Introduction
Datalog is a subset of the Prolog programming language that is used as a query language in deductive databases[wiki].
Jatalog is a Datalog implementation in Java. It provides a parser for the language and an evaluation engine to execute queries that can be embedded into larger applications.
In a nutshell:
- The engine implements semi-naive, bottom-up evaluation.
- It implements stratified negation; Technically, it implements the Stratified Datalog¬ language[ceri].
- It can parse and evaluate Datalog programs from files and Strings (actually anything that implements
java.io.Reader). - It has a fluent API through which it can be embedded in Java applications to run queries.
- It implements "=", "<>" (alternatively "!="), "<", "<=", ">" and ">=" as built-in predicates.
- It avoids third party dependencies.
- Values with "quoted strings" are supported.
- Retract facts with the
~ operator, for example p(q,r)~. - The class
Shell implements a REPL command-line interface.
Background
A Datalog program consists of facts and rules. Facts describe knowledge about the world. Rules describe the relationships between facts from which new facts can be derived.
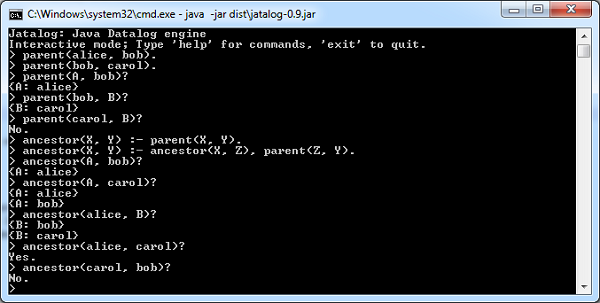
The following Datalog program describes that Alice is a parent of Bob and Bob is a parent of Carol, and then provides rules for deriving an ancestor relationship from the facts:[wiki]
% Facts:
parent(alice, bob).
parent(bob, carol).
% Rules:
ancestor(X, Y) :- parent(X, Y).
ancestor(X, Y) :- ancestor(X, Z), parent(Z, Y).
Variables in Datalog are capitalized. In the example, X, Y and Z are variables, whereas alice and bob are constants. Facts cannot contain variables - they are said to be ground.
The collection of facts is called the Extensional Database (EDB).
In the fact parent(alice, bob) the parent is called the predicate, while alice and bob are the terms. The number of terms is called the arity. The arity of parent is 2 and some literature will write it as parent/2. It is expected that all facts with the same predicate will have the same arity.
In the example, the two facts:
parent(alice, bob) reads "alice is a parent of bob"parent(bob, carol) reads "bob is a parent of carol"
The collection of rules is called the Intensional Database (IDB). Rules consist of a head and a body, separated by a :- symbol. The head of the rule describes a new fact that can be derived whereas the body describes how that fact should be derived.
In the rule ancestor(X, Y) :- parent(X, Y) the ancestor(X, Y) is the head, and parent(X, Y) is the body. It specifies that the fact "X is an ancestor of Y" can be derived if the fact "X is a parent of Y" holds true.
It is also said that the body of the rule implies the head, so parent(X, Y) implies ancestor(X, Y).
The Datalog engine will use this rule to determine that "alice is an ancestor of bob" and "bob is an ancestor of carol" when queries are executed.
The second rule ancestor(X, Y) :- ancestor(X, Z), parent(Z, Y) says that the fact "X is an ancestor of Y" can also be derived if there exists a Z such that "X is an ancestor of Z" and "Z is a parent of Y".
Using this rule, the Datalog engine will determine that "alice is an ancestor of carol" from all the other facts that have already been derived during query evaluation.
Queries can be run against the database once the facts and the rules have been entered into the system:
ancestor(X, carol)? queries "who are carol's ancestors?"ancestor(alice, Y)? queries "of who is alice the ancestor?"ancestor(alice, carol)? asks "Is alice an ancestor of carol?"
Answers come in the form of a collection of the mapping of variable names to values that satisfy the query. For example, the query ancestor(X, carol)?'s results will be {X: alice} and {X: bob}.
Jatalog implements some built-in predicates which can be used in rules and queries: equals "=", not equals "<>", greater than ">", greater or equals ">=", less than "<" and less or equals "<=".
You can have multiple clauses in a query, separated by commas. For example sibling(A, B), A <> alice? asks "who are siblings of A where A is not alice?"
Additionally, Jatalog's syntax uses the ~ symbol for retracting facts form the database. For example, the statement planet(pluto)~ will retract the fact that pluto is a planet. The syntax is adapted from [rack]'s, but it is unclear whether other Datalog implementations use it.
