Introduction
Nowadays, networks are evolving. Virtualization is emerging less or more in every technology, and the necessity of a more dynamic and scaling architecture lead to the development of software defined network. These approaches have been developed and deployed on an already well-tested and consolidated architecture, that has been patched to adapt to new necessity through the last 30 years: the IP technologies.
But what if such old-but-gold architecture is not enough to match the next future challenges? What if it's only a special case of a more generic view which now (and in the past too) has started to emerge, but has been a threat just as a curious case of use?
I'm going to introduce in this article the idea of Recursive Internetworking in a very practical way. The original idea comes from John Day, a computer scientist, network engineer and cartographer, which is one of the network pioneers of the old days. If you want to acquire more detailed and theoretical information over this branch of networks, I strongly encourage you to take a look at the book "Patterns in Network Architecture: A Return to Fundamentals" (PNA), which was my first source of ideas for the development of this project.
I want to apologize in advance with that few experts in this area if this article appears too simple or simplify some details about the architecture idea. The scope of this document is to introduce the idea, not to give a strong background on it.
Background
I would say, as always, that maintaining an open mind approach while reading this article is one of the most important things to do. A general background with networks is required, but since I'm going to touch the architecture itself from its base, the speech should be generic for everyone to follow.
The Classic View in Internetworking, TCP/IP Stack
The TCP/IP stack, also known as Internet Protocol suite, is a network model which aims at providing an end-to-end, robust, communication. It achieves such functionalities by using a layered approach, where it defines a set of layers (five, to be more precise) which provides service through the use of different protocols. Every layer encapsulates whatever comes from the upper one and offers an additional service that span over the domain of the layer itself. Such layers are by definition:
- Application, which span its domain over user-defined applications. This service uses the lower layer in order to provide reliable or unreliable communication "pipes" between client and server instances.
- Transport, which performs host-to-host communication and span its domain over the entire host. This means that the layer has a bigger domain rather than the Application one, since it offers a service to all the applications of all the host users.
- Network, which performs exchanging of datagrams between network boundaries. This layer is capable of routing and forwarding, thus allowing data to "use" other nodes in between to arrive at the destination.
- Link, which performs the necessary operation to actually transmit the signal over a certain technology and decode it on the other side. Its domain is purely fixed between two physical machines and has no "big view" of the overall communication.
- Physical, which is the "cable" where the data travels on. This level is not considered here because it's not possible to logically change it (you need to modify it by hand IRL).
Since the concept can become twisted, let's take an example that I found on Wikipedia (see: https://en.wikipedia.org/wiki/Internet_protocol_suite). You can also deepen your knowledge on the TCP/IP stack by reading the information present on that page.
In the following example, we have one client communicating with a server using the service offered by UDP/IP. Since the server is not present in the local machine, but is placed on a host connected through one (or more) routers, the packet will cross also those nodes in its route from the source to the destination.
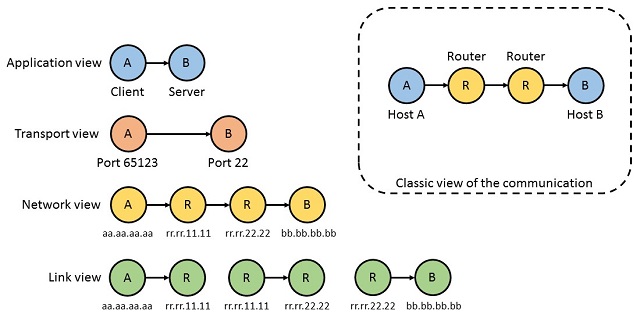
The classical view is a generalization of what is happening, which usually mixes all the different layers of the networking model. Since we are speaking of different layers, we should also ask what layer-view we want to look at. As you can see in this image, every layer has its own map of the same communication, which is resumed in the top-right box as presented from the Wikipedia example. The datagram flows starting from the Application layer to the Link layers (top to bottom in the figure), and during all this traversal, it will change the domain where it lives.
When the packet changes layer and passes to the lower one, then it's encapsulated with another header which contains the information which is relative to that domain, and which is necessary for another host/router of that layer to understand it.
If we look at the entire traversal process of such information, we can draw the following schema (that we will call from now on "side view", because it looks at the communication from a side perspective):

If you follow the arrow starting from the Client and arriving at the Server, we can see step by step what is happening to the data. Every time the packet changes domain and flows from an upper layer to the lower one, an header is put in front of the old data and append the necessary information that the layer needs to correctly handle the data. This is especially seen in the Network layer, where the intermediate nodes use the IP destination address field to identify if the packet is for them and, if not, who is the next hop to its path to the real destination.
