In a previous post, I looked at how you can use BenchmarkDotNet to help diagnose why one benchmark is running slower than another. The post outlined how ETW Events are used to give you an accurate measurement of the # of Bytes allocated and the # of GC Collections per benchmark.
Inlining
In addition to memory allocation, BenchmarkDotNet can also give you information about which methods were inlined by the JITter. Inlining is the process by which code is copied from one function (the inlinee) directly into the body of another function (the inliner). The reason for this is to save the overhead of a method call and the associated work that needs to be done when control is passed from one method to another.
To see this in action, we are going to run the following benchmark:
[Benchmark]
public int Calc()
{
return WithoutStarg(0x11) + WithStarg(0x12);
}
private static int WithoutStarg(int value)
{
return value;
}
private static int WithStarg(int value)
{
if (value < 0)
value = -value;
return value;
}
BenchmarkDotNet also gives you the ability to run Benchmarks against different versions of the .NET JITter and on various CPU Platforms. So, this test will ask it to run against the following configurations:
- Legacy JIT - x86
- Legacy JIT - x64
Once this is all set-up, we can run the benchmark and we get the following results:
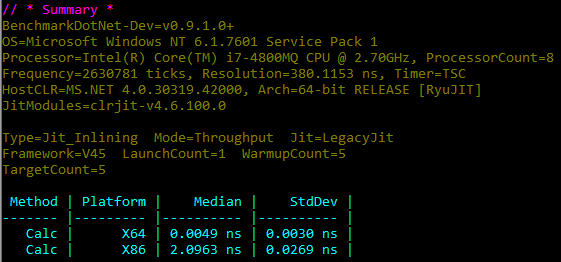
The interesting thing to note is that Legacy JIT - x64 runs significantly faster than the x86 version, even though they are both running the same C# code (from the Calc() function above).
So now we are going to ask BenchmarkDotNet to give us the JIT inlining diagnostics. These diagnostics are available via ETW Events and are collected, parsed and displayed at the end of the output, as shown below:

Here, we can see that when the x64 JITter runs, the WithStarg() function is successfully inlined into the Calc() function, whereas with x86 version, it is not. So the same code is being executed, but because the WithStarg() function is relatively simple, when it is not inlined the cost of the method call dominates and causes the Calc() function to take more time. For a comparison, the WithoutStarg() function is always inlined, because it doesn’t do anything with the value that is passed into it.
For a full-explanation of why there is a difference in behaviour between the 2 versions of the JITter, I recommend reading Andrey Akinhin’s blog post on the subject. But in summary, the x64 version is more efficient and it’s a bug/regression that the x86 version doesn’t have the same behaviour.
.NET JIT Inlining Rules
In this case, the specific reason that the Legacy JIT - x86 gives for not inlining the WithStarg() method is:
Fail Reason: Inlinee writes to an argument.
For reference, there is a comprehensive list of JIT ETW Inlining Event Fail Reasons available on MSDN, although interestingly enough, it doesn’t include this reason!
However, inlining isn’t always a win-win scenario. Because you are copying the same code to 2 locations, it can bloat the amount of memory that your programs needs.
Update: A more recent list of justifications that the .NET JITter provides for not inlining a method is available, thanks to Andy Ayers from Microsoft for pointing it out to me.
So there are some rules that the .NET JITter follows when deciding whether or not to inline a method (Note this list is from 2004, so the rules may well have changed since then.)
These are some of the reasons for which we won’t inline a method:
-
Method is marked as not inline with the CompilerServices.MethodImpl attribute.
-
Size of inlinee is limited to 32 bytes of IL: This is a heuristic, the rationale behind it is that usually, when you have methods bigger than that, the overhead of the call will not be as significative compared to the work the method does. Of course, as a heuristic, it fails in some situations. There have been suggestions for us adding an attribute to control these threshold. For Whidbey, that attribute has not been added (it has some very bad properties: it’s x86 JIT specific and it’s longterm value, as compilers get smarter, is dubious).
-
Virtual calls: We don’t inline across virtual calls. The reason for not doing this is that we don’t know the final target of the call. We could potentially do better here (for example, if 99% of calls end up in the same target, you can generate code that does a check on the method table of the object the virtual call is going to execute on, if it’s not the 99% case, you do a call, else you just execute the inlined code), but unlike the J language, most of the calls in the primary languages we support, are not virtual, so we’re not forced to be so aggressive about optimizing this case.
-
Valuetypes: We have several limitations regarding value types an inlining. We take the blame here, this is a limitation of our JIT, we could do better and we know it. Unfortunately, when stack ranked against other features of Whidbey, getting some statistics on how frequently methods cannot be inlined due to this reason and considering the cost of making this area of the JIT significantly better, we decided that it made more sense for our customers to spend our time working in other optimizations or CLR features. Whidbey is better than previous versions in one case: value types that only have a pointer size int as a member, this was (relatively) not expensive to make better, and helped a lot in common value types such as pointer wrappers (IntPtr, etc).
-
MarshalByRef: Call targets that are in MarshalByRef classes won’t be inlined (call has to be intercepted and dispatched). We’ve got better in Whidbey for this scenario.
-
VM restrictions: These are mostly security, the JIT must ask the VM for permission to inline a method (see CEEInfo::canInline in Rotor source to get an idea of what kind of things the VM checks for).
-
Complicated flowgraph: We don’t inline loops, methods with exception handling regions, etc…
-
If basic block that has the call is deemed as it won’t execute frequently (for example, a basic block that has a throw, or a static class constructor), inlining is much less aggressive (as the only real win we can make is code size)
-
Other: Exotic IL instructions, security checks that need a method frame, etc.
Summary
So we can see that BenchmarkDotNet will display multiple pieces of information that allow you to diagnose why your benchmarks take the time they do:
- Amount of Bytes allocated per Benchmark
- Number of GC Collections triggered (Gen 0/1/2)
- Whether a method was inlined or not
The post Adventures in Benchmarking - Method Inlining first appeared on my blog Performance is a Feature!
CodeProject

