This article details the atomic operations and C++11 memory barriers and the assembler instructions generated by it on x86_64 CPUs.
Three related articles:
- We make any object thread-safe
- We make a
std::shared_mutex 10 times faster - Thread-safe std::map with the speed of lock-free map
Introduction
High Performance of Lock-Based Data Structures
In this article, we will detail the atomic operations and C++11 memory barriers and the assembler instructions generated by it on x86_64 CPUs.
Next, we’ll show how to speed up the work of contfree_safe_ptr<std::map> up to the level of complex and optimized lock-free data structures that are similar to std::map<> in terms of their functionality, for example: SkipListMap and BronsonAVLTreeMap from libCDS library (Concurrent Data Structures library): https://github.com/khizmax/libcds.
And we can get such multi-threaded performance for any of your initially non-thread-safe T-class used as contfree_safe_ptr<T> – it is safe_ptr<T, contention_free_shared_mutex> class, where contention_free_shared_mutex is own optimized shared-mutex.
Namely, we will show how to realize your own high-performance contention-free shared-mutex, which almost does not conflict on readings. We implement our own active locks - spinlock and recursive-spinlock - to lock the rows in the update operations. We will create RAII-blocking pointers to avoid the cost of multiple locking. Here are the results of performance tests.
And as «Just for fun» bonus, we will demonstrate the way of realization of our own class of simplified partitioned type partitioned_map, which is even more optimized for multithreading, consisting of several std::map, in analogy with partition table from RDBMS, when the boundaries of each section are known initially.
Background
Fundamentals of Atomic Operations
Let’s consider the fundamentals of multithreading, atomicity and memory barriers.
If we change the same data from a set of threads, i.e., if we run the thread_func() function simultaneously in several threads:
int a;
void thread_func() { a = a + 1; }
then each thread calling the thread_func() function adds 1 to the ordinary shared variable int a; In the general case, such a code will not be thread-safe, because compound operations (RMW - read-modify-write) with the ordinary variables consist of many small operations, between which another thread can change the data. The operation a = a+1; consists of at least three mini-operations:
- Load the value of the variable “
a” into the CPU register - Add
1 to the value in the register - Write the value of the register back into the variable “
a”
For non-atomic int a, if initially a=0; and 2 threads perform the operation a=a+1; then the result should be a=2; But the following can happen (step by step):
int a = 0; Thread 1: register1 = a; Thread 2: register2 = a Thread 1: register1++; Thread 2: register2++; Thread 1: a = register1; Thread 2: a = register2;
Two threads added +1 to the same global variable with initial value = 0, but in the end, the variable a = 1 - such a problem is called Data-Races.
There are three ways that help to avoid such a problem:
- To use atomic instructions with atomic variables - but there is one disadvantage, the number of atomic functions is very small - therefore, it is difficult to realize complex logic with the help of such functions: http://en.cppreference.com/w/cpp/atomic/atomic
- To develop your own complex lock-free algorithms for each new container.
- To use locks (
std::mutex, std::shared_timed_mutex, spinlock…) – they admit 1 thread, one by one, to the locked code, so the problem of data-races does not arise and we can use arbitrary complex logic by using any normal not thread-safe objects.
For std::atomic<int> a: if initially a=0; and 2 threads perform the operation a+=1; then the result always will be a=2;
std::atomic<int> a;
void thread_func() { a += 1; }
The following always happens on x86_64 CPU (step by step):
std::atomic<int> a = 0;
Thread 1: register1 = a; Thread 1: register1++; Thread 1: a = register1;
Thread 2: register2 = a; Thread 2: register2++; Thread 2: a = register2;
On processors with LL/SC-support, for example on ARM, other steps occur, but with the same correct result: a = 2.
Atomic variables are introduced into the standard C++11: http://en.cppreference.com/w/cpp/atomic/atomic
std::atomic<> template class members functions are always atomic.
Here are three fragments of the correct code identical in meaning:
- Example:
std::atomic< int > a;
a = 20;
a += 50;
- It is identical to example 1:
std::atomic< int > a;
a.store( 20 );
a.fetch_add( 50 );
- It is identical to example 1:
std::atomic< int > a;
a.store( 20, std::memory_order_seq_cst );
a.fetch_add( 50, std::memory_order_seq_cst );
It means that for std::atomic:
load() and store() is equal to operator= and operator Tfetch_add() and fetch_sub() is equal to operator+= and operator-=- Sequential Consistency
std::memory_order_seq_cst is the default memory barrier (the most strict and reliable, but also the slowest with regard to others).
Let’s note the difference between std::atomic and volatile in C++11: http://www.drdobbs.com/parallel/volatile-vs-volatile/212701484
There are five main differences:
- Optimizations: For
std::atomic<T> a; two optimizations are possible, which are impossible for volatile T a;
- Optimization of the fusion:
a = 10; a = 20; can be replaced by compiler with a = 20; - Optimization of substitution by a constant:
a = 1; local = a; can be replaced by the compiler a = 1; local = 1;
- Reordering:
std::atomic<T>a; operations can limit reordering around themselves for operations with the ordinary variables and operations with other atomic variables in accordance with the used memory barrier std::memory_order _... In contrast, volatile T a; does not affect the order of regular variables (non-atomic / non-volatile), but the calls to all volatile variables always preserve a strict mutual order, i.e., the order of execution of any two volatile-operations cannot be changed by the compiler, but this order can be changed by the CPU/PCI-express/other device where the buffer with this volatile variable is physically located. - Spilling:
std::memory_order_release, std::memory_order_acq_rel, std::memory_order_seq_cst memory barriers, which are specified for std::atomic<T> a; operations, initiate spilling of all regular variables before execution of an atomic operation. That is to say that these barriers upload the regular variables from the CPU registers into the main memory/ cache, except when the compiler can guarantee 100% that this local variable cannot be used in other threads. - Atomicity / alignment: For
std::atomic<T> a; other threads see that operation has been performed entirely or not performed at all. For Integral-types T, this is achieved by alignment of the atomic variable location in memory by compiler - at least, the variable is in a single cache line, so that the variable can be changed or loaded by one operation of the CPU. Conversely, the compiler does not guarantee the alignment of the volatile variables. Volatile-variables are commonly used to access the memory of devices (or in other cases), so an API of the device driver returns a pointer to volatile variables, and this API ensures alignment if necessary. - Atomicity of RMW-operations (read-modify-write): For
std::atomic<T> a; operations ( ++, --, += , -= , *=, /=, CAS, exchange) are performed atomically, i.e., if two threads do operation ++a; then the a-variable will always be increased by 2. This is achieved by locking cache-line (x86_64) or by marking the cache line on CPUs that support LL/SC (ARM, PowerPC) for the duration of the RMW-operation. Volatile variables do not ensure atomicity of compound RMW-operations.
