Introduction
I wrote this article because I was in need of a basic XML parser and could not find one suitable for my needs on the internet (a light weight parser).
The complexity of the parsers out there is rather disarming, and requires a huge amount of knowledge to understand. If you are not a seasoned C++ programmer, it is very hard to make sense of the code, and if you are then you have already written your own parser.
I wrote the parse function, then a set of classes for storing the data parsed, and an example on how to use it (MFC dialog based with a tree view). This parser is very simple and has only the basic functionality in order to work, no fancy stuff. There are some limitations to it:
- The parser recognizes comments to some extent. An error will be generated if any are found in the XML file outside the root node.
- As of 29-September-2010, some
CDATA support has been added. It is still limited (for example:
will generate an error). Also, CDATA sections may exist only as node values. Extra implementation can be easily added if needed but given the purpose of this project, I would prefer to leave like this, in order not to complicate the parse function to the extent that it gets difficult to modify. - No support for processing instructions
- No support for DTDs and entities
What is New
This project has been designed with simplicity in mind, in order to be able to assimilate the code base quickly and easily and add to it the extra functionality needed by each specific application.
These classes provide only the basic functionality, therefore is the most lightweight parser from all that I could find: 500 lines of code for the parser (including some unused base64 functions, which can be removed if necessary), and another 500 for the binary tree construct. If more functionality is needed, this has to be added in order to fulfill one's needs.
It is very easy to understand and work with this code as a base for further development.
The parsing function is iterative, it only goes once through the XML string, so the performance is quite satisfactory. The memory requirements are low, each object allocates just how much memory it actually needs. There is much more room for improvement, but it is not the target of this project.
How It Works
I personally think that nothing else needs to be said about this, because the code speaks for itself, and it has been designed to be easy to read and understand. If it is considered necessary, I can go in some details on how it works, and how to be enriched.
Using the Code
Dealing with the XML format, there are three classes (marked with a red dot) :
Cxml, CAttribute and CNode.
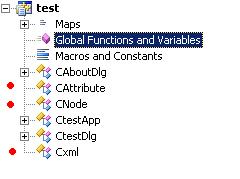
Cxml class is the working horse for this project and contains the parse function:
bool Cxml::ParseString(_TCHAR* szXML);
Once parsed, the information needs to be stored in memory in a manner easy to use, therefore the existence of the Node and Attribute classes.
The Node class has a tree like structure, having a parent pointer and a children list. It also contains a list of Attributes.
An addition to these classes, there is a Utils set of files (.h & .cpp) in which there are some utility functions.
How to Use It?
Well, in order to use it, you have to do the following:
After the ParseString returns, the structure of the XML is replicated in the class, and the XML root node can be retrieved with the...
oxml->GetRootNode();
...call.
There is a peculiarity here. Because I have adopted the "last in first out" way, the nodes will be organized in a reverse order than they are to be found in the original XML string.
The Node object can be navigated by using its public functions. Remember though that the GetNextChild() function increments the position of the counter and I have not implemented a way to reset it.
The best way to understand the inner workings is to get the demo project and test for yourselves. You will need Visual Studio 2008 to compile the project as is, without reconstruction. If you reconstruct remember: it has not been tested for Unicode.
Download the project and extract it. Compile. Run it and press the load button.

Choose one of the XML files provided as examples. Click open.
This is the result for one of the XML files provided.
<CATALOG>
...
<PLANT>
<COMMON>Snakeroot</COMMON>
<BOTANICAL>Cimicifuga</BOTANICAL>
<ZONE>Annual</ZONE>
<LIGHT>Shade</LIGHT>
<PRICE>$5.63</PRICE>
<AVAILABILITY>071199</AVAILABILITY>
</PLANT>
<PLANT>
<COMMON>Cardinal Flower</COMMON>
<BOTANICAL>Lobelia cardinalis</BOTANICAL>
<ZONE>2</ZONE>
<LIGHT>Shade</LIGHT>
<PRICE>$3.02</PRICE>
<AVAILABILITY>022299</AVAILABILITY>
</PLANT>
</CATALOG>
History
- September 20, 2010
- September 21, 2010
- September 22, 2010
- New version of the project has been updated
- Corrected a bug for multiple attributes
- Added 'some' support for comments. Comments outside the root node will generate an error
- September 28, 2010
- Tested for unicode, and added a unicode XML for ones test
- Removed the intellisense file from the project
- Removed the bug of confusing single quotes and double quotes with the actual delimiter found by Lorenzo Gatti
- September 29, 2010
- Added run-time support for UNICODE character set! The program must be compiled using this character set:
- September 29, 2010
- Some support for the
CDATA sections has been added - I also discovered that the Parse function needs some re-factoring because it got heavy and hard to understand.
- October 1, 2010
- Replaced all fixed size
char arrays from the project with dynamically allocated ones. - Added support for processing instructions. All processing instructions are now treated as a special type of node, just like the comments.
- Also comments can now exist outside the root-node of the XML since now the lowest level node is the
XML_DOC node, not the root-node of the XML.

