Table of Contents
Introduction
In this article, we will start with a brief overview of the Lambda Architecture design and principles for building real-time data-processing systems. Then we will design a simple analytics system with desirable properties of the Lambda Architecture. Our analytics system will be hosted on the Azure cloud and utilize such Azure services like HDInsight, Azure Redis, Azure Service Bus and other. After that, we will deploy the system to the cloud and perform integration test for the main scenario. Finally, we will make a conclusion about applied design approach.
Source Code
The source code is available on GitHub.
Lambda Architecture Overview
The Lambda Architecture stands to the fact that there's no single tool or technology in building robustness, fault-tolerant, scalable system that can produce analytics results close to real time. Instead of a single tool, the Lambda Architecture approach suggests to split the system into three layers: batch, speed, and serving layers. Each layer uses an own set of technologies and has own unique properties.
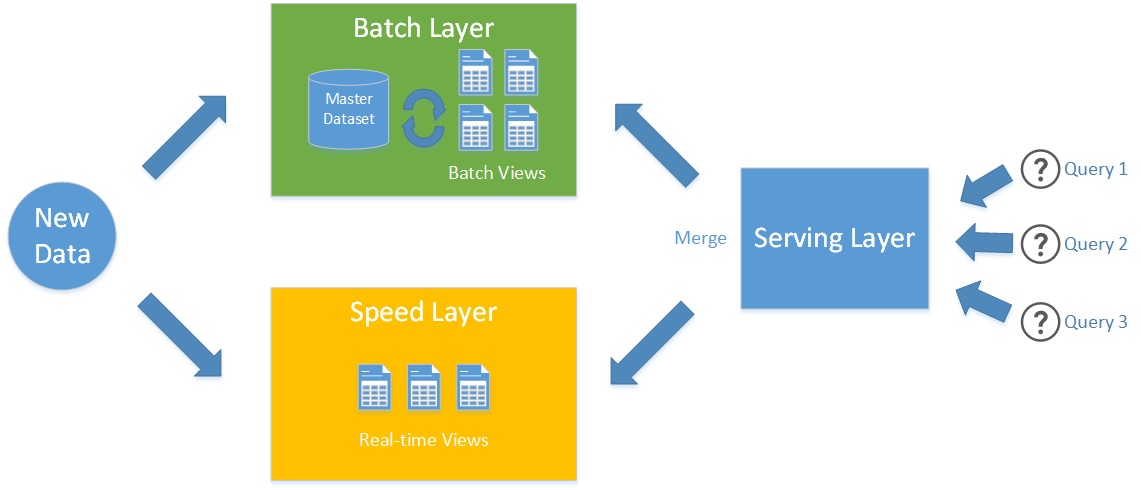
Batch Layer
The batch layer does two main things in fact: appends new incoming data into the single storage called master dataset and executes long-running, heavy calculations against the entire master dataset.
The master dataset can be represented by a database or distributed file system in which the batch layer adds new records. The batch layer never overrides existing records with latest, instead, it keeps all of them. It's important property called immutability and it allows to robustly discourage errors and data corruption.
The other responsibility of the batch layer is constant recomputation of entire master dataset and providing batch views - data structures with low read latency which can be used to answer on incoming user's queries.
Speed Layer
The speed layer precomputes incoming data every time when a new bit of data appears. In contradistinction to the batch layer, the speed layer doesn't recalculate entire master dataset, instead, it uses an incremental approach. The result of the speed layer precomputation is called real-time view.
Difference between Batch and Stream Processing
To understand a difference between batch- and stream- processing, let's calculate an average value of a stream of numbers: 1,4,6,12,17. The batch processing according to description should persist all stream numbers into the array [1,4,6,12,17] and then compute average for the entire array: (1+4+6+12+17) / 5 = 8.
The stream processing calculates average every time when a new number appears. We can use following formula: realtime_avg = (realtime_avg * n + x)/(n + 1),
where
realtime_avg - initially equals to 0 and keeps current average value for input stream
n - number of processed numbers
x - current incoming number from a stream.