There is one general rule for the variables std::atomic and volatile: each read or write operation always calls the memory/ cache, i.e., the values are never cached in the CPU registers.
Also, we note that any optimizations and any reordering of independent instructions relative to each other done by the compiler or CPU are possible for ordinary variables and objects (non-atomic/non-volatile).
Recall that operations of writing to memory with atomic variables with std::memory_order_release, std::memory_order_acq_rel and std::memory_order_seq_cst memory barriers guarantee spilling (writing to the memory from the registers) of all non-atomic/non-volatile variables, which are in the CPU registers at the moment, at once: https://en.wikipedia.org/wiki/Register_allocation#Spilling.
Changing the Order of Instructions Execution
The compiler and processor change the order of instructions to optimize the program and to improve its performance.
Here is an example of optimizations that are done by the GCC compiler and CPU x86_64: https://godbolt.org/g/n91hpt.
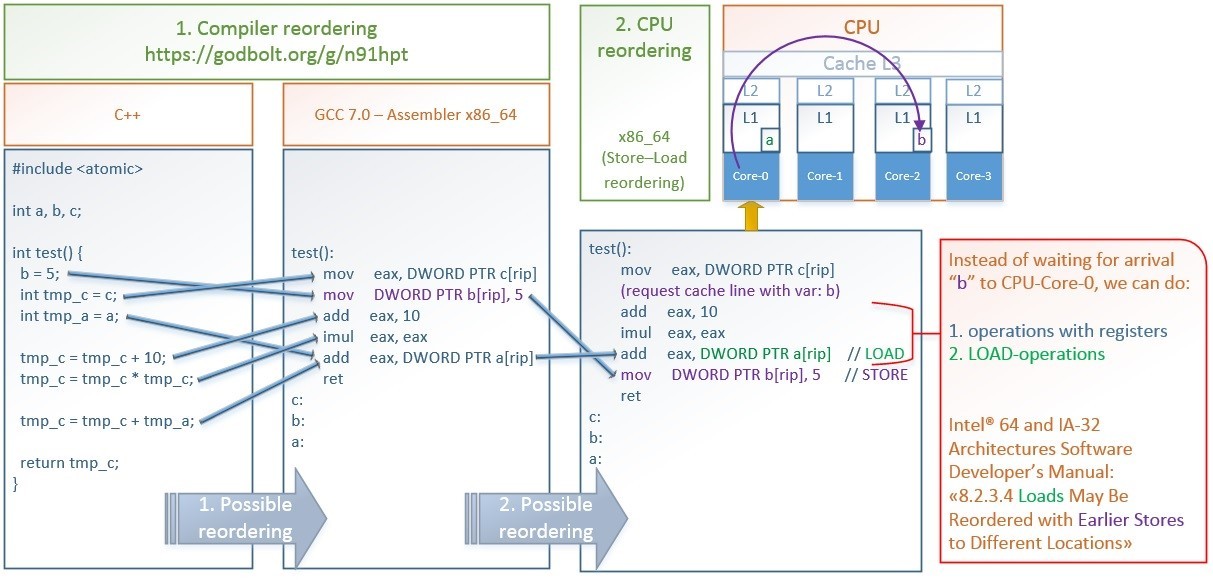
Full size picture: https://hsto.org/files/3d2/18b/c7b/3d218bc7b3584f82820f92077096d7a0.jpg
Optimizations shown in picture:
- GCC 7.0 compiler reordering:
- It interchanges writing to the memory
b = 5; and uploading from the memory to the register int tmp_c = c ;. This allows you to ask for the “c” value as early as possible, and while the CPU is waiting for this long operation, the CPU pipeline allows the execution of operation b = 5; as these 2 operations do not depend on each other. - It combines uploading from the memory into the register
int tmp_a = a; and the addition operation - tmp_c = tmp_c + tmp_a; in the result, we have one operation add eax, a[rip] instead of two operations.
- x86_64 CPU reordering:
The CPU can exchange the actual writing to the memory mov b[rip], 5 and reading from the memory, which is combined with the addition operation - add eax, a[rip].
Upon initiating the writing to the memory through mov b[rip], 5 instruction, the following occurs: first, the value of 5 and the address of b[rip] are placed in the Store-buffer queue, the cache lines containing the address b[rip] in all the CPU cores are expected to be invalidated and a response from them is being waited, then CPU-Core-0 sets the “eXclusive” status for the cache line containing b[rip]. Only after that, the actual writing of the value of 5 from the Store-buffer is carried out into this cache line at b[rip]. For more details about the cache-coherency protocols on x86_64 MOESI / MESIF, changes in which are visible in terms of all the cores immediately, see this link.
In order not to wait all this time - immediately after “5” is placed in the Store-Buffer, without waiting for the actual cache entry, we can start execution of the following instructions: reading from the memory or registers operations. This is what the x86_64 CPU performs:
Intel® 64 and IA-32 Architectures Software Developer’s Manual Volume 3 (3A, 3B, 3C & 3D): System Programming Guide.
Quote:
8.2.3.4 Loads May Be Reordered with Earlier Stores to Different Locations
The Intel-64 memory-ordering model allows a load to be reordered with an earlier store to a different location. However, loads are not reordered with stores to the same location.
CPUs of the x86_64 family have a strong memory model. And CPUs that have a weak memory model, for example, PowerPC and ARM v7/v8, can perform even more reorderings.
Here are the examples of possible reordering of an entry in the memory of ordinary variables, volatile-variables and atomic variables.

This code with ordinary variables can be reordered by the compiler or by the CPU, because its meaning does not change within one thread. But within a set of threads, such reordering can affect the logic of the program.
If two variables are volatile, then the following reordering is possible. The compiler cannot reorder operations on volatile variables at compile-time, but the compiler allows the CPU to do this reordering at run-time.
To prevent all or only some of the reordering, there are atomic operations (recall that atomic operations use the most stringent memory barrier - std::memory_order_seq_cst by default).
Another thread can see the changes of the variables in the memory exactly in this modified order.
