Introduction
I am a Microsoft SQL Server Developer, I am really passionate about this technology. Once I had experience with SyBASE ASE. It could become my permanent job assignment. But it didn't. And that is why: to get a job offer I had to pass through several tests and interviews, of course. One phase of which was implementing SQL queries of different complexity. There was a task to build hierarchy among them. As fun of Microsoft SQL Server 2008, I completed it fast. ...so I was hired. And while all installations/permissions settings were be performing, my manager gave me a task to implement my tests using SyBASE with the aim to fill this time up. I repeated these queries in SyBASE, but I quit the job after that and continued to look for a job (as a Microsoft SQL Server developer, of course). The cause is considerable advantage of Microsoft SQL Server over SyBASE from a developer's point of view. This article is devoted to the comparison of expanses provided by Microsoft SQL Server and SyBASE to developer at Hierarchy building sample.
Background
This article is a conclusion of my short touch in SyBASE. I am not master of SyBASE. Thus I am not pretending on objectivity of my words concerning SyBASE SQL. This article does not cover any comparison of performance and costs of two RDBMSs described above, I did not touch anything but speed and comfort of SQL queries composition using Microsoft SQL Server and SyBASE dialects of SQL.
Problem
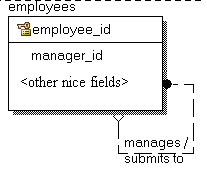
We have got a table of employees with primary key (employee_id) and self referencing foreign key (manager_id) to indicate manager of current employee - 'null' means 'selfmanaged' (see picture below). It is needed to know who from managers have more than 8 subordinates 'under' her. So the main problem is to build a full hierarchy table of all subordinates (including indirect ones) (it's classic). And then just roll data up and select interesting totals matched to criteria. So let the game begin!
Microsoft SQL Server 2008 Solution
Design
- You build a table with all subordinates for a given employee using recursive query.
- You pack this query to function that returns table for given manager whose id is passed as
manager_id parameter. - You call the created function for each employee using
CROSS APPLY on created early function
Solution, In Fact
Function to get all subordinates for a given manger:
CREATE FUNCTION fn_get_all_subordinates(@manager_id AS bigint)
RETURNS @subordinates TABLE
(
manager_id bigint NOT NULL
,employee_id bigint NOT NULL
,employee_level int NOT NULL
)
AS
BEGIN
with Manager_Subordinates(manager_id, employee_id, employee_level)
as
(
select emp.manager_id, emp.employee_id, 0 employee_level
from employees emp
where emp.manager_id = @manager_id
union all
select ms.manager_id, emp.employee_id, employee_level + 1
from employees emp
join Manager_Subordinates ms
on emp.manager_id = ms.employee_id
)
insert into @subordinates
select manager_id, employee_id, employee_level
from Manager_Subordinates ms;
RETURN
END
GO
T-SQL query to get managers who get more than 8 subordinates (including indirect ones):
select emp.employee_name
from
employees emp
join
(
select stat.manager_id employee_id
from employees emp
cross apply fn_get_all_subordinates(emp.employee_id) stat
group by stat.manager_id
having COUNT(stat.employee_id) > 8
) stat
on emp.employee_id = stat.employee_id
SyBASE ASE Solution
Research
First, what I was confronted with was the existence of two kinds of SyBase at least. It is 'ASE' and 'AnyWhere'. At the worst, I should work with the former which is more scanty in its SQL. It does not support With Recursive and so it does not provide support for recursive queries. It's bad but it is just the beginning of the story. Next oddity was the fact SyBase ASE does not support TABLE as return type. So the only way to perform recursion is to create a temporary table ('sharp-table') in one procedure and call another one from former and force the last to fill this table by rows up. It is not nice too. So the only solution which I could live with is build hierarchy iteratively (transformation of recursive algorithm to iterative analogue is challenge - I love it!).
Design
- You take all top managers from employees set by criteria 'Top manager has null in her manager_id attribute'.
