Source code:
https://github.com/rivantsov/LockDemo
Introduction
The data in relational databases is often logically organized into documents (invoices, purchase orders) with parts residing in multiple tables, linked through one-to-many or many-to-many relationships. These documents usually have some internal consistency requirements (order total should match sum of all order items). While we can ensure consistency by properly programming individual CRUD operations, the challenge is to manage the concurrent attemps to edit and load documents, to prevent problems like deadlocks, broken internal contstraints, or loading snapshot in the middel of the edit.
An example of internal consistency requirement - an Invoice total should always match the sum of order lines (items). With several concurrent processes adding items to an invoice there is a chance the total ends up wrong - the last finished process would set it to what it thinks it should be, not knowing there are more just added by concurrent process. And an attempt to read the document while it is in the middle of the edit by other process may result in a broken snapshot, with invoice total not matching sum of its lines.
The solution is to serialize edits and reads using explicit locks in the database - to ensure that no two processes edit the same document semiltaneously, and that read operations have to wait for completion of any edits. Automatic, implicit locks set by the database engine are not enough - the engine does not know the total scope of the operation and which records should be locked in advance. Now, it should not be a big problem, right?
Document locking - such a common and important task, should be straightforward and reasonably easy to implement! Just common sense...
But this is not the case. Not always. It is in fact pretty straightforward for 'other' servers - MySql, PostgreSql, Oracle. For MS SQL Server it turned out to be a real challenge. I have gone through this experience and would like to share my findings.
This article contains not only findings and recommendations for proper locking, but also a demo/test app that verifies the solution, and also provides a playground to try and test different approaches.
Document locking turned out to be one of those rare cases, when in-place testing of the solution is not sufficient. You need a separate, standalone app with some 'unrealistic', hardened workload to verify that you got it right. When it comes to locks, the initial assessment - 'I tried and it seems to work' - might be quite misleading. (it happened to me in fact). It takes a specially written app - 30 threads beating on 5 documents - to uncover the truth: it does not quite work. But we are always too busy to write a separate app to test the solution when there's no apparent reason to suspect that things are not so simple.
So the accompanying demo app is this test app that we are usually too busy to write. Play with it, try it in different modes, with and without locks; try changing isolation levels, number of threads, twist SQLs, etc - to see what actually works and what fails. Quite possible, you might discover that some (simpler?) alternative works (simpler compared to what I suggest below); then just let me and others know.
Background
Database servers use locks to manage concurrent access to data. First, there are automatic locks - these are set automatically by the database engine, mostly to prevent data corruption that can happen if 2 or more processes edit the same record at the same time. These automatic locks, while preserving integrity of the data, sometimes have bad effects - deadlocks.
The servers expose locking functionality to the applications to let them establish locks explicitly, to avoid bad things like deadlocks or reading partially changed document, in the middle of the edit.
Locks in the database have a scope (lifetime) and it is the enclosing transaction. When transaction commits or aborts, all locks are released. What about a lock when there is no transaction? There is always a transaction. Simply when you execute a single SQL statement without transaction, the database encloses it into an implicit, automatic transaction. As a result, the lock established in a standalone statement without explicit transaction will be released immediately after the statement is finished - because its enclosing implicit transaction will be committed automatically after the statement completes.
Let's again list our goals.
- Prevent deadlocks from automatic locks by the database engine when we update the documents.
- Preserve the document integrity. - total in header should match sum of detail rows.
- Loading a consistent snapshot of the document, which does not include any incompleted changes which were in progress at the time of the load.
- Additional requirement - concurrent reads should not block each other, to improve throughput. Only concurrent updates should be exclusive.
To achieve the first two goals (update preserving consistency and no deadlocks), an obvious solution is to put an exclusive update lock on the document at the beginning of the transaction. The database engine really does not know about documents, it knows about and can lock only rows in tables. To lock the document, we need to explicitly lock the 'root' - document header, some data row that is always there and serves as a 'main/header' part - like PurchaseOrderHeader or Invoice Header rows in corresponding tables. The trick is to lock the header at the very beginning of the transaction, and to do it even if we do not plan to update the header itself but only modify the child items/lines.
