Update 06.10.2021
- New Hardware tested: Insane improvements since 2016!
NVIDIA GeForce RTX 3080
Single GFlops = 27089,95GFlops = 27TFlops
Update 13.12.2016
- Works on multiple GPUs and any other OpenCL device now. Please comment your result of the demo
Introduction
This project is going to show you that a modern Core I7 is probably the slowest piece of programmable hardware you have in your PC. Modern Quad Core CPUs have about 6 Gflops whereas modern GPUs have about 6Tflops of computational power.
This project can dynamically execute simple programs written in a C dialect (OpenCL C) on your GPU, CPU or both. They are compiled and executed at run time.
This is also going to show that GPU programming does not have to be hard. In fact, you only need a little bit of basic programming skills for this project.
If you want to skip the introduction and dive into using this, feel free to download the source code.
Do I Need This?
Your computer is a very powerful machine. By using only the CPU to execute tasks, you might waste about 90% of its potential.
If you have a piece of code which is concurrent and you want to speed it up, this is the right project for you. Ideally, all your data fits into some float or other numeric arrays.
Examples for a potential speed up would be:
- Work on pictures or movies
- Any work that can be done parallel
- Do hard number crunching on your GPU
- Save energy and time by using GPU and CPU in parallel
- Use your GPU for any task and have your CPU free to do something else
Keep in mind that this project uses OpenCL. Unlike Cuda, it runs on any GPU (Amd, Nvidia, Intel) and also on the CPU. So any program you write can be used on any device. (Even phones)
Tested on NVIDA, AMD, and Intel.
These are the results for simple prime calculation:
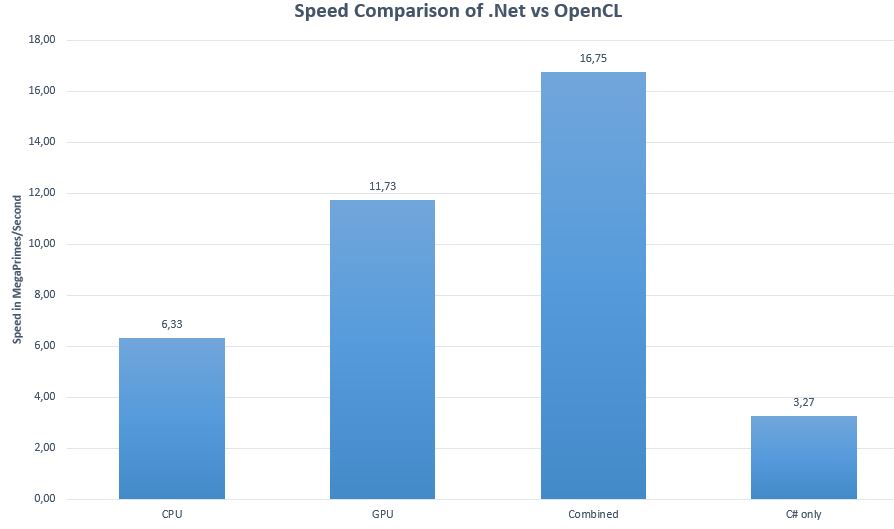
As you can see, you really can speed up your program a LOT. Native C# is 5x slower than the best speed you can get on your PC. This is not even the best case scenario. The speedup factor can approach 500x in pure multiply add workloads. (GPUs really shine in this domain). If there are many ifs, the CPU can be better sometimes.
Most importantly, it is really easy to write a program for your GPU and CPU with this class.
OpenCL code always runs faster than C# on arrays and is really easy and quick to just use with this project.
(See example below) The overhead you have as a developer is literally zero. Just write a function and you are done. Dont think about computedevices, pinvoke, marshalling and other stuff.
How Do I Use It?
OpenCL programming can be a very time consuming task. This helper project will reduce your programming overhead so that you can concentrate on the core problem. It is written in C# but could be adapted to any .NET language and also C++.
Imagine you wanted to know all prime numbers from 2 to 10^8. Here is a simple implementation in C# (yes, I know there are much better algorithms to calculate primes).
static void IsPrimeNet(int[] message)
{
Parallel.ForEach(message, (number, state, index) =>
{
int upperlimit = (int)Math.Sqrt(number);
for(int i=2;i<=upperlimit;i++)
{
if (message[index]%i == 0)
{
message[index] = 0;
break;
}
}
});
}
Now we take this code and translate it to OpenCL-C.
The following Kernel is declared as a string in a file, inline or in a resource file.
kernel void GetIfPrime(global int* message)
{
int index = get_global_id(0);
int upperl=(int)sqrt((float)message[index]);
for(int i=2;i<=upperl;i++)
{
if(message[index]%i==0)
{
message[index]=0;
return;
}
}
}
OpenCL does wrap your kernel (piece of code to run) in a loop. For simple 1D Arrays, you can get the index by calling get_global_id(0); The upper index of your index is passed when you invoke the kernel.
For more information, check out this link.
Instead of int[], you write int* and so on. You can also pass every other primitive type (int, float...).
You have to pass arguments in the same order in which you declared them. You can also call printf inside your kernel to debug later. You can define as many methods as you like inside the kernel. You pick the entry point later by calling Invoke("Name Here").
OpenCL C is the same as C but you cannot use pointers and you also have some special data types.
For in depth information, check out this link.
Here is how you would use this project:
- Add the Nuget Package
Cloo - Add reference to OpenCLlib.dll.
