What is Machine Learning?
“Machine learning is the field of study that gives computers the ability to learn without being explicitly programmed” Arthur Smauel.
We can think of machine learning as approach to automate tasks like predictions or modelling. For example, consider an email spam filter system, instead of having programmers manually looking at the emails and coming up with spam rules. We can use a machine learning algorithm and feed it input data (emails) and it will automatically discover rules that are powerful enough to distinguish spam emails.
Machine learning is used in many application nowadays like spam detection in emails or movie recommendation systems that tells you movies that you might like based on your viewing history. The nice and powerful thing about machine learning is: It learns when it gets more data and hence it gets more and more powerful the more data we give them.
Types of Machine Learning
There are three different types of machine learning: supervised, unsupervised and reinforcement learning.
Supervised Learning
The goal of supervised learning is to learn a model from labelled training data that allows us to make predictions about future data. For supervised machine learning to work we need to feed the algorithm two things: the input data and our knowledge about it labels).
The spam filter example mentioned earlier is a good example of supervised learning; we have a bunch of emails (data) and we know whether each email is spam or not (labels).
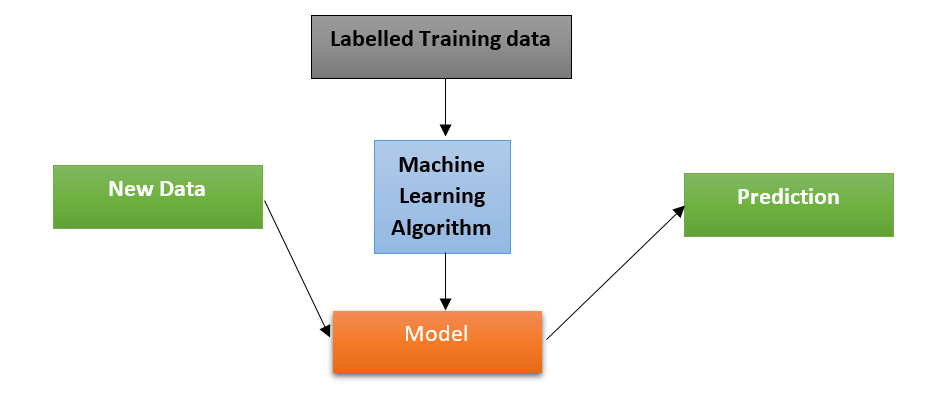
Supervised learning can be divided into two subcategories:
1. Classification: It is used to predict categories or class labels based on past observations i.e. we have discrete variable you want to distinguish into discrete categorical outcome. For example, in the email spam filter system the output is discrete “spam” or “not spam”.
2. Regression: It is used to predict a continuous outcome. For example, to determine the price of houses and how it is affected by the number of rooms in that house. The input data is the house features (no. of rooms, location, size in square feet, etc…) and the output is the price (the continuous outcome).
Unsupervised Learning
The goal of unsupervised learning is to discover hidden structure or patterns in unlabeled data and it can be divided into two subcategories
1. ![Image 2]() Clustering: It is used to organize information into meaningful clusters (subgroups) without having prior knowledge of their meaning. For example, the figure below shows how we can use clustering to organize unlabeled data into groups based on their features.
Clustering: It is used to organize information into meaningful clusters (subgroups) without having prior knowledge of their meaning. For example, the figure below shows how we can use clustering to organize unlabeled data into groups based on their features.

2. Dimensionality Reduction (Compression): It is used to reduce a higher dimension data into a lower dimension ones. To put it more clearly consider this example. A telescope has terabytes of data and not all of these data can be stored and so we can use dimensionality reduction to extract the most informative features of these data to be stored. Dimensionality reduction is also a good candidate to visualize data because if you have data in higher dimensions you can compress it to 2D or 3D to easily plot and visualize it.
Reinforcement Learning
The goal of reinforcement learning is to develop a system that improves its performance based on the interaction with a dynamic environment and there is a delayed feedback that act as a reward. i.e. reinforcement learning is learning by doing with a delayed reward. A classic example of reinforcement learning is a chess game, the computer decided a series of moves and the reward is the “win” or “lose” at the end the game.
You might think that this is similar to supervised learning where the reward is basically a label for the data but the core difference is this feedback/reward is not the truth but it is a measure of how well the action to achieving a certain goal.
Data Preprocessing
The quality of the data and the amount of useful information it contains affect greatly how well an algorithm can learn. Hence, it is important to preprocess the dataset before using it. The most common preprocessing steps are: removing missing values, converting categorical data into shape suitable for machine learning algorithm and feature scaling.
Missing Data
Sometimes the samples in the dataset are missing some values and we want to deal with these missing values before passing it to the machine learning algorithm. There are a number of strategies we can follow
1. Remove samples with missing values: This approach is by far the most convenient but we may end up removing too many samples and by that we would be losing valuable information that can help the machine learning algorithm.
2. Imputing missing values: Instead of removing the entire sample we use interpolation to estimate the missing values. For example, we could substitute a missing value by the mean of the entire column.
Categorical Data
In general, features can be numerical (e.g. price, length, width, etc…) or categorical (e.g. color, size, etc..). Categorical features are further split into nominal and ordinal features.