For our example,
when number 1 appears realtime_avg = (0*0+1)/(0+1)=1 , n=1
when number 4 appears realtime_avg = (1*1+4)/(1+1)=2.5, n=2
when number 6 appears realtime_avg = (2.5*2+6)/(2+1)=3.66666[6], n=3
when number 12 appears realtime_avg = (3.66666[6]*3+12)/(3+1)=5.75, n=4
when number 17 appears realtime_avg = (5.75*4+17)/(4+1)=8, n=5
As you can see, finally both the batch and stream processing produced the same result equals 8. The difference is that batch processing doesn't provide intermediate results when the speed layer does for each new incoming number.
Serving Layer
Because batch layer supposed to be slow and can be behind the speed layer on minutes or even hours, the Lambda Architecture supposes one more layer - serving layer that merges result of batch and speed layer computations. This way the serving layer can provide the most actual computation results.
Properties of Lambda Architecture
The properties listed below emerge naturally from the Lambda Architecture design approach.
- Robustness and fault tolerance - the system is tolerant to machines failure and human mistakes like data corruption. The batch and real-time views can be always recomputed from the master dataset.
- Low latency read and update - the Lambda Architecture allows to achieve both without compromising robustness.
- Scalability - all layers can be scaled independently.
- Generalization - Lambda Architecture can be used across a large number of different applications.
Meetup Analytics Demo
As far as we already know, the Lambda Architecture allows us to get best of two worlds: batch and stream processing and it can be effectively used in building real-time data-processing systems. Now, time to go deeper into the Lambda Architecture details and we will try to implement a simple data analytics system.
First of all, we need to find a stream of data to analyze. A brief googling led me to a publicly available API of Meetup events stream (here's visualization of the stream: http://meetup.github.io/stream/rsvpTicker). The Meetup is a service allowing people to organize meetings with similar interests and discuss topics like sport, learning, photography etc. The service provides public API with streaming information about people who planning to visit a meeting in particular location. Once somebody applied to the meeting via mobile or web application, the information becomes available in the stream almost in real time.
Now, we will design a data-processing system which can analyze how many people going to visit a Meetup event in London, and, for sure, our design will be based on Lambda Architecture. Let's start designing each layer considering following example:

In the example, we can see a timeline with four Meetup messages - 4 users decided to visit the event in London.
The design of batch layer for that problem is pretty straightforward: the system should persist each user message into the data storage and continuously run a job that aggregates all messages in the storage by event ID and location. In the example above, aggregation occurred at 08:01:00 and produces a batch view which includes a time when aggregation finished and a number of people planning to visit the event: 08:01:00 and 3.
The speed layer uses fully incremental approach and just increments a counter of the visitors when a new person applied to the event. But instead of having a single counter for each event and location, we will group incoming requests into time baskets and keep counters for each basket. The size of the time basket can vary depending on the system load. For our example let's choose the size of the basket equals 1 minute. As you can see from the picture, when the Meetup Analytics system receives a query there are two baskets in speed layer: the first 08:00:00-08:01:00 basket keeps value 3, and the second 08:01:00-08:02:00 - value 1.
To answer the question "How many people going to visit the event in London?" at 08:02:30, the serving layer just uses results of both batch and speed layers computations. Firstly, the serving layer load batch view - "3 people were planning to visit the event till 08:01:00" and then the serving layer have to load all baskets from last batch aggregation (08:01:00) till now (08:02:00). In our example, there is only one basket satisfying that condition - the basket 08:01:00-08:02:00 with value 1. Merging value 3 from the batch layer with value 1 from the speed layer, the serving layer responds 4 - the closest to real-time information about the number of event visitors.
Choosing Azure Service for Meetup Analytics
It's time to bring the idea described in the previous section to a life. We need to choose tools and technologies for each layer of our system and, as you could already guess, we will use Azure cloud and services. For sure, it could be a different combination of Azure services with own pros and cons in solving the particular problem, but I stopped on following set considering service reliability, scalability, extensibility, and applicability in terms of Lambda Architecture design.
