Last time we look at remoting. You can kind of think of clustering as an extension to remoting, as some of the same underlying parts are used. But as we will see clustering is way more powerful (and more fault tolerant too).
My hope is by the end of this post that you will know enough about Akka clustering that you would be able to create your own clustered Akka apps.
A Note About All The Demos In This Topic
I wanted the demos in this section to be as close to real life as possible. The official akka examples tend to have a single process. Which I personally think is quite confusing when you are trying to deal with quite hard concepts. As such I decided to go with multi process projects to demonstrate things. I do however only have 1 laptop, so they are hosted on the same node, but they are separate processes/JVMs.
I am hoping by doing this it will make the learning process easier, as it is closer to what you would do in real life rather than have 1 main method that spawns an entire cluster. You just would not have that in real life.
What Is Akka Clustering?
Unlike remoting which is peer to peer, a cluster may constitute many members, which can grow and contract depending on demand/failure. There is also the concept of roles for actors with a cluster, which this post will talk about.
You can see how this could be very useful, in fact you could see how this may be used to create a general purpose grid calculation engine such as Apache Spark.
Seed Nodes
Akka has the concept of some initial contact points within the cluster to allow the cluster to bootstrap itself as it were.
Here is what the official Akka docs say on this:
You may decide if joining to the cluster should be done manually or automatically to configured initial contact points, so-called seed nodes. When a new node is started it sends a message to all seed nodes and then sends join command to the one that answers first. If no one of the seed nodes replied (might not be started yet) it retries this procedure until successful or shutdown.
You may choose to configure these “seed nodes” in code, but the easiest way is via configuration. The relevant part of the demo apps configuration is here
akka {
.....
.....
cluster {
seed-nodes = [
"akka.tcp://ClusterSystem@127.0.0.1:2551",
"akka.tcp://ClusterSystem@127.0.0.1:2552"]
}
.....
.....
]
The seed nodes can be started in any order and it is not necessary to have all seed nodes running, but the node configured as the first element in the seed-nodes configuration list must be started when initially starting a cluster, otherwise the other seed-nodes will not become initialized and no other node can join the cluster. The reason for the special first seed node is to avoid forming separated islands when starting from an empty cluster. It is quickest to start all configured seed nodes at the same time (order doesn’t matter), otherwise it can take up to the configured seed-node-timeout until the nodes can join.
Once more than two seed nodes have been started it is no problem to shut down the first seed node. If the first seed node is restarted, it will first try to join the other seed nodes in the existing cluster.
We will see the entire configuration for the demo app later on this post. For now just be aware that there is a concept of seed nodes and the best way to configure those for the cluster is via configuration.
Saying that there may be some amongst you that would prefer to use the JVM property system which you may do as follows:
-Dakka.cluster.seed-nodes.0=akka.tcp:
-Dakka.cluster.seed-nodes.1=akka.tcp:
Roles
Akka clustering comes with the concept of roles.You may be asking why would we need that?
Well its quite simple really, say we have a higher than normal volume of data coming through you akka cluster system, you may want to increase the total processing power of the cluster to deal with this. How do we do that, we spin up more actors within a particular role. The role here may be “backend” that do work designated to them by some other actor say “frontend” role.
By using roles we can manage which bits of the cluster get dynamically allocated more/less actors.
You can configure the minimum number of role actor in configuration, which you can read more about here:
http://doc.akka.io/docs/akka/snapshot/java/cluster-usage.html#How_To_Startup_when_Cluster_Size_Reached
Member Events
Akka provides the ability to listen to member events. There are a number of reasons this could be useful, for example
- Determining if a member has left the cluster
- If a new member has joined the cluster
Here is a full list of the me Cluster events that you may choose to listen to
The events to track the life-cycle of members are:
ClusterEvent.MemberJoined – A new member has joined the cluster and its status has been changed to Joining.ClusterEvent.MemberUp – A new member has joined the cluster and its status has been changed to Up.ClusterEvent.MemberExited – A member is leaving the cluster and its status has been changed to Exiting Note that the node might already have been shutdown when this event is published on another node.ClusterEvent.MemberRemoved – Member completely removed from the cluster.ClusterEvent.UnreachableMember – A member is considered as unreachable, detected by the failure detector of at least one other node.ClusterEvent.ReachableMember – A member is considered as reachable again, after having been unreachable. All nodes that previously detected it as unreachable has detected it as reachable again.
And this is how you might subscribe to these events
cluster.subscribe(self, classOf[MemberUp])
Which you may use in an actor like this:
class SomeActor extends Actor {
val cluster = Cluster(context.system)
override def preStart(): Unit = cluster.subscribe(self, classOf[MemberUp])
def receive = {
case MemberUp(m) => register(m)
}
def register(member: Member): Unit =
if (member.hasRole("frontend"))
...
}
We will see more on this within the demo code which we will walk through later
ClusterClient
What use is a cluster which cant receive commands from the outside world?