Download OpenCLLib.zip. - Add
using OpenCL
static void Main(string[] args)
{
int[] Primes = Enumerable.Range(2, 1000000).ToArray();
EasyCL cl = new EasyCL();
cl.Accelerator = Accelerator.Gpu;
cl.LoadKernel(IsPrime);
cl.Invoke("GetIfPrime", Primes.Length, Primes);
}
static string IsPrime
{
get
{
return @"
kernel void GetIfPrime(global int* message)
{
int index = get_global_id(0);
int upperl=(int)sqrt((float)message[index]);
for(int i=2;i<=upperl;i++)
{
if(message[index]%i==0)
{
//printf("" %d / %d\n"",index,i );
message[index]=0;
return;
}
}
//printf("" % d"",index);
}";
}
}
With this, you can dynamically compile and invoke OpenCL kernels. You can also change your accelerator (CPU, GPU) after you have loaded the kernel.
If you want to use every bit of computational power of your PC, you can use the class MultiCL. This class works by splitting your work into N parts. Every part is pushed onto the GPU or CPU whenever possible. This way, you get the maximum performance from your PC. You also know how much work is already done which is not possible with EasyCL.
static void Main(string[] args)
{
int[] Primes = Enumerable.Range(2, 1000000).ToArray();
int N = 200;
MultiCL cl = new MultiCL();
cl.ProgressChangedEvent += Cl_ProgressChangedEvent1;
cl.SetKernel(IsPrime, "GetIfPrime");
cl.SetParameter(Primes);
cl.Invoke(0, Primes.Length, N);
}
private static void Cl_ProgressChangedEvent1(object sender, double e)
{
Console.WriteLine(e.ToString("0.00%"));
}
How Does It Work?
This work references the Nuget package Cloo. With Cloo, calls to OpenCL are possible from .NET.
It basically hides all the implementation details you need to know to use OpenCL and Cloo. To get more information about your kernel or device, use the class OpenCL.
There are 3 classes in this project:
EasyCL (Call Kernels very easily)MultiCL (Call Kernels on all OpenCL devices at the same time for max speed)OpenCL (Call Kernels and get some information about your device)
Internally, every call to Invoke calls the corresponding methods in the OpenCL API:
void Setargument(ComputeKernel kernel, int index, object arg)
{
if (arg == null) throw new ArgumentException("Argument " + index + " is null");
Type argtype = arg.GetType();
if (argtype.IsArray)
{
Type elementtype = argtype.GetElementType();
ComputeMemory messageBuffer = (ComputeMemory)Activator.CreateInstance
(typeof(ComputeBuffer<int>), new object[]
{
context,
ComputeMemoryFlags.ReadWrite | ComputeMemoryFlags.UseHostPointer,
arg
});
kernel.SetMemoryArgument(index, messageBuffer);
}
else
{
typeof(ComputeKernel).GetMethod("SetValueArgument").MakeGenericMethod(argtype).Invoke
(kernel, new object[] { index, arg });
}
}
Every time you change the kernel or the accelerator, the program gets recompiled:
For a faster prototyping phase, this class also tells you why you cannot compile your kernel.
public void LoadKernel(string Kernel)
{
this.kernel = Kernel;
program = new ComputeProgram(context, Kernel);
try
{
program.Build(null, null, null, IntPtr.Zero);
}
catch (BuildProgramFailureComputeException)
{
string message = program.GetBuildLog(platform.Devices[0]);
throw new ArgumentException(message);
}
}
It is very important to know that if your GPU driver crashes or kernels use 100% of your GPU for more than 3 seconds (on pre Win10 machines), the kernel will get aborted. You should dispose the EasyCL object after that.
EasyCL cl = new EasyCL();
cl.InvokeAborted += (sender,e)=> Cl_InvokeAborted(cl,e);
private void Cl_InvokeAborted(EasyCL sender, string e)
{
}
For some reason, I don't know it is faster to invoke an empty kernel first and then all subsequent calls are faster. (OpenCL initialization maybe).
What is Missing?
You cannot choose if you want to use the host pointer or read write access to int[] passed to the kernel. I did not see any performance gain by setting an array to read only. This seems to be a legacy function.
This class is written for PCs. With Visual Studio/Xamarin, it should be easy to adapt it for phones. (Modern Smartphones with 8 Cores do rival most Laptops in performance.)
Make sure to have all the newest drivers installed.
http://www.nvidia.com/Download/index.aspx?lang=en-us
http://support.amd.com/en-us/download
https://software.intel.com/en-us/articles/opencl-drivers#latest_CPU_runtime
How Can I Help?
If you see this article and want to help out, please download the demo program. I would be very interested in your results.
My Results:
(06.10.2021 - Time flies - Hardware gets faster!)
NVIDIA GeForce RTX 3080
Single GFlops = 27089,95GFlops
Double GFlops = 567,55GFlops
Memory Bandwidth = 0,40GByte/s
AMD Ryzen 9 5950X 16-Core Processor
Single GFlops = 91,01GFlops
Double GFlops = 87,24GFlops
Memory Bandwidth = 1,15GByte/s
(13.12.2016)
AMD RX480:
5527,46 Single GFlops
239,78 Double GFlops
Intel(R) Core(TM) i7-4790K CPU @ 4.00GHz:
6,63 Single GFlops
7,33 Double GFlops
(10.09.2016)
GeForce GTX 1060 6GB
Single GFlops = 3167,97GFlops
Double GFlops = 233,58GFlops
Memory Bandwidth = 3,55GByte/s
Intel(R) Core(TM) i7-4790K CPU @ 4.00GHz
Single GFlops = 201,32GFlops
Double GFlops = 206,96GFlops
Memory Bandwidth = 3,10GByte/s