The Link layer does the same (well, every layer behaves like this), but it keeps removing its information when the packet is moved to the top (Network), and re-encapsulate it again when the packet has to be moved to the next host. This happens because the Network layer has a bigger scope than the Link one; in fact is placed on its top!
If we take a look at the data now (data-view schema), we can determine how many layers the packet is traversing by counting how many layer headers are attached to its front:
During the ascending/descending operations on the routers, the green part, which is relative to the Link layer, is the one which keeps being changed (or updated), because even if it remains at the same level, it changes its domain. We are not always using the same Link couple, otherwise the datagram will keep remaining on the same link without ever changing (and thus it never arrives at the destination). When the data is handled by the Network layer, the source and destination addresses of the Ethernet header changes, and when it changes, then it means it's going to use a different type of Link, which can have a different domain.
As you can see in this picture, the domain of every layer is quite nicely defined. At Link layer, we have 3 different domains which makes it possible for the packet to reach the destination. Since link layer is the bottom-most one, you can ideally match these layers with the ethernet cable itself: it has a well-defined pair of interfaces, and information which is travel on that cable only makes sense for that cable (since the interfaces changes if you change cable). The Network layer (1 layer above) has a huger domain, since it provides an abstraction over links that bound every node in this small communication example. This is the Internet (for example, IPv4) and allows your packet to move in the most twisted architecture ever built by humanity until now. At Transport layer, you can find a more restricted domain which is confined inside the single machine, and allow you to aim at a specific service within the host (since the host can offer more than one service).
I hope you are still following me here... :)
The Need for Layers
The defined structure for the network stack has served us very well through the networking story until recently, where the need for more organization of the network has been required. The first attempt to use additional layer can be seen, for example, in the introduction of Point-to-Point protocols like VPN and even before with the introduction of Network Address Translation (NAT).
NAT has been introduced some time ago to solve one big problem of the IP Network layer, which was (and still is) the address exhaustion. Since the addresses of IPv4 are 32bit wide, this means that you can "only" have in that layer about four billions of possible, distinct nodes. So this is why additional domains (at level Network) have been introduced while trying to solve the problem (which has not been solved, but just moved until our days).
Network engineers basically reserved some address in order to use them to form "private" networks. In the public IP, address space is not legal to be assigned with such address (which are the classic 10.x.x.x and 192.168.x.x, and the less used 172.16.x.x). When traffic flowing through your network reaches the public IP, its source address is translated with the one of the router, which remembers about this swap. Now the packet travels along the network with the "public IP" address, and is able to reach the destination on the other side of the network.
Another example of additional layer, but of a different type, is the introduction of Virtual Private Networks. This technology has been introduced because there is the necessity to connect to a "private network" (because it has been NAT-ted in order to save addresses) from the IP public domain. Using the existing IP network to provide the service for this virtual one, a VPN allows hosts to connect to secured domains (internal networks) which normally are not reachable "from the outside". This is generically done by adding some other headers after the internal one, in order to have it traveling around the public network. Since the public network is not ensured to be safe (you never know where the packet will be forwarded), also security and encryption mechanism are bound together with the additional headers.
There are a lot of other examples of protocols/configuration that change the classical approach of the TCP/IP stack and makes it not the best option to resolve a certain problem. There can be new technologies, for example, that are not compatible with the classical view and need additional "layers" to organize better the communication (Link layer for wireless technologies, for example, splits in two).
Even if the IP network as it is has served us for a really long time, and did it really good (otherwise, it would have collapsed a long time ago), now we are reaching the far "limits" of that idea, and we need something new... evoluted. Take into account that not only must it do it while preserving the old configuration, but it must embrace also new concept of the network that is emerging.
Recursive Networks
When we speak of Recursive Networks, we have first to introduce a pair of concepts that must be known in advance. After this very small introduction (to see the very theoretical part read the PNA), I'll start to show how the example for the classic stack works also natively for this sort of architecture.
The concepts are:
- Internetworking is IPC communication!
A client and a server (or whatever component) just exchanges information between each other without considering the fact of the locality of the endpoint. It shall and must not care of what type of network it can use, but instead register to some IPC which provide to it the necessary service to reach the endpoint. The IPC will offer a series of QoS (Quality of Service) that the application can decide to use or not. - The IPC mechanisms recurse their services on different layers.
This means that you have only one type of mechanism that is perfectly isolated from other components, and you can have various instances of it organized as a stack which offers a set of services. As for the classic stack, each layer provides additional service to the communication that can enhance, organize or protect the communication, as you prefer.
There is way more behind this, but I have neither the ability nor the patience to explain everything (the article would be never ending). It took one year to me to understand (and accept!) this new kind of architecture.
So, let's start again from the first example we had for the classic TCP/IP network stack. At the top layer, really few details changes: you still have two applications (processes) that desire to exchange data between each other by using a certain QoS (which can be the "best effort" one, or some other of more refined profiles). In order to do this, they both will use IPC processes that are connected to each others (we call this operation "enrolment") and offer the required service.