Well luckily we don’t have to care about that as Akka comes with 2 things that make this otherwise glib situation ok.
Akka comes with a ClusterClient which allows actors which are not part of the cluster to talk to the cluster. Here is what the offical Akka docs have to say about this
An actor system that is not part of the cluster can communicate with actors somewhere in the cluster via this ClusterClient. The client can of course be part of another cluster. It only needs to know the location of one (or more) nodes to use as initial contact points. It will establish a connection to a ClusterReceptionist somewhere in the cluster. It will monitor the connection to the receptionist and establish a new connection if the link goes down. When looking for a new receptionist it uses fresh contact points retrieved from previous establishment, or periodically refreshed contacts, i.e. not necessarily the initial contact points.
Receptionist
As mentioned above the ClusterClient makes use of a ClusterReceptionist, but what is that, and how do we make a cluster actor available to the client using that?
The ClusterReceptionist is an Akka contrib extension, and must be configured on ALL the nodes that the ClusterClient will need to talk to.
There are 2 parts this, firstly we must ensure that the ClusterReceptionist is started on the nodes that ClusterClient will need to communicate with. This is easily done using the following config:
akka {
....
....
....
# enable receptionist at start
extensions = ["akka.cluster.client.ClusterClientReceptionist"]
}
The other thing that needs doing, is that any actor within the cluster that you want to be able to talk to using the ClusterClient will need to register itself as a service with the ClusterClientReceptionist. Here is an example of how to do that
val system = ActorSystem("ClusterSystem", config)
val frontend = system.actorOf(Props[TransformationFrontend], name = "frontend")
ClusterClientReceptionist(system).registerService(frontend)
Now that you have done that you should be able to communicate with this actor within the cluster using the ClusterClient
The Demo Dissection
I have based the demo for this post largely against the “Transformation” demo that LightBend provide, which you can grab from here :
http://www.lightbend.com/activator/template/akka-sample-cluster-scala
The “Official” example as it is, provides a cluster which contains “frontend” and “backend” roles. The “frontend” actors will take a text message and pass it to the register workers (“Backend”s) who will UPPERCASE the message and return to the “frontend”.
I have taken this sample and added the ability to use the ClusterClient with it, which works using Future[T] and the ask pattern, such that the ClusterClient will get a response from the cluster request.
We will dive into all of this in just a moment
For the demo this is what we are trying to build
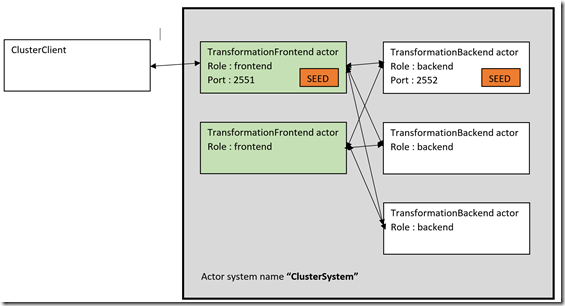
SBT / Dependencies
Before we dive into the demo code (which as I say is based largely on the official lightbend clustering example anyway) I would just like to dive into the SBT file that drives the demo projects
This is the complete SBT file for the entire demo
import sbt._
import sbt.Keys._
lazy val allResolvers = Seq(
"Typesafe Repository" at "http://repo.typesafe.com/typesafe/releases/",
"Akka Snapshot Repository" at "http://repo.akka.io/snapshots/"
)
lazy val AllLibraryDependencies =
Seq(
"com.typesafe.akka" %% "akka-actor" % "2.4.8",
"com.typesafe.akka" %% "akka-remote" % "2.4.8",
"com.typesafe.akka" %% "akka-cluster" % "2.4.8",
"com.typesafe.akka" %% "akka-cluster-tools" % "2.4.8",
"com.typesafe.akka" %% "akka-contrib" % "2.4.8"
)
lazy val commonSettings = Seq(
version := "1.0",
scalaVersion := "2.11.8",
resolvers := allResolvers,
libraryDependencies := AllLibraryDependencies
)
lazy val root =(project in file(".")).
settings(commonSettings: _*).
settings(
name := "Base"
)
.aggregate(common, frontend, backend)
.dependsOn(common, frontend, backend)
lazy val common = (project in file("common")).
settings(commonSettings: _*).
settings(
name := "common"
)
lazy val frontend = (project in file("frontend")).
settings(commonSettings: _*).
settings(
name := "frontend"
)
.aggregate(common)
.dependsOn(common)
lazy val backend = (project in file("backend")).
settings(commonSettings: _*).
