This article introduces RE/flex for C++. RE/flex generates fast lexical analyzers similar to Flex, but supports Unicode patterns, indentation matching, lazy repeats, smart input handling, error reporting, and performance tuning. RE/flex is compatible with Bison and accepts Flex lexer specifications.
Introduction
In this article, I will introduce the RE/flex lexical analyzer generator. The RE/flex open source project was motivated by the possibility to build a generator based on an entirely different approach to tokenization that permits regex libraries to be used by the generated scanners (a.k.a. lexical analyzers, lexers, and tokenizers). This approach provides additional benefits, such as the flexibility to choose POSIX-mode and even Perl-mode (!) regex engines with a rich regex syntax, including support for Unicode. Another motivation was the challenge to create a new algorithm to construct deterministic finite automata (DFAs) for efficient pattern matching with lazy quantifiers (a.k.a. non-greedy repeats, lazy repeats, and reluctant repeats). This algorithm is also new. My third goal was to make RE/flex faster than Flex, at least for typical cases. I knew that was a challenge because Flex (the fast lexical analyzer) has been around a long time and the contributors to Flex made it very fast. Performance tests show that RE/flex is faster than Flex and faster than other regex libraries that may be used for scanning.
Why RE/flex?
RE/flex is a new fast and flexible regex-based scanner generator for C++. It shares many similarities with Flex and Lex, but is fundamentally different in its overall design for several reasons. Firstly, the design aims to make RE/flex faster than Flex by using direct-coded DFAs that are typically more efficient to simulate with modern CPUs. Secondly, this design offers a more expressive regex syntax to be used in lexer specifications by supporting other regex libraries, including PCRE2 and Boost.Regex in addition to the built-in RE/flex regex engine. Perhaps other regex libraries will be included in the future to expand the choice of matcher engines. Thirdly, this design produces scanners in humanly-readable source code with a structure that clearly shows the user's actions in source code form exactly as specified in the user's lexer specification.
This powerful new design is made possible by the fact that any regex engine can in principle be used to tokenize input: given a set of n patterns pi, i=1,...,n, a regex of the form "(p1) | (p2) | ... | (pn)" can be used to match and tokenize the input. The group capture index i of a matching pattern pi that is returned by the regex matcher identifies the pattern pi that matched. If a pattern uses a group (X), then that group must be converted to a non-capturing group of the form (?:X) before we can use it in our patterns. We then use repeated partial matching in our scanner to advance over the input to tokenize by executing specific actions corresponding to the patterns matched:
int Lexer::lex()
{
if (!has_matcher())
matcher("(p1)|(p2)|...|(pn)"); while (true)
{
if (... EOF reached ...)
return 0;
switch (matcher().scan()) {
case 1: ... break;
case 2: ... break;
... ...
default:
... }
}
}
The scanner source code generated by the reflex tool is structured in this way and is therefore very different from the source code generated by Flex. The improved source code output is not only humanly readable, it also typically runs faster than Flex code when scanners are generated with reflex option --fast. This reflex option produces an efficient DFA in direct code instead of in tables. For example, the following DFA is generated by reflex option --fast for pattern "\w+", which runs quite efficiently to match words:
void reflex_code_FSM(reflex::Matcher& m)
{
int c1 = 0;
m.FSM_INIT(c1);
S0:
c1 = m.FSM_CHAR();
if (97 <= c1 && c1 <= 122) goto S5;
if (c1 == 95) goto S5;
if (65 <= c1 && c1 <= 90) goto S5;
if (48 <= c1 && c1 <= 57) goto S5;
return m.FSM_HALT(c1);
S5:
m.FSM_TAKE(1);
c1 = m.FSM_CHAR();
if (97 <= c1 && c1 <= 122) goto S5;
if (c1 == 95) goto S5;
if (65 <= c1 && c1 <= 90) goto S5;
if (48 <= c1 && c1 <= 57) goto S5;
return m.FSM_HALT(c1);
}
Another advantage of RE/flex is the rich regex pattern syntax offered by PCRE2 and Boost.Regex, and also by the new RE/flex regex library included with the RE/flex software. The RE/flex regex library supports Unicode, indent/nodent/dedent anchors, lazy quantifiers, word boundaries, and more.
