This is a show case of a dockerized Postgres to improve the coupling between versioned codebase and database schema.
Introduction
The article shows how Alice, the development manager, applies few techniques in her team giving some guarantees to Bob, the developer, to write code compliant to a given database schema, i.e., the field of a data object is also present as a column in a table. This approach is based on integration tests, Postgres dockerization, version control and database schema versioning. The reader can apply the ideas to other technologies like wsdl versioning or other database engines.
Background
I'm Alice and before introducing my approach, I clarify the meaning of few keywords I've used before.
First, what is an Integration test? It is the phase of software testing where two or more modules are combined and tested as a group. In this case, we want to test if our code is able to perform real database selections, i.e., all needed columns in a particular table are both in the schema and in the code. In a more complex scenario, it would sound like "we want to test if our data access layer is able to perform CRUD operations against the current datasource configured in the preproduction environment".
Second, what is a schema versioning? A good practice in software development is to keep code and schema strictly coupled, for this reason also, *.sql scripts should be versioned. In my team, we order them using a proper name (es. 0_1 -> 0_2 -> 1_0 -> ..., maybe using some semantic versioning convention) and we separate them between DML (data manipulation language) scripts and DDL (data definition language) scripts. One of the main benefits is that we can reproduce programmatically the schema wherever, i.e., in production, in a particular stage of the continuous integration pipeline, or ... in a dockerized database. :-)
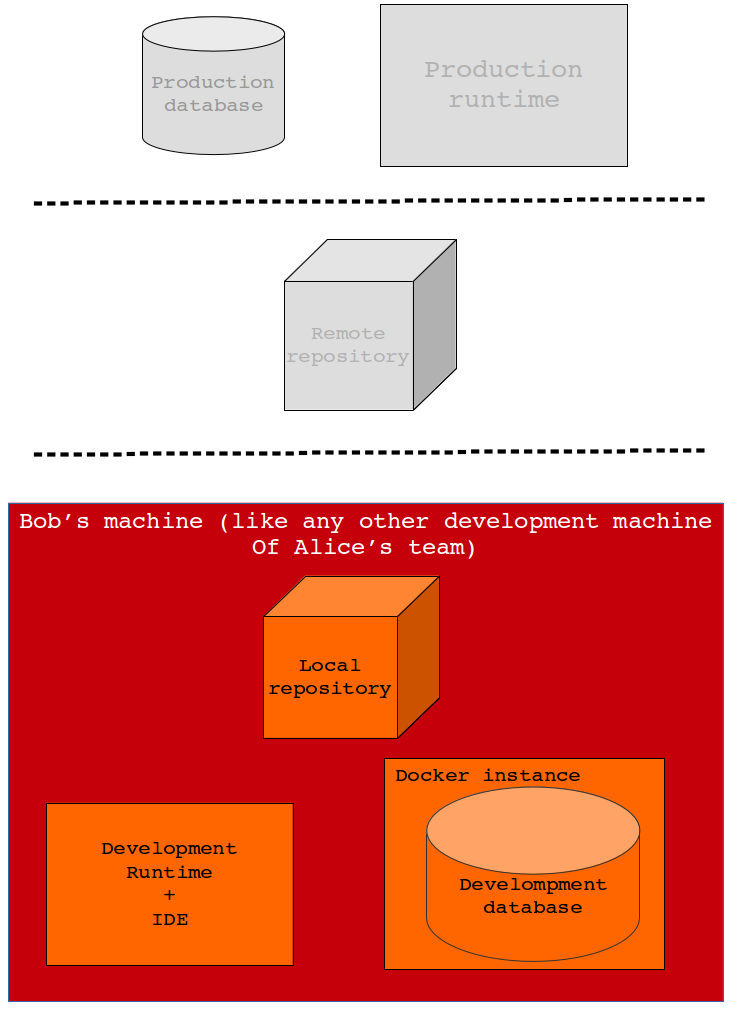
Third, what is a dockerized Postgres? You can think about it like a lightweight virtual machine that runs in your OS and that contains your Postgres database. You can start it, stop it, access it, configure it, distribute it and more important, you do this once, programmatically and in a centralized way!