Ordinal features can be sorted and ordered. For example, size (small, medium, large), we can order these sizes large > medium > small. While nominal features do not have an order for example, color, it doesn’t make any sense to say that red is larger than blue.
Most machine learning algorithm require that you convert categorical features into numerical values. One solution would to assign each value a different number starting from zero. (e.g. small à 0 ,medium à 1 ,large à 2)
This works well for ordinal features but might cause problems with nominal features (e.g. blue à 0, white à 1, yellow à 2) because even though colors are not ordered the learning algorithm will assume that white is larger than blue and yellow is larger than white and this is not correct.
To get around this problem is to use one-hot encoding, the idea is to create a new feature for each unique value of the nominal feature.
In the above example, we converted the color feature into three new features Red, Green, Blue and we used binary values to indicate the color. For example, a sample with “Red” color is now encoded as (Red=1, Green=0, Blue=0)
Feature Scaling
Assume we have data with two features one on a scale from 1 to 10 and the other on a scale from 1 to 1000. If the algorithm uses distance as part of its working or if it is trying to minimize mean square error, it is safe to assume that the algorithm will spend most of the time focusing on feature 2.
To solve this, we will use normalization which is bringing the different features onto the same scale. We scale the features in the range of [0, 1]
is a particular sample, is the smallest value in the feature and is the largest one.
Another approach is standardization
Where, is the mean of all the sample for that particular feature and is the standard deviation of that feature.
The following table shows the result of standardization and normalization on a sample input data
Training VS Test Data
We typically split the input data into learning and testing datasets. The then run the machine learning algorithm on the learning dataset to generate the prediction model. Later, we use the test dataset to evaluate our model.
It is important that the test data is separate from the one used in training otherwise we will be kind of cheating because may for example the generated model memorizes the data and hence if the test data is also part of the training data then our evaluation scores of the model will be higher than they actually are.
The data is usually split 75% training and 25% data or 2/3 training and 1/3 testing. It is important to note that: the smaller the training set the more challenging it is for the algorithm to discover the rules.
In addition, when splitting the dataset, you need to maintaining class proportions and population statistics otherwise we will have some classes that are under represented in the training dataset and over represented in the test dataset.
For example, you may have 100 sample and a total of 80 samples are labeled with Class-A and the remaining 20 instances are labeled with Class-B. you want to make sure when splitting the data that you maintain this representation.
One way to avoid this problem and to make sure that all classes are represented in both training and testing datasets is stratification. It is the process of rearranging the data as to ensure each set is a good representative of the whole. In our previous example, (80/20 samples), it is best to arrange the data such that in every set, each class comprises around 80:20 ratios of the two classes.
Cross Validation
A crucial step when building our machine learning model is to estimate its performance on that that the model hadn’t seen before. We want to make sure that the model generalizes well to new unseen data.
One case, the machine learning algorithm has different parameters and we want to tune these parameters to achieve the best performance. (Note: the parameters of the machine learning algorithm are called hyperparameters). Another case, sometimes we want to try out different algorithms and choose the best performing one. Below are some of the techniques used.
Holdout Method
We simply split the data into training and testing datasets. We train the algorithm on the training dataset to generate a model. In order, to evaluate different algorithms we use the testing data to evaluate each algorithm.
However, if we reuse the same test dataset over and over again during algorithm selection, the test data has now come part of the training data. Hence, when we use the test data for the final evaluation the generated model is biased towards the test data and the performance score is optimistic.
Holdout Validation
As before, we split the data into training and testing dataset. Then, the training data is further split into training and validation sets.
The training data is used to train different models. Then the validation data is used to compute performance of each of them and we select the best one. Finally, the model is then used for the test set to evaluate performance. The next figure illustrates this idea.
However, because we use the validation set multiple times, Holdout validation is sensitive to how we partition the data and that is what K-fold cross validation tries to solve.
K-fold cross validation
Initially, we split the data into training and testing dataset. Furthermore, the training dataset is split into K chunks.
Suppose we will use 5-fold cross validation, the training data set is split into 5 chunks and the training phase will take place over 5 iterations. In each iteration we use one chunk as the validation dataset while the rest of the chunk are grouped together to form the training dataset.
This is very similar to Holdout validation except in each iteration the validation data is different and this removed the bias. Each iteration generates a score and the final score is the average score of all iteration. As before we select the best model and use the test data for the final performance evaluation.
Conclusion
In this article I tried to give a 10,000 foot view of machine learning. I deliberately avoided discussing any specific machine learning algorithm because that would take volumes. If you are interested in machine learning I suggest checking out some of the material in the further reading section.
Further Reading
1. Machine Learning: a Coursera Course taught by Andrew Ng, Associate Professor, at Stanford University. The couse provides a broad introduction to machine learning, datamining, and statistical pattern recognition.
2. Machine Learning with scikit-learn [Part 1,Part 2]: A beginner/Intermediate level tutorial on machine learning with scikit-learn.
3. Python Machine Learning: A book written by Sebastian Raschka. This book discusses the fundamentals of machine learning and how to utilize these in real-world applications using Python.