How Fast is RE/flex?
RE/flex is faster than Flex when comparing Flex with the best performance options. RE/flex is also faster than Boost.Spirit.Lex, and much faster than popular regex libraries, such as Boost.Regex, C++11 std::regex, PCRE2 and RE2. For example, tokenizing a representative C source code file into 244 tokens takes only 8 microseconds:
| Command / Function | Software | Time (μs) |
reflex --fast --noindent | RE/flex 1.6.7 | 8 |
reflex --fast | RE/flex 1.6.7 | 9 |
flex -+ --full | Flex 2.5.35 | 17 |
reflex --full | RE/flex 1.6.7 | 18 |
boost::spirit::lex::lexertl::actor_lexer::iterator_type | Boost.Spirit.Lex 1.66.0 | 40 |
pcre2_jit_match() | PCRE2 (jit) 10.32 | 60 |
hs_compile_multi(), hs_scan() | Hyperscan 5.1.0 | 209 |
reflex -m=boost-perl | Boost.Regex 1.66.0 | 230 |
pcre2_match() | PCRE2 (pre-compiled) 10.30 | 318 |
RE2::Consume() | RE2 (pre-compiled) 2018-04-01 | 417 |
reflex -m=boost | Boost.Regex POSIX 1.66.0 | 450 |
RE2::Consume() | RE2 POSIX (pre-compiled) 2018-04-01 | 1226 |
flex -+ | Flex 2.5.35 | 3968 |
std::regex::cregex_iterator() | C++11 std::regex | 5979 |
The table shows the best times of 30 tests with average time in microseconds over 100 runs using Mac OS X 10.12.6 clang 9.0.0 -O2, 2.9 GHz Intel Core i7, 16 GB 2133 MHz LPDDR3. Hyperscan disqualifies as a potential scanner due to its "All matches reported" semantics resulting in 1915 matches for this test and due to its event handler requirements. Download the tests here. The download includes a Dockerfile with instructions to test the performance on practically any system.
The RE/flex matcher tracks line numbers, column numbers, and line indentations, whereas Flex does not in this comparison (disabled with option %option noyylineno) and neither do the other regex matchers in the table, except Boost.Regex used with RE/flex. Tracking this information incurs some overhead. RE/flex indentation tracking is disabled with --noindent to remove the overhead of indentation tracking.
To produce this table with performance statistics as fair as possible, I've used RE/flex option --regexp-file to generate the regex string and used it with each regex library to tokenize a string of C source code stored in memory, thus avoiding the unpredictable overhead of file IO. This regex string has n=56 patterns of the form "(p1) | (p2) | ... | (pn)" where each pi is a pattern to match C/C++ token lexemes. The patterns use non-capturing groups (?:...) to replace parenthesis, which allows the capture group index to identify the token matched. In this way, I tried to made the performance comparisons as fair as possible by measuring the time it takes to tokenize the input stored in memory instead of in files, i.e., to measure raw performance without IO overhead. Of course, performance depends on the hardware and OS so your mileage may vary. However, tests with modern CPUs and OS versions still show that RE/flex is faster than Flex for typical use cases.
Compatibility of RE/flex with Flex and Bison/Yacc
When designing RE/flex using the aforementioned approach, I wanted to make sure that the project is fully compatible with Bison and Yacc parsers. These tools are popular and are typically pre-installed with Linux and Unix distributions. I also wanted to make sure that RE/flex accepts standard Flex specifications (using RE/flex compatibility option --flex). This means that if you are already familiar with Flex or Lex, then you will find RE/flex easy to use. To generate a yyFlexLexer class that has the same methods as a Flex++ yyFlexLexer class, simply use reflex option --flex:
reflex --flex lexspec.l
This generates the scanner source code in lex.yy.cpp. RE/flex is for C++ projects only. Using C++ permitted a significant number of additions to the lexer specification language and permitted the introduction of many new methods that can be used in rule actions, as I will explain further in the next section. However, you can still use RE/flex with C code, such as Bison-generated parsers that expect a global yylex() function. To do so, use the --flex and --bison command-line options or simply --yy to combine these options and force POSIX compliance:
reflex --yy lexspec.l
However, RE/flex also supports options to build Bison reentrant parsers, bison-bridge, bison-locations, and bison-complete parsers. These advanced parsers are MT-safe and manage the locations of syntax errors in cooperation with the lexer.