The retract query can contain variables and multiple clauses: The statement thing(N, X), X > 5~ will delete all things from the database where X is greater than 5.
Using the Code
If you want to use the Java API, you just need to add the compiled JAR to your classpath.
The Main-Class in the JAR's manifest points to za.co.wstoop.jatalog.Shell, which implements the REPL interface. To start the interpreter, simply run the JAR file with the Java -jar command-line option, like so:
java -jar target/jatalog-0.0.1-SNAPSHOT.jar [filename]
In addition to an interpreter for the Datalog language, Jatalog also provides an API through which the database can be accessed and queried directly in Java programs.
The following is an example of how the facts and the rules from above example can be written using the Fluent API:
Jatalog jatalog = new Jatalog();
jatalog.fact("parent", "alice", "bob")
.fact("parent", "bob", "carol");
jatalog.rule(Expr.expr("ancestor", "X", "Y"),
Expr.expr("parent", "X", "Z"), Expr.expr("ancestor", "Z", "Y"))
.rule(Expr.expr("ancestor", "X", "Y"), Expr.expr("parent", "X", "Y"));
The queries can then be executed as follows:
Collection<Map<String, String>> answers;
answers = jatalog.query(Expr.expr("ancestor", "X", "carol"));
The answers collection will contain a list of all the variable mappings that satisfy the query:
{X: alice}
{X: bob}
The query from the previous example can also be written as
answers = jatalog.executeAll("ancestor(X, carol)?");
Jatalog also provides a Jatalog.prepareStatement() method that will parse strings into Statement objects that can be executed later. The Statement.execute() method takes a Map<String, String> of variable bindings as a parameter, so that it can be used to do batch inserts or queries. For example:
Statement statement = Jatalog.prepareStatement("sibling(Me, You)?");
Map<String, String> bindings = Jatalog.makeBindings("Me", "bob");
Collection<Map<String, String>> answers;
answers = statement.execute(jatalog, bindings);
In the above example, the variable Me is bound to the value bob, so the statement.execute(...) line is equivalent to executing the query sibling(bob, You)?.
The Javadoc documentation contains more information and the unit tests in the src/test directory contain some more examples.
Compiling with Maven
The preferred method of building Jatalog is through Maven.
# Compile like so:
mvn package
# Generate Javadocs
mvn javadoc:javadoc
# Run like so:
java -jar target/jatalog-0.0.1-SNAPSHOT.jar file.dl
Where file.dl is the name of a file containing Datalog commands to be executed. It is omitted, the interpreter will enter an interactive mode where commands will be read from System.in.
Compiling with Ant
An Ant build.xml file is also provided:
# Compile like so:
ant
# Generate Javadocs
ant docs
# Run like so:
java -jar dist/jatalog-0.0.1.jar
Points of Interest
Jatalog's evaluation engine is bottom-up, semi-naive with stratified negation. See [ceri] for more details.
Bottom-up means that the evaluator will start with all the known facts in the EDB and use the rules to derive new facts. It will repeat this process until no more new facts can be derived. It will then match all of the facts to the goal of the query to determine the answer. (The alternative is top-down, where the evaluator starts with a series of goals and uses the rules and facts in the database to prove those goals.)
Semi-naive is an optimization of the Datalog engine wherein the evaluator will only consider a subset of the rules that may be affected by facts derived during the previous iteration, rather than all of the rules in the IDB.
Stratified negation means that the order in which rules are evaluated are arranged in such a way that negated goals cause sensible facts to be derived.
Consider, for example, the rule p(X) :- q(X), not r(X). with the fact q(a) present in the EDB, but not r(a), and suppose that there are other rules in the database that imply p(X) and r(X). If the engine were to evaluate these rules naively, then it will derive the fact p(a) in the initial iteration. It is then possible that the fact r(a) may be derived in a subsequent iteration, which results in the facts p(a) and r(a) contradicting each other.
The stratified negation evaluates the rules in an order such that all the r(X) facts are derived before any of the p(X) facts can be derived which eliminates such contradictions.
Stratified negation puts additional constraints on the usage of negated expressions in Jatalog, which the engine checks for.
