Downloads
Download Kerosene.ORM.zip
Download KeroseneTests.zip
Latest code in GitHub
Latest code, documentacion and tests are maintained in GitHub where you can also submit your issues. Nuget packages are also available for the following repos:
Kerosene.ORM source code.
Kerosene.Tools source code.
Kerosene.ORM.SqlServer source code.
Introduction
In almost all projects, from enterprise-level solutions to personal ones, we need to use some sort of database. Even with the rise of No SQL solutions relational databases are still the most used ones. The most common way of using the services provided by our favorite one from our application is through an ORM solution.
ORM (Object-Relational Mapping) solutions promise to deliver an abstraction layer by which we can focus on our business logic and business-level entities instead of diverting our attention with the myriad of details we would have to take into consideration otherwise if we deal directly with our databases.
But, having said that, many of us are not completely comfortable with the way most ORM solutions deliver that promise. We dislike the time and efforts we need to devote just to start understanding their idiosyncrasies, and tired with the complexity they take to create even the simplest solution. Many don’t even properly implement the separation of concerns paradigm, requiring us to pollute our business-level code with ORM-related stuff, demanding us to decorate our POCO classes with attributes, or having to make them inherit from an ORM-specific base class. And, even worse, many don’t realize we are grown-up professionals, that we know what we are doing, and that we want full control on what SQL code is executed on our behalf.
What Kerosene ORM provides?
Kerosene ORM has been built to solve all these annoyances. It is an open source and full-featured ORM with real full support of POCO classes, as well as support low-level operations if needed. Among its many interested features we can mention the following ones:
- Self-adaptive and Configuration-less.
Kerosene ORM does not use any external mapping or configuration files at all. Or, worse, a set of out-of-band tools to create those mappings.
- Full real support for POCO objects, and clear Separation of Concerns. There is no need to pollute our business classes with attributes or any ORM-related stuff. We don't need to make them inherit from any specific ORM base type. Aggregate roots work the way they should and we just need to add and remove child instances to their parent’s lists without involving any ORM specific code.
- No mandatory conventions. With
Kerosene ORM we are not constrained by foreign rules and so we are free to use whatever names we want for the members of our POCO classes and database columns. For instance, the library will automatically find out which ones are the primary key ones, if any.
- Flexible and Resilient. Instead of hiding the reality
Kerosene ORM acknowledges that things in the field tend sometimes to be messy. Columns are added or removed, indexes are dropped or created, and even business binaries and assemblies are updated… but Kerosene ORM is architected to endure all those scenarios, as far as just the relevant names do not change, without needing to recreate any mapping or recode our applications.
- Full control of the SQL code generated.
Kerosene ORM will execute only the SQL code we are specifying, no more, no less. We will be able to use a natural SQL-alike syntax from our C# code, even using complex ones, without losing all the automatic and dynamic mapping capabilities provided.
All these characteristics make Kerosene ORM an ideal solution for iterative and agile development scenarios and, even more, where a number of disparate teams is involved, from developers to IT and database responsible ones. It is worth to mention that Kerosene ORM is fundamentally a database-first solution as it reverts to the database to find all the information it needs.
Scope of this article
This article contains a high-level introduction to Kerosene ORM. For deeper details please take a look at the following ones:
- Kerosene ORM Dynamic Records In Depth. A deep dive into the “Dynamic Records” operational mode of
Kerosene ORM. This mode provides low-level access to the capabilities and contents provided by the database, and is also suited for data intensive scenarios.
- Kerosene ORM Entity Maps In Depth. A deep dive into the “Entity Maps” operational mode of
Kerosene ORM, where the library maps on our behalf the results obtained from the database into instances of our POCO business classes.
- Kerosene ORM for WCF. An accompanying library that shows how to provide a SQL-alike service so that a client can connect to a WCF proxy server that shields the real database from any external access.
- Kerosene Dynamic Data Services. An agnostic description of the Dynamic Repository and Dynamic Unit of Work patterns that not depends on any underlying ORM technology. Kerosene ORM has been built around those principles and can be used to implement this patterns in an n-Tier scenario.
The downloads
This article includes downloads for the Kerosene ORM library, accompanying ones, and test projects. Please feel free to use them or to contribute in Kerosene GitHub project repository.
Several NuGet and symbols packages are also available:
- Kerosene.ORM: the main library package containing the Dynamic Records and Entity Maps features. It also includes the “Direct” variants to facilitate the access to databases in direct connection scenarios.
- Kerosene.Tools: a library containing the core tools used in the ORM, including the generic ability of parsing dynamic lambda expressions.
- Kerosene.ORM.SqlServer: a package that provides specialized support for SQL Server 2008, 2012 and 2014 versions. Additional packages for other database versions are in the cooking.