To get you started with RE/flex, you will find several examples in the RE/flex repository on GitHub and on SourceForge. The examples include Bison parsers, from very basic to more advanced bison-bridge, bison-location, and bison-complete parsers.
The Structure of a RE/flex Lexer Specification
The structure of a lexer specification is the same as Flex, but with some additions. A lexer specification consists of three parts separated by a line with %%: the Definitions section, the Rules section, and the User code section.
- The Definitions section defines named patterns. That is, commonly used regex patterns can be named and used in other patterns as macros. This section may also contain user code: a
%top{...} block with code that goes all the way to the top of the generated scanner source code and the usual %{...%} code blocks copied to the scanner's source code. A %class{...} block defines the lexer class member variables and functions. The %init{...} block defines the lexer class constructor code for initializations. We can also add one or more %option to configure the scanner and define start conditions states with %s and %x. - The Rules section defines pattern-action pairs. Actions are written in C++ and are triggered when the pattern matches.
- The User code section at the end of the specification can be used to add any C++ code necessary. For stand-alone scanners, this typically has a
main() function defined.
The following outlines the basic structure of a RE/flex lexer specification:
%top{
#include <iostream>
}
%{
%}
%class{
public:
void a_public_function();
private:
std::string a_private_string;
}
%init{
a_private_string = "initialized";
}
%option unicode
newline \n
%%
"foo" { a_public_function(); }
"bar" { a_private_string = text(); }
{newline}
. { std::cerr << "unknown character at " << lineno() << ":" << columno(); }
%%
int main()
{
Lexer lexer;
while (lexer.lex() != 0)
continue;
}
Patterns are regular expressions extended with the common Lex/Flex syntax, which means that the named pattern {newline} is expanded into (?:\n), the quoted text "foo" is a literal match of foo, and a slash / (not shown in the example) is a lookahead pattern (traditionally called a trailing context in Lex).
This example shows three built-in functions used in the rule actions: text() that returns the 0-terminated char text matched, lineno(), and columno(). The first two are the same as yytext and yylineno in Flex. Flex-compatible actions are enabled with reflex option --flex.
The following table shows some of the actions of a long list of RE/flex functions that can be used in rule actions:
| RE/flex action | Lex/Flex action | Result |
text() | YYText(), yytext | 0-terminated text match |
str() | n/a | std::string text match |
wstr() | n/a | std::wstring text match |
size() | YYLeng(), yyleng | size of the match in bytes |
wsize() | n/a | number of wide chars matched |
lineno() | yylineno | line number of match (>=1) |
columno() | n/a | column number of match (>=0) |
echo() | ECHO | echo text match |
start(n) | BEGIN n | set start condition to n |
The classic Lex/Flex actions listed in the table can be used in a RE/flex lexer specification with reflex option --flex. Because the matcher library object is accessible in the rule actions via matcher(), you can use it in your rule actions for added power. Here are some useful example matcher() methods:
| RE/flex action | Flex action | Result |
matcher().input() | yyinput() | get next 8-bit char from input |
matcher().winput() | n/a | get wide character from input |
matcher().unput(c) | unput(c) | put back 8-bit char |
matcher().more() | yymore() | concat the next match to this match |
matcher().less(n) | yyless(n) | shrink match length to n |
matcher().line() | n/a | get the entire line as a string containing the match |
These are only a few examples. For a complete list, see the RE/flex user guide.
Unicode Pattern Matching
A scanner generator that cannot handle Unicode is as good as using a typewriter for texting on a mobile phone. Most modern programming languages have Unicode lexical structures that require Unicode-capable scanners to construct parsers and compilers. At least the widely-used UTF-8 encoding format should be natively supported. Scanner generators produce lexers that scan files (in addition to 8-bit strings and perhaps also wide strings), which makes them different from regex engines, i.e., most regex libraries can be used for pattern matching wide strings. To scan files containing Unicode, the files have to be decoded from UTF-8, UTF-16, or UTF-32 (UCS-4) formats. This decoding is done automatically and efficiently on the fly in RE/flex.