Take into account that you don't have anymore the details of what there is under the IPC you are using. You don't care about it any more: as long as the IPC offers to you the connection service, this is enough for the communication to happens. This works like the black box concept for software, and allow you to change/adapt the underlying network without any disruption in the stack configuration.
Each IPC offers enough functionalities to dispatch packet in the network it is actually serving, so we don't have anymore two protocols that must live together to provide the service (TCP without IP does not work, since its domain is restricted to the machine). This means that a layer is more than enough to aim for a certain endpoint and dispatch a packet to it.
As you can see in the image, I arranged the network in order to have a similar case of the classical TCP/IP stack: an application called A wants to communicate with another one called B. To obtain the ability to exchange data, the applications have to register over IPC A and IPC B of the yellow layer, which you can consider as a layer of IPCs connected all over the world (the IP recursive version). Recursively, also the IPC A of the yellow layer has registered on an IPC A of the green one in order to reach the first router, which is the next hop for its communication. The green layer provides an abstraction over Ethernet, in this case, and so has the necessary knowledge to setup a datagram in order to be handled by the NIC.
If we take a look now on the "side-view" of the stack organization, we do not see big differences of the previous classic stack. Note that since we use recursion, we have IPC-to-IPC communication over all the layers, and not only on Transport or Application layer for TCP/IP stack. At every layer, it seems to communicate straight to the destination (with or without some forwarding in the middle, which actually only happens in the Yellow layer here).
So what is happening to the data passing though these recursive layers? Well, basically every time the packet traverses a layer (going up or down), it is processed by the IPC belonging to that layer. During this operation, the header of the packet is analyzed to check what is its destination and if such destination is reachable. If this is the case, then the packet is encapsulated in an additional layer header which make it legal to travel on that network, and dispatched to the next hop of the same layer (for example, from yellow A to yellow B, the packet has to go though R1). If the IPC abstracts a technology of some sort, then the recursion stops because the data is given to the NIC or to that technology northbound interface. If there are more layers under it, then the process repeats.
Notice that every layer can decide to arrange the data in the best way it wishes, and this organization will not affect any top or bottom layer as long as it is returned to the top the way it arrived. For example, the Technology abstraction layer can decide to put a CRC check at the tail room of the data in order to check for consistency or recover any error, and this is transparent to the Yellow one as long as the data is returned stripped from the additional header(s).
The system is really similar to the TCP/IP one. No, wait... it's more or less the same except for the fact that is more generalized now. The example given, for the sake of simplicity, has been maintained the same, but you can add any layer you want/need in between without having to redesign/fix/hack the network stack itself. Such behavior is supported now by design and you are actually encouraged to take advantage of this functionality. The simple example given turns out to be only a special case where you want a single, wide, layer spread across the whole network instead of a more refined organization.
So, how should it become the NAT and the VPN example previously seen in the TCP/IP stack?
Well, in brief, they collapse in a single case because layering offers both a private environment (hides upper layer organization to the lower one), where you can setup your personal set of nodes, and a private naming domain (you can decide the name to use that lower IPCs let you register).
Not only that, but recursive networks introduce by design some concepts that are currently emerging now, like for Software Defined Networks (SDN). In fact, SDN aims to manage network services through network abstraction by decoupling network from data planes. Recursive networks already provide the possibility to shape and isolate networks using layering, so you decide through what nodes the traffic will pass by just creating a private layer in the way you want (by enrolling IPC in a way that they are considered neighbors). You can, for example, build a network on the top of the Global (yellow) one in the previous example, using some of those nodes. The way you enroll the various elements creates the link between the nodes (enrolments indicates neighbors), and so creates the network as you want. Application created on top of this "private network" won't have any idea of how the Yellow layer is organized, and nor will they be conscious of any change happening to it (except maybe in latency or periods out-of-service for network reconfiguration).
As you can see, the concept is really simple, and as all the simple things leave many open options. On the other side, speaking of such new concept of the network leave lot of persons with headache and doubts, also because no real solutions are available except for some very experimental prototypes that can help to have an idea about this.
It's All Smoke and Mirrors?
After these large amount of words, now a question that you will probably have in mind is: "Dude, this is CodeProject... where is the code?", and probably you are right. But I'm not here only to present the idea, but also to offer a prototype for this (a medium-sized one).
The stack has been developed entirely in kernel-mode (as it should be for every network stack), and it's possible to load it as a kernel module, without having to use special distribution of Linux (the only OS supported for this technology right now).
