Introduction
I was asked recently what kind of approach to take when one needs to display large volumes to data to a user in a linear manner. In particular, what if you had millions of records (or even just hundreds, same concepts apply!), and for whatever reason, needed to allow the user to be able to scroll through these. I have handled this before using some well traveled patterns so I thought it would be useful to put it down as a short article and share the knowledge.
Background
When dealing with anything more than a screenful of data, we need to consider how to present this data to the user. How will the user see the data and how can they navigate it? Clearly, anything more than a screens worth of data is too much for the poor human eye to take in at once and process with accuracy, so we need to implement some system of managing things behind the scenes. These basic concepts work the same for web as they do on desktop as they do on mobile (and perhaps other interfaces we haven't encountered yet!). This article looks at these (which you may know already nut have not thought too much about) and gives some examples and things to look out for.
Core Concept 1 - tracking user position
When a user requests data, they do it from a particular point of view, or position. The position taken, depends on the perspective and context of the data. Some examples:
- Facebook feed
- When you load up Facebook, depending on the underlying algorithms, you are presented with the latest posts of your friends, showing the most recent at the top of the page. The starting position here, is the last time perhaps that you logged in, or looked at this particular friends feed.
- CodeProject front page (1)
- After you land on the CodeProject homepage, you see 'Latest articles'. These are presented to you in a liner fashion. showing one featured article at the top, and then the ten latest article/tips. The starting position here, is the top ten articles published just before the time you logged in.
- CodeProject front page (2)
- When you get to the front page and you see the title bar, you notice, oh, I can filter this list of articles by clicking a button indicating a particular technology type. Currently available at time of writing for example are Android, C#, C++ etc.... When you click on one of the buttons, a filter is applied, and now, the starting position has changed to be not from all articles, but a subset of articles of a particular type.
With the above examples, we can see that the perspective of where the user stands in relation to the data they want to see, and we want to present to them, can be variable. Therefore a critical part of presenting large amounts of data to a user is understanding and tracking their user position relevant and in context to the overall dataset we are dealing with.
Core Concept 2 - data portals
When a user requests data, and we need to know a few things:
- what is the users required view of the entire dataset
- what is their position in relation to the required view
- what volume of data is the user capable of viewing/handling at one time
We have seen this pattern on the desktop and the web on many occasions - its the concept of data paging.
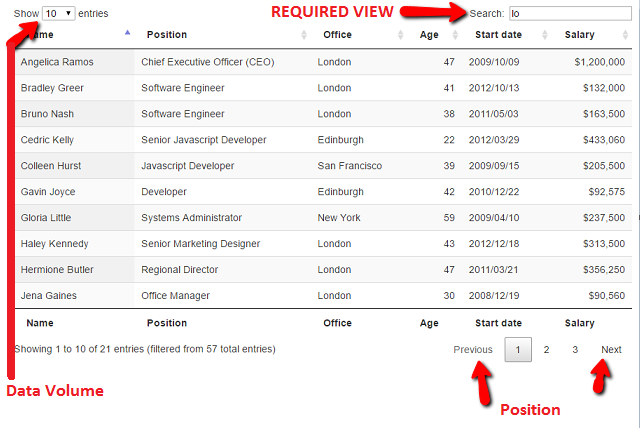
In the example above (from the wonderful datatables .net), we can see the users required view is a filter on any field that contains 'lo', their current position is 'page 1', and they only wish to view a volume of 10 records at one time.
Backend scrolling view-port management
It is clear and obvious from the front-end point of view, what's happening, or more correctly, what we are instructing to happen, but how is it handled on the backend?
To explain, lets look at a simple example of a dataset of 15 records. Lets assume that the user starts out at the first record, and wants to move through in blocks/views/sets of 5 records at a time. In step 1, we get records 1..5, step 2 records 6..10, and finally in step 3 records 11..15.

When the user clicks on the 'prev/next' buttons on the front-end, they send an instruction to the backend saying 'I am here at position X, please give me Y number of records from that position'.
Step 1 - Starting position = <Start> Record 0, from here, give me 5 records = Rec 1..5
Step 2 - Starting position = Record 5, from here, give me 5 records = Rec 6..10
Step 3 - Starting position = Record 10, from here, give me 5 records = Rec 11..15
This translates to the backend very simply, depending on the backend you are using - here are two examples:
SQL (2012): OFFSET (starting position) FETCH NEXT (count required) ref MSDN
eg:
SELECT RecordID, FirstName FROM Contacts
order by RecordID
OFFSET 10 ROWS
FETCH NEXT 5 ROWS ONLY
LINQ: SKIP (starting position) TAKE (count required) ref MSDN
var custQuery2 =
(from cust in db.Customers
orderby cust.ContactName
select cust)
.Skip(50).Take(10);
Check the documentation for whatever other backend you are using - there should be an equivalent methodology to allow you to implement this functionality.
