This is Part 4 of a MongoDB tutorial series that discusses Aggregation which is one of the important features of MongoDB.
Introduction
Welcome to Day 4 (believe me, it will take more than one day) of MongoDB tutorial. In this article, we will see one of the vital features of MongoDB, namely Aggregation. Till now, we learnt how to Insert/Update/Delete and Index in MongoDB, but if we talk about a real world application, then we can't live without Aggregation.
MongoDB introduces a big change in 2.2 release named Aggregation Framework. Before Aggregation framework, MongoDB used Map/Reduce for such type of operations. So Aggregation is an alternative of Map/Reduce.
So what is Aggregation: In one line, we can say that Aggregation performs operations on documents and provides the computed result.
Background
It will be good to have some MongoDB knowledge before this. So it will be good to cover my below articles before this:
- Mongo DB Tutorial and Mapping of SQL and Mongo DB Query
- MongoDB Tutorial - Day 2
- MongoDB Tutorial - Day 3 (Performance - Indexing)
Aggregate Function
To achieve Aggregation, we use Aggregate Function in MongoDB. The syntax of Aggregation function is:
db.collectionName.aggregate(pipeline options)
CollectionName: CollectionName is the name of the collection on which we want to apply the aggregate function.
Pipeline: Aggregation Pipeline is a framework which performs aggregation for us. When we use Aggregation Framework, MongoDB passes document of a collection through a pipeline. In this pipeline, the document passes through different stages. Each stage changes or transforms the document and finally we get the computed result.
Aggregation Pipeline Stages
We have the below Stages (It's not a complete list. For a complete list, visit the MongoDB official Site) in Aggregation Pipeline and Mapping with SQL Server so that we can have a clear picture assuming that we have a little knowledge of SQL server:
| In SQL | In MongoDB | Description |
Select | $project | Passes the fields to the next stage with existing Fields or with New fields. We can add new Fields dynamically.
|
Where | $match | This will filter the documents and will pass only matching documents to the next pipeline stage.
|
Limit | $limit | Limit the first x unmodified documents and pass them to the next stage of pipeline. x is the number of the documents which will pass through the next stage of pipeline.
|
GroupBy | $group | This will group the documents and pass them to the next stage of Aggregation pipeline.
|
OrderBy | $sort | It will change the order of documents either in ascending or descending order.
|
Sum | $sum | To calculate the sum of all the numeric values.
|
Join | $lookup | It will perform the left outer join with another collection in same database.
|
So much talk! It's time to understand some pipeline stages and Operators with some examples.
Now suppose we have a School database and have a Student Collection as below:
db.Student.insert({StudentName : "Vijay",Section : "A",
Marks:70,Subject:["Hindi","English","Math"]})
db.Student.insert({StudentName : "Gaurav",Section : "A",Marks:90,Subject:["English"]})
db.Student.insert({StudentName : "Ajay",Section : "A",Marks:70,Subject:["Math"]})
db.Student.insert({StudentName : "Ankur",Section : "B",Marks:10,Subject:["Hindi"]})
db.Student.insert({StudentName : "Sunil",Section : "B",Marks:70,Subject:["Math"]})
db.Student.insert({StudentName : "Preeti",Section : "C",
Marks:80,Subject:["Hindi","English"]})
db.Student.insert({StudentName : "Anuj",Section : "C",Marks:50,Subject:["English"]})
db.Student.insert({StudentName : "Palka",Section : "D",Marks:40,Subject:["Math"]})
db.Student.insert({StudentName : "Soniya",Section : "D",
Marks:20,Subject:["English","Math"]})
We will see different stages and how they work on this Student Collection. So let's get ready for some good stuff.
$match
$match is similar to Where in SQL. In SQL, we use Where to filter the data and it is the same here. If we need to pass only a subset of our data in the next stage of Aggregation Pipeline, then we use $match. $match filters the data and pass the matching data to the next stage of Pipeline.