The project has been developed with simplicity, deployability and performances in mind. So you can clone, build and load it in your kernel in about 5 minutes. Look at the "documentation" folder to acquire some additional information of it, and more precisely on what system has been developed and tested until now (mainly Debian and Arch systems). Since, as I said, portability and performances are important focus for the project, you can run this system also on low power consumption devices as Raspberry Pi (the entire project is now tested between Raspberries version 1, 2 and 3 and Debian switches).
Work in Progress
Since we are speaking of a prototype, and also at kernel level, be sure NOT TO USE your normal machine when testing this software, but instead a virtual machine or a dedicated one. Kernel panics have become really rare by now, but I'm a human being and error can lurk in parts I have not considered yet.
The architecture is achieving already good performances and introduces minimal latency, but still is not optimized and I'm preparing some updates (in the future) in order to take advantage of existing tricks (used by the TCP/IP stack) to improve its efficiency.
Compile and Load
As a first operation, you should clone the project into your Linux system. The pre-requisites in order to build and run this project are really minimal, and they are listed in the documentation/install file. Take into account that for the compilation stages, the project, for the moment, assume that the project root is /RNS. You can of course change this, but you have to remember to fix the Makefiles in order to point to the right project root folder.
# Root directory.
ROOT := /RNS
This line is present at the top of every Makefile in the project.
You can use a set of scripts I'm shipping with the project in order to speed up the operations: under linux/scripts project subdirectory, you will find a set of functionalities. If you invoke compile.sh from a shell, you will be able to have it ready in no time (takes about 1 minute on a Raspberry version 1).
To load it into your kernel, you can invoke the load.sh script in a similar way. Once the loading steps have been done correctly (you should be able to see using the dmesg utility), some service messages will inform you that everything is up and running.
An example of such output is:
RNS successfully loaded with status 0
Unload
It is enough to invoke the unload.sh script in linux/scripts whenever you want to start removing everything from the stack. If something goes wrong, this is also the time when you can get some error, which can be silent or not. One of the most common ones, if you introduce new modules, is:
Memory use mismatch!
which usually informs you that when the cleaning operations finish, you left behind some memory that will be lost until reboot. If that is the case, check again that for every allocation you also have a deallocation procedure that frees the reserved memory!
Create Two Applications that Communicate
In order to have two or more applications using the services provided from the stack, you must first configure it. To interact with the stack, a tool is already in place and is called rnsctrl (RNS control). Take into account that using this tool correctly can require root permissions since it has to interact with a device driver in order to ship the command to the kernel level.
The tool can be found under linux/tools/bin subdirectory in the repository, which is where all the compiled tools are stored. If you invoke the tool without any arguments or with the --help option, you should be able to see the action it can commit on the stack. This tool gives you FULL control over the kernel stack, at the moment.
The first action you have to do (after you invoked the load.sh script) is to create an IPC manager, which is a stack container. This means that, by design, you can also create logically separated network stack in the same physical machine.
root@64:/# /RNS/linux/tools/bin/rnsctrl --create-ipcm
Going to create a new IPCM...
IPCM 1 successfully created...
Once you got the IPCM running, you have to create an IPC process that will offer the communication service to both the applications, and this is done in a similar way with:
root@64:/# /RNS/linux/tools/bin/rnsctrl --create-ipcp 1 L 1 ""
Going to create a new IPCP...
IPCP 1 successfully created...
This command will create an IPC process in the IPC manager 1 (the one newly created), give the name "A" to it and told to follow the model 1 (which is loaded by the load.sh script) with no arguments. A model in RNS is a way to react to events triggered by the stack itself. This way, you can publish various models and decide how the new IPC process will behaves. IPC that abstracts over a technology, for example, does not need to change the stack itself, but just needs to publish a new model, which is a standalone kernel module.
Model 1 is RNS IPC model, which provides a generic recursive behavior for IPCs.
Ok, now that you have the stack configured, you only need to create the applications. I already ship with the stack some user-space tools that I use to verify that the performances and the mechanism are right. One of these applications is a native ping for RNS, and will be the one which we are going to use. As always, just run the application without arguments or with --help option to have more information about its functionalities.
For the server, write:
root@64:/# /RNS/linux/tools/bin/rnsping 1 1 a 2 --listen
which will run the ping utility on IPC manager 1, IPC process 1. It will assign the name "a" within the stack, and ask to use QoS class 2 (for the moment, the only important field for QoS is the id). It will just stand still and listen for whoever wants to exchange messages with him.
For the client, write:
root@64:/# /RNS/linux/tools/bin/rnsping 1 1 b 2 a
which will run the ping utility on IPC manager 1, IPC process 1. It will assign the name "b" within the stack, and ask to use QoS class 2. Now instead of listen, you give the name of the application which you want to communicate with (which is the server a). If everything is successful, you will be able to see the following log trace:
Starting client b(2)...