The above are well known optimization and evaluation techniques described in the literature. See [ceri] for a good overview. Jatalog also implements some other minor optimizations where it makes sense:
- The class
StackMap provides a Map implementation that has a handle to a parent Map. A large part of Jatalog's internal implementation revolves around looking up variable bindings in recursive calls in the Engine.matchGoals() method. Having the StackMap eliminates the need to copy existing variable bindings into a new Map with each recursive call to matchGoals(). - The class
IndexedSet is a Set implementation where the elements stored in it can be indexed according to some key for quick lookup. The Jatalog implementation uses it to group the facts by predicate, and find those facts quickly. It prevents iterating through the entire EDB when it already knows the predicate it is looking for. - Jatalog also filters out irrelevant facts before it starts the bottom-up expansion of the database. For example, if the query is about the
ancestor predicate, then the bottom-up expansion does not need to expand rules relating to employed. This is done through a mechanism similar to the semi-naive evaluation in the getRelevantPredicates() method of the Engine class.
There are opportunities to run some of the methods in parallel using the Java 8 Streams API (I'm thinking of the calls to expandStrata() in expandDatabase() and the calls to matchRule() in expandStrata() in particular). This is a bit more complicated than I thought it would be, and so I'm not too concerned about implementing it at the moment.
I've decided against arithmetic built-in predicates, such as plus(X,Y,Z) => X + Y = Z, for now because they aren't that simple. They should be evaluated as soon as the input variables (X and Y) in this case becomes available, so that Z can be computed and bound for the remaining goals. It would require a more complex parser and for the Expr objects to represent an abstract syntax tree.
It is conceptually possible to make the List<String> terms of Expr a List<Object> instead, so that you can store complex Java objects in the database (as POJOs). It won't be that useful a feature if you just use the interpreter, but it could be a nice-to-have if you use the fluent API. I don't intend to implement it at the moment, though.
References
- [wiki] Wikipedia topic, http://en.wikipedia.org/wiki/Datalog
- [elma] Fundamentals of Database Systems (3rd Edition); Ramez Elmasri, Shamkant Navathe
- [ceri] What You Always Wanted to Know About Datalog (And Never Dared to Ask); Stefano Ceri, Georg Gottlob, and Letizia Tanca
- [bra1] Deductive Databases and Logic Programming; Stefan Brass, Univ. Halle, 2009 http://dbs.informatik.uni-halle.de/Lehre/LP09/c6_botup.pdf
- [banc] An Amateur’s Introduction to Recursive Query Processing Strategies; Francois Bancilhon, Raghu Ramakrishnan
- [mixu] mixu/datalog.js; Mikito Takada, https://github.com/mixu/datalog.js
- [kett] bottom-up-datalog-js; Frederic Kettelhoit http://fkettelhoit.github.io/bottom-up-datalog-js/docs/dl.html
- [davi] Inference in Datalog; Ernest Davis, http://cs.nyu.edu/faculty/davise/ai/datalog.html
- [gree] Datalog and Recursive Query Processing; Todd J. Green, Shan Shan Huang, Boon Thau Loo and Wenchao Zhou Foundations and Trends in Databases Vol. 5, No. 2 (2012) 105-195, 2013 http://blogs.evergreen.edu/sosw/files/2014/04/Green-Vol5-DBS-017.pdf
- [bra2] Bottom-Up Query Evaluation in Extended Deductive Databases, Stefan Brass, 1996 https://www.deutsche-digitale-bibliothek.de/binary/4ENXEC32EMXHKP7IRB6OKPBWSGJV5JMJ/full/1.pdf
- [sund] Datalog Evaluation Algorithms, Dr. Raj Sunderraman, 1998 http://tinman.cs.gsu.edu/~raj/8710/f98/alg.html
- [ull1] Lecture notes: Datalog Rules Programs Negation; Jeffrey D. Ullman; http://infolab.stanford.edu/~ullman/cs345notes/cs345-1.ppt
- [ull2] Lecture notes: Datalog Logical Rules Recursion; Jeffrey D. Ullman; http://infolab.stanford.edu/~ullman/dscb/pslides/dlog.ppt
- [meye] Prolog in Python, Chris Meyers, http://www.openbookproject.net/py4fun/prolog/intro.html
- [alec] G53RDB Theory of Relational Databases Lecture 14; Natasha Alechina; http://www.cs.nott.ac.uk/~psznza/G53RDB07/rdb14.pdf
- [rack] Datalog: Deductive Database Programming, Jay McCarthy, https://docs.racket-lang.org/datalog/ (Datalog library for the Racket language)
History
Version 0.9
- This is the initial version released for public scrutiny.
For convenience, the source code is also stored on https://github.com/wernsey/Jatalog.