If we do not specify the memory barrier for an atomic operation, then the most strict barrier std::memory_order_seq_cst is used by default, and no atomic or non-atomic operations can be reordered with such operations (but there are exceptions that we will consider later).
In the above case, we first write to the ordinary variables a and b, and then - to the atomic variables a_at and b_at, and this order cannot be changed. Also, writing to memory b_at cannot occur earlier than writing to memory a_at. But writing to the variables a and b can be reordered relative to each other.
When we say “can be reordered”, this means that they can, but not necessarily. It depends on how the compiler decides to optimize the C++ code during compilation, or how the CPU decides to do that at runtime.
Below, we will consider more weak memory barriers, which allow reordering the instructions in the allowed directions. This allows the compiler and CPU to better optimize the code and increase the performance.
Barriers of Reordering of Memory Operations
The C++11 standard memory model provides us with 6 types of memory barriers that correspond to the capabilities of modern CPUs for speculative execution. By using them, we do not completely prohibit the change of the order, but we prohibit it only in the necessary directions. This allows the compiler and the CPU to optimize the code as much as possible. And the forbidden directions of reordering allow us to keep correctness of our code. http://en.cppreference.com/w/cpp/atomic/memory_order
enum memory_order {
memory_order_relaxed,
memory_order_consume,
memory_order_acquire,
memory_order_release,
memory_order_acq_rel,
memory_order_seq_cst
};
memory_order_consume. Immediately, we note that we practically will not use memory_order_consume barrier, because in the standard, there are doubts about the practicability of its usage - a quotation from the standard.
Quote:
§29.3
(1.3) — memory_order_consume: a load operation performs a consume operation on the affected memory location. [ Note: Prefer memory_order_acquire, which provides stronger guarantees than memory_order_consume. Implementations have found it infeasible to provide performance better than that of memory_order_acquire. Specification revisions are under consideration. — end note ]
memory_order_acq_rel. Also, we note that memory_order_acq_rel barrier is used only for atomic compound operations of RMW (Read-Modify-Write), such as: compare_exchange_weak()/_strong(), exchange(), fetch_(add, sub, and, or, xor) or their corresponding operators: http://en.cppreference.com/w/cpp/atomic/atomic
The remaining four memory barriers can be used for any operations, except for the following: “acquire” is not used for store(), and “release” is not used for load().
Depending on the chosen memory barrier, for the compiler and the CPU, it is prohibited to move the executable code relative to the barrier in different directions.
Now let’s see what the arrows specify and what can be interchanged and what cannot be interchanged:
For two instructions to be interchanged, it is necessary that the barriers of both the instructions allow such an interchange. Because “other any code” means the ordinary non-atomic variables that do not have any barriers, then they allow any order changes. By the example of Relaxed-Release-Relaxed, as you can see, the possibility to change the order of the same memory barriers depends on the sequence of their appearance.
Let’s consider, what do these memory barriers mean and what advantages they give us, by the example of realization of the simplest “spin-lock” type lock, which requires the most common Acquire-Release reordering semantics. Spin-lock is a lock that is similar to std::mutex in terms of its way of use.
First, we realize the spin-lock concept direct in the body of our program. And then, we realized a separate spin-lock class. To realize locks (mutex, spinlock ...), you should use Acquire-Release semantics, C++11 Standard § 1.10.1 (3).
Quote:
§ 1.10.1 (3)
… For example, a call that acquires a mutex will perform an acquire operation on the locations comprising the mutex. Correspondingly, a call that releases the same mutex will perform a release operation on those same locations. Informally, performing a release operation on A forces prior side effects on other memory locations to become visible to other threads that later perform a consume or an acquire operation on A.
The main point of the Acquire-Release semantics is that: Thread-2 after performing the flag.load(std::memory_order_acquire) operation should see all the changes to any variables/structures/classes (not even atomic ones) that have been made by Thread-1 before it executed the flag.store(0, std::memory_order_release) operation.
The basic purpose of locks (mutex, spinlock ...) is creation of a part of code that can be executed only by one thread at the same time. Such a code area is called the critical section. Inside it, you can use any normal code, including those without std::atomic<>.
Memory barriers prevent the compiler from optimizing the program so that no operation from the critical section goes beyond its limits.
The thread, which captures the lock first, executes this lock of the code, and the remaining threads wait in the cycle. When the first thread releases the lock, the CPU decides which next of the waiting threads will capture it, etc.
Here are two identical examples:
- by using
std::atomic_flag:[19] http://coliru.stacked-crooked.com/a/1ec9a0c2b10ce864 - by using
std::atomic<int>:[20] http://coliru.stacked-crooked.com/a/03c019596b65199a
Example-1 is more preferable. Therefore, for it, we will schematically show the intent of using memory barriers - solid blue shows atomic operations:
[19] http://coliru.stacked-crooked.com/a/1ec9a0c2b10ce864
The purpose of the barriers is very simple - the compiler optimizer is not allowed to move instructions from the critical section to the outside:
- No instruction placed after
memory_order_acquire can be executed before it. - No instruction placed before
memory_order_release can be executed after it.
Any other changes in the order of execution of independent instructions can be performed by the compiler (compile-time) or by the CPU (run-time) in order to optimize the performance.
For example, the line int new_shared_value = shared_value; can be executed before lock_flag.clear(std::memory_order_release);. Such reordering is acceptable and does not create data-races, because the entire code, which accesses the data that is common for multiple threads, is always enclosed within two barriers - “acquire” and “release”. And outside, there is a code that works only with the thread local data, and it does not matter in which order it will be executed. The thread local dependencies are always stored in a way similar to that of single-threaded execution. That is why, int new_shared_value = shared_value; cannot be executed before shared_value + = 25;
What exactly is the compiler doing in std::memory_order:
- 1, 6: The compiler generates the assembler instructions acquire-barrier for the load operation and the release-barrier for the store operation, if these barriers are necessary for the given CPU architecture
- 2: The compiler cancels the previous caching of variables in the CPU registers in order to reload the values of these variables changed by another thread - after the
load(acquire) operation - 5: The compiler saves the values of all variables from the CPU registers to the memory so that they can be seen by other threads, i.e., it executes spilling (link) - up to store(release)
- 3, 4: The compiler prevents the optimizer from changing the order of the instructions in the forbidden directions - indicated by red arrows
And now let’s see what happens, if we use Relaxed-Release semantics instead of Acquire-Release:
- On the left. In case of Acquire-Release, everything is executed correctly.