Example 1
Suppose we want to filter data based on Section A in Student Collection, then we will use $match as below:
db.Student.aggregate
(
[
{
"$match":
{
"Section":"A"
}
}
]
)
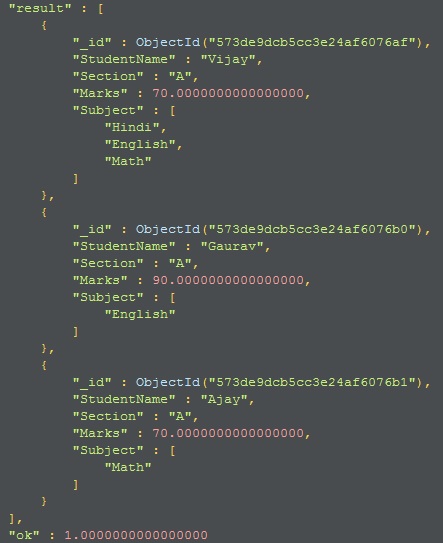
This will filter the data according to our $match and will pass only 3 rows to next Stage of pipeline where Section is A.
Result
Example 2
Suppose if want to find out all the records where Section is A and Marks are greater than 80.
db.Student.aggregate (
[
{
$match:
{
$and:[{Section:'A'},{Marks: {"$gt" :80}}]
}
}
]
)
This will give us one record.
Result

NOTE: There can be more than one $match in Aggregate Function.
$project
We can compare this clause with SELECT in SQL. We can select certain fields, rename Fields from documents though $project. In short, $project reshapes the documents by adding/removing or renaming the documents for the next stage of pipeline. In $project, we use 1 or true if we want to include the Field and 0 or false if we want to exclude a particular field.
Example 1
In the below query, we want only StudentName, Section and Marks from student collection, then we will use the below query:
db.Student.aggregate
(
[
{
"$project":{StudentName : 1,Section:1,Marks:1}
}
]
)
Example 2
Now if we want to find out StudentName, Section and Marks from Student Collection where Section is 'A', then we will use $project and $match both.
db.Student.aggregate
(
[
{
"$match":
{
"Section":"A"
}
},
{
"$project":
{
StudentName : 1,Section:1,Marks:1
}
}
]
)
Result
NOTE: _id will be visible by default, if we don't want the _id field in result, then we need to remove it explicitly as below:
"$project":{StudentName : 1,Section:1,Marks:1,_id:0}
$unwind
$unwind works on the array field inside the documents. $unwind creates a new document for each array element in an array. $unwind output is a new document of each entry of an array inside a document. we use $unwind to flattens the data.
Example 1
Suppose we want to apply $unwind on a document where name is Vijay. In this document, we have an array field named Subject which contains three subjects named Hindi, English and Math. Let's see what $unwind will do with this document:
db.Student.aggregate
(
[
{
"$match":
{
"StudentName":"Vijay"
}
},
{
"$unwind":"$Subject"
}
]
)
Result
Example 2
If we want to select only StudentName, Section, Marks, Subject, then we can use $project along with $match and $unwind as below:
db.Student.aggregate
(
[
{
"$match":
{
"StudentName":"Vijay"
}
},
{
"$unwind":"$Subject"
},
{
"$project":
{
StudentName : 1,Section:1,Marks:1,Subject:1
}
}
]
)
MongoDB is Schema less so it might be possible that some documents does not contain array or some contain an empty array so will $unwind work for such documents? The answer is yes! After MongoDB release 3.2, if the document contains an empty array or does not contain an array, then pipeline will ignore the input document and will not generate output document for such document.
Before MongoDB release 3.2, if we don't have an array or we have an empty array and we are using $unwind, then MongoDB generates an error.
Example 3
Let me add two documents as below in our Student Collection. In the first document, we have an empty array and in the second document, we don't have any array field.
db.Student.insert({StudentName : "Tarun",Section : "A",Marks:95,Subject:[]})
db.Student.insert({StudentName : "Saurabh",Section : "A",Marks:95})
Now let me run the $unwind again for the document where StudentName is Tarun and Saurabh.
db.Student.aggregate
(
[
{
"$match":
{
"StudentName":{$in:["Saurabh","Tarun"]}
}
},
{
"$unwind":"$Subject"
}
]
)
So the above query will not generate any output document because the array is missing or empty.
includeArrayIndex Parameter
Example 4: In $unwind, we can pass the second parameter named includeArrayIndex which we can pass in $unwind if want to include ArrayIndex in result.
db.Student.aggregate
(
[
{
"$match":
{
"StudentName":"Vijay"
}
},
{
"$unwind":{ path: "$Subject", includeArrayIndex: "arrayIndex" }
}
]
)
Result
$group
MongoDB uses $group to group the documents by some specified expression. $group is similar to Group clause in SQL. Group in SQL is not possible without any Aggregate Function and the same is here. We can not group in MongoDB without Aggregate Functions. Let's understand with an example.