Our business scenario
To get the most out from the discussions that follow we are going to suppose that we are dealing with a (minimalist) HR system composed by three main tables: Regions, Countries and Employees, as follows:
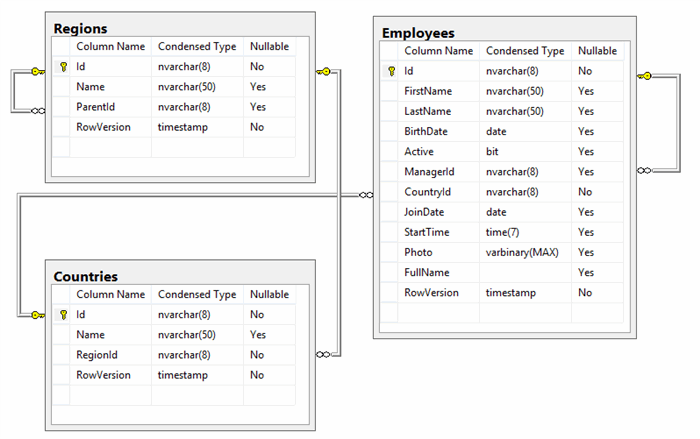
To make things a bit more interesting regions are organized in a hierarchical fashion, so the ParentId column maintains what region the current one belongs to, or null if it is a top-most one. Similarly, countries have a RegionId column that contains the region that country belong to. And, finally, employees contain both a CountryId column (that must not be null) and a ManagerId one that, if it is not null, identifies the manager of the current employee.
Note also that the three of them have an "Id" column… but this has happened by chance! There is nothing in Kerosene ORM that require us to use any special names or conventions, we are free to use any names we may wish. In addition we don’t even have to know which columns are the primary key ones, if any exists – actually Kerosene ORM does not require us to have a complete knowledge of the structure and metadata of our records, basically just the names of the tables and columns we are interested in (and in some circumstances not even those).
Operational Modes
Kerosene ORM works in two operational modes:
- Dynamic Records: this mode is the door to access the low-level capabilities and contents produced by our database. It is, essentially, a wrapper around ADO.NET but providing dynamic SQL parsing capabilities. It is able to dynamically adapt to any structure the contents produced by our database may have, without requiring any kind of attributes or mapping files. It is suited to those scenarios were no classes are needed to hold those results, or to data intensive scenarios.
- Entity Maps: this mode provides the dynamic mapping among the records in our database and the POCO business entities in our applications. In this mode we concentrate on our business logic and the library will persist to and retrieved from the database those entities on our behalf.
Our applications can freely mix both operational modes as we need.
Dynamic Records
As mentioned above Kerosene ORM uses the Dynamic Records operational mode to provide access to the low-level capabilities of our database, adapt dynamically to whatever results it produces, and all of these without having to write any configuration or mapping files.
Let’s suppose that we are suddenly asked to give some help to the HR guys. For unfathomable reasons they urgently need a report with the details of the employees whose last name starts with 'P' or greater. Using Kerosene ORM it is as easy as follows:
using Kerosene.ORM.Core;
using Kerosene.ORM.Direct;
var link = LinkFactory.Create();
var cmd = link
.From(x => x.Employees)
.Where(x => x.LastName >= "P");
foreach(var rec in cmd) Console.WriteLine("\n- Employee: {0}", rec);
That’s it, less than 5 minutes and we are done! We have not had to write any complex or external mapping files or, as happens in this example, any business class at all regardless what results are produced from the database.
But what have we done exactly?
- First thing first, we have imported the relevant namespaces. The “Core” one contains the main
Kerosene ORM interfaces and elements, whereas the “Direct” adapts those for direct connection scenarios (the most common ones where we connect to the database using a standard connection string).
- Then we have then instantiated a “Link” object using a helper factory. Links implement the
IDataLink interface and are the objects used by Kerosene ORM to represent an agnostic connection against an underlying database, regardless if it is a direct one, a WPF one, or any other type. They take care of maintaining transactions, opening and closing the underlying physical connection with the database when needed, and so on.
- Once we have that link we have used its
From() method to create a query command. Its argument is a dynamic lambda expression that resolves into the name of the table we are interested in. And then we have used then its Where() method to specify the records we want to retrieve where, similarly, we have also used a dynamic lambda expression to express the filtering logic.
- Finally we have executed the command, by enumerating it, and printed the records received from the database. These records are
IRecord instances that dynamically adapt themselves to whatever structure those records may have.