- On the right. In case of Relaxed-Release, part of the code inside the critical section, which is protected by a lock, can be moved outside by the compiler or CPU. Then, there will be a problem with Data Races - a lot of threads will start to work simultaneously with the data, which are not processed by atomic operations, before locking.
Note that it is usually impossible to implement all logic in relation to general data only with the help of atomic operations, since there are very few of them and they are rather slow. Therefore, it is simpler and faster to do the following actions: to set the flag “closed” by means of one atomic operation, to perform all non-atomic operations in relation to the data common to the threads, and to set the flag “open”.
We will show this process schematically in time:
For example, two threads start executing the add_to_shared() function:
- Thread-1 comes a little earlier and performs 2 operations at a time by means of one atomic instruction
test_and_set(): it performs checkup and if lock_flag == false, then it sets the “true” value to it (that is, locks spin-lock) and returns “false”. Therefore, the while(lock_flag.test_and_set()); expression ends immediately and the code of the critical section starts to be executed. - At this point, thread-2 also starts executing this atomic instruction
test_and_set(): it performs checkup and if lock_flag == false, then it sets the “true” value. Otherwise, it does not change anything and returns the current “true” value. Therefore, the while(lock_flag.test_and_set()); expression will be executed until, while(lock_flag); - Thread-1 performs the addition operation
shared_value += 25; and then sets the lock_flag=false value by means of an atomic operation (that is, unlocks spin-lock). - Finally, thread-2, after finishing waiting for the condition
lock_flag == false, assigns lock_flag = true, returns “false” and completes the cycle. Then it performs the addition of shared_value + = 25; and assigns lock_flag = false (unlocks spin-lock).
At the beginning of this chapter, we gave 2 examples:
- by using
std::atomic_flag and test_and_set():[21] http://coliru.stacked-crooked.com/a/1ec9a0c2b10ce864 - by using
std::atomic<int> and compare_exchange_weak():[22] http://coliru.stacked-crooked.com/a/03c019596b65199a
For more details, see: http://en.cppreference.com/w/cpp/atomic/atomic
Let’s see how the assembler code for x86_64, which is generated by GCC compiler, differs from these two examples:
To be convenient in use, it can be combined into one class:
class spinlock_t {
std::atomic_flag lock_flag;
public:
spinlock_t() { lock_flag.clear(); }
bool try_lock() { return !lock_flag.test_and_set(std::memory_order_acquire); }
void lock() { for (size_t i = 0; !try_lock(); ++i)
if (i % 100 == 0) std::this_thread::yield(); }
void unlock() { lock_flag.clear(std::memory_order_release); }
};
Example of usage of spinlock_t: [23] http://coliru.stacked-crooked.com/a/92b8b9a89115f080
The following table will help you to understand which barrier you should use and what it will be compiled into:
Full size picture: https://hsto.org/files/4f8/7b4/1b6/4f87b41b64a54549afca679af1028f84.jpg
You should necessarily know the following information, only if you write a code in assembler x86_64, when the compiler cannot interchange the assembler instructions for optimization:
seq_cst. The main difference (Clang and MSVC) from GCC is when you use the Store operation for the Sequential Consistency semantics, namely: a.store (val, memory_order_seq_cst); - in this case, Clang and MSVC generate the [LOCK] XCHG reg, [addr] instruction, which cleans the CPU-Store-buffer in the same way as the MFENCE barrier does. And GCC in this case uses two instructions MOV [addr], reg and MFENCE.RMW (CAS, ADD…) always seq_cst. As all atomic RMW (Read-Modify-Write) instructions on x86_64 have the LOCK prefix, which cleans the Store-Buffer, they all correspond to the Sequential-Consistency semantics at the assembler code level. Any memory_order for RMW generate an identical code, including memory_order_acq_rel.LOAD(acquire), STORE(release). As you can see, on x86_64, the first 4 memory barriers (relaxed, consume, acquire, release) generate an identical assembler code - i.e., x86_64 architecture provides the acquire-release semantics automatically. Besides, it is provided by the MESIF (Intel) / MOESI (AMD) cache coherency protocols. This is only true for the memory allocated by the usual compiler tools, which is marked by default as Write Back (but it’s not true for the memory marked as Un-cacheable or Write Combined, which is used for work with the Mapped Memory Area from Device - only Acquire- Semantic is automatically provided in it).
As we know, dependent operations cannot ever be reordered anywhere, for example: (Read-X, Write-X) or (Write-X, Read-X)
- Slides from speech of Herb Sutter for x86_64: https://onedrive.live.com/view.aspx?resid=4E86B0CF20EF15AD!24884&app=WordPdf&authkey=!AMtj_EflYn2507c
In x86_64, any of the following cannot be reordered:
Quote:
- Read-X – Read-Y
- Read-X – Write-Y
- Write-X – Write-Y
- In x86_64, any of the following can be reordered: Write-X <–> Read-Y. To prevent it, the
std::memory_order_seq_cst barrier, which can generate four options of a code in x86_64, depending on the compiler, is used: http://www.cl.cam.ac.uk/~pes20/cpp/cpp0xmappings.html
Quote:
- load: MOV (from memory) store: MOV (to memory), MFENCE
- load: MOV (from memory) store: LOCK XCHG (to memory)
- load: MFENCE + MOV (from memory) store: MOV (to memory)
- load: LOCK XADD ( 0, from memory ) store: MOV (to memory)
A summary table of correspondence between the memory barriers and the CPU instructions for architectures (x86_64, PowerPC, ARMv7, ARMv8, AArch64, Itanium): http://www.cl.cam.ac.uk/~pes20/cpp/cpp0xmappings.html
You can have a look at a real assembler code for different compilers by clicking the following links. And also, you can choose other architectures: ARM, ARM64, AVR, PowerPC.
GCC 6.1 (x86_64):
Clang 3.8 (x86_64):
Besides, we will demonstrate briefly in a table, what effect the various memory barriers have on the order in relation to CAS (Compare-and-swap) - instructions: http://en.cppreference.com/w/cpp/atomic/atomic/compare_exchange
Examples of Reordering Memory Access Operations
Now we’ll show more complex examples of reordering from four consecutive operations: LOAD, STORE, LOAD, STORE.
- Blue rectangles specify atomic operations.
- Dark blue rectangles inside light blue ones (in examples 3 and 4) are parts of the compound atomic Read-Modify-Write (RMW) instructions that consist of several operations.
- White rectangles are common non-atomic operations.
