Introduction
I’m back with a new Elasticsearch experience to share with you!
Not long ago, I was assigned to come up with a solution that calculates buckets upon a pair of date fields. At first, I thought, “Well, piece of cake! It’s plenty of material online”.
Until I realized that, for this particular scenario, I had to use some dynamic scripting to yield this aggregation.
Although indeed you can find lots of material and discussions in forums, there are some nuances that I’ve only learned while coding it. Good old development struggle!
Let’s quit talking and jump on it!
The Requirement
Let's assume that you are given this table as a data source:
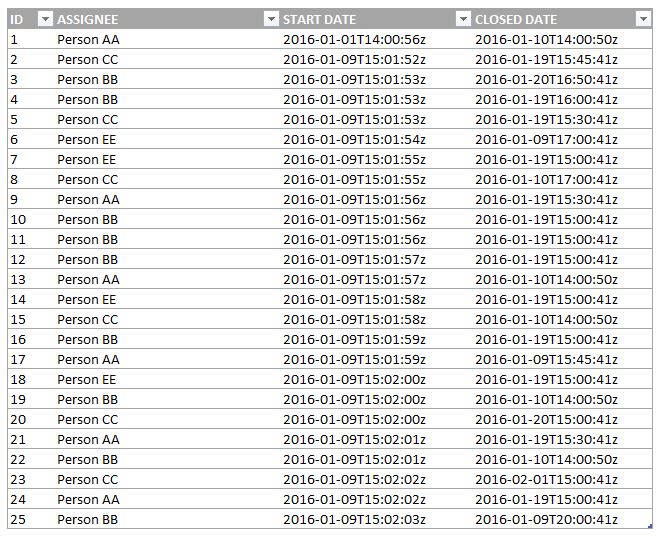
And your application must be able to calculate the difference between “START DATE” and “CLOSED DATE” and aggregate the results into buckets as follows:
Date diff in Minutes:
- From 0 to 30 minutes
- From 31 to 60 minutes
- Greater than 1 hour
Date diff in Hours:
- From 0 to 2 hours
- From 2 to 24 hours
- Greater than 1 day
Date diff in Days:
- From 0 to 3 days
- From 3 to 7 days
- Greater than a week
"Piece of cake, right?"
Creating the Indexes
In my previous articles, I’ve demonstrated how to create and map a new index. However, a few things have changed since then. Now, using Elastic 5, you should proceed as follows:
- Create your index structure (mapping):
PUT logs
{
"mappings": {
"userlog": {
"properties": {
"name": {
"properties": {
"ASSIGNEE": {
"type": "text"
}
}
},
"START DATE": {
"type": "date"
},
"CLOSED DATE": {
"type": "date"
}
}
}
}
}
- Add some documents (same data shown in the table above):
PUT logs/userlog/_bulk?refresh
{"index":{"_id":1}}
{"ASSIGNEE":"Person AA","START DATE":"2016-01-01T14:00:56z",
"CLOSED DATE":"2016-01-10T14:00:50z"}
{"index":{"_id":2}}
{"ASSIGNEE":"Person CC","START DATE":"2016-01-09T15:01:52z",
"CLOSED DATE":"2016-01-19T15:45:41z"}
{"index":{"_id":3}}
{"ASSIGNEE":"Person BB","START DATE":"2016-01-09T15:01:53z",
"CLOSED DATE":"2016-01-20T16:50:41z"}
{"index":{"_id":4}}
{"ASSIGNEE":"Person BB","START DATE":"2016-01-09T15:01:53z",
"CLOSED DATE":"2016-01-19T16:00:41z"}
{"index":{"_id":5}}
{"ASSIGNEE":"Person CC","START DATE":"2016-01-09T15:01:53z",
"CLOSED DATE":"2016-01-19T15:30:41z"}
{"index":{"_id":6}}
{"ASSIGNEE":"Person EE","START DATE":"2016-01-09T15:01:54z",
"CLOSED DATE":"2016-01-09T17:00:41z"}
{"index":{"_id":7}}
{"ASSIGNEE":"Person EE","START DATE":"2016-01-09T15:01:55z",
"CLOSED DATE":"2016-01-19T15:00:41z"}
{"index":{"_id":8}}
{"ASSIGNEE":"Person CC","START DATE":"2016-01-09T15:01:55z",
"CLOSED DATE":"2016-01-10T17:00:41z"}
{"index":{"_id":9}}