For consistent clean read we set a shared read lock on the document header. The lock should be 'shared', so that concurrent reads do not block each other. Just like with updates, the lock should be set at the start of the transaction. Transaction? - you may ask, - for reading? Yes, we must execute read (all SELECT statements) within an explicit transaction - because lock's lifetime is the enclosing transaction, and this is the only way to ensure that no concurrent change happens while we load the doc.
Database servers (some of them) support a special way of managing concurrent updates: row versioning. Basically the server keeps multiple versions of the same row while concurrent updates (and reads) are in progress, and uses them to serve 'consistent' views of the data to each process. In this case, if we read data within a transaction, the version we see is always the data as it was at the start of the transaction. So for these servers (Postgres, Oracle, and now MS SQL with snapshot isolation) we do not need to set any read locks, just execute SELECTs within a transaction.
The logical sequence is the following for any read or update operation:
- Start transaction
- Load the document header with appropriate lock
- Perform all other read and/or update operations
- Commit transaction
Note that in both read or update cases, we start with loading (SELECT) of the header, only with different locks. For an update operation that might seem like some extra, unneeded load; but usually that's the way it usually works, at least in web applications. When the server receives an update command from the client, it starts with loading the doc, applies the changes to 'objects', and then submits the document to the database. So this SELECT it is not completely out of the line.
Now we can turn to actual implementation, but first we will review the accompanying demo app and what it is doing.
Using the code
The sample code for the article is in github repo: https://github.com/rivantsov/LockDemo
The app can execute a locking test against any of the servers: MS SQL Server, PostgreSQL, MySql, Oracle. You must have an installation of the target server somewhere. Download the zip from repo, open the solution in Visual Studio 2015, and follow the instructions in the ReadMe.md file. Basically you need to choose the server, adjust the connection string in the app.config for this server, run the DDL scripts to create database tables, and finally run the app.
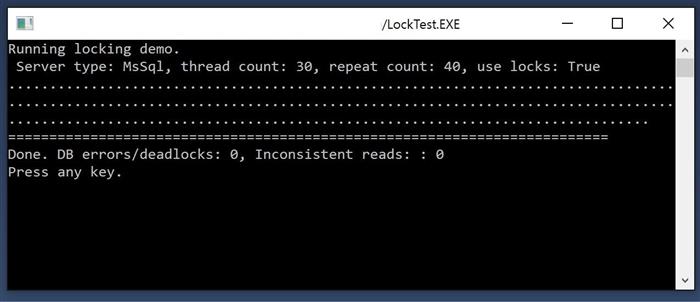
Try running it with no locks to see the difference (set UseLocks=false in app.config file):

The following section explains some internals of the app - the data model, locks for different servers, etc. After that we will get to particulars of each server and how to lock things properly.
Demo app and sample document model
The demo app uses a simplified data model of a compound document with master/detail parts:
The document consists of a header in the DocHeader table, and multiple DocDetail records linked to the header. The primary key for header is the DocName column. The DocDetail rows are identified by Name, and the primary key is composite: (DocName, Name). The document is simply a named thing with a dictionary of name-value pairs. The header has Total column - it should be equal to the sum of all values in related DocDetail rows - this is an internal 'consistency' constraint.
Note: Please do not focus on this 'design', this is not NOT the way I do things in the real world. Rather, it is the most simplified example that illustrates the point of the article - working with multi-part documents in a relational database. This is just a demo model!
The demo app initially creates 5 documents with names 'D0'..'D4', each having 5 child DocDetail rows with names 'V0'..'V4'. The documents are initially consistent (valid, correct) - all Value and Total values are zeros. We pre-create all documents and do not insert or delete anything during the main part of the test, only update the existing records. The case with random inserts/deletes would be probably even more interesting, but for simplicity we limit to updates only - trust me, it uncovers all bad things that are there.
After creating the docs, the application starts the main run. It launches 30 threads, each repeating 40 times the following operation:
Randomly choose one of two actions - Read or Update.