We’ll give four examples. Each example will demonstrate possible reordering of operations with ordinary variables around the operations with atomic variables. But only in examples 1 and 3, some reordering of atomic operations among themselves is also possible.
1st case is interesting in that several critical sections can be fused into one.
The compiler cannot perform such a reordering at compile-time, but the compiler allows the CPU to do this reordering at run-time. Therefore, the fusion of critical sections that run in different sequences in different threads can not lead to a deadlock, because the initial sequence of instructions will be visible to the processor.
Therefore, the processor will try to enter into the second critical section in advance, but if it cannot, it will continue completing the first critical section.
3rd case is interesting in that the parts of two compound atomic instructions can be reordered:
STORE A ⇔ LOAD B
- This is possible with PowerPC architecture, where compound operations consist of 3 separate ASM instructions (
lwarx, addi, stwcx), and their atomicity is achieved by means of LL / SC technique (wiki-link); for the assembler code, see: godbolt.org/g/j8uw7n The compiler cannot perform such a reordering at compile-time, but the compiler allows the CPU to do this reordering at run-time.
2nd case is interesting in that std::memory_order_seq_cst is the strongest barrier and would seem to prohibit any reordering of atomic or non-atomic operations around itself. But seq_cst-barriers have only one additional property compared to acquire / release - only if both atomic operations have a seq_cst-barrier, then the sequence of operations STORE-A (seq_cst); LOAD-B (seq_cst); cannot be reordered. Here are two quotes from C++ standard:
1. Strict mutual order of execution is retained only for operations with the barrier memory_order_seq_cst, Standard C++11 § 29.3 (3): http://www.open-std.org/jtc1/sc22/wg21/docs/papers/2016/n4606.pdf
Quote:
§ 29.3 (3)
There shall be a single total order S on all memory_order_seq_cst operations, consistent with the “happens before” order and modification orders for all affected locations, such that each memory_order_seq_cst operation B that loads a value from an atomic object M observes one of the following values: …
2. If an atomic operation has a barrier different from memory_order_seq_cst, then it can be reordered with memory_order_seq_cst operations in allowed directions, Standard C++11 § 29.3 (8): http://www.open-std.org/jtc1/sc22/wg21/docs/papers/2016/n4606.pdf
Quote:
§ 29.3 (8)
[ Note: memory_order_seq_cst ensures sequential consistency only for a program that is free of data races and uses exclusively memory_order_seq_cst operations. Any use of weaker ordering will invalidate this guarantee unless extreme care is used. In particular, memory_order_seq_cst fences ensure a total order only for the fences themselves. Fences cannot, in general, be used to restore sequential consistency for atomic operations with weaker ordering specifications. — end note ]
The directions allowed for reordering non-seq_cst atomic operations (atomic and non-atomic) around seq_cst-atomic operations are the same as for acquire / release:
a.load(memory_order_seq_cst) – allows the same reordering as a.load(memory_order_acquire) for other non-seq_cst atomic operationsb.store(memory_order_seq_cst) – allows the same reordering as a.store(memory_order_release) for other non-seq_cst atomic operations
A stricter order is possible, but is not guaranteed.
In case of seq_cst, as well as for acquire and release, nothing going to STORE (seq_cst) can be executed after it, and nothing going after LOAD (seq_cst) can be executed before it.
But in the opposite direction, reordering is possible, examples of C++ code and generated code on Assembler x86_64 and PowerPC.
Now we’ll show the changes in the instructions order that are permitted for CPUs by the compilers, for example, GCC for x86_64 and PowerPC.
The following order changes around memory_order_seq_cst operations are possible:
- On x86_64, at the CPU level, the Store-Load reordering is permitted. That is to say, the following sequence can be reordered:
STORE-C(release); LOAD-B(seq_cst); ⇒ LOAD-B(seq_cst); STORE-C(release);, as in x86_64 architecture, MFENCE is added only after STORE(seq_cst), but for LOAD(seq_cst), the assembler instructions are identical for LOAD(release) and LOAD(relaxed): https://godbolt.org/g/BsLqas - On PowerPC, at the CPU level, Store-Load, Store-Store reordering and others are permitted. That is to say, the following sequence can be reordered:
STORE-A(seq_cst); STORE-C(relaxed); LOAD-C(relaxed); ⇒ LOAD-C(relaxed); STORE-C(relaxed); STORE-A(seq_cst);, as on PowerPC architecture, for seq_cst-barrier, sync (hwsync) is added only before STORE(seq_cst) and before LOAD(seq_cst). Thus, all the instructions that are between STORE(seq_cst) and LOAD(seq_cst) can be executed before STORE(seq_cst): https://godbolt.org/g/dm7tWd
For more detail, see the following example with three variables with semantics: seq_cst and relaxed.
Reordering permitted by C++ compiler
Why are such changes of order possible? Because C++ compiler generates the assembler code, which allows you to do such reordering in relation to x86_64 and PowerPC CPUs:
Quote:
Reordering permitted by different CPUs in the absence of assembler-barriers between the instructions
“Memory Barriers: a Hardware View for Software Hackers” Paul E. McKenney June 7, 2010: http://www.rdrop.com/users/paulmck/scalability/paper/whymb.2010.06.07c.pdf
There is one more feature of the data exchange between the threads, which is manifested upon interaction of four threads or more. If at least one of the following operations does not use the most stringent barrier memory_order_seq_cst, then different threads can see the same changes in different order. For example:
- If thread-1 changed some value first
- And thread-2 changed some value second
- Then thread-3 can first see the changes made by thread-2, and only after that it will see the changes made by thread-1
- And thread-4, on the contrary, can first see the changes made by thread-1, and only after that, it will see the changes made by thread-2
This is possible because of the hardware features of the cache-coherent protocol and the topology of location of the cores in the CPUs. In this case, some two cores can see the changes made by each other before they see the changes made by other cores. In order that all threads could see the changes in the same order, i.e., they would have a single total order (C++ 11 § 29.3 (3)), it is necessary that all operations (LOAD, STORE, RMW) would be performed with the memory barrier memory_order_seq_cst: http://en.cppreference.com/w/cpp/atomic/memory_order
In the following example, the program never finish with assert(z.load()! = 0) error; Since all operations use the most stringent memory barrier - memory_order_seq_cst: http://coliru.stacked-crooked.com/a/52726a5ad01f6529
This code in the online compiler taken by the link: http://en.cppreference.com/w/cpp/atomic/memory_order
In the figure, we’ll show what order change is possible for Acquire-Release semantics and for Sequential semantics by the example of 4 threads:
- Acquire-Release
- It is possible to change the order of ordinary variables in the allowed directions
- It is possible to change the order of atomic variables with Acquire-Release semantics
- Sequential
- It is possible to change the order of ordinary variables in the allowed directions
- It is impossible to change the order of atomic variables with Sequential semantics
Active Spin-Locks and Recursive-Spin-Lock
We will show how the memory barriers are applied for atomic operations by the example of realization of own active locks: spin-lock and recursive-spin-lock.