settings(
name := "backend"
)
.aggregate(common)
.dependsOn(common)
There are a few things to note in this
- We need a few dependencies to get clustering to work. Namely
- akka-remote
- akka-cluster
- akka-cluster-tools
- akka-contrib
- There are a few projects
- root : The cluster client portion
- common : common files
- frontend : frontend cluster based actors (the client will talk to these)
- backend : backend cluster based actors
The Projects
Now that we have seen the projects involved from an SBT point of view, lets continue to look at how the actual projects perform their duties
Remember the workflow we are trying to achieve is something like this
- We should ensure that a frontend (seed node) is started first
- We should ensure a backend (seed node) is started. This will have the effect of the backend actor registering itself as a worker with the already running frontend actor
- At this point we could start more frontend/backend non seed nodes actors, if we chose to
- We start the client app (root) which will periodically send messages to the frontend actor that is looked up by its known seed node information. We would expect the frontend actor to delegate work of to one of its known backend actors, and then send the response back to the client (
ClusterClient) where we can use the response to send to a local actor, or consume the response directly
Common
The common project simply contains the common objects across the other projects. Which for this demo app are just the messages as shown below
package sample.cluster.transformation
final case class TransformationJob(text: String)
final case class TransformationResult(text: String)
final case class JobFailed(reason: String, job: TransformationJob)
case object BackendRegistration
Root
This is the client app that will talk to the cluster (in particular the “frontend” seed node which expected to be running on 127.0.0.1:2551.
This client app uses the following configuration file
akka {
actor {
provider = "akka.cluster.ClusterActorRefProvider"
}
remote {
transport = "akka.remote.netty.NettyRemoteTransport"
log-remote-lifecycle-events = off
netty.tcp {
hostname = "127.0.0.1"
port = 5000
}
}
}
We then use the following main method to kick of the client app
import java.util.concurrent.atomic.AtomicInteger
import akka.actor.{Props, ActorSystem}
import akka.util.Timeout
import scala.io.StdIn
import scala.concurrent.duration._
object DemoClient {
def main(args : Array[String]) {
val system = ActorSystem("OTHERSYSTEM")
val clientJobTransformationSendingActor =
system.actorOf(Props[ClientJobTransformationSendingActor],
name = "clientJobTransformationSendingActor")
val counter = new AtomicInteger
import system.dispatcher
system.scheduler.schedule(2.seconds, 2.seconds) {
clientJobTransformationSendingActor ! Send(counter.incrementAndGet())
Thread.sleep(1000)
}
StdIn.readLine()
system.terminate()
}
}
There is not too much to talk about here, we simply create a standard actor, and send it messages on a recurring schedule.
The message looks like this
case class Send(count:Int)
The real work of talking to the cluster is inside the ClientJobTransformationSendingActor which we will look at now
import akka.actor.Actor
import akka.actor.ActorPath
import akka.cluster.client.{ClusterClientSettings, ClusterClient}
import akka.pattern.Patterns
import sample.cluster.transformation.{TransformationResult, TransformationJob}
import akka.util.Timeout
import scala.concurrent.duration._
import scala.concurrent.ExecutionContext.Implicits.global
import scala.util.{Failure, Success}
class ClientJobTransformationSendingActor extends Actor {
val initialContacts = Set(
ActorPath.fromString("akka.tcp://ClusterSystem@127.0.0.1:2551/system/receptionist"))
val settings = ClusterClientSettings(context.system)
.withInitialContacts(initialContacts)
val c = context.system.actorOf(ClusterClient.props(settings), "demo-client")
def receive = {
case TransformationResult(result) => {
println("Client response")
println(result)
}
case Send(counter) => {
val job = TransformationJob("hello-" + counter)
implicit val timeout = Timeout(5 seconds)
val result = Patterns.ask(c,ClusterClient.Send("/user/frontend", job, localAffinity = true), timeout)
result.onComplete {
case Success(transformationResult) => {
println(s"Client saw result: $transformationResult")
self ! transformationResult
}
case Failure(t) => println("An error has occured: " + t.getMessage)
}
}
}
}
As you can see this is a regular actor, but there are several important things to note here:
- We setup the
ClusterClient with a known set of seed nodes that we can expect to be able to contact within the cluster (remember these nodes MUST have registered themselves as available services with the ClusterClientReceptionist - That we use a new type of actor a
ClusterClient - That we use the
ClusterClient to send a message to a seed node within the cluster (frontend) in our case. We use the ask pattern which will give use a Future[T] which represents the response. - We use the response to send a local message to ourself
FrontEnd
As previously stated the “frontend” role actors serve as the seed nodes for the ClusterClient. There is only one seed node for the frontend which we just saw the client app uses via the ClusterClient.
So what happens when the client app uses the frontend actors via the ClusterClient, well its quite simple the client app (once a connection is made to the frontend seed node) send a simple TransformationJob which is a simple message that contains a bit of text that the frontend actor will pass on to one of its registered backend workers for processing.
The backend actor (also in the cluster) will simply convert the TransformationJob contained text to UPPERCASE and return it to the frontend actor. The frontend actor will then send this TransformationResult back to the sender which happens to be the ClusterClient. The client app will listen to this (which was done using the ask pattern) and will hook up a callback for the Future[T] and will the send the TransformationResult to the clients own actor.