- For Update action: Start transaction; randomly choose the document name and 3 random value names (out of V0..V4). Update these 3 values with a random number in the range 1..10; load all details rows, calculate total and update header's Total value; commit.
- For Read action: Pick random document name, load the document header, load all detail rows. Calculate total of details' Value columns, compare to Total in the header. If mismatch - this is a consistency check error, increment the error count.
The following snippet is the method that runs the operations on a separate thread, one of 30:
private void RunRandomOps(object objRepo) {
var repo = (DocRepository)objRepo;
var rand = new Random();
DocHeader doc;
int total;
for(int i = 0; i < Program.RepeatCount; i++) {
if(i % 5 == 0)
Console.Write(".");
Thread.Yield();
var op = rand.Next(2);
var docName = "D" + rand.Next(5);
try {
switch(op) {
case 0:
repo.Open(forUpdate: true);
if(Program.UseLocks)
doc = repo.DocHeaderLoad(docName);
repo.DocDetailUpdate(docName, "V" + rand.Next(5), rand.Next(10));
repo.DocDetailUpdate(docName, "V" + rand.Next(5), rand.Next(10));
repo.DocDetailUpdate(docName, "V" + rand.Next(5), rand.Next(10));
total = repo.DocDetailsLoadAll(docName).Sum(d => d.Value);
repo.DocHeaderUpdate(docName, total);
repo.Commit();
break;
case 1:
repo.Open(forUpdate: false);
doc = repo.DocHeaderLoad(docName);
total = repo.DocDetailsLoadAll(docName).Sum(d => d.Value);
if(total != doc.Total) {
Interlocked.Increment(ref InconsistentReadCount);
var msg = "\r\n--- Inconsistent read; doc.Total: " + doc.Total + ", sum(det): " + total;
Console.WriteLine(msg);
repo.Log(msg);
}
repo.Commit();
break;
}
} catch(Exception ex) {
Interlocked.Increment(ref DbErrorCount);
Console.WriteLine("\r\n--- DB error: " + ex.Message + " (log file: " + repo.LogFile + ")");
repo.Log("Db error ----------------------------------- \r\n" + ex.ToString() + "\r\n");
repo.Rollback();
}
}
}
The execution is sprinkled with calls to Thread.Yield(), you see one in the code above, there are more. This makes thread switching more frequent to 'harden' the test. Thread count and repeat count can be changed in the app.config file.
The app.config file also has 'UseLocks' setting: if false, the test will run without any locks, and you will see multiple errors: update operations cause deadlocks, while read operations result in failed consistency check - docHeader.Total does not match Sum of docDetail rows. With UseLocks set to true, you see no errors - the app is using appropriate locking strategy for the selected server type, and all goes OK.
The app writes all SQLs and errors into log files in the bin/debug folder, a separate file for each thread, named 'sqllog_N.log' where N is a thread number - so if you are interested in detail SQL and error stack traces - look there. Here is a sample of SQLs in the log file, with document load followed by update for MySql:
BeginTransaction
SELECT "DocName", "Total" FROM lck."DocHeader" WHERE "DocName"='D2' LOCK IN SHARE MODE
SELECT "DocName", "Name", "Value"
FROM lck."DocDetail" WHERE "DocName"='D2'
Commit
BeginTransaction
SELECT "DocName", "Total" FROM lck."DocHeader" WHERE "DocName"='D2' FOR UPDATE
UPDATE lck."DocDetail"
SET "Value" = 6 WHERE "DocName" = 'D2' AND "Name" = 'V0'
UPDATE lck."DocDetail"
SET "Value" = 0 WHERE "DocName" = 'D2' AND "Name" = 'V2'
UPDATE lck."DocDetail"
SET "Value" = 1 WHERE "DocName" = 'D2' AND "Name" = 'V2'
SELECT "DocName", "Name", "Value"
FROM lck."DocDetail" WHERE "DocName"='D2'
UPDATE lck."DocHeader" SET "Total" = 7 WHERE "DocName" = 'D2'
Commit
A few words about implementation for multiple servers. The app runs SQL statements through a class named DocRepository - it constructs the SQL and executes it. For each supported server type there is a subclass that slightly adjusts the behavior of the base class for the target server. The main adjustments are in the class constructor: we alter SQL templates for loading the header with read or write lock - each server has its own hints/clauses. In addition, MS SQL and Oracle require specific isolation levels for transactions.