Further, we will need these locks for locking separate rows (row-lock) in the table instead of locking the whole table (table-lock). This will increase the degree of parallelism and increase the performance, because different threads can work with different rows in parallel, without locking the whole table.
The number of synchronization objects provided by the operating system can be limited. The number of rows in a table can be equal to millions or billions, many operating systems do not allow you to create so many mutexes. And the amount of spin-locks can be any, as far as RAM allows it. That is why they can be used for locking every single row.
In fact, spinlock is +1 byte to each row, or +17 bytes upon using recursive-spin-lock (1 byte for the flag + 8 bytes for the recursion counter + 8 bytes for the thread_id thread number).
The main difference between recursive_spinlock and ordinary spinlock is that recursive_spinlock can be repeatedly locked by the same thread, i.e., it supports recursive nested locks. Similarly, std::recursive_mutex is different from std::mutex.
Example of nested locks:
Let's see how recursive_spinlock_t works.
If you try to run this code in the MSVC 2013 compiler, you will get a very strong slowdown due to the std::this_thread::get_id() function: https://connect.microsoft.com/VisualStudio/feedback/details/1558211
We will modify the recursive_spinlock_t class so that it caches the thread-id in the variable __declspec (thread) - this is the thread_local analog of the C++11 standard. This example will show good performance in MSVC 2013: [28] http://coliru.stacked-crooked.com/a/3090a9778d02f6ea
This is a patch for the old MSVC 2013, so we will not think about the beauty of this solution.
It is believed that in most cases, the recursive locking of a mutex is a design error, but in our case, this can be a slow but working code. Secondly, all can be mistaken, and with the nested recursive locks, recursive_spinlock_t will work much slower, and spinlock_t will hang forever - which is better, it’s up to you.
In case of using our thread-safe pointer safe_ptr<T>, both examples are quite logical, but the second one will work only with recursive_spinlock:
safe_int_spin_recursive->second++; // can be used: spinlock & recursive_spinlocksafe_int_spin_recursive->second = safe_int_spin->second + 1; // only recursive_spinlock
Realization of Own High-Performance Shared-Mutex
It is well-known that new types of mutexes gradually appeared in new C++ standards: http://en.cppreference.com/w/cpp/thread
- C++11:
mutex, timed_mutex, recursive_mutex, recursive_timed_mutex - C++14:
shared_timed_mutex - C++17:
shared_mutex
shared_mutex is a mutex that allows many threads to read the same data simultaneously, if at that time, there are no threads that change these data. Shared_mutex was not created in one day. There were disputes about its performance in comparison with the usual std::mutex.
The classic realization of shared_mutex with a count of the number of readers showed an advantage in speed only when many readers held the lock for a long time - i.e., when they had been reading for a long time. With short reads, shared_mutex only slowed down the program and complicated the code.
But are all the shared_mutex realizations so slow in short reads?
The main reason for slow operation of std::shared_mutex and boost::shared_mutex is the atomic counter of readers. Each reader thread increments the counter during locking and decrements it upon unlocking. As a result, threads constantly drive one cache line between the cores (namely, drive its exclusive-state (E)). According to the logic of this realization, each reader thread counts the number of readers at the moment, but this is absolutely not important for the reader thread, because it is important only that there is not a single writer. And, since the increment and decrement are RMW operations, they always generate Store-Buffer cleaning (MFENCE x86_64) and, at x86_64 level, asm actually correspond to the slowest semantics of the Sequential Consistency.
Let’s try to solve this problem.
There is a type of algorithm that is classified as write contention-free - when there is not a single memory cell in which it would be possible to write more than one thread. In a more general case, there is not a single cache line in which it would be possible to write more than one thread. In order to have our shared-mutex be classified as write contention-free only in the presence of readers, it is necessary that readers do not interfere with each other - i.e., each reader should write a flag (which is read by it) to its own cell and remove the flag in the same cell at the end of reading - without RMW operations.
Write contention-free is the most productive guarantee, which is more productive than wait-free or lock-free.
It is possible that each cell is located in a separate cache line to exclude false-sharing, and it is possible that cells lie tightly - 16 in one cache line - the performance loss will depend on the CPU and the number of threads.
Before setting the flag, the reader checks if there is a writer - i.e., if there is an exclusive lock. And since shared-mutex is used in cases where there are very few writers, then all the used cores can have a copy of this value in their cache-L1 in shared-state (S), where they will receive the value of the writer’s flag for 3 cycles, until it changes.
For all writers, as usually, there is the same flag want_x_lock - it means that there is a writer at the moment. The writer threads set and remove it by using RMW-operations.
lock(): while(!want_x_lock.compare_exchange_weak(flag, true, std::memory_order_acquire))unlock(): want_x_lock.store(false, std::memory_order_release);
But to make the readers not interfere with each other, they shall write information about their shared-locks in different memory cells. We will allocate an array for these locks, the size of which we will set with the default template parameter of 20. At the first call, the lock_shared() thread will be automatically registered, taking a certain place in this array. If the number of threads is larger than the size of the array, then the remaining threads, upon calling the lock_shared(), will call an exclusive lock of the writer. The threads are rarely created, and the time spent by the operating system for their creation is so long that the time of registration of a new thread in our object will be negligible.
We will make sure that there are no obvious errors - by examples, we will show that everything is working correctly, and after that, we will demonstrate schematically the correctness of our approach.
