What is Serverless Framework?
Serverless Framework refers to building stateless function that does not have dependency on base operating system or hardware resources. It lets developers focus on building stateless functions without worrying about how to provision and scale resources.
Serverless functions are stateless, event-driven and executed in container. With Serverless functions, you are charged as per Pay As You Go Model (PAYG), i.e., you don't have to pay for idle resources. You only pay for each request when code is executed.
When to Use Serverless Framework
Serverless functions are useful in scenarios when you want to reduce operational cost, deployment complexity, use benefits of Auto Scaling, quick time to market.
For example:
- You want to build a micro service that will generate a Usage report on Request.
- You want to trigger a back end / computational operation on a specific event such as records inserted in
Dynamo DB Table. - You want to quickly develop and deploy a file processing service.
Refer to AWS Documentation for More scenarios.
** While Serverless functions are a good choice for stateless functions, one should make a conscious decision considering various business, technical parameters and limitations of Serverless framework. Not all applications can be developed using Serverless Framework.
AWS Lambda and Programming Language Options
One of the most popular options available today for building Serverless functions is AWS Lambda. AWS Lambda was introduced in 2014 with support for Node.Js, Java and Python Programming language.
Last year in December 2016, AWS announced support for developing lambda functions using C# Programming language on .NET Core 1.0 Run time. This allows .NET Developers to leverage their C# skills for building Serverless functions.
I will walk you through a simple event registration function developed using AWS Lambda and C#. But before getting started, let's understand programming model concepts of AWS Lambda.
Function Handler: Function Handler is an entry point to start execution of the lambda function. It takes input data as first parameter and lambda context as second parameter. If you have long running computation task, you can take advantage of Async lambda functions. Refer to AWS Lambda Developer Guide for more details.
Context Object: Context object is passed as second parameter to handler. Context object provides useful information about AWS Lambda run time. This could be used within function to control the execution of AWS function.
Logging: A properly designed function should have appropriate logging mechanism. AWS Lambda writes all logs to Cloud Watch. which could be used for analysis / troubleshoot if required. There are three ways to write logs in AWS function:
- Using
Console.write or Console.writeline method - Using
Log method of the Amazon.Lambda.Core.LambdaLogger class - Using
Context.Logger.Log method
Exceptions: In the event of an unhandled error, an exception is sent back in Payload and logged to CloudWatch. You can look through exceptions logged by function in cloud watch.
Let's Get Started
Step 1
Install AWS Toolkit for Visual Studio. You can find AWS toolkit for Visual Studio at https://aws.amazon.com/visualstudio/.
Step 2
Create New AWS Lambda Project (.NET Core) and Choose Empty Function Blue Print. it will create project and include FunctionHandler in Function.cs.
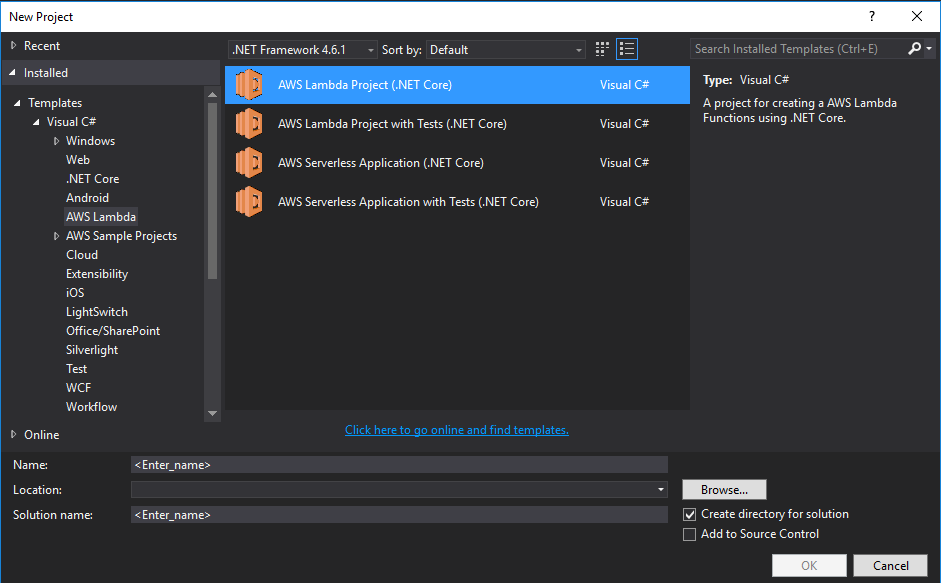

Step 3
Install AWSSDK.DynamoDBV2 and AWSSDK.Lambda using Nuget Package Manager or by editing Project.JSON File.