A note on Dynamic Lambda Expressions
Dynamic Lambda Expressions (DLEs) are heavily used in Kerosene ORM. They are defined as lambda expressions where at least one of their arguments is a C# dynamic one: Kerosene ORM typically uses a Func<dynamic, object><dynamic, object=""> signature.
When this happens the operations bounded to those arguments (getters, setters, invocation of methods, etc.) are not bounded at compile-time but rather deferred till run-time, where the Kerosene ORM parsing engines can inspect and use them appropriately. This is why, for instance, we have been able to write 'x => x.LastName >= "P"' in a natural SQL-alike way to compare between two string-alike objects, something that the C# compiler does not allow. And note that we have not needed to specify any information on what the 'LastName' column type would be.
A second example
Live is not easy. HR has come back with a new request: in this case they want a report containing the details of the employees that are not active ones, along with the details of the last country they have worked for. Fine, no problems, at the end of the days they are the one that control the payroll so we will better give them some extra help. One approach, among many others, can be the following one:
var cmd = link
.From(x => x.Employees.As(x.Emp))
.From(x => x.Countries.As(x.Ctry))
.Where(x => x.Active == false || x.Active == null)
.Where(x => x.Ctry.Id == x.Emp.CountryId)
.OrderBy(x => x.Ctry.Id, x => x.Emp.Id)
.Select(x => x.Ctry.Id, x => x.Ctry.Name)
.Select(x => x.Emp.All());
This approach queries from several tables simultaneously. Yes, we could have used a join-based approach, but this example let us see some interesting features:
- We have used several
From() methods, each specifying one of the tables we are interested in. In their arguments we have used the Alias() virtual extension method to specify the aliases of those tables. These methods are intercepted when Kerosene ORM is parsing an expression, and used to add extra logic or information as in this case.
- We have chained several
From(), Where() and Select() methods. This is a general rule: in most circumstances we can use the same methods as many times as we want and Kerosene ORM will take care of combining their contents into the appropriate SQL statements afterwards.
- Instead of using the same method many times they typically accept a variable number of dynamic lambda expressions as its arguments. Both ways are equivalent and can be freely mixed.
- Finally note how we have used the
All() virtual extension method appended to the name of the table: it is used to express than we want to select all the possible columns from that one.
Query commands do support many other methods and syntaxes, as the Join(), OrderBy(), GroupBy(), Having(), Skip(), and Take() ones, and many others. Please take a look at the accompanying articles for more details.
Using the records
Obviously we may to do something else with the records we have retrieved than to write them out into the console. IRecord instances are dynamic objects that adapt themselves to whatever structure is retrieved from the database. We can access their contents using both dynamic and indexed ways:
foreach (dynamic rec in cmd)
Console.WriteLine("\n- Country: {0}, Employee: {1}, {2}",
rec.Ctry.Id,
rec["Emp", "LastName"],
rec.FirstName);
- As we have used the dynamic keyword for the enumeration variable we have been able to access its contents dynamically, as in '
rec.Ctry.Id'. Note that in this case we have specified the table and column we are interested in, but if there were no ambiguities we could have used instead just the column name (as in 'rec.FirstName').
- Note that we have used in the example the table alias, but we could have also used the table name if we have preferred to do so: '
rec.Countries.Id'. Records keep track of the aliases used so both forms are equivalent.
- Finally, accessing the contents dynamically is quite nice but it has some performance penalty. If we don’t want to pay this no-so-big price we can also use the indexed approach where we can also specify the table and column, or just the column name.
If we ever want to investigate the complete structure of these contents, or to access the metadata returned by the database for each table-column entry, each record carries the Schema property that gives us access to those details. Please refer to the accompanying articles for more details.
Executing the commands
Kerosene ORM commands are either ‘enumerable’ commands, ‘scalar’ commands, or both simultaneously. Enumerable ones return back the records produced by the database, and are executed when enumerated, as happened in the examples above.
For these commands there are also available the First(), Last(), ToList() and ToArray() methods. The First() and Last() ones will return ‘null’ if no records were available but no exceptions will be thrown as this scenario is considered as a valid operational condition and not as an error one.
var cmd = link...;
var rec = cmd.First();
Scalar commands will return an integer when executed. For instance, it can be the number of records affected by the execution of the command, or any other value the command produced. To execute a scalar command we will use its Execute() method:
var cmd = link...;
int n = cmd.Execute();
Extending the syntax
In order not to make Kerosene ORM dependent on a particular database dialect or version it features a number of extensibility mechanisms. The default and most used one happens when it encounters a construction that it is not aware of: in this case it assumes we know what we are writing down and just injects that construction into the parsed SQL text.