64 bytes from a: token=1, time=xxxx ms
64 bytes from a: token=2, time=xxxx ms
64 bytes from a: token=3, time=xxxx ms
64 bytes from a: token=4, time=xxxx ms
Here a picture of what is happening if a schema can make it more clear:
Add More Layers
How you decide to use the stack is up to you, but since I always was speaking of recursion is better to show how this happens in RNS. In a practical way, you just have to repeat what you did to have two applications to communicate with each other. During stack configuration, you just need to add more IPC process, using always the same command, like:
root@64:/# /RNS/linux/tools/bin/rnsctrl --create-ipcp 1 A 1 ""
Going to create a new IPCP...
IPCP 1 successfully created...
root@64:/# /RNS/linux/tools/bin/rnsctrl --create-ipcp 1 A 1 ""
Going to create a new IPCP...
IPCP 2 successfully created...
Now that you have two IPC processes, you only need to register one over the other using the following command:
root@64:/# /RNS/linux/tools/bin/rnsctrl --register-ipcp 1 1 2
IPCM 1 is going to register IPCP 1 on 2...
IPCP 1 successfully registered on IPCP 2...
As you can see, you always have to give the IPC manager context to the operation, since you have to specify in which logical stack the action takes place. I want to remember you again that running every utility present in the project without arguments or with the --help flags will provide the list of the functionalities offered.
The Most Basic Network
Since getting two ping applications communicating with each other in a simply way is boring, let's configure a more complex stack with a point-to-point setup. Using the stack as it is will allow you to literally emulate small networks (since IPC view lets you abstract over the technology used): what you need to do is just setup, register and enroll IPC the way you want.
Let's say we want two applications to speak over a single layer: what we need is two IPCs in total (one per application) and a lower one which provides the "loopback" service. Since now the IPCs stand on the same layer, you can't any more assign to them the same number, but you need to identify your personal addressing scheme.
If you start from a clean loaded stack (so unload and load it again, in order to have a complete cleanup), you can do the following:
root@64:/# /RNS/linux/tools/bin/rnsctrl --create-ipcm
Going to create a new IPCM...
IPCM 1 successfully created...
root@64:/# /RNS/linux/tools/bin/rnsctrl --create-ipcp 1 A 1 ""
Going to create a new IPCP...
IPCP 1 successfully created...
root@64:/# /RNS/linux/tools/bin/rnsctrl --create-ipcp 1 B 1 ""
Going to create a new IPCP...
IPCP 2 successfully created...
root@64:/# /RNS/linux/tools/bin/rnsctrl --create-ipcp 1 L 1 ""
Going to create a new IPCP...
IPCP 3 successfully created...
Now you have created 3 IPC processes: two stays on the same layer (A and B), while the last one (L) will provide the loopback services. The next step is to place A and B over L, so they will be on the same level, and then just have them enroll to start exchange forwarding information (like who are the other reachable IPCs and which AE you can reach though them).
To that operation, you just need to:
root@64:/# /RNS/linux/tools/bin/rnsctrl --register-ipcp 1 1 3
IPCM 1 is going to register IPCP 1 on 3...
IPCP 1 successfully registered on IPCP 3...
root@64:/# /RNS/linux/tools/bin/rnsctrl --register-ipcp 1 2 3
IPCM 1 is going to register IPCP 2 on 3...
IPCP 2 successfully registered on IPCP 3...
root@64:/# /RNS/linux/tools/bin/rnsctrl --enroll-to 1 1 B 3
IPCP 1 is going to enroll to B using 3...
IPCP 1 successfully enrolled to B...
The last command will ask the IPC process 1 to enroll to "B" using the services offered by IPC process 3, which is the loopback one. You then have just to repeat the old operations with the ping applications and you should be able to have the two instances communicating over a simple "virtual" link.
So, for the server:
root@64:/# /RNS/linux/tools/bin/rnsping 1 1 a 2 --listen
while for the client:
root@64:/# /RNS/linux/tools/bin/rnsping 1 2 b 2 a
Note that the second digit given change, because the applications will use a different IPC process to access the communication service. The server will register on IPC 1, which is A, while the client will live over IPC 2, which is B.
Here again, a picture of what is happening if a schema can make it more clear:
Breaking Free from the Local Node
As I said, you can create a small network and emulate how RNS works just by creating IPC process within the local PC and then enrolling/register them in the right way. But just remaining in the local machine can be pretty boring and not very useful for internetworking, and this is why RNS is shipped with an UDP IPC model. This model allows you to create IPC processes which abstract the UDP/IP technology, and so allow you to go where UDP itself goes.
Using this model, I personally performed (with a colleague) some cross-atlantic ping experiments from Boston to Ireland (using the existing IP network), achieving less of more the ICMP performances in term of latency. It can't go faster of course, since it sits over UDP, but at least the stack does not introduce big performance losses on the communication (not trivial to do at this level).