Happy days.
So that is what we are trying to achieve, lets see what bits and bobs we need for the frontend side of things
Here is the configuration the frontend needs
#
akka {
actor {
provider = "akka.cluster.ClusterActorRefProvider"
}
remote {
log-remote-lifecycle-events = off
netty.tcp {
hostname = "127.0.0.1"
port = 0
}
}
cluster {
seed-nodes = [
"akka.tcp://ClusterSystem@127.0.0.1:2551",
"akka.tcp://ClusterSystem@127.0.0.1:2552"]
#
# excluded from snippet
auto-down-unreachable-after = 10s
#
# auto downing is NOT safe for production deployments.
# you may want to use it during development, read more about it in the docs.
#
# auto-down-unreachable-after = 10s
}
# enable receptionist at start
extensions = ["akka.cluster.client.ClusterClientReceptionist"]
}
There are a couple of important things to note in this, namely:
- That we configure the seed nodes
- That we also use add the
ClusterClientReceptionist - That we use the
ClusterActorRefProvider
And here is the frontend application
package sample.cluster.transformation.frontend
import language.postfixOps
import akka.actor.ActorSystem
import akka.actor.Props
import com.typesafe.config.ConfigFactory
import akka.cluster.client.ClusterClientReceptionist
object TransformationFrontendApp {
def main(args: Array[String]): Unit = {
val port = if (args.isEmpty) "0" else args(0)
val config = ConfigFactory.parseString(s"akka.remote.netty.tcp.port=$port").
withFallback(ConfigFactory.parseString("akka.cluster.roles = [frontend]")).
withFallback(ConfigFactory.load())
val system = ActorSystem("ClusterSystem", config)
val frontend = system.actorOf(Props[TransformationFrontend], name = "frontend")
ClusterClientReceptionist(system).registerService(frontend)
}
}
The important parts here are that we embellish the read config with the role of “frontend”, and that we also register the frontend actor with the ClusterClientReceptionist such that the actor is available to communicate with by the ClusterClient
Other than that it is all pretty vanilla akka to be honest
So lets now focus our attention to the actual frontend actor, which is shown below
package sample.cluster.transformation.frontend
import sample.cluster.transformation.{TransformationResult, BackendRegistration, JobFailed, TransformationJob}
import language.postfixOps
import scala.concurrent.Future
import akka.actor.Actor
import akka.actor.ActorRef
import akka.actor.Terminated
import akka.util.Timeout
import scala.concurrent.duration._
import scala.concurrent.ExecutionContext.Implicits.global
import akka.pattern.pipe
import akka.pattern.ask
class TransformationFrontend extends Actor {
var backends = IndexedSeq.empty[ActorRef]
var jobCounter = 0
def receive = {
case job: TransformationJob if backends.isEmpty =>
sender() ! JobFailed("Service unavailable, try again later", job)
case job: TransformationJob =>
println(s"Frontend saw TransformationJob : '$job'")
jobCounter += 1
implicit val timeout = Timeout(5 seconds)
val result = (backends(jobCounter % backends.size) ? job)
.map(x => x.asInstanceOf[TransformationResult])
result pipeTo sender
case BackendRegistration if !backends.contains(sender()) =>
context watch sender()
backends = backends :+ sender()
case Terminated(a) =>
backends = backends.filterNot(_ == a)
}
}
The crucial parts here are:
- That when a backend registers it will send a
BackendRegistration, which we then watch and monitor, and if that backend terminates it is removed from the list of this frontend actors known backend actors - That we palm off the incoming
TransformationJob to a random backend, and then use the pipe pattern to pipe the response back to the client
And with that, all that is left to do is examine the backend code, lets looks at that now
BackEnd
As always lets start with the configuration, which for the backend is as follows:
#
akka {
actor {
provider = "akka.cluster.ClusterActorRefProvider"
}
remote {
log-remote-lifecycle-events = off
netty.tcp {
hostname = "127.0.0.1"
port = 0
}
}
cluster {
seed-nodes = [
"akka.tcp://ClusterSystem@127.0.0.1:2551",
"akka.tcp://ClusterSystem@127.0.0.1:2552"]
#
# excluded from snippet
auto-down-unreachable-after = 10s
#
# auto downing is NOT safe for production deployments.
# you may want to use it during development, read more about it in the docs.
#
# auto-down-unreachable-after = 10s
}
# enable receptionist at start
extensions = ["akka.cluster.client.ClusterClientReceptionist"]
}
You can see this is pretty much the same as the frontend, so I won’t speak to this anymore.