Programmatic control of locks in various servers
We now get to the core subject of the article - concrete patterns for proper concurrency management in various database servers. If we use ADO.NET we have the following control points to manage the execution of SQL statements at the server:
- Transaction Isolation Level - when we open a transaction using connnection.BeginTransaction method we can provide a desired isolation level as a parameter. If no value provided, the level is Unspecified.
- Hints or special SQL keywords/clauses added to SQL statements that specify required locks.
- Database-wide settings that must be set properly to make locking work in a desired way. It turns out only MS SQL Server needs these options, other servers work out-of-the-box, with the default settings.
The following subsections list the exact settings and provide examples for each of the servers.
MySql
Transaction Isolation Level for read and write: Unspecified
SQL clauses
Read: LOCK IN SHARE MODE
Write: FOR UPDATE
Examples:
SELECT "DocName", "Total" FROM lck."DocHeader" WHERE "DocName"='N1' LOCK IN SHARE MODE
SELECT "DocName", "Total" FROM lck."DocHeader" WHERE "DocName"='N1' FOR UPDATE
Note: Remember that to start updating document we need to lock the header - even if we are not going to update the header, only detail rows. We do it by selecting the header with 'update' lock.
PostgreSql
Transaction Isolation Level for read and write: Unspecified
SQL clauses
Read: FOR SHARE
Write: FOR UPDATE
Examples:
SELECT "DocName", "Total" FROM lck."DocHeader" WHERE "DocName"='N1' FOR SHARE
SELECT "DocName", "Total" FROM lck."DocHeader" WHERE "DocName"='N1' FOR UPDATE
Oracle
Transaction Isolation Level
Read: Serializable
Write: ReadCommitted
SQL clauses
Read: (none)
Write: FOR UPDATE
Examples:
SELECT DocName, Total FROM DocHeader WHERE DocName='N1' FOR UPDATE
Note: Oracle uses data row versioning, so consistent reads with Serializable isolation level do not need any extra hints in SQL.
MS SQL Server
Database-wide settings
ALLOW_SNAPSHOT_ISOLATION = ON
READ_COMMITTED_SNAPSHOT = ON
Transaction Isolation Level
Read: Snapshot
Write: ReadCommitted
SQL hints:
Write: WITH(UpdLock)
Example:
SELECT "DocName", "Total" FROM lck."DocHeader" WITH(UpdLock) WHERE "DocName"='N1'
MS SQL Server is quite a special case - it requires some database-level settings. You need to enable Snapshot isolation level for the database. Roughly speaking, the Snapshot mode means 'enable row versioning mode': when an update is in progress, the server keeps several versions of the data row, one for each update process plus original version. Each process is presented with its own 'current' version. This approach is quite similar to what PostgreSql and Oracle are doing by default. With snapshot isolation you do not need any clauses/hints for read operations - only UpdLock hint for writes.
Rant: the troubling case of MS SQL Server
At first look the case of MS SQL Server does not seem much different from other servers - just two extra database-wide settings, not a big deal. The problem is not the pattern per se, but the fact that it is quite difficult to figure out. The solution for MS SQL above is NOT readily available in any MSDN article, server documentation page, or even third-party post - at least I could not find it, and I spent quite a lot of time looking. What you find is endless explanations of isolation levels, internal locks and intricate details of SQL server internals - which make you head explode, but do not really get you close to the solution. I did read many of these articles end-to-end, but still could not figure out how to make my little case to work. That was really shocking for me.