As always, load a clean stack using the given scripts and then configure it on both the machines that are going to communicate between each others. This means that machine 1 should be configured as (remember to adjust the IP address to the one of your configurations):
root@64:/# /RNS/linux/tools/bin/rnsctrl --create-ipcm
Going to create a new IPCM...
IPCM 1 successfully created...
root@64:/# /RNS/linux/tools/bin/rnsctrl --create-ipcp 1 A 2 "12345,B:192.168.1.2:12345"
Going to create a new IPCP...
IPCP 1 successfully created...
While machine 2 has to be configured as (also here, revisit the IP address to match your setup):
root@64:/# /RNS/linux/tools/bin/rnsctrl --create-ipcm
Going to create a new IPCM...
IPCM 1 successfully created...
root@64:/# /RNS/linux/tools/bin/rnsctrl --create-ipcp 1 B 2 "12345,A:192.168.1.1:12345"
Going to create a new IPCP...
IPCP 1 successfully created...
What changes here is:
- The model of the IPC now is different, since we are not using anymore type 1, but type 2 instead (these ids are generic ones I decided to assign to the IPC models when I compiled and loaded them) which is UDP abstraction IPC.
- The arguments for the IPC now is not empty, but contains the necessary information in order to use the abstracted technology to reach the destination. First, we got the UDP port where the IPC will listen from, which is 12345; then we got information that the IPC A is available on IP address 192.168.1.1, on port 12345. We need such information since for the moment there is no name resolver (DNS) for RNS.
What is left is to enroll one IPC with the other now, in order for them to create a "network" and start exchanging forwarding and routing information. For example, on Machine 1, you can simply issue the command:
root@64:/# /RNS/linux/tools/bin/rnsctrl --enroll-to 1 1 B -1
IPCP 1 is going to enroll to B using -1...
IPCP 1 successfully enrolled to B...
Since there is no other IPC under us (we are using UDP instead), we give the last digit, which is the IPC number to use to perform the enrollment, as -1 (invalid). The successful message is given if the message leaves the machine without error, but there is no guarantee that it will reach its destination, since we are over UDP. If we start to receive information from the enrolled IPC, then we have the confirmation that the IPC accepted our enrollment (this hand-shaking mechanism can be made more robust; for the moment like this is enough for me).
All the other procedures remain practically unchanged! This means that the application on the top still uses the same command line in order to communicate between each other: they, in fact, do not know (and don't care) about what is giving service to them, as long as they respect the QoS they requested.
So, for the server (on Machine 1):
root@64:/# /RNS/linux/tools/bin/rnsping 1 1 a 2 --listen
while for the client (on Machine 2):
root@64:/# /RNS/linux/tools/bin/rnsping 1 1 b 2 a
The Models SDK
As I said, the project has been developed with simplicity in mind, and so it must offer a way to personalize various aspects of the communication without having to mess with the core stack itself. This is an important aspect since one of the current limitations of the TCP/IP stack is its rigidity, and the necessity to directly hack it if you need to perform something special.
Various elements in the RNS stack performs operations following models, which tell them how to behave in different situations. You can picture a model (in a technical view) as a standalone kernel module which offers some callbacks to the stack. When you register a model, you need to assign an id to it (this is why I assigned id 1 to RNS IPC model and id 2 to UDP IPC model). A catalog is maintained shared between all the stack instances, so you can publish the model for every IPC manager in the kernel.
The elements that you can personalize are:
- IPC, which allow you mainly to abstract a technology and decide how the recursion takes place into the stack. IPC models also decide how to "translate" a QoS profile of an upper layer to one of your layers, in order to use the right profile for a communication. An additional decision that IPC makes is decide how enrollment is handled. These two operations are aggregated here for simplicity, but is probable that a personal SDK will be introduced for them in the near future.
- Flow Allocators, which allow you to decide what to do when a new flow needs to be established. This is a global view of all the flows, and so can decide how to redistribute them, when to accept or negate a communication. The standard one offered now performs implicit flow definition, so a flow is created in the moment its first packet flows though the IPC. This is a matter of policy, and you can decide to use some more explicit mechanisms (you just have to write it yourself). During flow creation, you can also decide to apply a certain model to certain flows which, for example, follow a specific QoS.
- Flows, which allows you to decide how to handle communication with flow granularity. These are really important since it's here that you can introduce personalizations and state machines, like if you want to build a sort of TCP for RNS. During flow operations, you can also add/remove custom additional headers, or whatever you like more: you have full control on the flowing data.
- Pdu Forwarding Informant, which allows you to decide what kind of routing and forwarding decision you apply on datagrams. If you want to develop a specific routing strategy (like Dijkstra, ECMP, whatever... ) you build the logic here. These models also allow you to format and decode forwarding information update messages.