Infrastructure
- Azure Service Bus (1) - message broker which guarantees reliable message delivery to both batch and speed layer.
- Service Fabrik - responsible for publishing services on Azure instances and scaling
- ARM templates - infrastructure for deployment the Meetup Analytics system to the Azure cloud
Batch Layer
- HDInsight Blob Storage (3) - distributed file system (Hadoop), represents master dataset of the Meetup Analytics
- Hive (2) - allows run Hadoop job and perform intensive aggregations against a data in HDInsight Blob Storage using SQL-like syntax
Speed Layer
- Redis (4) - in-memory, key-value, NoSQL data storage with fast read and write operations
Serving Layer
- Represented by simple REST service (5) which publicly available for user's requests
Batch Layer Implementation
As you can see from the diagram above, the batch layer service listens to the Azure Service Bus topic and persists all incoming messages to blob storage container(MasterDataset container):
CloudBlobContainer container = blobClient.GetContainerReference(storageConfiguration.MasterDataSetContainerName);
CloudBlockBlob blockBlob = container.GetBlockBlobReference(
$"meetup_{DateTime.UtcNow.ToString("yyyyMMddHHmmss")}_{Guid.NewGuid()}");
await blockBlob.UploadTextAsync(JsonConvert.SerializeObject(message));
Each message is stored as JSON text in separate blob instance. The following Hive query allows mapping unstructured data in blob storage container to logical Hive table - MeetupMessages.
DROP TABLE IF EXISTS MasterDataset;
CREATE EXTERNAL TABLE MasterDataset (textcol string) STORED AS TEXTFILE LOCATION '%path-to-master-dataset-in-azure-blob-storage%';
DROP TABLE IF EXISTS MeetupMessages;
CREATE EXTERNAL TABLE MeetupMessages
(
json_body string
)
STORED AS TEXTFILE LOCATION '/a';
INSERT OVERWRITE TABLE MeetupMessages
SELECT CONCAT_WS(' ', COLLECT_LIST(textcol)) AS singlelineJSON
FROM (SELECT INPUT__FILE__NAME, BLOCK__OFFSET__INSIDE__FILE, textcol FROM MasterDataset DISTRIBUTE BY INPUT__FILE__NAME SORT BY BLOCK__OFFSET__INSIDE__FILE) x
GROUP BY INPUT__FILE__NAME;
Now MeetupMessages table contains all JSON Meetup messages and can be used as a source for aggregating messages by event ID and location. Following Hive query creates external table 'Result' in Azure Blob Storage and populate it with information about the number of visitors:
DROP TABLE IF EXISTS Result;
CREATE EXTERNAL TABLE Result (aggTimestamp string, count int)
PARTITIONED BY (rsvp_id string, group_country string, group_city string)
STORED AS TEXTFILE
LOCATION '{azure-blob-storage-url}';
INSERT OVERWRITE TABLE Result
PARTITION (rsvp_id, group_country, group_city)
SELECT ‘{job-execution-time}' as aggTimestamp
,Count(*) as count
,GET_JSON_OBJECT(MeetupMessages.json_body,'$.rsvp_id') as rsvp_id
,GET_JSON_OBJECT(MeetupMessages.json_body,'$.group.group_country') as group_country
,GET_JSON_OBJECT(MeetupMessages.json_body,'$.group.group_city') as group_city
FROM MeetupMessages
WHERE GET_JSON_OBJECT(MeetupMessages.json_body,'$.mtime') < ‘{job-execution-time}'
GROUP BY GET_JSON_OBJECT(MeetupMessages.json_body,'$.rsvp_id'),
GET_JSON_OBJECT(MeetupMessages.json_body,'$.group.group_country'),
GET_JSON_OBJECT(MeetupMessages.json_body,'$.group.group_city');
Speed Layer Implementation
Starting to implement the speed layer, we need to think not only how to save each new portion of data, but also about how we're going to query precomputed real-time views. That's why we will keep 2 Redis sorted sets updated. The first sorted set(counter sorted set) will keep time baskets with a number of meetup visitors, for example:
Sorted Set
| Key | Member | Score |
| ---------------------------------------------- | --------------------------- | ------------ |
| counter_event1_UK_London | 635872320600000000 | 3 |
| | 635872320600000010 | 1 |
It would seem that sorted set contains all required analytics information: time baskets per event and location with a number of visitors. The reason for having the other sorted set is that serving layer should query only baskets which were created after batch view computation. To filter only latest baskets, we can use Redis ZREMRANGEBYLEX command that requires scores in the sorted set be equal 0 to return the correct result. So we will have the other sorted set with baskets (baskets sorted set), apply ZREMRANGEBYLEX command to it and intersect result with the counter sorted set.
