The INSERT statement is used to add rows to a SQL Server data table. In this article, we’ll explore how to use the INSERT statement. We discuss some best practices, limitations, and wrap-up with several examples.
This is the second article in a series of articles. The first is entitled Introduction to SQL Server Data Modification Statements.
All the examples for this lesson are based on Microsoft SQL Server Management Studio and the AdventureWorks2012 database. You can get started using these free tools using my Guide Getting Started Using SQL Server.
Before We Begin
Though this article uses the AdventureWorks database for its examples, I’ve decided to create an example table for use within the database to help better illustrate the examples. You can find the script you’ll need to run here.
INSERT Statement Basic Structure
The INSERT statement is used to add rows to a table. Though an insert statement can insert data from many sources, such as literal values or source vales, the basic format is the same.
There are three components to an INSERT statement:
- The table you wish to add rows
- The columns you wish to populate with data
- The source data you wish to add to the row
The general format for the Insert statement IS:
INSERT INTO tableName
(column1, column2, …)
VALUES (value1, value2, …)
We’re now going to do some sample inserts, so if you haven’t done so already, run the script to create the esqlSalesPerson table.
Simple Example – Inserting Single Row
In this example, we insert a single row into the esqlSalesPerson table. Here is its table structure:
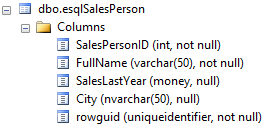
Let’s assume we want to insert a new salesperson into the table. The command to run is:
INSERT INTO dbo.esqlSalesPerson
(FullName, SalesLastYear, City, rowguid)
VALUES ('George Hitson', NULL, 'Midland', '794310D2-6293-4259-AC11-71D96689A3DD')
Notice we didn’t specify the SalesPersonID in the column list. This is because, being an identity value, that column is automatically populated.
You can switch around the columns; they don’t have to be in order. Also notice not all the columns are specified:
INSERT INTO dbo.esqlSalesPerson
(City, FullName, rowguid)
VALUES ('Traverse City', 'Donald Sax', 'F6E26EFD-5838-40F8-ABB3-D487D2932873')
Creates the following row:

Notice that since SalesLastYear wasn’t specified, it is NULL:
A row’s column values are enclosed in parenthesis (). To insert more than one row, just include another set of column values. Just be sure to separate each set with a comma as below:
INSERT INTO dbo.esqlSalesPerson
(City, FullName, rowguid)
VALUES ('Bay City', 'Ralph Gitter', 'DED7DB59-7149-47DD-8D8F-D5FCFFF11124'),
('Alpena', 'Mike Orange', '94600A1E-DD83-4ACE-9D59-8CD727A2C83E')
Before we continue on with a more complicated example, it’s important to step back and consider the INSERT statement’s behavior and some best practices.
Considerations
Data Type Considerations (Padding)
Keep in mind that when inserting data into columns whose data type is CHAR, VARCHAR, or VARBINARY, the padding or truncation of data depends upon the SET ANSI_PADDING setting.
When SET ANSI_PADDING OFF then CHAR data types are padded with spaces, VARCHAR data types have trailing spaces removed, and VARBINARY have trailing zeros removed.
For instance, if a field is defined as CHAR(10) and you insert the value ‘Kris’ into this column, then it will be padded with six spaces. The value inserted is ‘Kris ‘.
Error Handling
You can handle errors when executing an INSERT statement using a TRY…CATCH construct.
There are several common reasons an INSERT statement may fail. Some of the common ones are:
- Unique Key Violation – You’re trying to insert a record into a table which causes a duplicate key value.
- Primary Key Violation – You’re trying to insert a record into a table which already has a row with the same primary key.
- Foreign Key Violation – You're trying to insert a row into a “
child” table, yet the “parent” doesn’t exist. - Data Type Conversion – You’re trying to insert a row, where one of the values can’t be correctly converted into the corresponding columns data type.
In these cases, the INSERT statement execution stops and the INSERT generates an error. No rows from the INSERT statement are inserted into the table, even those rows that didn’t generate an error.
This “all or nothing” behavior can be modified for arithmetic errors. Consider a divide by zero error.
INSERT INTO myNumbers (x, y)
VALUES (10/0, 5),
(10/5, 2),
(10/2, 5)
This will generate an error if SET ARITHABORT is set to ON. In this case, the inserted is stopped, no rows are inserted, and an error thrown.