First, my own experience with several server types, MS SQL was always the most developer-friendly - it is usually 'other' servers that require extra work. Secondly, the case in point is not some very specific extreme and once in a lifetime scenario - it is a very basic, fundamental case which MUST be implemented if your app is dealing with important financial or legal data. So it should be in place at thousands web sites there, given the popularity of MS SQL and .NET platform in the business app world. But surprisingly - no ready-to-use advice.
I described my problem at T-SQL forum at official Microsoft site. Very quickly two experts (MVPs) responded, and we started working on it together. Surprisingly, again, they did not come up with solution right a way. It took several try/fail attempts, analysing transaction logs, over 2 days to finally figure it out. In no way I am questioning their expertise (of MVPs that helped me) , no! They ARE experts, but it took them more than one guess to find the solution.
It is really disturbing. I think there are thousands of websites out there running on MS SQL Server and handling critical information, and their owners - seasoned developers I am sure - might be thinking they are handling concurrency right. And it might not the case for many of them.
It takes a specially written test app, serious investment of time and effort, to test and confirm (?!), or discover that concurrency handling is not right.
What might be the solution for MS SQL world, other than writing an article like this one? One way to go for Microsoft is to finally (!) implement (standard?) SQL clauses for shared/read/write locks like PostgreSql or MySql (not MS SQL-specific table hints!), to make implementation straightforward and out-of-the-box, just like in 'other' servers (which are by the way more SQL standards compliant in many cases). What to do with snapshot isolation setting that must be enabled upfront? Throw an error if the code tries to use 'FOR UPDATE' locking clause without this option enabled, clearly explaining the extra steps to do to use this feature. The argument that it is already there, just implemented with hints, and explained in docs - no, it is not - my own experience says otherwise.
The other troubling point for me is that all you can find googling for concurrency in relation to ADO.NET and Entity Framewok is articles about Optimistic Concurrency (see section below), and you get the impression that there's nothing else to talk about in concurrency management! Really?...
In my humble opinion, Microsoft should do something about this.
Database locks and ORMs
Object-Relational Mapping (ORM) frameworks are commonly used to access databases from middle tier components. All real apps working with databases use ORMs, even if it is home-build light-weight ORM.
As for concurrency supports, it should be clear now that any real ORM, being the bridge to the database, must support the document-level locking. To the best of my knowledge, the ONLY ORM today that directly supports these locks is
VITA - a full-featured .NET ORM Framework.
Yes, I am the developer of this ORM - you guessed it right, and it does support multiple servers: MS SQL Server, Postgres, MySql and SQLite; Oracle is coming. VITA is more than just ORM - it is application framework, it does many more things like integration with Web API stack, pre-built modules for pieces of functionality like Login, logging of all kinds, advanced web clients, etc.
That actually explains how this article came to be. Some time ago the concurrency support work item finally made it to the top of my to-do list, and I started researching the subject. I wrote the unit test, similar to the code for this article (30 threads beating 5 docs), and it took no time to make it work for Postgres and MySql. But for MS SQL server - that's where the trouble started. Quite shocking, in all years of working with these 3 servers, the MS SQL was always the easiest one. Not this time. The rest of the story you already know. Finally, after implementing all this locking in VITA, I decided to share the findings, and wrote a test app that does not rely on VITA for data access to different servers, just to make a clear case with no dependencies, no obscure framework code underneath.
Optimistic concurrency - how it relates to this?
Optimistic concurrency is a popular pattern for managing concurrent access to server documents by multiple users. If you use it, you might be wondering - how it relates to the issues discussed in this article? If I use optimistic concurrency - does this mean I am already OK, or I still need all this locking stuff? The answer is yes, you still need it; optimistic concurrency is for different type of 'concurrency', and you might still hit deadlocks and inconsistent reads, even if you have optimistic stuff done correctly.
Let's quickly refresh what is optimistic concurrency pattern. Each document has a timestamp (or row version), that uniquely identifies the version of the document; with each update the timestamp changes. When user intends to modify the document, it loads it from the server, and the server sends the timestamp/version value along with the document. When the user finishes the changes and submits the new version, the server checks the current timestamp of the document in the database with the version received with the changes. If it is different, it means that somebody else has already updated the document while the user was changing it on the client. In most cases it results in error sent back to the user: "Sorry, document was updated". The server rejects the update because it might be unsafe to update with values made over already stale version. The app suggests to refresh the doc, look at it again, make changes and resubmit.