Unicode pattern matching is enabled with reflex command-line option --unicode or with %option unicode in a lexer specification:
%option unicode
With this option, the . (dot), \w, \s, \l, \u, \u{XXXX}, and \p{...} patterns match Unicode. These match respectively any Unicode character (except newline \n), a Unicode word character, Unicode space, Unicode lower case letter, Unicode upper case letter, Unicode U+XXXX, and a Unicode character class.
\s+
\w+ { std::cout << text() << "\n"; }
\p{Unicode} { std::cout << "U+" << std::hex << wstr().at(0) << " \n"; }
. { std::cerr << "invalid Unicode!\n"; }
This lexer removes all white space from a file and prints words that are composed of Unicode letters, numerical digits, and connector-punctuation such as underscores. The matched text is printed in UTF-8 format to std::cout with text() (which is the same as yytext in Flex syntax). Any other Unicode characters are printed in U+XXXX code using the first character of the wide string wstr() match. Finally, the . (dot) pattern is used to catch all else, including invalid characters that are outside of the valid Unicode range U+0000 to U+D7FF and U+E000 to U+10FFFF. When UTF-8 or UTF-16 files are scanned, then an invalid UTF encoding such as an overlong form is also matched by . (dot).
To match any valid Unicode character, I recommend to use \p{Unicode}. We only want to use . (dot) for catch-all-else cases as needed. One such case is to match invalid content as shown in the example above to prevent the scanner from jamming on its input when nothing valid matches. For this reason, the . (dot) is designed to be permissive and matches valid Unicode but also matches invalid UTF-8 and UTF-16 sequences in order to catch file encoding errors. I've also made the . (dot) is self-synchronizing, which means that it advances to the next character on the input after matching an invalid character.
Indent, nodent, and dedent Matching
RE/flex takes a direct approach to matching indent, nodent and dedent positions in text by introducing two new anchors, one for indent and one for dedent. These anchors, when combined with a third undent anchor \k, are proven to be sufficiently powerful to handle any complicated indentation rules applied to a document as input to the scanner, such as Python and YAML (tokenizers for Python and YAML are included with RE/flex).
The approach is pretty straightforward. An indent stop position is matched on a new line with the pattern ^[ \t]+\i. Note that ^[ \t]+ matches the margin spacing up to the indent that is matched and set with \i, but only when the margin spacing is increased.
Likewise, a dedent is matched with ^[ \t]*\j. This matches a previous indent stop and removes it from the internal stack.
Because a more significant decrease in margin spacing may result in multiple stop positions to be removed all at once, we should also add a pattern with a single \j anchor to match each extra indent stop. This matches any extra dedents that occur on the same line, one at a time without consuming any input:
^[ \t]+
^[ \t]+\i
^[ \t]*\j
\j
Some articles on the web suggest that Lex/Flex can be used for indentation matching, but they completely neglect the issue of multiple dedents (i.e. the fourth rule above) that cannot reliably work in Lex/Flex.
Note that matching a nodent line that is aligned to the current stop position is done with a pattern that lacks the \i and \j anchors.
Let's see how this works. Say our input to scan is the following:
def abs(n):
if n < 0:
n = -n
return n
else:
return n
Then the four patterns we defined are matched in this order: 2, 2, 1, 3, 2, 3, 3. Note that the first line has no indent margin and no indent stop.
There is no restriction on using white space only for indents, such as [ \t]+, that defines the margin spacing. The margin spacing can be anything, not just spaces and tabs, as long as the pattern does not include a newline character \n.
It may be necessary to temporarily memorize the indent stops when scanning text over multiple lines by patterns that should not change the current indent stop positions, such as line continuations, multi-line comments and expressions that require "line joining" as in Python. This can be done by saving the current indent stops with matcher().push_stops() and retrieving them again with matcher().pop_stops().
For example, to scan a multi-line comment over multiple (indented) lines without affecting the current indent stops, we should save the current stops and transition to a new start condition state CONTINUE:
"/*" matcher().push_stops();
BEGIN CONTINUE;
<CONTINUE>{
"*/" matcher().pop_stops();
BEGIN INITIAL;
.|\n
}
We typically define start condition states, such as CONTINUE in this example, when scanning text that is matched by a different set of patterns and rules. The matcher().push_stops() method resets the indent stop positions. The positions can be accessed directly using matcher().stops() that returns a reference to a std::vector<size_t> with these positions that are ordered from low to high. You can change the vector as long as the low-to-high order is maintained.