For instance, even if the COUNT function is not known to the Kerosene ORM parser we can write what follows:
var cmd = link
.From(x => x.Employees)
.Select(x => x.Count("*").As(x.Result));
dynamic rec = cmd.First();
int num = rec.Result;
The parser will find something that it does not understand, and that looks like a method call. It will use its name, inject into the SQL code, and parse its arguments to produce the following text:
SELECT Count(@0) AS Result FROM Employees
As we can see the arguments of this method-alike constructions are parsed and captured by default, which is nice to avoid SQL-injection attacks. But in this particular example we can refine it by avoid the “*” to be captured by using the so-called “scape syntax" as follows:
... x => x.Count(x("*")) ...
where we have surrounded with parenthesis the part we want to be injected into the SQL code as we have written it. Using this syntax the command would have been translated into:
SELECT Count(*) AS Result FROM Employees
Insert, Delete and Update commands
Link instances also provide us with the appropriate methods to create these commands. For instance, to insert a new record into the database we can use:
var cmd = link
.Insert(x => x.Employees)
.Columns(
x => x.Id = "007",
x => x.FirstName = "James",
x => x.LastName = "Bond",
x => x.CountryId = "uk");
var rec = cmd.First();
The argument of the Insert() method is, again, a dynamic lambda expression that resolves into the name of the table we are interested in. Then we use its Columns() method, which takes a variable number of dynamic lambda expressions each specifying the column affected and its value, where this value can resolve into any valid SQL sentence, as well as to any reference or value we can obtain from the surrounding C# code.
In this case, for simplicity, we can use its First() method to execute the command and to return back the exact contents and metadata of the new record inserted in the database.
Updating a record follows the same pattern. We just need to locate what records we are interested in and then specifying the columns to modify:
var cmd = link
.Update(x => x.Employees)
.Where(x => x.Id == "007")
.Columns(
x => x.Id = "008",
x => x.FirstName = x.FirstName + "_Surrogate");
var list = cmd.ToList();
Note that the WHERE clause does not need to resolve to just one record, but also to a set of them if we want to update many records in just one operation. In this case we can use the ToList() method (or enumerate the command) to obtain all the records affected by the execution of the command.
We can now figure out what we have to do to delete one or many records from our database:
var cmd = link
.Delete(x => x.Employees)
.Where(x => x.Id == "007");
int n = cmd.Execute();
Note that if we have not used the WHERE clause then we will end up trying to delete all records from the table we are dealing with. Remember, Kerosene ORM treats us as grown up developers, and assumes we know what we are doing. In this case we have used its Execute() method to just obtain the number of records affected.
Raw commands
From time to time it may happen that we want to execute some logic that is not completely covered by any of the standard commands. For instance, we may want to use a CTE expression, or we want to invoke a stored procedure. For this scenarios Kerosene ORM provides us with the specialized “Raw” command. Let’s see an example:
var cmd = link.Raw(
"EXEC employee_insert @FirstName = {0}, @LastName = {1}",
"James", "Bond");
Whatever text we write as the argument of the Raw command will be executed against the database: in this example we are, for instance, invoking the ‘employee_insert’ stored procedure (what it does really doesn't matter, it is just an example).
There are two nice things to bear in mind:
- The first one is that we can specify the command arguments using the standard curly brace ‘
{n}’ syntax. Kerosene ORM will capture those arguments to avoid SQL injection attacks.
- And the second one is that Raw command can be both enumerated and executed as a scalar command, depending upon the concrete logic we are using. So, in the first case we will receive the records produced as happened with any of the standard commands, and obtain the metadata associated with them.
Converting Records into Entities
Kerosene ORM provides the Entity Maps operational mode to map among the records in our database and instances of our POCO classes. But, sometimes, we have not such classes created. For instance, it may happen that those results are only used in a very concrete part of our application and it will enough to use an anonymous type.
For this scenarios the Kerosene ORM enumerators used to execute an enumerable command carry the Converter property, a delegate whose signature is Func<IRecord, object><irecord, object=""> that, if it is not null, is invoked each iteration to convert the current record to whatever object the delegate wants to return using the record contents. For instance:
var cmd = link.From(x => x.Employees);
foreach (var obj in cmd.ConvertBy(rec =>
{
dynamic r = rec;
return new { r.Id, Name = string.Format("{0}, {1}", r.LastName, r.FirstName) };
}))
Console.WriteLine("\n> Object: {0}", obj);
As said, this is a fast and convenient mechanism for a number of scenarios – for instance when we don’t want the overhead of creating a class for results not used in any other place. But, on the flip side, the state of these entities is not tracked, or their dependencies (if any) are not taken into consideration automatically. For these needs, it is better to move into the “Entity Maps” operational mode.