- RMT, which allows you to introduce custom scheduling algorithms at RMT level, which means apply a decision on every forwarded datagram. If for some reason, the model doesn't let the packet pass though him, then an error is reported an the scheduling event is invoked. In addition of this, you also can decide to apply some decisions for every packet forwarded (passed to the lower layers) or processed (passed to upper layers).
As for QoS and Enrollment, probably new SDK families will be introduced in the future, but for the moment, these are the only available ones that you can decide to personalize. Since models are a custom way to do something in the RNS network stack, you are free to use the strategy you like to handle your traffic. Unlike for the core parts, you do not need to share it on the repository, because they are a standalone components that can include a proprietary/patented logic.
Every model is independent from other type of models, so you can decide to swap one with another without having to change the entire IPC. Of course, there can be a case where you need two or more components to collaborate in order to ensure a certain service, but in that case, it is up to you to bind them together and ensure no mess is happening in the IPC. An example of this case can be a Flow Allocator and Flows models which have to coexist, where the FA needs a certain Flow model to be assigned to flows with a certain QoS, or RMT taking advantage of an additional header placed by a specific Flow model.
Soft Transaction to Recursive Network
Now it's time for some consideration of the transaction from the classical TCP/IP stack view to a recursive one. In the past years, hundreds of companies developed basic and advanced solutions for networking technologies using the classical approach and the IP technologies (both in term of software and hardware). Will all these efforts be wasted? Do we have to start everything from the beginning, negating all the solutions done until now?
Well, my personal answer is: NO!
What we achieved until now must not be destroyed. The network has become too complex to think of a complete reset of all its functionalities in order to introduce a new technology. If something has to be included, it must be done in a soft way, and such technology must grant a compatibility to old infrastructures.
If you think about the architecture like for lego bricks, you must be able to take every layer (brick) and organize it as you wish, or as the network itself requires. In this view, the TCP/IP layer (offered by the default network stack) is just a brick that you can decide to put on the top or on the bottom. By placing it at a different level, you achieve different services from the technology, which are:
- If you put TCP/IP on the top, you will be able to use existing, legacy IP applications over the Recursive network. Then, you can better organize (also in a hierarchical way) the network which is under the TCP/IP one without having this one to realize about the change. You can also write an IPC which abstracts over a certain technology and have TCP/IP working transparently over whatever technology without minimal effort (remember, like a lego brick, you attach at the bottom the necessary logic).
- If you put TCP/IP on the bottom, you can use it as a technology which provides world-wide connection, and you can add additional custom services to handle traffic or routing to better shape the flowing traffic. This is the approach used in the given example, where we had native RNS application running over UDP.
I also want to point out that I'm taking the particular example of TCP/IP in order to be clear in presenting the technology, but ideally this can be done with whatever technology you like more.
It's All Smoke and Mirrors... Again?
Aaaand again... I'm not here just to provide ideas for future project, but working prototypes (ok, I did an oxymoron here). Together with RNS, you can find a tool which allows you to filter all the IP traffic and redirect it into the RNS subsystem; this traffic then traverses the stack and its organization (which you decide and personalize as you need) and is delivered to another host, that will receive valid IP traffic on a valid interface. This allows legacy applications to run without any change, but with a minimal or no reconfiguration, over recursive networking technologies.
The project Balcora provides such functionalities by creating kernel-level applications which just have one job (kind of daemon at kernel-level), and it's filtering IP traffic flowing through a network device and pumping it into the RNS stack. When such type of traffic is received from the recursive (bottom) layer, it's injected back into the classic network stack. Upper layer applications (like a web browser) does not realize the change (except for a minimal additional latency) and thus continue to work without disruption.
Project Balcora is not built during normal compile operations of the stack, but you can find it under linux/tools/balcora. Just invoking the Makefile is enough to build it (as always, remember to adjust the project root folder if you cloned the project in a path different from /RNS).
cd /RNS/linux/tools/balcora/
make
insmod ./balcora.ko
This will create the balcora.ko kernel module and an user-space application called balctrl, which is the control utility you need to create kernel-level AE and bound them to an interface. You can now configure the RNS stack in order to match the configuration for remote communication, the example that we already had some chapters ago.
Starting from a clean load, you should configure the Machine 1 as (revisit the IP address to match your setup):
/RNS/linux/tools/bin/rnsctrl --create-ipcm
Going to create a new IPCM...
IPCM 1 successfully created...
/RNS/linux/tools/bin/rnsctrl --create-ipcp 1 A 2 "12345,B:192.168.1.2:12345"
Going to create a new IPCP...
IPCP 1 successfully created...