Example 1
Suppose we want to find out Total Marks group by Section, then we will use $group as below:
db.Student.aggregate ([
{
"$group":
{
"_id":
{
"Section" : "$Section"
},
"TotalMarks":
{
"$sum": "$Marks"
}
}
}
])
In this query, _id Field is mandatory. In _id, we pass the field on which we want to group the documents. This will give us the below result:
Result
Example 2
If we want to fetch Total Marks for only Section 'A', then we can pass a $match also.
db.Student.aggregate ([
{
"$match":{Section :'A'}
},
{
"$group":
{
"_id":
{
"Section" : "$Section"
},
"TotalMarks":
{
"$sum": "$Marks"
}
}
}
])
This will Sum the Total Marks of Section 'A' only.
Result
Example 3
Suppose we want to fetch the count of students in each section and Total marks and average marks as well:
db.Student.aggregate ([
{
"$group":
{
"_id":
{
"Section" : "$Section"
},
"TotalMarks":
{
"$sum": "$Marks"
},
"Count":{ "$sum" : 1},
"Average" : {"$avg" : "$Marks"}
}
}
])
Result
Example 4
If we want to rename the column Names in the above query (Section to SectionName and TotalMarks to Total), then we can use $project along with $group as below:
db.Student.aggregate ([
{
"$group":
{
"_id":
{
"Section" : "$Section"
},
"TotalMarks":
{
"$sum": "$Marks"
},
"Count":{ "$sum" : 1},
"Average" : {"$avg" : "$Marks"}
}
},
{
"$project" :
{
"SectionName" : "$_id.Section",
"Total" : "$TotalMarks"
}
}
])
$sort
$sort is similar to orderby clause in SQL server. In MongoDB, we have $sort for this. $sort will sort the documents in either ascending or descending order as below. MongoDB uses 1 for ascending and -1 for descending.
Example 1
If we want to sort the result in descending order by SectionName, then we can use $sort.
db.Student.aggregate ([
{
"$group":
{
"_id":
{
"Section" : "$Section"
},
"TotalMarks":
{
"$sum": "$Marks"
},
"Count":{ "$sum" : 1},
"Average" : {"$avg" : "$Marks"}
}
},
{
"$project" :
{
"SectionName" : "$_id.Section",
"Total" : "$TotalMarks"
}
},
{
"$sort":{"SectionName":-1}
}
])
$limit
$limit operator is used to pass n documents to the next pipe line stage where n is the limit. n is the number of documents
Example 1
If we want to sort the documents as in the above query and we need to pass only two documents to the next stage of pipeline, then we use $limit.
db.Student.aggregate ([
{
"$group":
{
"_id":
{
"Section" : "$Section"
},
"TotalMarks":
{
"$sum": "$Marks"
},
"Count":{ "$sum" : 1},
"Average" : {"$avg" : "$Marks"}
}
},
{
"$project" :
{
"SectionName" : "$_id.Section",
"Total" : "$TotalMarks"
}
},
{
"$sort":{"SectionName":-1}
},
{
"$limit" : 2
}
])
Result
$skip
$skip is use to skip the first n documents and remaining will be passed in the next pipeline. n is the number of documents which we want to skip.
Example 1
In the above example, if we want to skip first one document and then we want to pass the next two documents to the next stage of pipeline, then we will use the below query:
db.Student.aggregate ([
{
"$group":
{
"_id":
{
"Section" : "$Section"
},
"TotalMarks":
{
"$sum": "$Marks"
},
"Count":{ "$sum" : 1},
"Average" : {"$avg" : "$Marks"}
}
},
{
"$project" :
{
"SectionName" : "$_id.Section",
"Total" : "$TotalMarks"
}
},
{
"$sort":{"SectionName":-1}
},
{
"$skip" : 1
},
{
"$limit" : 2
}
])
Result
$lookup
This is the most awaited feature in MongoDB. $lookup is equal to joins in SQL. $lookup comes with MongoDB release 3.2. Before MongoDB version 3.2, there were no concept of joins (in my first articles, I mentioned that MongoDB does not support Join in my first article). Let's understand this by using an example.