Entity Maps
When using the Kerosene ORM Entity Maps operational mode the library will dynamically map the records obtained from the database to instances of our business-level POCO classes, and their contents, state and dependencies are tracked. To do this Kerosene ORM does not require us to write external configuration or mapping files, using any kind of pre-canned conventions, polluting our classes with attributes, or needing them to inherit from any ORM specific base class.
What’s more, Kerosene ORM will try figure out by default what tables to use and how to perform the mapping among their columns and the members of our POCO classes. Only if we want to use non-standard table or column names, or if we want to define navigational properties and dependencies, then we need to provide some extra information to Kerosene ORM in the form of a custom map.
Types of Members
Kerosene ORM is able to manage several types of members in its maps: Simple, Lazy and Eager ones.
Simple Members
As said before Kerosene ORM will try to, by default, make a correspondence among the columns in the database and the members in our POCO classes whose names match the names of those columns. When this happens the member is said to be a “Simple” member, and Kerosene ORM will handle the mapping between the member and the column automatically.
If there is not a corresponding member for a given column then it is ignored – and the opposite is also true. Note that if the names of the columns in the map are not case sensitive Kerosene ORM will understand this fact and won’t enforce case sensitiveness when finding a match.
Members can be both fields and properties, and they can be public, protected or private ones. Kerosene ORM will find out their getters and setters, if any, and use them appropriately.
Eager and Lazy Members
In addition there might be members in our POCO classes whose contents have not a direct one-to-one correspondence to a column in the database. We may need to query the database to obtain them, or to perform complex calculations, or to access external web services, or to… whatever. Some of those members could also be navigational properties maintaining references to other entities.
When this happens Kerosene ORM will let us to specify how to obtain their contents by customizing the map associated with the type of our POCO class. If the member is a property, and it is a virtual one, and either its getter or setter is accessible, then it is said to be a “Lazy” member and its contents are obtained only when its getter is used. Otherwise it is said to be an “Eager” members and its contents are obtained immediately after the primary record of the entity is read from the database.
What kind of member to use
“Simple” members are the default ones and we have to do nothing to use them. By the way, if we want some column not to participate in the mapping mechanism we can tell that to Kerosene ORM using the Columns property of its associated map. But I digress, please see the accompanying articles for more details.
When we have the option to use either “Lazy” or “Eager” members the former are preferred over the later ones. This is because “Eager” members will try to load the complete object’s graph into memory, with an increased consumption, and will also experiment a delay till their cascaded dependencies are retrieved. But, on the flip side, if we cannot modify the POCO class definition because it, for instance, sits in an assembly we cannot modify, supporting eager members is quite useful.
We can freely mix Simple, Lazy and Eager members, even in the same entity, without any restrictions.
Using Simple Maps
Let’s suppose we have laid out our Region class as follows, with a one-to-one correspondence among the columns we are interested at and the members of our class:
public class Region
{
public string Id { get; set; }
public string Name { get; set; }
public string ParentId { get; set; }
}
Obtaining a repository instance
The only mandatory thing we have to do to use Kerosene ORM maps is to obtain a repository instance:
using Kerosene.ORM.Maps;
...
var link = ...;
var repo = RepositoryFactory.Create(link);
A repository is an object that implements the IDataRepository interface. They are used by Kerosene ORM to keep what types are mapped to what POCO classes, how that mappings behave, and the entities that are tracked on behalf of those maps.
We could have obtained that instance by using the constructor of its class but using the factory is handy and let us avoid importing more namespaces. The first argument of its Create() method is the link the repository will use to connect to the underlying database, which can be obtained by any of the mechanisms discussed in this article. There are no limits on the number of repositories we can create that share the same link. However, each repository will maintain its own vision about the state and contents of the underlying database.
Query commands
Once we have our repository instance we can use its methods to execute the appropriate commands. For instance, to retrieve contents from the database we create and use a query command as follows:
var cmd = repo.Query<employee>();
var list = cmd.ToList();
</employee>
The type argument of the Query() method let us specify the type of the entities we are interested in. It is an enumerable command that, when execute, will retrieve the records from the database, and will use their contents to create the appropriate instances of the POCO class we have specified through its type.
Of course we can filter what entities we want to retrieve. For instance, to get a particular entity we could have written something like:
var cmd = repo.Where<employee>(x => x.Id == "007");
var emp = cmd.First();
</employee>
Or, to obtain a list of entities in a particular order we could have written:
var cmd = repo.Where<employee>(x => x.ParentId == "M").OrderBy(x => x.Id);
var spies = repo.ToArray();
</employee>
The nice thing is that we are not constrained to obtain our entities by just using a pre-canned set of FindXXX() methods, but rather using any kind of logic our application may need in a given scenario.