{"ASSIGNEE":"Person AA","START DATE":"2016-01-09T15:01:56z",
"CLOSED DATE":"2016-01-19T15:30:41z"}
{"index":{"_id":10}}
{"ASSIGNEE":"Person BB","START DATE":"2016-01-09T15:01:56z",
"CLOSED DATE":"2016-01-19T15:00:41z"}
{"index":{"_id":11}}
{"ASSIGNEE":"Person BB","START DATE":"2016-01-09T15:01:56z",
"CLOSED DATE":"2016-01-19T15:00:41z"}
{"index":{"_id":12}}
{"ASSIGNEE":"Person BB","START DATE":"2016-01-09T15:01:57z",
"CLOSED DATE":"2016-01-19T15:00:41z"}
{"index":{"_id":13}}
{"ASSIGNEE":"Person AA","START DATE":"2016-01-09T15:01:57z",
"CLOSED DATE":"2016-01-10T14:00:50z"}
{"index":{"_id":14}}
{"ASSIGNEE":"Person EE","START DATE":"2016-01-09T15:01:58z",
"CLOSED DATE":"2016-01-19T15:00:41z"}
{"index":{"_id":15}}
{"ASSIGNEE":"Person CC","START DATE":"2016-01-09T15:01:58z",
"CLOSED DATE":"2016-01-10T14:00:50z"}
{"index":{"_id":16}}
{"ASSIGNEE":"Person BB","START DATE":"2016-01-09T15:01:59z",
"CLOSED DATE":"2016-01-19T15:00:41z"}
{"index":{"_id":17}}
{"ASSIGNEE":"Person AA","START DATE":"2016-01-09T15:01:59z",
"CLOSED DATE":"2016-01-09T15:45:41z"}
{"index":{"_id":18}}
{"ASSIGNEE":"Person EE","START DATE":"2016-01-09T15:02:00z",
"CLOSED DATE":"2016-01-19T15:00:41z"}
{"index":{"_id":19}}
{"ASSIGNEE":"Person BB","START DATE":"2016-01-09T15:02:00z",
"CLOSED DATE":"2016-01-10T14:00:50z"}
{"index":{"_id":20}}
{"ASSIGNEE":"Person CC","START DATE":"2016-01-09T15:02:00z",
"CLOSED DATE":"2016-01-20T15:00:41z"}
{"index":{"_id":21}}
{"ASSIGNEE":"Person AA","START DATE":"2016-01-09T15:02:01z",
"CLOSED DATE":"2016-01-19T15:30:41z"}
{"index":{"_id":22}}
{"ASSIGNEE":"Person BB","START DATE":"2016-01-09T15:02:01z",
"CLOSED DATE":"2016-01-10T14:00:50z"}
{"index":{"_id":23}}
{"ASSIGNEE":"Person CC","START DATE":"2016-01-09T15:02:02z",
"CLOSED DATE":"2016-02-01T15:00:41z"}
{"index":{"_id":24}}
{"ASSIGNEE":"Person AA","START DATE":"2016-01-09T15:02:02z",
"CLOSED DATE":"2016-01-19T15:00:41z"}
{"index":{"_id":25}}
{"ASSIGNEE":"Person BB","START DATE":"2016-01-09T15:02:03z",
"CLOSED DATE":"2016-01-09T20:00:41z"}
- If everything went well, you should be able to search the documents (rows) you’ve just inserted using this command:
GET logs/userlog/_search
Introducing Painless Scripting
As I mentioned, for this demo, I’m using the latest Elastic version. This release was a big deal for the community, the Elastic guys have changed the product quite a lot, and among these changes, they introduced a new scripting language called Painless.
It’s not like we were unable to use custom script previously, though. Elastic has a couple of third party languages embedded within the product. I personally got along pretty well with Groovy.
