Introduction
JSON is considered slow, like several times slower than protobuf/thrift/avro/...
https://github.com/ngs-doo/dsl-json is a very fast JSON library implemented Java, which proved JSON is not that slow.
http://jsoniter.com/ ported dsl-json codegen from .NET to Java (although, dsl-json is a Java library, the codegen is not). I also added a very sexy "Any" data type to lazy parse any JSON in weakly typed way (which will not be covered in this article, you check it out here.)
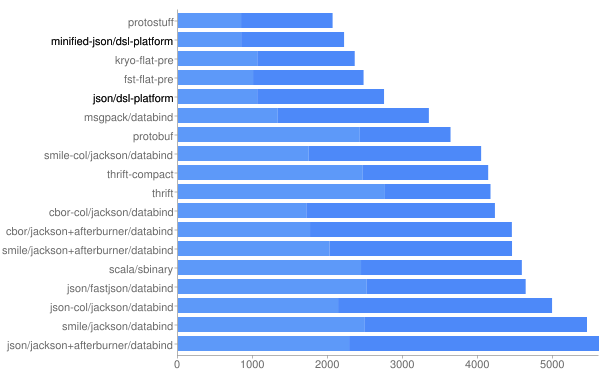
Serialization speed: https://github.com/json-iterator/jvm-serializers
- protobuf: 684
- thrift: 1317
- avro: 1688
- dsl-json: 471
- jsoniter: 517
De-serialization speed:
- protobuf: 448
- thrift: 734
- avro: 844
- dsl-json: 776
- jsoniter: 726
What is the secret of dsl-json that makes JSON even faster than thrift/avro? Isn't text protocol slow?
Optimization
There is no JNI or SIMD dark magic. JVM is still not a ideal platform for instruction level customization. Go might be a good choice to try some SIMD, for example: https://github.com/minio/blake2b-simd
The optimization is pretty straight forward:
- allocation less
- scan only once
- minimal branching
- fast path shortcut, optimize for 80% case
Jsoniter ported the implementation of dsl-json, so the following article will be based on jsoniter instead.
Single Pass Scan
All parsing is done within one pass directly from byte array stream. Single pass has two levels of meaning:
- On the large scale: the iterator API is forward only, you get what you need from the current spot. There is no going back.
- On the micro scale:
readInt or readString is done in one pass. For example, parse integer is not done by cutting string out, then parse string. Instead, we use the byte stream to calculate int value directly. Even readFloat or readDouble is implemented this way, with exceptions.
Related source code: https://github.com/json-iterator/java/blob/master/src/main/java/com/jsoniter/IterImplNumber.java
Minimum Allocation
Making copy is avoided at all necessary means. For example, the parser has an internal byte array buffer holding recent byte. When parsing the field name of object, we do not allocate new bytes to hold field name. Instead, if possible, the buffer is reused as slice (like go).
Iterator instance itself keeps a copy of all kinds of buffer it used, and they can be reused by reset iterator with new input instead of create brand new iterator.
Related source code: https://github.com/json-iterator/java/blob/master/src/main/java/com/jsoniter/IterImpl.java
Pull from Stream
The input can be a InputStream, we do not read all bytes out into a big array. Instead, the parsing is done in chunks. When we need more, we pull from the stream.
Related source code: https://github.com/json-iterator/java/blob/master/src/main/java/com/jsoniter/IterImplForStreaming.java
Take string Seriously
String parsing is a performance killer if it is not handled properly. The trick I learned from jsonparser and dsljson is taking a fast path for string without escape character.
For Java, the string is utf-16 char based. Parsing utf8 byte stream to utf16 char array is done by the parser directly, instead of using UTF8 charset. The cost of construct string, is simply a char array copy.
Related source code: https://github.com/json-iterator/java/blob/master/src/main/java/com/jsoniter/IterImplString.java
Covert string back into bytes is also slow. If we are sure the string is ASCII only, there is a faster way to do that using getBytes.
Related source code: https://github.com/json-iterator/java/blob/master/src/main/java/com/jsoniter/output/JsonStream.java
Schema Based
Iterator API is active instead of passive compared to tokenizer API. It does not parse the token out, then if branching. Instead, given the schema, we know exactly what is ahead of us, so we just parse them as what we think it should be. If inputs disagree, then we raise proper error.
If data binding is done using codegen mode, the whole decoder/encoder source code will be generated. We know exactly what to write first, what to write second. What to expect next.