There is a quick shortcut for matching multiple lines of text when the text has to be ignored by the scanner, such as multi-line comments and line continuations. To implement line continuations after a \ (backslash) placed at the end of a line, we must ignore the next indent. Similarly, C-style multi-line comments matched with the pattern "/*"(.|\n)*?"*/" (using a lazy repetition (.|\n)*?) should be ignored and not affect the current indent stops. To do this, we use the RE/flex (?^X) negative pattern that consumes text without actions, making the matching part of the input essentially invisible:
(?^"/*".*?"*/")
(?^\\\n[ \t]*)
The negative pattern (?^X) is a RE/flex-specific addition. It is can be very handy to use to skip unwanted input, such as comments, without affecting indent stop positions. However, any action associated with a negative pattern won't be executed because negative patterns skip input and do not trigger a pattern match.
Finally, the undent anchor \k may be used in a pattern. The undent anchor matches when the indent depth changed at or before the position of the anchor \k in its pattern, i.e., when patterns with \i or \j would match too. Anchor \k keeps the current stops intact, essentially undoing the indentation change (i.e. "undenting"). For example, to ignore multi-line comments that may be nested, we can use anchor \k as follows:
%{
int level;
%}
%x COMMENT
%%
^[ \t]+ out() << "| ";
^[ \t]+\i out() << "> ";
^[ \t]*\j out() << "< ";
\j out() << "< ";
[ \t] "/*"\k? level = 1;
start(COMMENT);
.|\n echo();
<COMMENT>{
"/*" ++level;
"*/" if (--level == 0)
start(INITIAL);
.|\n
}
%%
Note that [ \t]*"/*"\k? matches the start of a /*-comment with leading white space. When this space is on the left margin, it is also initially matched by the 2nd rule or the 3rd rule up to the /*, resulting in indent stop changes made by anchors \i and \j, respectively. Even though rule 2 and 3 won't match the /*, but only the space in the margin leading up to the /*, the \i and \j anchors will change the indent stops. Anchor \k restores these stops and matches if the indent stops actually changed. Rule 5 also applies to non-margin /*-comments, with the /*-comments placed anywhere. For these two reasons we made \k optional with \k?.
More details and examples of indent, nodent, dedent, and undent patterns can be found in the RE/flex user guide.
Lazy Repeats Are Nice, but Also Noughty
In the previous section, we saw how to use a lazy repeat (.|\n)*? to match C-style multi-line comments with "/*"(.|\n)*?"*/". The extra ? is called a lazy quantifier and changes the * greedy repeat into a *? non-greedy lazy repeat (also called reluctant repeat). Why is a lazy repeat needed here? Note that the pattern (.|\n) matches any character (. (dot) matches any character except newline \n). The problem is that a greedy repeat (.|\n)* in the pattern "/*"(.|\n)*"*/" eats all matching text including */, but up to the last */ in the input text before EOF. The usual way to work around greedy repeats is to prevent the repeated pattern from matching */, such as "/*"([^*]|\*+[^/])*"*/". By contrast, lazy repeats are simpler and more elegant.
The lazy quantifier ? can be used to make the following greedy patterns lazy:
X??Y
X*?Y
X+?Y
X{n,m}?Y
Take, for example, the pattern (a|b)*?bb. The text abaabb and bb match this pattern, but bbb does not match (actually, there is a partial match since bb matches this pattern, but the third b remains on the input for the next match by a scanner).
What about the pattern a*? that has no continuing pattern Y? This matches nothing. When the pattern Y permits an empty text match or matches the same text as X, then lazyness kills X. To make lazy repeats behave nicely, make sure they are followed by a pattern that matches non-empty text or make sure they are properly anchored. For example, a*?$ matches a series of a's up to the end of the line. However, in this case, lazyness is not required and a greedy pattern a*$ works just fine.