{
"title": "Title",
"description": "Description",
"version": "1.0.0-*",
"buildOptions": {},
"dependencies": {"Microsoft.NETCore.App": {"type": "platform","version": "1.0.0"},
"Microsoft.Extensions.Configuration.Json": "1.1.0",
"Amazon.Lambda.Core": "1.0.0*",
"Amazon.Lambda.Serialization.Json": "1.0.1",
"Amazon.Lambda.Tools": {"type": "build","version": "1.2.1-preview1"},
"AWSSDK.DynamoDBv2": "3.3.2.1",
"AWSSDK.Lambda": "3.3.2.6"
},
"tools": {"Amazon.Lambda.Tools": "1.2.1-preview1"},
"frameworks": {"netcoreapp1.0": {"imports": "dnxcore50"}
}
}
Observe the below Assembly attribute created by Empty Function Template. It is self explanatory from the comment. It is basically required to Serialize Input / Output parameter of Lambda Function:
Step 4
Write Logic in FunctionHandler (i.e., Entry point for Lambda Function)
In the below example, I am creating a registration table in DynamoDB if it does not exist. And then, insert record. Basically, on first request to lambda function, a table will be created before inserting record and on every subsequent request, records will be inserted in table. (In real world scenario, you may already have a table.)
In order to establish a connection with DynamoDB, you need to specify accessKey, secretKey and service URL. While developing .NET applications, we all maintained connection strings and other configurable information in configuration files so that we don't have to change code and we can point same code to Dev, Staging or Production.
AWS Lambda has got concept of Environment Variables. You can set all your configurable values in Environment Variables at the time of deployment and then access those variables using System.Environment.GetEnviornmentVariable method. It took me a while to figure out how to pass configurable values to C# Lambda Function. Initially, I thought lambdaContext will hold configuration information but letter on discovered Environment variables are accessible through System.Environment. GetEnviornmentVariable method:
public Function()
{
_accessKey = Environment.GetEnvironmentVariable("AccessKey");
_secretKey = Environment.GetEnvironmentVariable("SecretKey");
_serviceUrl = Environment.GetEnvironmentVariable("ServiceURL");
}
The below code is the function handler that accepts Customer POCO Object (having Name and EmailId members) as first parameter and Lambda Object Context as second parameter. Earlier, I explained different ways to log to cloud watch. I have used all three methods in the below code:
public async Task FunctionHandler(Customer customer, ILambdaContext context)
{
Console.WriteLine("Execution started for function - {0} at {1}",
context.FunctionName , DateTime.Now);
var dynamoDbClient = new AmazonDynamoDBClient(
new BasicAWSCredentials(_accessKey, _secretKey),
new AmazonDynamoDBConfig { ServiceURL = _serviceUrl,
RegionEndpoint = RegionEndpoint.APSoutheast2});
await CreateTable(dynamoDbClient,TableName);
LambdaLogger.Log("Insert record in the table");
await dynamoDbClient.PutItemAsync(TableName, new Dictionary<string, AttributeValue>
{
{ "Name", new AttributeValue(customer.Name) },
{ "EmailId", new AttributeValue(customer.EmailId) },
});
context.Logger.Log(string.Format("Finished execution for function -- {0} at {1}",
context.FunctionName,DateTime.Now ));
}
Step 5
Deploy code to AWS Lambda Service.
There are two different ways to deploy C# Lambda function. One using AWS toolkit for Visual Studio and the second using AWS Console. For the purpose of this demo, we will use AWS Toolkit.
Right click on project in Solution Explorer and click on Publish to AWS Lambda.
Ensure you have entered Assembly Name, Type Name and Method Name correctly, Otherwise, you will get LambdaException at run time.
Configure Execution Memory, Timeout, VPC, Role and Environment Variables. You can also encrypt Environment variables using KMS Key. Ensure account profile has appropriate access permission.
Invoke function from function view window. It allows you to Configure environment variable and check log output.. You can also look at detailed log in cloud watch logs.
That's it! First Serverless function is deployed.
Reference
Complete Source Code
You can find the complete source code on my GitHub.
History
- 25th February, 2017: Initial version