Example generated code: https://github.com/json-iterator/java/blob/master/demo/src/main/java/encoder/com/jsoniter/demo/User.java
Skip Should Take Different Path
Skip an object or array should take different path learned from jsonparser. We do not care about nested field name or so when we are skipping a whole object.
This area can be further improved in language support SIMD: https://github.com/kostya/benchmarks/pull/46#issuecomment-147932489
Related source code: https://github.com/json-iterator/java/blob/master/src/main/java/com/jsoniter/IterImplSkip.java
Table Lookup
Some calculation such as what is int value for char ‘5’ can be done ahead of time.
Related source code: https://github.com/json-iterator/java/blob/master/src/main/java/com/jsoniter/IterImplNumber.java
Match Field by Hash
Most part of JSON parsing can be pre-defined by providing a class as the schema. However, there is no ordering of field names in JSON. So there must be a lot of branching when matching field. The trick used in dsl-json is hashcode. Instead of comparing field name string by string, it calculates the hash of field and does a switch-case lookup.
Match Field by trie-tree
hashcode is not collison free. We can add string equals after hashcode match, or we can do this:
public Object decode(java.lang.reflect.Type type, com.jsoniter.Jsoniter iter) {
com.jsoniter.SimpleObject obj = new com.jsoniter.SimpleObject();
for (com.jsoniter.Slice field = iter.readObjectAsSlice(); field != null;
field = iter.readObjectAsSlice()) {
switch (field.len) {
case 6:
if (field.at(0)==102) {
if (field.at(1)==105) {
if (field.at(2)==101) {
if (field.at(3)==108) {
if (field.at(4)==100) {
if (field.at(5)==49) {
obj.field1 = iter.readString();
continue;
}
if (field.at(5)==50) {
obj.field2 = iter.readString();
continue;
}
}
}
}
}
}
break;
}
iter.skip();
}
return obj;
}
}
Shortcut Path
We know most string is ASCII, so we can try to decode it as if it's only ASCII first. If it is not the case, we fallback to a slower way.
Related source code: https://github.com/json-iterator/java/blob/master/src/main/java/com/jsoniter/IterImplString.java
Lazy Parsing
If read JSON into Object or JsonNode, we read all the fields and elements. It will allocate a lot of memory and do a lot of computation. If we can deserialize only when we have to, the lazy parsing can save lot of unnecessary work.
This is the core idea behind "Any" data type. It essentially makes the forward only json-iterator random accessible.
Related source code: https://github.com/json-iterator/java/blob/master/src/main/java/com/jsoniter/any/ObjectLazyAny.java
Related source code: https://github.com/json-iterator/java/blob/master/src/main/java/com/jsoniter/any/ArrayLazyAny.java
Write As Much As We Can in One Call
One important optimization in JSON serialization is do not write byte by byte. write("{\"field1\":") is faster than write('{'), write("field1") then write(':').
If we know some field is not-nullable, we can combine its quote or [] into the one write call.
Related source code: https://github.com/json-iterator/java/blob/master/src/main/java/com/jsoniter/output/CodegenResult.java
Faster Number codec
SIMD can make this faster as well, sadly Java does not have it. But faster implementation than Integer.toString and Integer.valueOf is possible.
Related source code: https://github.com/json-iterator/java/blob/master/src/main/java/com/jsoniter/output/StreamImplNumber.java
Dynamic Class Shadowing
The input can be byte array or input stream. The decoding can be greatly simplified if only limited byte to process. However, we cannot assume we only process byte array. Normally, we would use virtual method to solve this problem. However, runtime dispatching via vtable is slow.
Like C++ template, Java has class and class loader to achive zero-cost abstraction. The class loading process can be injected with different class. We implement two classes, one IterImpl.class one IterImplForStreaming.class. At runtime, we decide which one is the one to use through class shadowing.
Related source code: https://github.com/json-iterator/java/blob/master/src/main/java/com/jsoniter/DynamicCodegen.java
Summary
Don't get me wrong, JSON is a slower text protocol than binary protocols. JSON implemention and binary protocol implementation is a different story. Without careful optimization, binary protocol can be slower, even in theory, it should be much faster. With current implementation in the Java world, other options are not "significantly" faster than JSON.
Java is missing the SIMD support, which makes me wonder will SIMD makes JSON faster? Will SIMD make protobuf/thrit/avro even faster? Go can be a really good language to try things out. Looking forward to that.