Ok so following what we did with the frontend side of things, lets now look at the backend app
package sample.cluster.transformation.backend
import language.postfixOps
import scala.concurrent.duration._
import akka.actor.ActorSystem
import akka.actor.Props
import com.typesafe.config.ConfigFactory
object TransformationBackendApp {
def main(args: Array[String]): Unit = {
val port = if (args.isEmpty) "0" else args(0)
val config = ConfigFactory.parseString(s"akka.remote.netty.tcp.port=$port").
withFallback(ConfigFactory.parseString("akka.cluster.roles = [backend]")).
withFallback(ConfigFactory.load())
val system = ActorSystem("ClusterSystem", config)
system.actorOf(Props[TransformationBackend], name = "backend")
}
}
Again this is VERY similar to the front end app, the only notable exception being that we now use a “backend” role instead of a “frontend” one
So now lets look at the backend actor code, which is the final piece of the puzzle
package sample.cluster.transformation.backend
import sample.cluster.transformation.{BackendRegistration, TransformationResult, TransformationJob}
import language.postfixOps
import scala.concurrent.duration._
import akka.actor.Actor
import akka.actor.RootActorPath
import akka.cluster.Cluster
import akka.cluster.ClusterEvent.CurrentClusterState
import akka.cluster.ClusterEvent.MemberUp
import akka.cluster.Member
import akka.cluster.MemberStatus
class TransformationBackend extends Actor {
val cluster = Cluster(context.system)
override def preStart(): Unit = cluster.subscribe(self, classOf[MemberUp])
override def postStop(): Unit = cluster.unsubscribe(self)
def receive = {
case TransformationJob(text) => {
val result = text.toUpperCase
println(s"Backend has transformed the incoming job text of '$text' into '$result'")
sender() ! TransformationResult(text.toUpperCase)
}
case state: CurrentClusterState =>
state.members.filter(_.status == MemberStatus.Up) foreach register
case MemberUp(m) => register(m)
}
def register(member: Member): Unit =
if (member.hasRole("frontend"))
context.actorSelection(RootActorPath(member.address) / "user" / "frontend") !
BackendRegistration
}
The key points here are:
- That we use the cluster events, to subscribe to
MemberUp such that if its “frontend” role actor, we will register this backend with it by sending a BackendRegistration message to it - That for any
TrasformationJob received (from the frontend which is ultimately for the client app) we do the work, and send a TransformationResult back, which will make its way all the way back to the client
And in a nutshell that is how the entire demo hangs together. I hope I have not lost anyone along the way.
Anyway lets now see how we can run the demo
How do I Run The Demo
You will need to ensure that you run the following 3 projects in this order (as a minimum. You can run more NON seed node frontend/backend versions before you start the root (client) if you like)
- Frontend (seed node) : frontend with command line args : 2551
- Backend (seed node) : backend with command line args : 2551
- Optionally run more frontend/backend projects but DON’T supply any command line args. This is how you get them to not be treated as seed nodes
- Root : This is the client app
Once you run the projects you should see some output like
The “root” (client) project output:
[INFO] [10/05/2016 07:22:02.831] [main] [akka.remote.Remoting] Starting remoting
[INFO] [10/05/2016 07:22:03.302] [main] [akka.remote.Remoting] Remoting started; listening on addresses :[akka.tcp://OTHERSYSTEM@127.0.0.1:5000]
[INFO] [10/05/2016 07:22:03.322] [main] [akka.cluster.Cluster(akka://OTHERSYSTEM)] Cluster Node [akka.tcp://OTHERSYSTEM@127.0.0.1:5000] – Starting up…
[INFO] [10/05/2016 07:22:03.450] [main] [akka.cluster.Cluster(akka://OTHERSYSTEM)] Cluster Node [akka.tcp://OTHERSYSTEM@127.0.0.1:5000] – Registered cluster JMX MBean [akka:type=Cluster]
[INFO] [10/05/2016 07:22:03.450] [main] [akka.cluster.Cluster(akka://OTHERSYSTEM)] Cluster Node [akka.tcp://OTHERSYSTEM@127.0.0.1:5000] – Started up successfully
[INFO] [10/05/2016 07:22:03.463] [OTHERSYSTEM-akka.actor.default-dispatcher-2] [akka.cluster.Cluster(akka://OTHERSYSTEM)] Cluster Node [akka.tcp://OTHERSYSTEM@127.0.0.1:5000] – Metrics will be retreived from MBeans, and may be incorrect on some platforms. To increase metric accuracy add the ‘sigar.jar’ to the classpath and the appropriate platform-specific native libary to ‘java.library.path’. Reason: java.lang.ClassNotFoundException: org.hyperic.sigar.Sigar