Here is an example of such a fast shared lock in which readers do not interfere with each other: [30] http://coliru.stacked-crooked.com/a/b78467b7a3885e5b
- During the shared lock, there can be no object changes. This line of two recursive shared-locks shows this:
assert(readonly_safe_map_string->at("apple") == readonly_safe_map_string->at("potato")); - the values of both lines should always be equal, because we change 2 lines in std::map under one eXclusive-lock std::lock_guard. - During reading, we really call the lock_shared() function. Let's reduce the cycle to two iterations, remove the lines modifying the data and leave only the first two inserts in
std::map in the main() function. Now we add the output of S letter to the lock_shared() function, and X letter - to the lock() function. We see that there are two X inserts going first, and only after that we see S - indeed, when reading const-objects, we call shared_lock(): [31] http://coliru.stacked-crooked.com/a/515ba092a46135ae - During the changes, we really call the lock() function. Now we’ll comment out the reading and leave only the operations of changing the array. Now only X letters are displayed: [32] http://coliru.stacked-crooked.com/a/882eb908b22c98d6
The main task is to ensure that there can only be one of the two states at the same time:
- Any number of threads successfully executed
lock_shared(). Thereat, all threads trying to execute lock() should change to standby mode. - One of the threads successfully executed
lock(). Thereat, all other threads trying to execute lock_shared() or lock() should change to standby mode.
Schematically, the table of compatible states looks like below:
Let’s consider the algorithm of our contention_free_shared_mutex for the cases when two threads are trying to perform operations at a time:
- T1-read & T2-read: The reader threads lock the mutex by using
lock_shared() - these threads do not interfere with each other, because they write states about locks in the memory cells separate for each thread. And at this time, there should not be an exclusive locking of the writer thread (want_x_lock == false). Except when the number of threads is bigger than that of the dedicated cells. In such a case, even the reader threads are locked exclusively by using the CAS-function: want_x_lock = true. - T1-write & T2-write: The writer threads compete with each other for the same flag (
want_x_lock) and try to set it to “true” by using the atomic CAS-function: want_x_lock.compare_exchange_weak(); Here, everything is simple, as in the usual recursive_spinlock_t, which we have discussed above. - T1-read & T2-write: The reader thread T1 writes the lock flag to its cell, and only after that, it checks if the flag (
want_x_lock) is set. If it is set (true), then it cancels its lock and after that, waits for the state (want_x_lock == false) and repeats this algorithm from the beginning.
The writer thread T2 sets the flag (want_x_lock = true), and then waits until all reader threads remove the locking flags from their cells.
The writer thread has a higher priority than the reader. And if they simultaneously set their locking flags, then the reader thread, by means of the following operation, checks if there is a writer thread (want_x_lock == true). If there is a writer thread, then the reader cancels its lock. The writer thread sees that there are no more locks from the readers and successfully completes the locking function. The global order of these locks is met due to the semantics of Sequential Consistency (std::memory_order_seq_cst).
Below, the interaction of two threads (the reader and the writer) is shown schematically.
Full size: https://hsto.org/files/422/036/ffc/422036ffce8e4c7e9b464c8a293fd410.jpg
In both functions, lock_shared() and lock(), for both marked operations 1 and 2 used std::memory_order_seq_cst - i.e., for these operations, there shall be a single total order for all threads.
Automatic Deregistration of the Thread in Cont-Free Shared-Mutex
When a thread first accesses our lock, it is registered. And when this thread is terminated or the lock is deleted, then registration should be canceled.
But now let’s see what happens if 20 threads work with our mutex and then these threads terminate and try to register new 20 threads, provided that the array of locks is 20: [33] http://coliru.stacked-crooked.com/a/f1ac55beedd31966
As you can see, the first 20 threads were successfully registered, but the following 20 threads could not register (register_thread = -1) and had to use the writer’s exclusive lock, despite the fact that the previous 20 threads had already disappeared and no longer use the lock.
To solve this problem, we add automatic cancellation of the thread registration when the thread is deleted. If the thread has worked with a lot of such locks, then at the time of thread termination, registration should be canceled in all such locks. And if, at the time of thread removal, there are locks, which are already deleted, no error is supposed to occur due to an attempt to cancel the registration in a non-existent lock.
Example: [34] http://coliru.stacked-crooked.com/a/4172a6160ca33a0f
As you can see, first, 20 threads were registered. After they were removed and 20 new threads were created, they also could register - under the same numbers register_thread = 0 - 19 (see the example output).
Now we’ll show that even if the threads have worked with locking, and then the lock was removed, then upon termination of the threads, there will be no error due to an attempt to cancel the registration in a non-existent lock object: [35] http://coliru.stacked-crooked.com/A/d2e5a4ba1cd787da
We set the timers so that 20 threads could be created, perform reading by using our lock and fall asleep at 500ms; and at that time, in 100ms, the contfree_safe_ptr object, which contains our lock contention_free_shared_mutex inside, could be removed; and only after that 20 threads could wake up and terminate. Upon their termination, there was no error due to deregistering in a remote lock object.
As a small addition, we will support MSVS2013 so that the owners of the old compiler can also see the example. We add simplified support for registering the threads, but without the possibility of deregistration of threads.
The final result will be shown as an example in which all the above thoughts are taken into account.
Example: [36] http://coliru.stacked-crooked.com/a/0a1007765f13aa0d
The Correct Functioning of the Algorithm and Selected Barriers
Above we have performed tests that showed no obvious errors. But in order to prove the working capacity, it is necessary to create a scheme of possible changes in the order of operations and possible states of variables.
Exclusive lock()/unlock() is almost as simple as in the case of recursive_spinlock_t. So, we will not consider it in detail.
The reader thread competition for lock_shared() and the writer thread competition for lock() has been discussed in detail above.
Now the main task is to show that lock_shared() uses at least Acquire-semantic in all cases; and unlock_shared() uses at least Release-semantic in all cases. But this is not a prerequisite for repeated recursive locking/unlocking.
Now let’s see how these barriers are implemented in our code.
The barriers for lock_shared() are shown schematically. The red crossed arrows indicate the directions, in which the change of the order is forbidden:
Barriers for unlock_shared() shown schematically:
Full size: https://hsto.org/files/065/9ce/bd7/0659cebd72424256b6254c57d35c7d07.jpg
Full size with marked conditional transitions: https://hsto.org/files/fa7/4d2/2b7/fa74d22b7cda4bf4b1015ee263cad9ee.jpg
We also show a block diagram of the same function lock_shared():
Full-size picture:
https://hsto.org/files/c3a/abd/4e7/c3aabd4e7cfa4e9db55b2843467d878f.jpg
In the oval blocks, strict sequences of operations are indicated:
- First red color operation is executed
- Then, purple color operation is executed
Green color indicates the changes that can be executed in any order, because these changes do not lock our “shared-mutex”, but the only increase the recursion nesting count - these changes are important only for local use. That is to say, these operations are not the actual entrance to a lock.