Bob's Development Machine
I'm Alice again. In my team, we distribute this development machine configuration. As you can see, it is quite generic and the guys can still browse Facebook or read some tennis article. :-)
- Ubuntu 16.04 LTS
- jdk 1.8.0_111
- docker 1.12.5
- mvn 3.3.9
- git 2.7.4
Hi, I'm Bob, a software engineer. I'd like to speak a bit about my daily development activity. Once I've opened the project simple_db_reader in my IDE, I write some code. Before committing, I follow these steps:
- I run
sh ./docker_start_env.sh to start/restart my local postgres. This is nice since I don't need any database installation and all the *.sql scripts are located in simple_db_reader/sql and automatically executed in an alphabetical order. Also, I can access some table with my PgAdmin! This is great to test new scripts locally! - I compile and test my code performing a
mvn package. - I can run the jar with
mvn exec:java - If everything is fine, I push in some remote branch:
A Busy Working Day in Alice's Office
Alice: Few days ago, we released a first version in production (changeset da1d744). You can see it with the commands:
git checkout mastergit checkout da1d744sh ./docker_start_env.sh mvn packagemvn exec:java
Figure 2 and Figure 3 show da1d744 checkout in the whole git log and the relation between the code and the database schema:

Figure 2
Figure 3
In the meanwhile, the DBA asked for a change request about a database denormalization, dropping the table address and adding a new column zipcode in people. It is important to remark that the request has a great impact in the code so we need to modify the integration test AppTest.testDatabaseAccess to be sure that the codebase is still aligned with the new schema. A new branch addressesDenormalization is created and Bob is working on it
git checkout addressesDenormalization
Figure 4 and Figure 5 show addressesDenormalization in git log and the new database schema with the compliant codebase:
Figure 4
Figure 5
Suddenly, during development, we received a ticket from the help desk about a bug in production: the "HALLO world" print is not correct, it has to be changed in "Hello World! We have to hot fix production now". Bob, checks out da1d744, creates a new branch productionBugFixing, fixes the code and merges in the master ready to be deployed in production:
git checkout mastergit checkout 472daa4sh ./docker_start_env.sh mvn packagemvn exec:java
Checking out productionBugFixing (Figure 6), Bob can work in a code base aligned to the database schema in production (Figure 7). Also, since the ddl is versioned, he can locally replicate the database and develop in a safer way.
Figure 6
Figure 7
Alice: Hey Bob, I heard about your fix, are you confident the code is still compliant with the database schema in production? No sql.exception is going to be raised, right !?
Bob: Just before pushing, I performed the integration test pointing to the production database schema replicated by the local dockerized Postgres:
sh ./docker_start_env.sh mvn test
Alice: That's ok! We can release the fix in production (Figure 8) ...
Figure 8
... and you can carry on working in addressesDenormalization (Figure 9):
Figure 9
Bob: For this activity, I checked out addressesDenormalization, I added some ddl script to perform the denormalization, fixed the broken data layer code and performed my tests. I'm ready to merge in master (Figure 10).
Figure 10
Alice: Once again, I've seen you had conflicts in merging in master and I know your fix has few impacts. Can you test the master again?
Bob: Sure!
git checkout mastersh ./docker_start_env.sh mvn test
Dear Alice, I'm confident that you can tell the dba to run the new incremental *.sql and we can deploy the denormalization!
Alice: Fine... I let you know soon :-)
Points of Interest
Bob's point: With dockerization, I can set up my development environment easily, skipping all the painful details like database installation and configuration. Also, I can access and perform scripts locally avoiding annoying issues that usually come from a shared development environment. Also, since the *.sql scripts are also versioned, I'm confident to automatically replicate the related schema.
Alice's point: In the first stage of building up the development environment, we configured once a dockerized Postgres and shared it between the team. Everyone enjoyed a ready to go installation and we used a clone of the container in our continuous integration pipeline as well. Also, the practice to keep the database schema versioned has few advantages: we can rebuild from scratch all the time a particular snapshot coupled with a particular checkout of the codebase. This is useful when different environments are involved in the release life cycle. Yet, sharing those scripts, we can communicate formally with the dba and other colleagues avoiding dangerous misunderstandings. Finally, integration tests between the access data layer and the codebase pointing to a real instance of the database gives us a certain level of confidence on technical details like the jdbc driver or some table indexing.
History
- 13th March, 2018: Initial version