[INFO] [10/05/2016 07:22:03.493] [OTHERSYSTEM-akka.actor.default-dispatcher-2] [akka.cluster.Cluster(akka://OTHERSYSTEM)] Cluster Node [akka.tcp://OTHERSYSTEM@127.0.0.1:5000] – Metrics collection has started successfully
[WARN] [10/05/2016 07:22:03.772] [OTHERSYSTEM-akka.actor.default-dispatcher-19] [akka.tcp://OTHERSYSTEM@127.0.0.1:5000/system/cluster/core/daemon] Trying to join member with wrong ActorSystem name, but was ignored, expected [OTHERSYSTEM] but was [ClusterSystem]
[INFO] [10/05/2016 07:22:03.811] [OTHERSYSTEM-akka.actor.default-dispatcher-19] [akka.tcp://OTHERSYSTEM@127.0.0.1:5000/user/demo-client] Connected to [akka.tcp://ClusterSystem@127.0.0.1:2552/system/receptionist]
[WARN] [10/05/2016 07:22:05.581] [OTHERSYSTEM-akka.remote.default-remote-dispatcher-14] [akka.serialization.Serialization(akka://OTHERSYSTEM)] Using the default Java serializer for class [sample.cluster.transformation.TransformationJob] which is not recommended because of performance implications. Use another serializer or disable this warning using the setting ‘akka.actor.warn-about-java-serializer-usage’
Client saw result: TransformationResult(HELLO-1)
Client response
HELLO-1
Client saw result: TransformationResult(HELLO-2)
Client response
HELLO-2
Client saw result: TransformationResult(HELLO-3)
Client response
HELLO-3
Client saw result: TransformationResult(HELLO-4)
Client response
HELLO-4
The “frontend” project output:
[INFO] [10/05/2016 07:21:35.592] [main] [akka.remote.Remoting] Starting remoting
[INFO] [10/05/2016 07:21:35.883] [main] [akka.remote.Remoting] Remoting started; listening on addresses :[akka.tcp://ClusterSystem@127.0.0.1:2551]
[INFO] [10/05/2016 07:21:35.901] [main] [akka.cluster.Cluster(akka://ClusterSystem)] Cluster Node [akka.tcp://ClusterSystem@127.0.0.1:2551] – Starting up…
[INFO] [10/05/2016 07:21:36.028] [main] [akka.cluster.Cluster(akka://ClusterSystem)] Cluster Node [akka.tcp://ClusterSystem@127.0.0.1:2551] – Registered cluster JMX MBean [akka:type=Cluster]
[INFO] [10/05/2016 07:21:36.028] [main] [akka.cluster.Cluster(akka://ClusterSystem)] Cluster Node [akka.tcp://ClusterSystem@127.0.0.1:2551] – Started up successfully
[INFO] [10/05/2016 07:21:36.037] [ClusterSystem-akka.actor.default-dispatcher-2] [akka.cluster.Cluster(akka://ClusterSystem)] Cluster Node [akka.tcp://ClusterSystem@127.0.0.1:2551] – Metrics will be retreived from MBeans, and may be incorrect on some platforms. To increase metric accuracy add the ‘sigar.jar’ to the classpath and the appropriate platform-specific native libary to ‘java.library.path’. Reason: java.lang.ClassNotFoundException: org.hyperic.sigar.Sigar
[INFO] [10/05/2016 07:21:36.040] [ClusterSystem-akka.actor.default-dispatcher-2] [akka.cluster.Cluster(akka://ClusterSystem)] Cluster Node [akka.tcp://ClusterSystem@127.0.0.1:2551] – Metrics collection has started successfully
[WARN] [10/05/2016 07:21:37.202] [ClusterSystem-akka.remote.default-remote-dispatcher-5] [akka.tcp://ClusterSystem@127.0.0.1:2551/system/endpointManager/reliableEndpointWriter-akka.tcp%3A%2F%2FClusterSystem%40127.0.0.1%3A2552-0] Association with remote system [akka.tcp://ClusterSystem@127.0.0.1:2552] has failed, address is now gated for [5000] ms. Reason: [Association failed with [akka.tcp://ClusterSystem@127.0.0.1:2552]] Caused by: [Connection refused: no further information: /127.0.0.1:2552]
[INFO] [10/05/2016 07:21:37.229] [ClusterSystem-akka.actor.default-dispatcher-17] [akka://ClusterSystem/deadLetters] Message [akka.cluster.InternalClusterAction$InitJoin$] from Actor[akka://ClusterSystem/system/cluster/core/daemon/firstSeedNodeProcess-1#-2009390233] to Actor[akka://ClusterSystem/deadLetters] was not delivered. [1] dead letters encountered. This logging can be turned off or adjusted with configuration settings ‘akka.log-dead-letters’ and ‘akka.log-dead-letters-during-shutdown’.
[INFO] [10/05/2016 07:21:37.229] [ClusterSystem-akka.actor.default-dispatcher-17] [akka://ClusterSystem/deadLetters] Message [akka.cluster.InternalClusterAction$InitJoin$] from Actor[akka://ClusterSystem/system/cluster/core/daemon/firstSeedNodeProcess-1#-2009390233] to Actor[akka://ClusterSystem/deadLetters] was not delivered. [2] dead letters encountered. This logging can be turned off or adjusted with configuration settings ‘akka.log-dead-letters’ and ‘akka.log-dead-letters-during-shutdown’.