Now, having pointed you to this common method of extracting a limited view of data from a structured dataset, I must caution you not to expect to rely on it every time. Always question the use case, the volume of data in question, the index fields you have to work with, etc. It may be the case that in very very large sets of data a map/reduce pattern may work well, or it may be that you have data pre-loaded for particular presentations of data that you can serve up, or it may be that the offset/limit slows down with a particular volume of data etc.... as usual, while this is a general 'how to', the specific answer in your case may well be 'it depends'. The basic concepts and patterns remain the same, the objective is to identify how to apply them best in your situation.
Here is an interesting read on how to approach things with an older structured database/rdbms if it does not natively support the offset concept.
Dynamic pagination
Before we move off simple tables of data, it is worth pointing out how to handle dynamic pagination. Where you are dealing with a reasonable amount of data, you would expect to see a pagination control something like this:
When you start adding data to it, what happens?
As you can see, the middle page numbers start to pad out ... this can get very messy very quickly. A good way to handle this is to visually shift the range of where you are indicating the user is in the view... heres how Google do it for example.. note the results start now at 9 and go to 18, and they tell us its page 14 of gazillons.... (they also give themselves a pat on the back for the speed of the result, and that's fine :))
Even Google does not allow you to search everything - sometimes they say - nope, you need to be more specific in your query please... take this message for example when I clicked past the 1000th page (the things I do for research!)..
(btw, the red text is mine... in jest!)
For further reading on pagination, have a look at the UI patterns pagination page, and if you want a good deep dive, kick your feet back and read Janko at Warp Speed on UI patterns for tables (its good!).
Four Ways to Optimize Paginated Displays
As the last brief word on optimizing pagination, heres a summary of some ideas by Bill Karwin on stack:
-
On the first query, fetch and cache all the results (nb: my note only for small datasets!)
-
Don't show all results. Not even Google lets you see the millionth result.
-
Don't show the total count or the intermediate links to other pages. Show only the "next" link.
-
Estimate how many results there are. Again, Google does this and nobody complains.
Tables and pagination are all very good, but what about this infinite scrolling business, how does that relate to the view portal concept? ... actually, it could be considered the same thing on the backend with a few tricks on the frontend, mostly concerned with pre and post caching of data the user is currently viewing. Lets look at how that works.
Core Concept 2 - caching
Infinite, or continuous scrolling, is effectively the same thing as pagination, except the user does not have to explicitly click to move to the next batch of data - we assume the intention for them. This can be triggered based on any number of triggers that suits your situation ... for example a scroll-bar hits its limit, the user scrolls tot he bottommost part of a page, the last piece of visible data on a screen is displayed into view... the trigger point, is simply down to your design.
The only real issue with infinite scrolling however, is how to optimize the experience for the user. How do we make it so that it feels seemless and fast? ... the answer lies in caching. At a very basic level, we anticipate what the user wants to do, and do it before they ask. There are numerous solutions out there that implement this for you as part of various presentation frameworks on different platforms, but its good to know the basic concepts of what might be happening under the hood. Lets look at one example approach.
Step 1 - default load
When we load up our webpage/app in the first place, we have a single default view ready for the user. This is the 'current view' shown below. In our app we know that the next thing the user will do is use their thumb/mouse to scroll the next piece of data into view. In this case, we already have our 'next view' loaded on the device/page, and are ready to show it immediately, there is no delay or distraction to the user experience. This 'next view' is cached by default, and ready to use. From a practical point of view, this means that when we set the page up, we load not only the current view, but also the 'next view' - the next view is not visible, but cached off-screen, and ready to use on-demand.
Step 2 - post and pre cache
When the user scrolls the 'next view' to become the 'current view', the current view moves away to be the 'previous view'. This new 'previous view' is cached invisible off-screen in case the user decides to scroll back up again. Immediately the 'next view' starts scrolling into place, we go straight off and fetch the next, 'next view' to replace it (its not quite inception, but it does come to mind!).
Step 2 - further management
Deciding what to do next is the domain of you the system designer. If you are designing this yourself from scratch you need to decide next steps, or, if you are using a pre-built system, you may have some configuration options you can choose to help flavor the size of cache etc. On a simplistic level, you may decide that as soon as you have moved two steps / scrolled away from an original 'current view', that realistically the user is not going to scroll back, and you might make the decision to delete that 'previous-previous-view'. Regardless of how your strategy works, the concept of pre-loading/caching data before you need it remains solid.
Data view
In case it helps, here is another view of what is happening as described above, but showing how the sample record data is being traversed....
You can read more about the infinite/continuous scrolling pattern on UI patterns.
Summary
That's the very basic core concept - obviously there is a lot more that can go on and this is the tip of the usual iceberg, however, hopefully it gives some a guide in the right direction.
Code examples
I will be uploading some code samples for this article shortly.
History
Version 1 - 7 July 2016.

