Introduction
Years ago, I worked for a telecom company in England. This was just at the time when the telecom market re-invented the snake oil business. Money was pouring into these companies, and we had the chance to work on some amazing HP-UX machines to create systems for network management. This basically meant providing a GUI based front end, with multiple processes running asynchronously in the background, all doing their communicating via IPC, and all doing clever and complex stuff with multiplexors and other telecoms kit out in the street.
It was a great time, our customers, other telecoms companies like us, could control their whole infrastructure from a single room, and the day of the man with a screwdriver and a van out in the street changing multiplexors were finally over! But, just as the aforementioned man with the van left, just as he closed the door on us, he muttered two words that eventually ground everything in my department to a halt..."combinatorial explosion...", well I definitely heard the word explosion anyway.
Background
Combinatorial explosion is a state that an OO design can get in. It's caused when designers of OO hierarchies over design. They end up with too many classes in hierarchies, as they believe that extending a system should just be about adding new classes, with just a little bit of extra code. Code that is so obvious to write, that it will reduce bugs and ambiguity, thus improving quality. They also thought they could force the software engineers to implement correct code because they were bound by strict contracts. So any time a new type of something needed to be managed, simply drop in a few classes, the engineers could infer from the class names the exact behaviour, and boom! A Miracle Gro software solution with a tenth of the dev budget, meaning QA can go back to being a hand full of testers, as no existing classes would be touched, so very little regression testing was needed.
This type of strict, overbearing design, is great for programmers. They can infer from the type that they are coding in (the class name) exactly how that class should behave, i.e., I am in the pushbutton telephone class, therefore my function to draw the buttons will do this, and when I am in my dial telephone class, my draw function will do that, nice and easy. But when inserting another type of base class, it can result in you having to implement a whole sub set of derived classes for your design to carry on working, especially if you make them full of abstract functions (pure virtuals in C++, or functions with no implementation, part of an interface - a contract basically).
Real Life Situation
So in the aforementioned telecoms company, we had OO modeled our multiplexors and their environment. We had a GUI based app that had a class for each type of multiplexor we sold. We had many multiplexors, and they could have different firmware on them. Each multiplexor was a fixed type, so it couldn't be migrated from one type to another. This was great, as no migration strategy was needed of persistent OO classes for the mux type. But the firmware could be upgraded, so we did have some migration to perform. The firmware type sat on the mux controller card in real life, but we thought that because there was only one mux controller card per multiplexor, the firmware type could just be an attribute of the Mux class, besides it saved another level of function indirection, going through a Mux->Card call to get the firmware type, we could now know directly in the Mux class the firmware type. Now let's talk about the classes we started with.
We had a base class called Mux, then SDH and PDH derived from this. These were two methods for sending network data traffic. From these two base classes, we had our concrete classes, i.e., SMA1, SMA4, SMA16, etc. However, soon enough (a year or so), we realised we had lots of C++ software switches on the firmware type in the code. So, for example, a typical function would look like this:
void SMA1::Draw()
{
if (firmware.IsA1.0() == true)
{
drawNormal ();
}
else if (firmware.IsA2.0() == true)
{
drawDoubleThick();
}
else if (firmware.IsA3.0() == true)
{
drawTrebleThick();
}
}
So the Draw function would have conditional logic that would draw the cards normally for firmware 1.0, twice as wide if it had firmware 2.0, and three times as wide for 3.0. Obviously, this is just an example, the code wasn't that simplistic (we used switches - haha that's a joke !).
It's easy to look at this function and say "Wow ! that's awful code", but this code crept into this state. New people joining the team, they grep for 1.0:
grep 1.0 *.cpp > work_to_do_for_new_firmware_type.omg
grep 1.0 *.h >> work_to_do_for_new_firmware_type.omg
All the functions with switch on firmware type would be extended, another case for the switch statement or putting an || (or) in the if statement (if the new firmware behaved the same as an existing one.) Remember someone didn't write this function all at the same moment in time.
The way the company operated was typical of a hardware manufacturer. Bear in mind that when firmware 3.0 came along, we in the software management team had a month to add support for it. The firmware team released new versions of firmware almost every month, driven by an insatiable marketing vision and peer pressure. The hardware team bought out new hardware every year, as it was much more expensive and risky to create new products altogether, better to extend existing ones. New products required management risk, and as we all know that doesn't happen much, better to stick with no risk, as even though there is no reward, there is no failure, right?
So new features were mostly added in firmware (if they could be), and if we didn't manage those new features in the software management team, then the customer didn't see any benefit from spending any more money, and our sales team couldn't drive profits up for Mr Shareholder (who basically was sitting on a billion dollars of worthless pyramid scheme paper). So we had a job to do, and quickly. So we did it, and eventually all our functions looked like the one above.
Just to remind you that the firmware was an attribute of the base MUX class.
Here is what our design looked like:
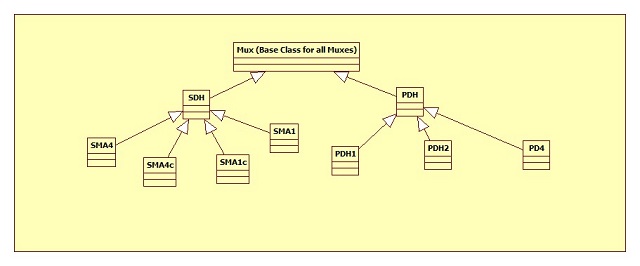
"So let's refactor!", we cried in unison, not literally cried of course, no, that came a bit later.
