name using the REPLACE function.
The result of each select execution is stored in a table variable for final presentation.
SET NOCOUNT ON
SET ANSI_WARNINGS OFF
DECLARE @TableName sysname
DECLARE @TableType VARCHAR(15)
DECLARE @Schema sysname
DECLARE @Catalog sysname
DECLARE @ColumnName sysname
DECLARE @OrdinalPosition INT
DECLARE @DataType sysname
DECLARE @char INT
DECLARE @num TINYINT
DECLARE @date SMALLINT
DECLARE @sql VARCHAR(MAX)
DECLARE @stmtString VARCHAR(MAX)
DECLARE @stmtNum VARCHAR(MAX)
DECLARE @stmtDate VARCHAR(MAX)
DECLARE @stmtOther VARCHAR(MAX)
DECLARE @stmtUnsup VARCHAR(MAX)
DECLARE @q CHAR(1)
DECLARE @qq CHAR(2)
DECLARE @Results TABLE
(
[Schema] sysname ,
[Catalog] sysname ,
[Table Name] sysname ,
[Table Type] VARCHAR(10) ,
[Column Name] sysname ,
[Seq] INT ,
[Data Type] sysname ,
[Avg Len/Val] NUMERIC ,
[Min Len/Val] NUMERIC ,
[Max Len/Val] NUMERIC ,
[Min Date] DATETIME ,
[Max Date] DATETIME ,
[Distinct Values] NUMERIC ,
[Num NULL] NUMERIC
)
SET @q = ''''
SET @qq = @q + @q
SET @stmtUnsup = 'null, null, null, null, null, null, 0'
SET @stmtString = 'avg(len([@@replace])), ' + 'min(len([@@replace])), ' + 'max(len([@@replace])), ' + 'null, null, count(distinct [@@replace]), '
+ 'sum(case when [@@replace] is null then 1 else 0 end)'
SET @stmtNum = 'avg(CAST(isnull([@@replace], 0) AS FLOAT)), ' + 'min([@@replace]) AS [Min @@replace], ' + 'max([@@replace]) AS [Max @@replace], '
+ 'null, null, count(distinct @@replace) AS [Dist Count @@replace], ' + 'sum(case when @@replace is null then 1 else 0 end) AS [Num Null @@replace]'
SET @stmtDate = 'null, null, null, min([@@replace]) AS [Min @@replace], ' + 'max([@@replace]) AS [Max @@replace], '
+ 'count(distinct @@replace) AS [Dist Count @@replace], ' + 'sum(case when @@replace is null then 1 else 0 end) AS [Num Null @@replace]'
SET @stmtOther = 'null, null, null, null, null, count(distinct @@replace) AS [Dist Count @@replace], '
+ 'sum(case when @@replace is null then 1 else 0 end) AS [Num Null @@replace]'
DECLARE TableCursor CURSOR
FOR
SELECT c.TABLE_SCHEMA ,
c.TABLE_CATALOG ,
c.TABLE_NAME ,
t.TABLE_TYPE ,
c.COLUMN_NAME ,
c.ORDINAL_POSITION ,
c.DATA_TYPE ,
c.CHARACTER_MAXIMUM_LENGTH ,
c.NUMERIC_PRECISION ,
c.DATETIME_PRECISION
FROM INFORMATION_SCHEMA.COLUMNS c
INNER JOIN INFORMATION_SCHEMA.TABLES t ON t.TABLE_SCHEMA = c.TABLE_SCHEMA
AND t.TABLE_NAME = c.TABLE_NAME
WHERE c.TABLE_SCHEMA IN ( 'dbo' )
AND c.TABLE_NAME LIKE 't_per%'
AND t.TABLE_TYPE NOT IN ( 'VIEW' )
ORDER BY c.TABLE_NAME ,
c.ORDINAL_POSITION
OPEN TableCursor
FETCH NEXT
FROM TableCursor
INTO @Schema, @Catalog, @TableName, @TableType, @ColumnName, @OrdinalPosition, @DataType, @char, @num, @date
WHILE @@FETCH_STATUS = 0
BEGIN
SET @sql = CASE WHEN @DataType = 'image' THEN @stmtUnsup
WHEN @DataType = 'text' THEN @stmtUnsup
WHEN @DataType = 'ntext' THEN @stmtUnsup
WHEN @char IS NOT NULL THEN @stmtString
WHEN @num IS NOT NULL THEN @stmtNum
WHEN @date IS NOT NULL THEN @stmtDate
ELSE @stmtOther
END
SET @sql = REPLACE(@sql, <a href="mailto:'@@replace'">'@@replace'</a>, @ColumnName)
IF @sql <> ''
BEGIN
SET @Schema = @q + @Schema + @q
SET @Catalog = @q + @Catalog + @q
SET @TableName = @q + @TableName + @q
SET @TableType = @q + @TableType + @q
SET @ColumnName = @q + REPLACE(@ColumnName, @q, @qq) + @q
SET @DataType = @q + @DataType + @q
SET @sql = 'SELECT ' + @Schema + ', ' + @Catalog + ', ' + @TableName + ', ' + @TableType + ', ' + @ColumnName + ', '
+ CONVERT(VARCHAR(5), @OrdinalPosition) + ', ' + @DataType + ', ' + @sql + ' FROM [' + REPLACE(@Schema, '''', '') + '].['
+ REPLACE(@TableName, '''', '') + ']'
PRINT @sql
INSERT INTO @Results
EXECUTE ( @sql
)
END
FETCH NEXT
FROM TableCursor
INTO @Schema, @Catalog, @TableName, @TableType, @ColumnName, @OrdinalPosition, @DataType, @char, @num, @date
END
CLOSE TableCursor
DEALLOCATE TableCursor
SELECT [Schema] ,
[Catalog] ,
[Table Name] ,
CASE [Table Type]
WHEN 'BASE TABLE' THEN 'TABLE'
ELSE [Table Type]
END AS 'Table Type' ,
[Column Name] ,
[Seq] ,
[Data Type] ,
[Avg Len/Val] ,
[Min Len/Val] ,
[Max Len/Val] ,
[Min Date] ,
[Max Date] ,
[Distinct Values] ,
[Num NULL]
FROM @Results
ORDER BY [Table Name] ,
[Seq] ,
[Column Name]
SET NOCOUNT OFF
SET ANSI_WARNINGS ON
Additional Remarks
- My intended usage for this report is to provide a big-picture view of the data by pasting the results into Excel. This is why I share the Avg/Min/Max columns with length or value based on data type to maximize real estate in the spreadsheet. This is also why I include spaces in the column names to allow word wrap in the Excel column headers.
- I used the ISO standard INFORMATION_SCHEMA views as opposed to other system schema tables to facilitate the conversion of the script for use with other databases that support ISO compliant views.
- The PRINT statement in the loop displays the individual SELECT statements to aid as a starting point for more detailed column analysis.
I hope this helps out in the seemingly endless quest for clean data!