Lazy repeats are not available in POSIX matchers. The concept was introduced in Perl that is regex-based using backtracking on the regex (or by using an alternative form of a matching engine). POSIX matchers are text-based and may use a deterministic finite automaton (DFA) to significantly speed up matching. A DFA-based matcher lacks lazy quantifiers, due to the inability to dynamically evaluate the context in which this form of regex-based information applies.
RE/flex adds lazy quantifiers to its POSIX matcher using a new DFA construction algorithm. A lazy repeat effectively cuts edges from a DFA, but may also lengthen the DFA to permit partial matches until the accept state is reached. Consider the following DFA constructed for regex (a|b)*bb:
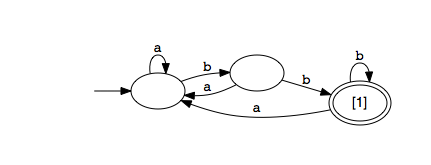
and compare this to the DFA constructed for regex (a|b)*?bb:

As you can see, the second DFA matches any a's and b's until bb is matched.
Using the Smart Input Class to Scan Files
We often have to scan files with text encoded in various popular formats such as UTF-8, UTF-16, UTF-32, ISO-8859-1, and sometimes even older encoding formats such as code pages 850, CP-1252, and EBCDIC. To support multiple input file formats, the RE/flex reflex::Input class converts the input format on the fly while scanning input by using a smart buffering technique. This smart buffering does not require the entire file to be read first, allowing the implementation of streaming lexers and regex matchers. The streaming converter detects UTF byte order marks (BOM) in files to enable automatic UTF-8/16/32 conversion by normalizing the text to UTF-8 for matching. In fact, when Unicode mode for matching is enabled with %option unicode, the input should be UTF encoded in this way.
If the input file is encoded in EBCDIC, ISO-8859-1 or extended Latin-1, then you should determine this in your code and set the decoding flag to use this file with a RE/flex lexer. For example, as follows:
#include "lex.yy.h" // generated with reflex --flex --header-file
int main()
{
FILE *fd = fopen("iso-8859-1-example-file.txt", "r"); if (fd != NULL)
{
reflex::Input input(fd, reflex::Input::file_encoding::latin); yyFlexLexer lexer(input); while (lexer.yylex() != 0) continue;
fclose(fd); }
}
RE/flex has built-in support for UTF encodings, ISO-8859-1 to 16, MACROMAN, EBCDIC, KOI8, and code pages 437, 850, 858, 1250 to 1258. You can also define a custom code page to be used by the smart input class that will then custom-translate 8-bit characters to Unicode using the specified code page entries.
Error Handling
Input error handling by a scanner and parser is extremely important. A compiler or interpreter is only as good as its error reporting to the user. Syntax errors in the input and semantic errors in the program should be reported in detail. To this end, Bison parsers typically invoke the function yyerror() on a syntax error. The same function can be used by a scanner to report erroneous input.
RE/flex offers several methods to assist with error reporting. The first and foremost is matcher().line() and its wide string variant matcher().wline(). These return the input line with the (mis)match as a (wide) string. This makes it easy to report errors in the input of line-based scanners such as interpreters:
void yyerror(Lexer *lexer, const char *msg)
{
std::string line = lexer->matcher().line();
std::cerr << "Error: " << msg << " at " <<
lexer->lineno() << "," << lexer->columno() << "\n" <<
line << ":\n";
for (size_t i = lexer->columno(); i > 0; --i)
std::cerr << " ";
std::cerr << "\\__ here" << std::endl;
}
Here, we want to pass the Lexer object to yyerror(). To do so, we use %option bison-bridge that generates code that passes the Lexer object to lexer functions as documented in Flex and also in RE/flex. The bison-bridge parser invokes yyerror() and we can do the same in our lexer specification (a calc.l and calc.y calculator example that uses this approach is included with RE/flex):
. yyerror(this, "mystery character");
If the input is not line-based, parsers may report a syntax error for a line that it has long passed over after which the error is detected. This means that the offending input has to be retrieved from the file and reported. Assuming we have a bison-complete parser yy::parser with bison-locations enabled, the following user-defined error() method reports the error regardless of the location and how many offending lines in the input file are to be reported:
void yy::parser::error(const location& loc, const std::string& msg)
{
std::cerr << loc << ": " << msg << std::endl;
if (loc.begin.line == loc.end.line && loc.begin.line == lexer.lineno())
{
std::cerr << lexer.matcher().line() << std::endl;
for (size_t i = 0; i < loc.begin.column; ++i)
std::cerr << " ";
for (size_t i = loc.begin.column; i <= loc.end.column; ++i)
std::cerr << "~";
std::cerr << std::endl;
}
else
{
FILE *file = lexer.in().file(); if (file != NULL)
{
yy::scanner::Matcher *m = lexer.new_matcher(file); lexer.push_matcher(m); off_t pos = ftell(file); fseek(file, 0, SEEK_SET); for (size_t i = 1; i < loc.begin.line; ++i)
m->skip('\n'); for (size_t i = loc.begin.line; i <= loc.end.line; ++i)
{
std::cerr << m->line() << std::endl; m->skip('\n'); }
fseek(file, pos, SEEK_SET); lexer.pop_matcher(); }
}
}
This example uses matcher().line() as well as a temporary matcher in the else-branch to seek the position in the input file to advance to using matcher().skip('\n'), which requires a seekable file as input. See also the RE/flex user guide for more details, in particular, the various RE/flex and Bison options used to make this work.