However, if SET ARITHABORT is set to OFF and ANSI_WARNINGS are OFF, then the same statement will successfully complete. Where there is a mathematical error, the result is replaced with NULL.
For example:
SET ARITHABORT OFF
SET ANSI_WARNINGS OFF
INSERT INTO myNumbers (x, y)
VALUES (10/0, 5),
(10/5, 2),
(10/2, 5)
adds three rows with the values:
When adding rows to tables, it is important to understand there are some columns which require special handling.
Handling Unique Identifiers
When adding data to column declared with the uniqueidentifier type, use the NEWID() function to generate a globally unique value.
As an example:
INSERT INTO dbo.esqlSalesPerson
(City, FullName, rowguid)
VALUES ('Traverse City', 'Donald Sax', NEWID())
Inserts a new row into the esqlSalesPerson. If you run the command again, another row is added, but the rowguid value is different.
Each time NEWID() is called, a different value is generated.
Identity Column Property
Whenever a row is inserted into a table with a identity column property, a new value is generated for that row’s column. Since esqlSalesPerson.SalesPersonID is an identity column, we don’t specify it in our INSERT statement. Each time a row is added, the identity value is incremented by one and added to the row.
If you try to insert a row using your own value, you’ll throw an error.
The INSERT statement:
INSERT INTO dbo.esqlSalesPerson
(SalesPersonID, City, FullName, rowguid)
VALUES (9999,'Traverse City', 'Donald Sax', NEWID())
Generates the error:
Cannot insert explicit value for identity column in table 'esqlSalesPerson' _
when IDENTITY_INSERT is set to OFF.
To get around this, you can SET IDENTITY_INSERT ON:
SET IDENTITY_INSERT esqlSalesPerson ON;
INSERT INTO dbo.esqlSalesPerson
(SalesPersonID, City, FullName, rowguid)
VALUES (9999,'Traverse City', 'Donald Sax', NEWID())
Runs with no errors thrown.
Default Values and Other
When inserting rows, any columns not specified are provided a value by the DBMS; otherwise the row cannot be loaded.
The DBMS automatically provides values for columns if:
- the column is an
IDENTITY column (see above) - a default value is specified. The default value is used if no other value is specified.
- the column is nullable, then it is set to
NULL - the column is computable, then the calculation is used
If a value isn’t provided by the statement and the engine is unable to provide a value, the row cannot be inserted. This typically happens with a value is missing and the column is NOT NULL.
Inserting Data from Other Tables
You can also use the INSERT statement to insert one or more rows from one table into another. One way this is accomplished is by using the results of a SELECT statement to provide values to the INSERT statement.
The general form is:
INSERT INTO targetTable
(column1, column2, …)
SELECT (column1, column2, …)
FROM sourceTable
Let’s assume the AdventureWorks sales manager would like to create a SalesPerson table and only include salespeople who’s last year’s sales were greater than $1,000,000.
To populate this table, you could run:
INSERT INTO esqlSalesPerson
(FullName, SalesLastYear, rowguid)
SELECT P.FirstName + ' ' + P.LastName, S.SalesLastYear, NEWID()
FROM Sales.SalesPerson S
INNER JOIN Person.Person P
ON P.BusinessEntityID = S.BusinessEntityID
WHERE S.SalesLastYear > 1000000
In order for this to work properly, the columns returned from the SELECT statement have to be in the same order as specified in the INSERT column list. In this example, notice that rowguid is a required field. To populate this value, we use the NEWID() function.
You can also use a common table expression to define the rows to insert. The example above, written as a CTE (Common Table Expression) is:
WITH topSalesPerson (FullName, SalesLastYear, rowguid)
AS (
SELECT P.FirstName + ' ' + P.LastName, S.SalesLastYear, NEWID()
FROM Sales.SalesPerson S
INNER JOIN Person.Person P
ON P.BusinessEntityID = S.BusinessEntityID
WHERE S.SalesLastYear > 1000000
)
INSERT INTO esqlSalesPerson
(FullName, SalesLastYear, rowguid)
SELECT FullName, SalesLastYear, rowguid
FROM topSalesPerson
Though there is more typing, I like the CTE method. I think it makes the INSERT statement easier to read.
Remember, when using SELECT statement to insert data into another table, it is best practice to first just run the SELECT statement as is to ensure you are selecting the correct rows. Also, always develop and test your code! I highly recommend using a development copy of your database.
The post Introduction to the INSERT Statement appeared first on Essential SQL.