- Then you take all submitters of top managers by matching manager IDs with value in
manager_id and save them into target table with subordination level 0 - it means 'direct subordination' ('target table' is table with pairs 'manager-subordinate' accompanied by 'subordinate level'). - You take all subordinates for subordinates of level 0 and keep them as subordinates of level 1 for primordial managers, then you take all subordinates for subordinates of level 1 - keep them as level 2, and so on.
- This is the end of iteration.
- Then you consider subordinates of level 0 from first iteration as next 'roots' and repeat table filling for 'new top managers', then get one of level 1, and so on until we reached leaves of deepest subordination level.
Algorithm admission: hierarchy has not got cycles because it is contrary to nature of staff subordination. In case of cycles existence, you will get an infinite loop. But you can easily expand algorithm to handle those cases by checking inserted rows on their existence in table before actual insert.
Solution, In Fact
This is a script to support population of testing data (please, correct it to ensure db integrity):
create table employee
(
employee_id numeric(38,0) identity primary key
,employee_first_name nvarchar(20) not null
,employee_last_name nvarchar(30) not null
,employee_name as employee_last_name + ', ' + substring(employee_first_name, 1, 1)
,manager_id numeric(38,0) null
,group_id numeric(38,0) null
,title_id numeric(38,0) DEFAULT 4 not null
,salary_type char(1) not null
,salary_amount numeric(15,4) not null
)
insert into employee(employee_first_name, employee_last_name, _
manager_id, group_id, title_id, salary_type, salary_amount)
values('Joe', 'Kilik', null, null, 1, 'w', 5000)
insert into employee(employee_first_name, employee_last_name, _
manager_id, group_id, title_id, salary_type, salary_amount)
values('Sue', 'Kilik', 1, null, 2, 'w', 4500)
insert into employee(employee_first_name, employee_last_name, _
manager_id, group_id, title_id, salary_type, salary_amount)
values('Sarah', 'Gilt', 2, 2, 1, 'w', 5000)
insert into employee(employee_first_name, employee_last_name, _
manager_id, group_id, title_id, salary_type, salary_amount)
values('John', 'Kahl', 3, 2, default, 'w', 3000)
insert into employee(employee_first_name, employee_last_name, _
manager_id, group_id, title_id, salary_type, salary_amount)
values('Jimmi', 'Gross', 3, 2, default, 'w', 2800)
insert into employee(employee_first_name, employee_last_name, _
manager_id, group_id, title_id, salary_type, salary_amount)
values('Carlos', 'Castanello', 3, 5, default, 'w', 7000)
insert into employee(employee_first_name, employee_last_name, _
manager_id, group_id, title_id, salary_type, salary_amount)
values('Doe', 'Johns', 1, null, 2, 'w', 2500)
insert into employee(employee_first_name, employee_last_name, _
manager_id, group_id, title_id, salary_type, salary_amount)
values('Gad', 'Real', 7, null, 3, 'w', 3500)
select * from employee order by manager_id
This is the script to take hierarchy (SyBASE ASE implementation):
declare @cur_lvl numeric(2,0)
declare @cur_iter numeric(4,0)
declare @rows_selected int
create table #all_submits
(
manager_id numeric(38,0)
,submit_id numeric(38,0)
,submit_level numeric(2,0)
,product_iter numeric(4,0)
)
set @cur_iter = 0
insert into #all_submits (manager_id, submit_id, submit_level, product_iter)
select employee_id, employee_id, -1, @cur_iter
from employee mgr where manager_id is null
while (1=1)
begin
set @cur_lvl = 0
while (1=1)
begin
insert into #all_submits (manager_id, submit_id, submit_level, product_iter)
select mgr.manager_id, sbm.employee_id, @cur_lvl, @cur_iter
from employee sbm join #all_submits mgr on sbm.manager_id = mgr.submit_id
where product_iter = @cur_iter and mgr.submit_level = @cur_lvl - 1
set @rows_selected = @@ROWCOUNT
if (0 = @rows_selected)
break
set @cur_lvl = @cur_lvl + 1
end
insert into #all_submits (manager_id, submit_id, submit_level, product_iter)
select submit_id, submit_id, -1, @cur_iter + 1
from #all_submits mgr
where submit_level = @cur_iter and product_iter = 0
set @rows_selected = @@ROWCOUNT
if (0 = @rows_selected)