Indeed, Kerosene ORM provides a wide range of methods in its Query commands, including some to support non-conventional query scenarios where, even in this POCO world, we can query or join from several tables simultaneously. Please refer to the accompanying articles for more details.
Weak maps
It is interesting to note that neither we have specified the name of the table from which to obtain our entities, nor we have created an explicit map for that type. When a type is used without an associated map for that type registered in a given repository Kerosene ORM will automatically create a “weak” map on our behalf, making also a number of educated guesses to find out a table name based upon the name of our type. And then will add to the map the columns and members as appropriate.
They are said to be “weak” ones because as soon as our application explicitly registers a map for a given type any previous weak one registered in the repository, if any, will be automatically discarded. If the previous one is not a weak one then an exception is thrown because a map for a given type can be registered only once in a given repository.
If you don’t like this feature it can be disabled by setting the WeakMapsEnabled property of the repository instance to false.
Insert, Update and Delete commands
Kerosene ORM follows the Unit Of Work patterns by which all change operations are firstly submitted (annotated) into the repository and then, when we are ready, executed as a single unit against the underlying database.
For instance, to insert a new entity in the database we can proceed as follows:
var emp = new Employee() { Id = "007", CountryId = "uk" };
...
var cmd = repo.Insert(emp);
cmd.Submit();
...
repo.ExecuteChanges();
The Insert() method creates the appropriate command, using our entity as its argument. We have not had to specify its type because it can be inferred from this entity. If we had used instead an object that inherits from this type we can always specify the appropriate command by using the type argument as in 'repo<MyType>.Insert<employee>(obj)'.
We then have submitted this command into the repository. We can of course submit more operations or perform any other activities as needed. Finally we have executes and persisted all the pending changes against the database invoking the ExecuteChanges() method od our repository.
We can now update our entity:
emp.FirstName = "James";
emp.LastName = "Bond";
...
repo.UpdateNow(emp);
Kerosene ORM will automatically find the changes experimented by our entities since the last time their contents were obtained from the database, and will create an update command containing only those changes.
In this example we have executed the update operation using the UpdateNow() method: it is basically a convenient way to submit and execute the command, along with any other submitted ones, in just one call. There are also similar InsertNow() and DeleteNow() methods available.
By the way, deleting our business entity from the database is as easy as follows:
repo.Delete(obj).Submit();
repo.ExecuteChanges();
or just:
repo.DeleteNow(obj);
Customizing the maps
Table names
It may happen that the easy pluralization rules Kerosene ORM uses to figure out the name of the table associated with a given type are not enough. When this happens we need to define and register into our repository a custom map.
We have two options: the first one is to create an instance of the DataMap<T><t> class, and use its methods to customize it, or to create a class that inherits from this one and, inside its constructor, proceed with those customizations. Both approaches can be used but the second one is preferred for technical reasons:
public class RegionMap : DataMap<Region><region>
{
public RegionMap(DataRepository repo) : base(repo, x => x.Regions)
{ ... }
}
</region>
The DataMap<T><t> class’ constructor takes two arguments, the repository where the new instance will be registered into, and a dynamic lambda expression that resolves into the name of the primary table in the database associated with our business entities. By the way, we can cast safely the IDataRepository instances returned by the RepositoryFactory static class into the DataRepository type this constructor expects.
Discriminators
It may happen that our table is used to hold different kind of related entities – for instance standard, gold and premium customers, and so on. It may also happen that we have different business types for each of those variants. We can specify what conditions the records have to meet to be considered as valid ones for one of those types by using the map’s Discriminator property.
If this property is not null it contains a dynamic lambda expression that resolves into the additional contents to inject into the WHERE clause of any query so that we will be sure the entities created by such queries are using the appropriate records.
For instance if, in addition of having our Employee class we could have a Director one that represents those employees without a manager, we can create a map for directors and set its discriminator property as follows:
public class Director : Employee
{
...
}
public class DirectorMap : DataMap<Director><director>
{
public DirectorMap(DataRepository repo) : base(repo, x => x.Employees)
{
Discriminator = x => x.ManagerId == null;
...
}
}
</director>
Other customizations
Kerosene ORM maps support other customizations as well. For instance we can specify how to control row versioning if the table has any column used for this:
VersionColumn.SetName(x => x.MyVersionColumn);
Kerosene ORM will keep the contents obtained when the entity was retrieved from the database and will compare those with the most up-to-date ones when executing an Update or Delete command. If the version has changed a ChangedException exception will be thrown.