[INFO] [10/05/2016 07:21:37.232] [ClusterSystem-akka.actor.default-dispatcher-21] [akka://ClusterSystem/system/endpointManager/reliableEndpointWriter-akka.tcp%3A%2F%2FClusterSystem%40127.0.0.1%3A2552-0/endpointWriter] Message [akka.remote.EndpointWriter$AckIdleCheckTimer$] from Actor[akka://ClusterSystem/system/endpointManager/reliableEndpointWriter-akka.tcp%3A%2F%2FClusterSystem%40127.0.0.1%3A2552-0/endpointWriter#-1346529294] to Actor[akka://ClusterSystem/system/endpointManager/reliableEndpointWriter-akka.tcp%3A%2F%2FClusterSystem%40127.0.0.1%3A2552-0/endpointWriter#-1346529294] was not delivered. [3] dead letters encountered. This logging can be turned off or adjusted with configuration settings ‘akka.log-dead-letters’ and ‘akka.log-dead-letters-during-shutdown’.
[INFO] [10/05/2016 07:21:38.085] [ClusterSystem-akka.actor.default-dispatcher-22] [akka://ClusterSystem/deadLetters] Message [akka.cluster.InternalClusterAction$InitJoin$] from Actor[akka://ClusterSystem/system/cluster/core/daemon/firstSeedNodeProcess-1#-2009390233] to Actor[akka://ClusterSystem/deadLetters] was not delivered. [4] dead letters encountered. This logging can be turned off or adjusted with configuration settings ‘akka.log-dead-letters’ and ‘akka.log-dead-letters-during-shutdown’.
[INFO] [10/05/2016 07:21:39.088] [ClusterSystem-akka.actor.default-dispatcher-14] [akka://ClusterSystem/deadLetters] Message [akka.cluster.InternalClusterAction$InitJoin$] from Actor[akka://ClusterSystem/system/cluster/core/daemon/firstSeedNodeProcess-1#-2009390233] to Actor[akka://ClusterSystem/deadLetters] was not delivered. [5] dead letters encountered. This logging can be turned off or adjusted with configuration settings ‘akka.log-dead-letters’ and ‘akka.log-dead-letters-during-shutdown’.
[INFO] [10/05/2016 07:21:40.065] [ClusterSystem-akka.actor.default-dispatcher-20] [akka://ClusterSystem/deadLetters] Message [akka.cluster.InternalClusterAction$InitJoin$] from Actor[akka://ClusterSystem/system/cluster/core/daemon/firstSeedNodeProcess-1#-2009390233] to Actor[akka://ClusterSystem/deadLetters] was not delivered. [6] dead letters encountered. This logging can be turned off or adjusted with configuration settings ‘akka.log-dead-letters’ and ‘akka.log-dead-letters-during-shutdown’.
[INFO] [10/05/2016 07:21:41.095] [ClusterSystem-akka.actor.default-dispatcher-19] [akka.cluster.Cluster(akka://ClusterSystem)] Cluster Node [akka.tcp://ClusterSystem@127.0.0.1:2551] – Node [akka.tcp://ClusterSystem@127.0.0.1:2551] is JOINING, roles [frontend]
[INFO] [10/05/2016 07:21:41.123] [ClusterSystem-akka.actor.default-dispatcher-19] [akka.cluster.Cluster(akka://ClusterSystem)] Cluster Node [akka.tcp://ClusterSystem@127.0.0.1:2551] – Leader is moving node [akka.tcp://ClusterSystem@127.0.0.1:2551] to [Up]
[INFO] [10/05/2016 07:21:50.837] [ClusterSystem-akka.actor.default-dispatcher-14] [akka.cluster.Cluster(akka://ClusterSystem)] Cluster Node [akka.tcp://ClusterSystem@127.0.0.1:2551] – Node [akka.tcp://ClusterSystem@127.0.0.1:2552] is JOINING, roles [backend]
[INFO] [10/05/2016 07:21:51.096] [ClusterSystem-akka.actor.default-dispatcher-16] [akka.cluster.Cluster(akka://ClusterSystem)] Cluster Node [akka.tcp://ClusterSystem@127.0.0.1:2551] – Leader is moving node [akka.tcp://ClusterSystem@127.0.0.1:2552] to [Up]
Frontend saw TransformationJob : ‘TransformationJob(hello-1)’
[WARN] [10/05/2016 07:22:05.669] [ClusterSystem-akka.remote.default-remote-dispatcher-24] [akka.serialization.Serialization(akka://ClusterSystem)] Using the default Java serializer for class [sample.cluster.transformation.TransformationJob] which is not recommended because of performance implications. Use another serializer or disable this warning using the setting ‘akka.actor.warn-about-java-serializer-usage’
[WARN] [10/05/2016 07:22:05.689] [ClusterSystem-akka.remote.default-remote-dispatcher-23] [akka.serialization.Serialization(akka://ClusterSystem)] Using the default Java serializer for class [sample.cluster.transformation.TransformationResult] which is not recommended because of performance implications. Use another serializer or disable this warning using the setting ‘akka.actor.warn-about-java-serializer-usage’
Frontend saw TransformationJob : ‘TransformationJob(hello-2)’
Frontend saw TransformationJob : ‘TransformationJob(hello-3)’
Frontend saw TransformationJob : ‘TransformationJob(hello-4)’
.