Since 2 conditions are executed, it is assumed that all the necessary side-effects of the multithreading are taken into account:
- The moment of making a decision to enter a lock always has semantics of at least “acquire” level:
want_x_lock.load(std::memory_order_seq_cst)want_x_lock.compare_exchange_weak(flag, true, std::memory_order_seq_cst)
- First, we always lock (1-red) and only after that we check (2-purple), whether we can enter the lock.
Further, the correctness of the algorithm can be verified by a simple comparison of these operations and their sequence with the logic of the algorithm.
All other functions of our lock “contention_free_shared_mutex” are more obvious from the point of view of the logic of multi-threaded execution.
Also, in recursive locks, atomic operations do not need to have a std::memory_order_acquire barrier (as is done in the figure), there is enough to set the std::memory_order_relaxed, because this is not the actual entrance to a lock - we are already in the lock. But this does not add much speed and can complicate understanding.
Using the Code
How to Use
An example of how to use contention_free_shared_mutex<> in C++ as highly optimized shared_mutex.
To compile in compiler Clang++ 3.8.0 on Linux, you should change Makefile.
#include < iostream >
#include < thread >
#include < vector >
#include "safe_ptr.h"
template < typename T >
void func(T &s_m, int &a, int &b)
{
for (size_t i = 0; i < 100000; ++i)
{
{
s_m.lock();
a++;
b++;
s_m.unlock();
}
{
s_m.lock_shared();
assert(a == b); s_m.unlock_shared();
}
}
}
int main() {
int a = 0;
int b = 0;
sf::contention_free_shared_mutex< > s_m;
std::vector< std::thread > vec_thread(20);
for (auto &i : vec_thread) i = std::move(std::thread([&]() { func(s_m, a, b); }));
for (auto &i : vec_thread) i.join();
std::cout << "a = " << a << ", b = " << b << std::endl;
getchar();
return 0;
}
This code is in the online compiler: http://coliru.stacked-crooked.com/a/11c191b06aeb5fb6
As you see, our sf::contention_free_shared_mutex<> is used in the same way as a standard std::shared_mutex.
Benchmark: std::shared_mutex VS contention_free_shared_mutex
Here is an example of testing on 16 threads for a single server CPU Intel Xeon E5-2660 v3 2.6 GHz. First of all, we are interested in the blue and purple lines:
safe_ptr<std::map, std::shared_mutex>contfree_safe_ptr<std::map>
You can download this benchmark for Linux (GCC 6.3.0) and Windows (MSVS 2015): bench_contfree.zip - 8.5 KB
To compile in compiler Clang++ 3.8.0 on Linux, you should change Makefile.
Command line for starting:
numactl --localalloc --cpunodebind=0 ./benchmark 16
The performance of various locks for different ratios of lock types: shared-lock and exclusive-lock:
- % exclusive locks = (% of write operations)
- % shared locks = 100 - (% of write operations)
(In the case of std::mutex - always used exclusive-lock)
Performance (the bigger – the better)
MOps - millions operations per second
- For 0% of modifications – our shared-mutex (as part of «contfree_safe_ptr<map>») shows performance 34.60 Mops, that is 14 times faster than standard
std::shared_mutex (as part of «safe_ptr<map, std::shared_mutex>») that shows only 2.44 Mops. - For 15% of modifications – our shared-mutex (as part of
«contfree_safe_ptr<map> ») shows performance 5.16 Mops, that is 7 times faster than standard std::shared_mutex (as part of «safe_ptr<map, std::shared_mutex>») that shows only 0.74 Mops.
Our lock «contention-free shared-mutex» works for any number of threads: for the first 36 threads as contention-free, and for the next threads as exclusive-lock. As can be seen from the graphs – even exclusive-lock «std::mutex» works faster than «std::shared_mutex» for 15% of modifications.
The number of threads 36 for the contention-free-locks is specified by the template parameter, and can be changed.
Now we will show the median latency for different ratios of lock types: shared-lock and exclusive-lock.
In the test code main.cpp, you should to set: const bool measure_latency = true;
Command line for starting:
numactl --localalloc --cpunodebind=0 ./benchmark 16
Median-latency (the lower – the better), microseconds
Thus, we created a shared lock, in which the readers do not interfere with each other during locking and unlocking, unlike std::shared_timed_mutex and boost::shared_mutex. But we have the following additional allocations for each thread: 64 bytes in the locks array + 24 bytes are occupied by the unregister_t structure for deregistration + an element pointing to this structure from the hash_map. Totally, it is about ~100 bytes per thread.
A more serious problem is the scaling feature. For example, if you have 8 CPUs (Intel® Xeon® Processor E7-8890 v4) with 24 cores each (48 HyperThreading threads each), then this is a total of 384 logical cores. Each writer thread must read 24576 bytes (64 bytes from each of 384 cores) before writing. But they can by read in parallel. It's certainly better than waiting until one cache line consistently goes from each of 384 threads to each one, like in ordinary std::shared_timed_mutex and boost::shared_mutex (for any type of unique/shared lock). But paralleling by 1000 cores and more is usually realized by a different approach, rather than by calling an atomic operation to process each message. All the options discussed above - atomic operations, active locks, lock-free data structures - are necessary for small latencies (0.5-10 usec) of individual messages.
For high indicators of the number of operations per second (i.е., for high system performance in general and scalability for tens of thousands of logical cores), they use mass parallelism approaches, “hide latency” and “batch processing” - batch processing when messages are sorted (for map) or grouped (for hash_map) and fused with the already available sorted or grouped array for 50 - 500 usec. As a result, each operation has ten-hundredfold latency, but this latency occurs in a great number of threads at a time. As a result, hide latency occurs because of using “Fine-grained Temporal multithreading”.
Let’s assume: each message has hundredfold latency, but the number of messages being processed is 10,000 times more. This is hundredfold more efficient per time unit. Such principles are used when developing on the GPU. Perhaps, in the following articles, we will discuss this in more detail.
Points of Interest
Conclusion: We have developed our own “shared-mutex”, which does not require that the reader threads synchronize with each other, as it is seen in the standard std::shared_mutex. We have strictly proved the correctness of the work of our “shared-mutex”. And also we studied atomic operations, memory barriers and allowed reordering directions for maximum optimization of performance in detail. Next, we’ll see how much we were able to increase the performance of multithreaded programs, compared to the standard std::shared_mutex.
History
- 24th April, 2017 - Initial version
- 1st May, 2017 - Added link to GitHub