Example 1
Suppose we have two collections named Country and City as below:
db.Country.insert({"_id":1,"Name":"India"})
db.Country.insert({"_id":2,"Name":"US"})
db.Country.insert({"_id":3,"Name":"UK"})
db.Country.insert({"_id":4,"Name":"Australia"})
db.City.insert({"_id":1,"Name":"Delhi","CountryID":1})
db.City.insert({"_id":2,"Name":"Noida","CountryID":1})
db.City.insert({"_id":3,"Name":"Chicago","CountryID":2})
db.City.insert({"_id":4,"Name":"London","CountryID":3})
db.City.insert({"_id":5,"Name":"Bristol","CountryID":3})
db.City.insert({"_id":6,"Name":"Sydney","CountryID":4})
If we want to fetch all the cities associated with countries, then we will use $lookup as below:
db.City.aggregate([
{
$lookup:
{
from: "Country",
localField: "CountryID",
foreignField: "_id",
as: "Country"
}
}
])
In the above query, we are joining City with Country collection, CountryID is local field of City and _id is a foreign field of Country.
$redact
MongoDB uses the $redact to restrict the content of the documents based on the information stored in the document itself. To understand this better, I will cover first $cond, $setIntersection, $size before $redact.
$cond
$cond checks a boolean expression and return expressions according to result. This is not a Stage in pipeline, but good to know how $cond works because we are going to use it shortly.
$cond follow the syntax as below:
{ $cond: { if: (boolean-expression), then: (true-case), else: (false-case) } }
Example 1
In our Student collection, If we want to display Good in result, if marks is greater than 70, and Poor if marks is less than 70, then we can use $cond as below:
db.Student.aggregate(
[
{
$project:
{
StudentName: 1,
Result:
{
$cond: { if: { $gte: [ "$Marks", 70 ] }, then: "Good", else: "Poor" }
}
}
}
]
)
Result
$setIntersection :-
$setIntersection takes two arrays as an Input and returns an array with the common element in both the array.
Suppose I have two arrays in a document in my Test collection as below:
db.Test.insert({"Array1":["1","2","3"],"Array2":["1","2","3","4","5"]})
Example
If we want to find out the common elements between two arrays, then we will use $setIntersection as below:
db.Test.aggregate(
[
{ $project: { "Array1": 1, "Array2": 1, commonToBoth:
{ $setIntersection: [ "$Array1", "$Array2" ] }, _id: 0 } }
]
)
Result
$size
$size counts and returns the total the number of items in an array. In the below query, we are counting the element of Array1 and Array2.
db.Test.aggregate(
[
{
$project: {
Array1count: { $size: "$Array1" },
Array2count: { $size: "$Array2" }
}
}
]
)
Result
So we are good with $cond, $setIntersection and $size and now let's understand $redant with an example but remove records where array is null or missing, otherwise $redant will throw an exception. So I am removing two documents from Student collection where array is null or empty (both the documents where array is empty or missing marks is 95):
db.Student.remove({Marks:95})
var SubjectAccess=["Math","Hindi"];
db.Student.aggregate(
[{
"$match": {"Section":"A"}
},
{
$redact:{
$cond: {
if: { $gt: [ { $size: { $setIntersection:
[ "$Subject", SubjectAccess ]{} }, 0 ] },
then: "$$DESCEND",
else: "$$PRUNE"
}
}
}])
The above query will check if Subject contains data, either Hindi or Math, then it will allow to pass the document to next stage of pipeline and it will restrict all the documents where subject does not contain either Math or Hindi and of course, it will match the condition where section is "A".
Result
So we are done enough for Day 4. Truly speaking, it's more than enough for a day, in fact for a week.
What's Next: MongoDB Connectivity with C#
Finally, if this is helpful and you liked it, please vote above.
History
- 21st May, 2016: Initial version