We can also specify that we want not a given column to participate in the mapping mechanism, even if there is a corresponding member in our POCO class. We can do this by adding an entry to the Columns collection of the map and setting its Excluded property to true:
Columns.Add(x => x.MyColumn).SetExcluded(true);
We can also specify which members are navigational properties, or how to obtain their contents if there are not a corresponding column in the database – we will see this customizations in the next section below.
Using Eager and Lazy members
Let’s now suppose we want our POCO classes to be a bit more elaborated so that they will contain navigational properties that refer to related entities. For instance we can rewrite our Region class as follows:
public class Region
{
public string Id { get; set; }
public string Name { get; set; }
virtual public Region Parent { get; set; }
virtual public List<region> Childs { get; private set; }
virtual public List<country> Countries { get; private set; }
}
</country></region>
As we are using the virtual keyword we are going to use “Lazy” members but all the discussions that follow will also apply to “Eager” ones.
Child Dependencies
Let’s take a look at how can we define a child dependency. In the following example we are interested at the Countries property that maintains the list of countries that belong to the region. We can define that dependency by adding a new entry to the Members collection of the associated map:
Members.Add(x => x.Countries)
.OnComplete((rec, obj) =>
{
obj.Countries.Clear();
obj.Countries.AddRange(
Repository.Where<country>(x => x.RegionId == obj.Id).ToList());
})
.SetDependencyMode(MemberDependencyMode.Child);
</country>
Its Add() method takes a dynamic lambda expression as its argument that resolves into the name of the member we are dealing with – and remember it can be a field or property, and it can be a public, protected or private one.
This method returns a IMapMember entry whose OnComplete() method is used to define what delegate to invoke to obtain the member’s contents when needed. This delegate takes two arguments, the first one the last record obtained from the database associated to the host entity, and the second one being a reference to the host entity itself.
As said before this delegate can take any action needed to obtain those contents. In our example we are firstly clearing the list, just for sanity, and the populating it again with the most up-to-date entities from the database. As we are defining this delete inside the map’s constructor we can use its Repository property for simplicity.
The last thing we have done is setting the dependency mode, in this case it being a “Child” one. Only “Child” or “Parent” dependencies are cascaded automatically when processing Insert, Delete or Update commands. If we set no mode it will have the default “None” one, which means that it will not be taken into consideration for cascade operations.
Parent Dependencies
Let’s now define a parent dependency: the Parent member of our POCO class that if it is not null will maintain the region this one belongs to. Its definition is similar to the previous one:
Members.Add(x => x.Parent)
.WithColumn(x => x.ParentId, col =>
{
col.OnWriteRecord(
obj => { return obj.Parent == null ? null : obj.Parent.Id; });
})
.OnComplete((rec, obj) =>
{
obj.Parent = Repository.FindNow<region>(x => x.Id == rec["ParentId"]);
})
.SetDependencyMode(MemberDependencyMode.Parent);
</region>
In this case we have used the WithColumn() method of the member entry that allows us to specify that the column it refers to has to be present in the map even if there is no corresponding member in our class. Its first argument is a dynamic lambda expression that resolves into the name of the database column.
Its second argument is a delegate used to customize that IMapColumn entry and, in this case, we are specifying how the value of the associated column shall be persisted back to the database when needed. In our example we are obtaining this value from the member’s value: if it is null we can persist back a null value, otherwise we will use the parent’s Id.
The OnComplete() method has a body that is quite similar to the previous examples but, instead of executing a query, we are using the FindNow() command for performance reasons. It will try to find that instance in the cache the repository maintains in memory and, only if it is not found there, it will query the database. Note that it may happen it returns null if the parent entity is not found in the cache or in the database, which is a perfectly valid situation and we set the member’s value correspondingly.
And, finally we cannot forget to set the dependency mode to “Parent”.
Working with Aggregate Roots
Kerosene ORM let us work with aggregate roots in a natural and easy way: we can add or remove entries to these collections without needing to use any ORM related operations. Even if we are dealing with real POCO classes Kerosene ORM will, behind the curtains, keep track of these modifications.
Only later, when we are done, we will persist those changes into the database:
var root = repo.Query<region>.Where(...).First();
...
root.Countries.RemoveAt(0);
root.Countries.Add(new Country() { Id = "ZZZ" });
...
repo.UpdateNow(root);
</region>
The internals of this mechanism are quite interesting and involves associating real-time a package of metadata with each managed entity such a way that no lists or dictionaries are involved for performance reasons. This metadata is also used to maintain the state of the entity and for other purposes. The details are beyond the scope of this introductory article, please refer to the accompanying ones for further information.
Insert, Delete and Update operations
All Kerosene ORM commands, Query, Insert, Delete or Update ones, work with lazy and eager members as explained before regarding simple ones, and with the same syntax.