The “backend”project output:
[INFO] [10/05/2016 07:21:50.023] [main] [akka.remote.Remoting] Starting remoting
[INFO] [10/05/2016 07:21:50.338] [main] [akka.remote.Remoting] Remoting started; listening on addresses :[akka.tcp://ClusterSystem@127.0.0.1:2552]
[INFO] [10/05/2016 07:21:50.353] [main] [akka.cluster.Cluster(akka://ClusterSystem)] Cluster Node [akka.tcp://ClusterSystem@127.0.0.1:2552] – Starting up…
[INFO] [10/05/2016 07:21:50.430] [main] [akka.cluster.Cluster(akka://ClusterSystem)] Cluster Node [akka.tcp://ClusterSystem@127.0.0.1:2552] – Registered cluster JMX MBean [akka:type=Cluster]
[INFO] [10/05/2016 07:21:50.430] [main] [akka.cluster.Cluster(akka://ClusterSystem)] Cluster Node [akka.tcp://ClusterSystem@127.0.0.1:2552] – Started up successfully
[INFO] [10/05/2016 07:21:50.437] [ClusterSystem-akka.actor.default-dispatcher-6] [akka.cluster.Cluster(akka://ClusterSystem)] Cluster Node [akka.tcp://ClusterSystem@127.0.0.1:2552] – Metrics will be retreived from MBeans, and may be incorrect on some platforms. To increase metric accuracy add the ‘sigar.jar’ to the classpath and the appropriate platform-specific native libary to ‘java.library.path’. Reason: java.lang.ClassNotFoundException: org.hyperic.sigar.Sigar
[INFO] [10/05/2016 07:21:50.441] [ClusterSystem-akka.actor.default-dispatcher-6] [akka.cluster.Cluster(akka://ClusterSystem)] Cluster Node [akka.tcp://ClusterSystem@127.0.0.1:2552] – Metrics collection has started successfully
[INFO] [10/05/2016 07:21:50.977] [ClusterSystem-akka.actor.default-dispatcher-2] [akka.cluster.Cluster(akka://ClusterSystem)] Cluster Node [akka.tcp://ClusterSystem@127.0.0.1:2552] – Welcome from [akka.tcp://ClusterSystem@127.0.0.1:2551]
[WARN] [10/05/2016 07:21:51.289] [ClusterSystem-akka.remote.default-remote-dispatcher-15] [akka.serialization.Serialization(akka://ClusterSystem)] Using the default Java serializer for class [sample.cluster.transformation.BackendRegistration$] which is not recommended because of performance implications. Use another serializer or disable this warning using the setting ‘akka.actor.warn-about-java-serializer-usage’
[WARN] [10/05/2016 07:22:05.651] [ClusterSystem-akka.remote.default-remote-dispatcher-7] [akka.serialization.Serialization(akka://ClusterSystem)] Using the default Java serializer for class [sample.cluster.transformation.TransformationJob] which is not recommended because of performance implications. Use another serializer or disable this warning using the setting ‘akka.actor.warn-about-java-serializer-usage’
Backend has transformed the incoming job text of ‘hello-1’ into ‘HELLO-1’
[WARN] [10/05/2016 07:22:05.677] [ClusterSystem-akka.remote.default-remote-dispatcher-15] [akka.serialization.Serialization(akka://ClusterSystem)] Using the default Java serializer for class [sample.cluster.transformation.TransformationResult] which is not recommended because of performance implications. Use another serializer or disable this warning using the setting ‘akka.actor.warn-about-java-serializer-usage’
Backend has transformed the incoming job text of ‘hello-2’ into ‘HELLO-2’
Backend has transformed the incoming job text of ‘hello-3’ into ‘HELLO-3’
Backend has transformed the incoming job text of ‘hello-4’ into ‘HELLO-4’
Nat or Docker Considerations
Akka clustering does not work transparently with Network Address Translation, Load Balancers, or in Docker containers. If this is your case you may need to further configure Akka as described here :
http://doc.akka.io/docs/akka/snapshot/scala/remoting.html#remote-configuration-nat
Where Can I Find The Code Examples?
I will be augmenting this GitHub repo with the example projects as I move through this series
https://github.com/sachabarber/SachaBarber.AkkaExamples