It should be clear that the optimistic concurrency is for handling concurrent users trying to update the document they loaded probably seconds or even minutes ago. The timespans of collisions is therefore seconds/minutes. For the concurrency that is the main subject of this article the timespan is milliseconds, for different concurrent processes executing on the server. Another point: if your document consists of a single record, you still have the reason to use optimistic concurrency, but not the locks we describe in this article. So the scope and range differences should be quite clear, and you still need locks even with optimistic pattern.
Let's illustrate with a hypothetical example. With optimistic concurrency implemented on the website (but no locks), imagine two users starting to edit the same document, around the same time. After finishing modifications, let's say they hit "Submit" button at exactly the same time. Two POST requests arrive at one or two separate web servers at the same moment, and two update processes start executing. Both processes perform concurrency check (compare version in database with version received from the client), both checks succeed - there were no completed updates in the middle. Then both processes try to make actual updates, and you get into all the troubles - deadlocks, invalid state of the doc, etc. Imagine also the third user loading the doc right at the time when an update is in progress - it will likely get a document in the middle of update, possibly internally inconsistent snapshot.
And what troubles me here is that all of the articles explaining optimistic concurrency implementation (and especially about its support in Entity Framework) - all these articles end up giving you impression that it's basically all you need to know about handling concurrency in your application. Sounds familiar?
Tale of two clicks
I want to share an interesting story, showing that locks might be useful even in a single-user scenario. I admit, I always thought that you need locks only when you have multiple users that can eventually edit the same document. It turned out that even with a single user there are cases when locks are the right solution.
We have a Web application, and we sometimes ask users to take a survey - a bunch of questions. We record answers in a simple table: (UserId, QuestionKey, Answer). There is a unique key on (UserId, QuestionKey) pair - only one answer per user per question. Users can scroll back to previous questions and change their answers, so saving an answer might be an insert (if record does not exist), or an update - if it does.
So we went to testing the prototype of the app (without locks, it wasn't there yet), and suddenly started seeing strange errors on the server. Submits were failing occasionally with 'unique index violation' error. Web call log clearly showed that in each case there were two identical submits, from the same client/machine, few milliseconds apart. Users were occasionally making double-clicks! (On touch devices like iPad touches often result in doubles or even multiple clicks). The rest is clear: after double-click the two requests arrive at the web server almost at the same time, both try to lookup the existing answer, do not find it, and then both try to insert a new name/value. The first wins and goes OK, while the second results in unique constraint violation.
Obvious fix - disable the button once it is clicked (instead of just waiting for new question shown). We tried it, errors became less frequent, but were still happening. The reason is that the UI is controlled by a client-side framework, and things like enable/disable are done through manipulating button styles, indirectly - through some element/attribute bindings to data (Angular!). So it takes some time to propagate the Disabled status and actually disable the button, and double-clicks do go through occasionally (that's my guess).
Rather than continuing to fight the issue on the client side, we opted for a fix on the server - by using server-side lock on the 'document'. We treat survey answers as a compound document, and require locking the header before you start adding the answer. The doubled submissions become serialized on the server, so the first in inserts while the second make a moot update of the same record. Problem solved.
In general, no client behavior, no matter how bad, even malicious, scripted by evil hacker, should cause the server to crash or fail, producing server-side error, period. This is solved by using document locks on the server.
Points of Interest
An interesting blog post about some extra locks and possible surprises in MS SQL Server because of foreign keys:
http://www.sqlnotes.info/2012/06/26/locking-behavior-fks/. Turns out you can get deadlock even when 2 processes update non-intersecting sets of records! With the described locking here I believe we have this situation covered, because we always lock the header, even if we plan to modify only the child record(s).
History
2016/08/24 - First version