One thing to bear in mind is that if we have defined dependencies with either a “Child” or “Parent” dependency mode Kerosene ORM will cascade the Insert, Update and Delete operations as appropriate. For instance, Insert and Update operations will identify what parent dependencies are not persisted and will insert them before executing the command with the current entity. Delete operations will make sure that any child dependencies are removed from the database before deleting the current one, and so on.
If a dependency has a dependency mode set to “None” (which is the default value) it will not be cascaded. This mode is used to identify members whose contents are to be obtained by convoluted ways, but that do not need to be cascaded.
Other goodies
Just now a few goodies that can make our lives easier:
- Note that we have not had to specify what columns are the primary key ones, if any.
Kerosene ORM will find them out or, if there are any, will try to use any columns marked as unique valued ones. If neither are found then Entity Maps cannot be used because Kerosene ORM expects a way to univocally identity what record to map from the primary table to a given entity. In this case we can use the Dynamic Records operational mode without any restrictions.
- If we want to clear the cache of entities of any of our repositories or maps we can use their
ClearEntities() methods. Note also that Kerosene ORM implements an internal collector that will automatically remove, from time to time, those entities that are not needed any longer.
- We can also use the map’s
Attach() and Detach() methods to, well, attach an entity to the map as if it were retrieved from the database, or to remove it from the map’s cache and make it behave as if it were not retrieved from it.
- If you ever need to retrieve the most up-to-date contents for a given entity you can use the repository’s
RefreshNow() method, passing as its argument the object to refresh. It returns a reference to a refreshed object, or null if it cannot be found in the database. Along the way it will also refresh any other entity in the cache that shares the same identity columns.
History
- Version 7.0.0, February 2015: API changes to support a streamlined architecture that provides full control on how the values of the dependencies are obtained. Improved support for cascading aggregate roots, and non-conventional query scenarios with POCO classes. Increased performance both in Dynamic Records (3x) and Entity Maps (4x) modes. Support for the
With() method of the query commands is dropped in this version (the workaround is to use Raw commands instead). Support for persisting change operations without an associated transaction is dropped in this version as it violates the Unit Of Work pattern. A delegate to control how exceptions are treated when persisting these changes is added into the API.
- Version 6.5, February 2013: Some bugs fixed; Improvements on the way the library automatically handles 'cascading' dependencies. Incorporates the foundations to implement the Dynamic Repository and the Dynamic Unit of Work patterns, along with sample applications that demonstrate those capabilities.
- Version 6.0, April 2013: Its focus was to include a completely revised "Entity Maps" mechanism and architecture, supporting table, eager and lazy loading variations for navigational or dependency properties, and an improved and cleaner overall architecture. It does also include the concept of 'generic engines' so supporting out-of-the-box MS SQL Server, Oracle, ODBC and OLE DB database generic engines.
- Version 5.5, January 2013: A maintenance version whose aims were, firstly, to simplify the syntax so that we don't need any longer a specific override for each possible clause variation and to, secondly, include an improved extensibility mechanism for the "Entity Maps" mode.
- Version 5.0, September 2012,
Kerosene ORM: New name as the former one ('Kynetic') was aggressively marketed by one major multinational. Additional focus of this version was to formalize the "Entity Maps" mechanism that substitutes the ones available in both Entity Framework and nHibernate frameworks.
- Version 4.5, May 2011: Included firstly an improved support for generic command arguments. Since this version the library accepts any arbitrary value for a command parameter, even those of your custom classes, regardless if they are supported or not by the underlying database, and without the need of converting them into strings. Secondly, it included a more advance preliminary support for what later became the "Entity Maps" mechanism.
- Version 4.0, January 2011: This version introduced the concept of 'agnostic links' that decouples the library from any specific connection or data context type. This was needed in order to provide support for WCF connection scenarios. It did also include, buried behind this WCF support, a first tentative version for the "Entity Maps" operational mode.
- Version 3.0, October 2010,
Kynetic ORM: Its focus was on an improved and more convenient parsing mechanism, using fully the concept of DLEs (Dynamic Lambda Expressions), and on performance. As the 'MetaDB' name was not compelling enough it was changed into 'Kynetic ORM'.
- Version 2.0, August 2010,
MetaDB: Its focus was to incorporate support for CUD operations (hence why its name changed from MetaQuery to MetaDB), and to resolve some bugs.
- Version 1.0, June 2010,
MetaQuery: the first public version of this project. Its focus was mainly to just sending kind-of dynamic queries against a concrete underlying database, and very primitive CUD-alike operations. It was, basically, a wrapper around the query capabilities of ADO.NET.
- Versions 0.x, 2008-2009: Preliminary non-public initial versions.