Performance Tuning
There are several reflex command-line options to debug a lexer and analyze its performance given some input text to scan. Command-line option -d generates a scanner that prints the matched text. Option -p generates a scanner that prints a performance report. The report shows the performance statistics obtained for each rule defined in the lexer specification. The statistics are collected while the scanner runs on some given input.
The -p option allows you to fine-tune the performance of your scanner by focusing on patterns and rules that turn out to be computationally expensive. This is perhaps best illustrated with an example. The JSON parser json.l located in the examples directory of the RE/flex download package was built with reflex option -p and then run on some given JSON input to analyze its performance:
reflex 0.9.22 json.l performance report:
INITIAL rules matched:
rule at line 51 accepted 58 times matching 255 bytes total in 0.009 ms
rule at line 52 accepted 58 times matching 58 bytes total in 0.824 ms
rule at line 53 accepted 0 times matching 0 bytes total in 0 ms
rule at line 54 accepted 0 times matching 0 bytes total in 0 ms
rule at line 55 accepted 0 times matching 0 bytes total in 0 ms
rule at line 56 accepted 5 times matching 23 bytes total in 0.007 ms
rule at line 57 accepted 38 times matching 38 bytes total in 0.006 ms
rule at line 72 accepted 0 times matching 0 bytes total in 0 ms
default rule accepted 0 times
STRING rules matched:
rule at line 60 accepted 38 times matching 38 bytes total in 0.021 ms
rule at line 61 accepted 0 times matching 0 bytes total in 0 ms
rule at line 62 accepted 0 times matching 0 bytes total in 0 ms
rule at line 63 accepted 0 times matching 0 bytes total in 0 ms
rule at line 64 accepted 0 times matching 0 bytes total in 0 ms
rule at line 65 accepted 0 times matching 0 bytes total in 0 ms
rule at line 66 accepted 0 times matching 0 bytes total in 0 ms
rule at line 67 accepted 0 times matching 0 bytes total in 0 ms
rule at line 68 accepted 314 times matching 314 bytes total in 0.04 ms
rule at line 69 accepted 8 times matching 25 bytes total in 0.006 ms
rule at line 72 accepted 0 times matching 0 bytes total in 0 ms
default rule accepted 0 times
WARNING: execution times are relative:
1) includes caller's execution time between matches when yylex() returns
2) perf-report instrumentation adds overhead and increases execution times
The timings shown include the time of the pattern match and the time of the code executed by the rule. If the rule returns to the caller, then the time spent by the caller is also included in this timing. For this example, we have two start condition states, namely INITIAL and STRING. The rule at line 52 is:
[][}{,:] { return yytext[0]; }
This returns a [ or ] bracket, a { or } brace, a comma, or a colon to the parser. Since the pattern and rule are very simple, we do not expect these to contribute much to the 0.824 ms time spent on this rule. The parser code executed when the scanner returns could be expensive. Depending on the character returned, the parser constructs a JSON array (bracket) or a JSON object (brace), and populates arrays and objects with an item each time a comma is matched. But which is most expensive? To obtain timings of these events separately, we can split the rule up into three similar rules:
[][] { return yytext[0]; }
[}{] { return yytext[0]; }
[,:] { return yytext[0]; }
Then, we use reflex option -p, recompile the scanner lex.yy.cpp. and rerun our experiment to see these changes:
rule at line 52 accepted 2 times matching 2 bytes total in 0.001 ms
rule at line 53 accepted 14 times matching 14 bytes total in 0.798 ms
rule at line 54 accepted 42 times matching 42 bytes total in 0.011 ms
So it turns out that the construction of a JSON object by the parser is, relatively speaking, the most expensive part of our application, when { and } are encountered on the input. We should focus our optimization effort there if we want to improve the overall speed of our JSON parser.