break
set @cur_iter = @cur_iter + 1
end
select mng.employee_first_name manager_name, _
sbm.employee_first_name submit_name, s.submit_level
from #all_submits s
join employee mng on mng.employee_id = s.manager_id
join employee sbm on sbm.employee_id = s.submit_id
where s.manager_id <> s.submit_id
order by product_iter, submit_level, mng.employee_first_name
drop table #all_submits
And this is the part to take interesting managers (you should replace by it select in the script above):
select mng.employee_first_name, submits_amount
from
(
select manager_id, count(*) submits_amount
from #all_submits s
where s.manager_id <> s.submit_id
group by s.manager_id
having count(*) > 8
) stat
join employee mng on mng.employee_id = stat.manager_id
order by submits_amount desc
I spent approximately 3-4 hours (180-240 minutes) to handle this task in SyBASE as opposed to 15-25 minutes in Microsoft SQL Server 2008. And who knows how many bugs it hides, despite spending a mass of time for testing/debugging. Bare figures are worth thousands of wordy arguments. I do not know how much SyBASE costs but it is obvious that development/maintenance using Microsoft SQL Server is greatly cheaper due to high performance of coding (it is 9-12 times faster in this sample).
Control Shot
Looking at realization of 'iterative' algorithm in SyBASE, I do not like scanning of the whole table for the purpose of getting IDs from #all_submits table by next submit level of first iteration ('insert roots (next)' section, in outer loop right after inner loop). It would be good to create some structure for quick selection of interesting rows. There is filtered index in Microsoft SQL Server 2008 to handle this perfectly. It creates data structure to support quick seek, this structure covers only elements of our interest, and it is not changed further because all next insertions perform out of index scope (it is filtered!). We will use FILLFACTOR assigned to 100 to avoid any gaps in index because we build it only once and there will be no insertions to it further (we cover data of only first iteration). To omit transference to clustered index, we include interesting data to that index with aid of INCLUDE option.
Creation of filtered index to accelerate selection data from certain scope:
...........
break
set @cur_lvl = @cur_lvl + 1
end
IF (0 = @cur_iter)
BEGIN
CREATE NONCLUSTERED INDEX NCI_iter0_lvl_AllSubmits
ON #all_submits(product_iter, submit_level)
INCLUDE(submit_id)
WHERE product_iter = 0
WITH (FILLFACTOR=100)
END
insert into all_submits (manager_id, submit_id, submit_level, product_iter)
............
Force using of created index to select submits for next level:
............
insert into all_submits (manager_id, submit_id, submit_level, product_iter)
select submit_id, submit_id, -1, @cur_iter + 1
from all_submits mgr
WITH (FORCESEEK, INDEX(NCI_iter0_lvl_AllSubmits))
where product_iter = 0 and submit_level = @cur_iter
............

Oracle Solution
To complete the picture, I add one more deserving competitor - Oracle. And it gets the first award. Oracle provides SELECT ... START WITH initial-condition CONNECT BY PRIOR recurse-condition. Only hierarchyid type in Microsoft SQL Server 2008 could contend over first place with Oracle solution, but it requires changes in design as opposed to Oracle which deals with 'classic' implementation of parent-child relation.
Select the data hierarchically:
select lpad(' ',2*(level-1)) || employee_first_name s
from employee
start with manager_id is null
connect by prior employee_id = manager_id;
Instead of Conclusion
Microsoft SQL Server 2008 is far ahead of SyBASE, although it is not an absolute leader. It has to absorb a lot of handy solutions existing in the market. I mean 'Windows class' of Oracle, for instance. Of course, Microsoft SQL Server 2008 supports aggregate_function over(partition by ... order by ....), but it is nothing in comparison with Oracle's dynamic window cursor and functions that allow reference to rows inside that cursor...
So I hope Microsoft will implement something similar soon, and many other handy features.
History
- 30th September, 2010: Initial post

