Introduction
In my previous article of MongoDB, I have talked about the Introduction to MongoDB and CRUD Operations in MongoDB. So it is the time that we should learn more about MongoDB, hence in this article I am going to talk about another important aspect of MongoDB i.e. Aggregation Pipeline.
Aggregation operations are very important in any type of database whether it is SQL or NoSQL. To perform aggregations operations, MongoDB group values from multiple documents together and then perform a variety of operations on grouped data to return a single result. SQL uses aggregate functions to return a single value calculated from values in columns.
MongoDB has three ways to perform aggregation: the aggregation pipeline, the map-reduce function, and the single purpose aggregation methods.
In this article, we will focus on aggregation pipeline. I'll try to cover each major section of it using simple examples. We will be writing mongo shell commands to perform aggregation.
Aggregation Pipeline
MongoDB's aggregation framework is based on the concept of data processing pipelines. Aggregation pipeline is similar to the UNIX world pipelines. At the very first is the collection, the collection is sent through document by document, documents are piped through processing pipeline and they go through series of stages and then we eventually get a result set.
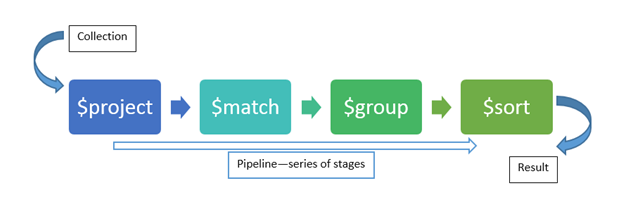
In the figure, you see that collection is processed through different stages i.e. $project, $match, $group, $sort these stages can appear multiple times.
Various stages in pipeline are:
$project – select, reshape data$match – filter data$group – aggregate data$sort – sorts data$skip – skips data$limit – limit data$unwind – normalizes data
Let’s try to visualize the aggregation with an example. Don’t worry about the syntax. I will be explaining it soon.
db.mycollection.aggregate([
{$match:{'phone_type':'smart'}},
{$group:{'_id':'$brand_name',total:{$sum:'$price'}}}
])

As you can see, in the diagram we have a collection, the $match stages filters out the documents then in next stage of pipeline documents gets grouped and we get the final result set.
Preparing Dummy Data
To run mongo shell commands, we need a database and some dummy records, so let’s create our database and a collection.
dept = ['IT', 'Sales', 'HR', 'Admin'];
for (i = 0; i < 10; i++) {
db.mycollection.insert({ //mycollection is collection name
'_id': i,
'emp_code': 'emp_' + i,
'dept_name': dept[Math.round(Math.random() * 3)],
'experience': Math.round(Math.random() * 10),
});
The above command will insert some dummy documents in a collection named mycollection in mydb database.
Syntax
db.mycollection.aggregate([
{$match:{'phone_type':'smart'}},
{$group:{'_id':'$brand_name',total:{$sum:'$price'}}}
])
Syntax is pretty much easier, aggregate function takes an array as argument, in array we can pass various phases/stages of pipeline.
In the above example, we have passed two phases of pipeline that are $match which will filter out record and $group phase which will group the records and produce final record set.
Stages of Pipeline
1. $project
In the $project phase, we can add a key, remove a key, reshape a key. There are also some simple functions that we can use on the key : $toUpper, $toLower, $add, $multiply, etc.
Let’s use $project to reshape the documents that we have created.
db.mycollection.aggregate([
{
$project:{
_id:0,
'department':{$toUpper:'$dept_name'},
'new_experience':{$add:['$experience',1]}
}
}
])
In this aggregate query, we are projecting the documents, _id:0 means _id which is compulsory we are hiding this field, a new key named department is created using previous dept_name field in upper case. The point to be noticed here is that field ‘dept_name’ is prefixed with ‘$’ sign to tell mongo shell that this field is the original field name of the document. Another new field named new_experience is created by adding 1 using $add function to the previous experience field. We will get the output like this:
2. $match
It works exactly like ‘where clause' in SQL to filter out the records. The reason we might want to match is because we'd like to filter the results and only aggregate a portion of the documents or search for particular parts of the results set after we do the grouping. Let's say in our collection we want to aggregate documents having department equals to sales, the query will be:
db.mycollection.aggregate([
{
$match:{
dept_name:'Sales'
}
}
])
3. $group
As the name suggests, $group groups documents based on some key. Let’s say we want to group employees on their department name and we want to find the number of employees in each department.
db.mycollection.aggregate([
{
$group:{
_id:'$dept_name',
no_of_employees:{$sum:1}
}
}
])
Here, _id is the key for grouping and I have created new key named no_of_employees and used $sum to find the total record in each group.
Let’s improve this query to present output in a more sensible way.
db.mycollection.aggregate([
{
$group:{
_id:{'department':'$dept_name'},
no_of_employees:{$sum:1}
}
}
])
Let’s say we want to group documents on more than on key, all we need to do is specify the name of the keys in _id field.
db.mycollection.aggregate([
{
$group:{
_id:{'department':'$dept_name',
'year_of_experience':'$experience'
},
no_of_employees:{$sum:1}
}
}
])
4. $sort
Sort helps you to sort data after aggregation in ascending or descending as per your need. Let’s say we want to group department name in ascending order and find out the number of employees.
db.mycollection.aggregate([
{
$group:{
_id:'$dept_name',
no_of_employees:{$sum:1}
}
},
{
$sort:{
_id:1
}
}
])
For descending use -1. Here in $sort, I have used _id field because in the first phase of aggregation, I used $dept_name as _id for aggregation.
5. $skip and $limit
$skip and $limit exactly same way skip and limit work when we do a simple find. It doesn’t make any sense to skip and limit unless we first sort, otherwise, the result is undefined.
We first skip records and then we limit.
Let’s see an example for the same.
db.mycollection.aggregate([
{
$group:{
_id:'$dept_name',
no_of_employees:{$sum:1}
}
},
{
$sort:{
_id:1
}
},
{
$skip:2
},
{
$limit:1
}
])
Documents are grouped, then sorted, after that, we skipped two documents and limit the document to only one.
6. $first and $last
As we know how sort works in the aggregation pipeline, we can learn about $first and $last. They allow us to get the first and last value in each group as aggregation pipeline processes the document.
db.mycollection.aggregate([
{
$group:{
_id:'$dept_name',
no_of_employees:{$sum:1},
first_record:{ $first:'$emp_code'}
}
}
])
7. $unwind
As we know in MongoDB, documents can have arrays. It is not easy to group on something within an array. $unwind first unjoin array data and then basically rejoin it in a way that lets us do grouping calculations on it.
Let’s say we have a document like this:
{
a:somedata,
b:someotherdata,
c:[arr1,arr2,arr3]
}
After $unwind on ‘c’, we will get three documents:
{
a:somedata,
b:someotherdata,
c:arr1
}
{
a:somedata,
b:someotherdata,
c:arr2
}
{
a:somedata,
b:someotherdata,
c:arr3
}
8. Aggregation Expressions
Let's see some expressions that are very common in SQL and in MongoDB. We have an alternate for that.
$Sum: We have already seen its example.$avg: Average works just like sum except it calculates the average for each group.$min: Finds out the minimum value from each grouped document.$max: Finds out the maximum value from each grouped document.
Further Reading
Below are some useful links from where you can further investigate and learn more about aggregation in MongoDB.
Conclusion
I have not explained all the topics in aggregation, but this article will help you kick-start using aggregation in MongoDB in your project and for your learning. I have attached mongo shell commands for your reference.