However, I’ve based this article on the very latest. So, if you are not using Painless, even though the languages are fairly similar, you must expect slight differences between them.
Generating the Range Buckets
Straight to the point, this is the query to compute the ranges by Minutes:
GET logs/userlog/_search
{
"size": 0,
"aggs": {
"groupby": {
"range": {
"script": {
"inline": "((doc['CLOSED DATE'].value - doc['START DATE'].value) / (3600000.0/60))"
},
"ranges": [
{
"from": 0.0,
"to": 30.0,
"key": "From 0 to 30 minutes"
},
{
"from": 30.0,
"to": 60.0,
"key": "From 30 to 60 minutes"
},
{
"from": 60.0,
"key": "Greater than 1 hour"
}
]
}
}
}
}
Explaining:
First, we are calculating the date diff (doc['CLOSED DATE'].value - doc['START DATE'].value) and dividing the result of this expression, in order to have it formatted in minutes (3600000.0/60).
Behind the scenes, each and every document (row) will be calculated this way, yielding a number of minutes. Those minutes will be grouped up into buckets, by a range aggregation.
An important remark from Elastic's page (in case you've missed that out): “Note that this aggregation includes the ‘from’ value and excludes the ‘to’ value for each range.” Take it into account when creating these buckets out there.
That’s the idea going forward:
- Calculate the date diff.
- Format the result according to your need.
- Arrange them in buckets.
Consequently, to get the buckets by Hour, the query would be:
GET logs/userlog/_search
{
"size": 0,
"aggs": {
"groupby": {
"range": {
"script": {
"inline": "((doc['CLOSED DATE'].value - doc['START DATE'].value) / 3600000.0)"
},
"ranges": [
{
"from": 0.0,
"to": 2.0,
"key": "From 0 to 2 hours"
},
{
"from": 2.0,
"to": 24.0,
"key": "From 2 to 24 hours"
},
{
"from": 24.0,
"key": "Greater than 1 day"
}
]
}
}
}
}
And finally in Days:
GET logs/userlog/_search
{
"size": 0,
"aggs": {
"groupby": {
"range": {
"script": {
"inline": "((doc['CLOSED DATE'].value - doc['START DATE'].value) / (3600000.0*24))"
},
"ranges": [
{
"from": 0.0,
"to": 3.0,
"key": "From 0 to 3 days"
},
{
"from": 3.0,
"to": 7.0,
"key": "From 3 to 7 days"
},
{
"from": 7.0,
"key": "Greater than a week"
}
]
}
}
}
}
Bonus: Searching the Raw Data through Ranges
What if I told you that we are able to fetch the rows for all of these nice buckets above? As you can imagine, the solution requires more Painless Scripting!
For instance, to be able to get all the rows that match with the following condition:
A: Having the date diff in days. B: The diff must be between 0 and 3 days.
The query would be:
GET logs/userlog/_search
{
"from": 0,
"size": 100,
"query": {
"bool": {
"filter": [
{
"bool": {
"filter": [
{
"script": {
"script": {
"inline": " (((doc['CLOSED DATE'].value - doc['START DATE'].value) /
(3600000.0*24)) >= 0 && ((doc['CLOSED DATE'].value -
doc['START DATE'].value) / (3600000.0*24)) < 3) "
}
}
}
]
}
}
]
}
}
}
As you can see, this command differs from the previous for two reasons:
- It is not an aggregation request, we are purely fetching the raw data.
- The Painless script was adjusted to select the documents that meet the criteria we've set ("result of the expression" >= to zero AND "result of the expression" <= 3).
Conclusion
Elasticsearch is constantly bringing innovation with each new release, the dev community is growing larger. Further down the track, they will be removing the third-party languages and stick with Painless.
So far, it has been proven as efficient as its predecessors.
This technique I've shown is very robust and flexible. Especially when you need to cope with advanced reports, based on date (or regular) calculations and buckets. It's a common requirement.
The samples above are just the beginning, soon I will be sharing many others.
See you next time!
History
- 3rd April, 2017: Initial version