We took out the firmware attribute type altogether, because we decided we would use more of OO the way it was intended. The class would tell us the type, we didn't need to have code that was conditional and ask the type, we could infer what we were by where we were writing the code. So in essence, if I was in the class SMA1, I knew I was an SMA1, so let's do things accordingly. We changed the design to add what we thought was an acceptable number of classes. Now our hierarchy looked like this (this is just a sub-set for brevity):

So we had new classes hanging off the SMA1, SMA4, SMA4c and SMA1c. And as we had all our functions virtual, Draw became overridden specifically for new firmware types. So the SMA1_FIRMWARE_VERSION::Draw functions became:
void SMA1_1.0::Draw()
{
drawNormal ();
}
void SMA1_2.0::Draw()
{
drawDoubleThick();
}
void SMA1_3.0::Draw()
{
drawTrebleThick();
}
Wow, look at how we reduced the amount of conditional code. This was super clean, and everyone did rest for the day, and take solace, etc...
To instantiate our classes, we had factory functions.
Then this happened:
"What does this guy want?"
"He has come bearing good news, we have been so successful we are releasing lots of new products called SMA32, SMA64, VCTS2, VCTS4. And there will be three new firmware types this quarter, and they are splitting the mux controller card, that means they can have a dual firmware mode."
Hahaha, so we would now have to have this hierarchy (again, I'm not spending 4 hours drawing all of it):
Note that for brevity, I have left off all lots of concrete classes (you can figure out which ones), I've demonstrated the concept with the use of the SMA4c derived classes. Only a fool would fill in the rest, and we did. We had crossed the Rubicon, Alea iacta est! There was no going back, the die was cast!
Two years later, we had another six types of multiplexor, and we now had roughly 15 firmware types, so our hierarchy looked like this:
Ok, get the picture? Yes the code did work, but surely this wasn't the way to KISS - "Keep IT Simple Stupid"? Was it?
The Theoretically Right Thing to Do in This Situation
Big chapter headings always make me curious. The books we pondered over next told us to avoid deep hierarchies! In fact, Zarathustra shouted out "Avoid inheritance as much as you can. Favour composition", said he, "Favour?" said I back.
So we analysed, and came up with the next solution. Take out all these classes, go back to having the Mux specific code into a Mux hierarchy, and have the firmware specific code in a separate hierarchy, and use composition. Go from a ISA to a HASA. So the Mux class has a firmware version, whereas before we had a Mux ISA firmware version (and a mux version).
So the hierarchy looked like this:
We had a much smaller design, and had successfully decoupled our bad design from mux type and firmware type amalgamated, splitting it into firmware and mux type independent hierarchies. The amount of coupling was not high, as were delegating the firmware specific code to the firmware hierarchy (imagine if we went back to saying Is1.0() inside the mux classes again! Back to square 1). The draw function became:
void SMA1::Draw()
{
firmware->Draw();
}
We had factory functions that would build the mux type and with it, the firmware type dependent on a passed in string from the users choice in the GUI. So our constructor would flow like this:
SMA1::SMA1(string firmwareType)
{
if (firmwareType=="1.0")
{
firmware = new firmware1_0();
}
}
So we now had two hierarchies.
Reality Sucks
Obviously, I would be lying if things were that simple, right? Yes, so let's save my reputation, and discuss the next set of problems. We found that in reality, some things were a combination of mux type and firmware, so for example, a SMA1 LED was blue for firmware 1.0, green for firmware version 2, and for an SMA4 LED, it was yellow and white respectively. So we couldn't have a function in the firmware hierarchy like this:
colour SMA1::GetColourLED()
{
if (Firmware() == 1.0)
return colour::Blue;
else if (Firmware() == 2.0)
return colour::Green;
etc.
}
Or this!
colour Firmware1_0::GetColourLED(
{
if (GetMuxType() == SMA1)
return colour::Blue;
else (GetMuxType() == SMA4)
return colour::Green;
}
As this would push us back to the original problem.
We knew we had to have another hierarchy for these things, so we tried to take a step back and say, "Well, are the colours for something other than the type of the mux or firmware?" And often, these types of things were, so we had an LED hierarchy. For example, the LED colour really represented the traffic speed, it just so happened the green and blue (2Meg and 4Meg) were on the SMA1 1.0 and 2.0 firmware respectively. And so, we modeled the colours based on that, network traffic speed. You get the picture.
And so hereth endeth the tale of the explosion of classes in the telecoms management system. I should say this was around 1989, so things were a little different then, we were using Shlaer–Mellor (before UML came along), and it was a nascent industry ready for making mistakes. In the end, we were good engineers and ready to admit we made big mistakes. But really, the biggest problem was probably believing two other groups of people:
Marketing and Sales - "There won't be any more new firmware releases. We are going to settle for just one per year, so basically only when a new piece of hardware comes out."
Our Management - "Don't worry, we can throw all this in the bin in 3 months, and we can remodel that whole part of the system, just stick in this one last new Mux type."
The moral of the tale? If something looks 50 times bigger than it should be, it probably is.
Thanks for reading!
History
- 22nd January, 2017: Initial version