While machine 2 has to be configured as (revisit the IP address to match your setup):
/RNS/linux/tools/bin/rnsctrl --create-ipcm
Going to create a new IPCM...
IPCM 1 successfully created...
/RNS/linux/tools/bin/rnsctrl --create-ipcp 1 B 2 "12345,A:192.168.1.1:12345"
Going to create a new IPCP...
IPCP 1 successfully created...
Then, in order to create a network between these nodes, you need to enroll them like:
/RNS/linux/tools/bin/rnsctrl --enroll-to 1 1 B -1
IPCP 1 is going to enroll to B using -1...
IPCP 1 successfully enrolled to B...
Nothing wrong until here, and it's perfectly the same as it was before. What changes is that now you have to bound some interfaces in order to have them being filtered from IP or injected with the traffic incoming from RNS.
Since you cannot filter the network device you already are using between the two machines (or otherwise, you cannot communicate any more), you will need another ad-hoc one. If you are using Virtual Box (or other virtual machines), you can add additional interfaces before running the VM instance, or if you are on a Raspberry device/real pc you can use TUN/TAP services (balcora works with network devices, so also TUN is supported).
For machine 1, do something like:
ifconfig eth2 192.168.200.1 netmask 255.255.255.0
While for machine 2, it is:
ifconfig eth2 192.168.200.2 netmask 255.255.255.0
The idea is to have the interfaces on both the machines to communicate with each other as they were speaking directly, but in reality RNS over eth1 is used to accomplish the real communication. The two applications ('c' and 's' in the picture) do not realize this redirection of the data flow. This works in the end like a TUN/TAP device for recursive networks which provide translation between the two architectures.
If you try to ping between the two interfaces, nothing happens because no routing rules nor IPv4 forwarding is active by default on the machine, and so the stack cannot resolve where the traffic has to go (remember, you got the two additional interfaces but there is no "cable" between them).
If you configure the baclora instances like, on machine 1:
/RNS/linux/tools/bin/balctrl --create eth2 1 1 B 2 A
and on machine 2:
/RNS/linux/tools/bin/balctrl --create eth2 1 1 A 2 B
you can now successfully use the legacy ping, iperf and other technologies (like SSH too) without any problem (well, balcora is in Beta state, so performances can be lower in particular cases). In fact, two application instances are created, one named A on machine 1 and the other B on machine 2, and they simply exchange IP traffic using the QoS 2 (see baclctrl --help for more information on the command line syntax) on RNS network.
Again, a picture is necessary in order to better explain what is happening here:
Since we are speaking of some sort of lego bricks, you can replace now the bottom-most layer with straight ethernet, pure wifi, LTE technology or whatever you want that provide a communication service, and the legacy ping application continue to work without any problem (because it's totally abstracted). You can also insert more layers near the private network one, if you wish, and also this does not destroy the service (or at least you do not need any reconfiguration of the top most elements).
Feedback from the Kernel Space
Since the whole stack resides in the kernel space, how do you know that you are doing the right thing if there's no feedback mechanism that reports about its status?
Since I have to debug and improve it (and I want to do it in a soft way), there are several ways to get feedback from the user space. If you just want to use it, the best location where to get data from the stack is the sysfs folder that you can find under /sys/rns. The structure of the files and folders under that directory will match exactly what is happening in the kernel, and gives some additional information that you can use to check if your configuration is right.
If you want to write some code and load it in the stack, then it is a must to uncomment the pre-processor variable DEBUG_VERBOSE that you can find at the beginning of the debug.h file, located in the repository folder core/kal/linux. Remember to comment it again when you are finished, or otherwise, you will flood your machine with a lot of extensive debugging information (this is the primary source of information for developers on testers).
Conclusion
Finally, the article is over... it was really big (for me), and I usually prefer small and precise ones. But since the architecture is really uncommon to see around, and information about it is not known by the majority of the people out there, I had to introduce it with a proper example.
What you saw here is just the tip of the iceberg with recursive internetworking technologies; there's a new world to discover here. You don't have anymore the constrain of a huge, monolithic implementation difficult to handle, but now it is possible to scale the number of IPC and the network complexity as you wish (and this is done by design). Models SDK allow to introduce custom strategies to investigate how it behaves your personal forwarding schema or congestion control logic on the network.
Not only can you setup a native recursive network, but you can also use it to enhance communication of existing IP network stack. You can also use it as an abstraction layer to move existing network over different technology which requires otherwise a complex, ad-hoc, implementation.
I'll be available if you have any technical question (or insults), and I also move some efforts to create a more wide documentation directly in the repository of the project. You can get my mail by looking at documentation/credits.txt file, which is the contributors list.
History
- 05/25/2016 - Started to work on the article
- 06/15/2016 - Release of the first version of the article
- 10/09/2018 - Attached source files due to Github project removal