As you noticed, the counter and baskets sorted sets must be always synchronized, that's why updating of both sorted sets must be wrapped in Redis transaction. Finally, we got following speed layer implementation:
public async Task ProcessMessageAsync(MeetupMessage message)
{
DateTime messageTime = new DateTime(message.Timestamp.Year, message.Timestamp.Month, message.Timestamp.Day, message.Timestamp.Hour, message.Timestamp.Minute, 0);
long basket = messageTime.Ticks;
string counterKey = $"counter_{message.EventId}:{message.Group.Country}:{message.Group.City}";
string basketsKey = $"basket_{message.EventId}:{message.Group.Country}:{message.Group.City}";
IDatabase db = _multiplexer.GetDatabase(_redisConfiguration.Database);
ITransaction transaction = db.CreateTransaction();
transaction.SortedSetIncrementAsync(counterKey, basket, 1);
transaction.SortedSetAddAsync(basketsKey, basket, 0);
await transaction.ExecuteAsync();
}
Serving Layer Implementation
The serving layer is public API that handles queries. Meetup Analytics serving layer can answer the question: How many people are planning to visit the event in particular location. To answer the question, the serving layer should load the latest batch view from Azure Blob Storage:
string batchViewKey = $"data/batchviews/rsvp_id={meetupId}/group_country={country}/group_city={city}";
CloudBlobContainer container = _blobClient.GetContainerReference(batchViewKey);
CloudBlockBlob blob = container.GetBlockBlobReference(_blobName);
string text = blob.DownloadText();
var tuple = text.Split(new[] { "\u0001" }, StringSplitOptions.RemoveEmptyEntries);
double time = double.Parse(tuple[0]);
long from = time.UnixTimeStampToDateTime().Ticks;
long batchLayerResult = long.Parse(tuple[1]);
and fetches a number of visitors from the speed layer:
string redisCounterKey = $"counter_{meetupId}:{country}:{city}";
string redisBasketKey = $"basket_{meetupId}:{country}:{city}";
string resultKey = "analyticsResult";
var db = _multiplexer.GetDatabase(_redisConfiguration.Database);
long speedLayerResult =
(long)db.ScriptEvaluate(LuaScript.Prepare(@"
redis.call('ZREMRANGEBYLEX', @redisBasketKey, '[0', @value);
redis.call('ZINTERSTORE', @resultKey, 2, @redisBasketKey, @redisCounterKey);
local sum=0
local z=redis.call('ZRANGE', @resultKey, 0, -1, 'WITHSCORES')
for i=2, #z, 2 do
sum=sum+z[i]
end
return sum"),
new
{
redisBasketKey = (RedisKey)redisBasketKey,
resultKey = (RedisKey)resultKey,
redisCounterKey = (RedisKey)redisCounterKey,
value = (RedisValue)$"[{from - 1}"
});
The merge operation of batch and speed layer results is just a sum of both:
long sum = batchLayerResult + speedLayerResult;
Let's Test It
Now, time to cover described Meetup Analytics scenario with automated test. We will write an integration test that requires all databases and Azure services published on the cloud, but batch, speed and serving layer classes running in a single process on a local machine.