The JSON lexer and parser source code used in this example are available for download with this article.
Interactive Input With Readline
Shells, interpreters, and other interactive command-line tools allow users to enter commands that are interpreted and executed by the application. The GNU readline library greatly enhances the interactive experience by offering a history mechanism and line-based editing. By contrast, simple interactive input by reading standard input gives users a cumbersome experience.
To use readline with RE/flex is a good example of how we can use the Flex-like wrap() function to our advantage. The wrap() function is invoked when EOF is reached, to permit a new input source to be assigned to continue scanning. In this example, readline() returns a line of input that we scan as a string. When the scanner reaches the end of this string, it triggers the wrap() function, which is set up to return the next line returned by readline(), etc.
The lexer specification we give here first includes the required C header files in the %top block and then defines the lexer class wrap() function in the %class block and the lexer class construction in the %init block:
%top{
#include <stdlib.h>
#include <stdio.h>
#include <readline/readline.h>
#include <readline/history.h>
}
%class{
const char *prompt;
virtual bool wrap() {
if (line)
{
free((void*)line);
line = readline(prompt);
if (line != NULL)
{
if (*line)
add_history(line);
linen.assign(line).push_back('\n');
in(linen);
}
}
return line == NULL ? false : true;
}
char *line;
std::string linen;
}
%init{
prompt = NULL;
line = readline(prompt);
if (line != NULL)
{
if (*line)
add_history(line);
linen.assign(line).push_back('\n');
}
in(linen);
}
A readline-based example lexer similar to this example, but using Flex actions, is available for download with this article.
Conclusions
RE/flex is not merely a C++ version of Flex. It adds many new useful features that Flex lacks, including critically required Unicode pattern matching, improved error reporting functions, smart input handling to accept input encoded in UTF-8/16/32 (with or without UTF BOM "Byte Order Mark"), ASCII, ISO-8859-1 to 16, EBCDIC, various code pages, lazy repeats in POSIX mode, and the generation of direct-coded DFAs in efficient C++ source code.
RE/flex also offers a uniform regex API for the four common methods of pattern matching: find, scan (continuous find), split, and matches. This uniform API is more than just a wrapper for PCRE2, Boost.Regex, RE/flex regex, and C++11 std::regex. This API offers a uniform interface to select the appropriate regex pattern matcher class to perform find, scan, split, and matches operations. This easy-to-use API can be used in any C++ application to match input from strings, streams, and file descriptors for files encoded in UTF or other formats. This API is effectively used in ugrep, an ultra fast and interactive grep-like tool written in C++11.
Further Reading
To learn more about RE/flex, I encourage you to read Constructing Fast Lexical Analyzers with RE/flex and the RE/flex user guide.
Download & License
RE/flex is available for download form SourceForge and GitHub. RE/flex is free open source licensed under the BSD-3 license.
History
- 25th April, 2017: First version of this article
- 30th April, 2017: Some cosmetic updates
- 16th May, 2017: Minor updates for clarification
- 25th June, 2017: Added download icon and explained the use of code pages
- 31st July, 2019: Expanded indent/nodent/dedent section with
\k anchor - 8th August, 2019: Updated performance comparisons to include RE/flex version 1.3.5
- 5th February, 2020: Added new section on Error Handling; updated performance comparisons
- 30th April 2020: Added PCRE2 as a regex engine option; updated examples and performance comparisons