[Fact]
public void Should_Merge_BatchAndSpeedLayerViews()
{
var meetupEventId = 1;
MeetupMessage meetupLondon1 = CreateMeetupMessageFromTemplate(meetupEventId,
new DateTime(2016, 01, 01, 08, 00, 10),
"UK", "London");
MeetupMessage meetupLondon2 = CreateMeetupMessageFromTemplate(meetupEventId,
new DateTime(2016, 01, 01, 08, 00, 20),
"UK", "London");
MeetupMessage meetupLondon3 = CreateMeetupMessageFromTemplate(meetupEventId,
new DateTime(2016, 01, 01, 08, 00, 50),
"UK", "London");
MeetupMessage meetupLondon4 = CreateMeetupMessageFromTemplate(meetupEventId,
new DateTime(2016, 01, 01, 08, 01, 40),
"UK", "London");
StreamProducer producer = new StreamProducer(DeploymentConfiguration.Default.ServiceBus);
producer.Produce(meetupLondon1);
producer.Produce(meetupLondon2);
producer.Produce(meetupLondon3);
producer.Produce(meetupLondon4);
var streamLayerConsumer = new SpeedLayer.MeetupMessageConsumer(
new MeetupStreamAnalytics(DeploymentConfiguration.Default.Redis),
DeploymentConfiguration.Default.ServiceBus);
while (streamLayerConsumer.ProcessedMessagesCount != 4) { }
var batchLayerConsumer = new BatchLayer.MeetupMessageConsumer(
new MeetupRepository(DeploymentConfiguration.Default.Storage),
DeploymentConfiguration.Default.ServiceBus);
while (batchLayerConsumer.ProcessedMessagesCount != 4) { }
RecalculationJob job = new RecalculationJob(
DeploymentConfiguration.Default.Storage,
DeploymentConfiguration.Default.HDInsight);
job.Execute(new DateTime(2016, 01, 01, 08, 01, 00));
long count = new MeetupQueries().GetAllMeetupVisitors(1, "UK", "London");
Assert.Equal(4, count);
}
Conclusion
We've done well designing our real-time system using Lambda Architecture. We managed to integrate many different services and tools like Redis, Hive, Hadoop, Azure Service Bus into the single data processing solution. We used a bulk of languages: C#, LUA, HQL (Hive SQL) in those places where they're fit the best. And we even tested happy path scenario with automated, integration test.
Earlier, we talked about properties that Lambda Architecture possesses. Now, let's validate whether Meetup Analytics system has all of them.
- Robustness and fault tolerance. The Meetup Analytics is totally tolerant to machine instance failures, 99% SLA guaranteed by Azure cloud for HDInsight cluster, Redis cluster and other VMs and services we used.
As you might know, Redis is an in-memory database and there is always exists a possibility of loosing the data in Redis - it's a price Redis developers paid for high performance. But Meetup Analytics design can handle even such awful case automatically. If speed layer lost all the data, the system will return result of batch layer computation and once speed layer is up and running again it will continue populate time baskets with visitor counters.
The other point of failure in the system - message delivery to batch and speed layers. There are following possible cases:
- Message was delivered to batch layer, but failed in delivering to speed layer. In this case, speed layer will return inconsistent value of visitors until batch layer finished recomputation and overrides speed layer computation.
- Message was delievered to speed layer, but failed in delivering to batch layer. In this case, the message considered as lost forever, because it was not added to the master dataset.
- Low latency read and update. Redis database in speed layer provides both: low latency read and update for Meetup Analytics operations. But batch layer provides robustness of the system.
- Scalability. Each layer of Meetup Analytics can by scaled independently and automatically. Each data storage supports clusstering by design.
As you could notice the Lambda Architecture supposes solving of the same problem twice: using batch and incremental approach.
That's it. I hope you found this article and provided code examples usefull and interesting.
References

