The state of the art
If you search the wikipedia site, you will find these similar algorithms:
- Computational geometry
- Online algorithm
- Graham scan
- Bucket sort
- Odd-even sort
Although the complexity of these algorithms is generally O(n2) or O(n log (n)), they usually do not use memory, while my own sorting algorithm uses it.
Introduction
In this previous article, I wrote that a sorting algorithm must take n lap to sort two sublists whose size is n / 2.
The set of numbers in a list is ideal when the complexity is p * n, if the number n is exactly equal to 2p.
This second article is a study on a method of sorting numbers that takes at most 3 * n times where n is the exact size of an unordered list.
On the whole, this study is far from being mathematical and not exclusively on the fundamental theorem of arithmetic[3].
Background
There are several algorithms for sorting numbers. Generally, we have numbers to sort; Nevertheless, it may be other formats: string, floating point, objects or any other data that can be compared.
There are two possible requirements depending on the approach of the sorting algorithm.
First, a comparator must be provided to compare two elements. Therefore, integers satisfy this condition.
Second, to sort, you must provide a function to calculate a distance between two items taken 2 to 2 in the list.
Comparing two elements is sometimes more difficult than calculating a function as a distance between two elements[1].
Graphical interpretation
A sorted list is a succession of numbers, so for every k > n, the n-th is less or equal than that of the k-th.
When the elements of a list are not sorted, the sorting algorithm automatically transforms this list into a succession of numbers ranging from the smallest to the largest without any human intervention.
Computers were very slow two decades ago. That's why it was important to have the fastest sorting algorithm possible.
If n = 1000, the simplest sorting algorithm will handle the job, at worst, after 999000 turns.
This simple algorithm is intuitive. Other algorithms are not. And if I assume that there is a faster sorting algorithm, this algorithm can result in an incomplete ordered number list.
A graphical function with a two-dimensional array
It is true that I can interpret a list of numbers as a graphic function with a two-dimensional array exactly.
For example, suppose this list of numbers shown below at this order :
45 33 5 21 98 7 4 5 77 34
It shows this graphical representation :
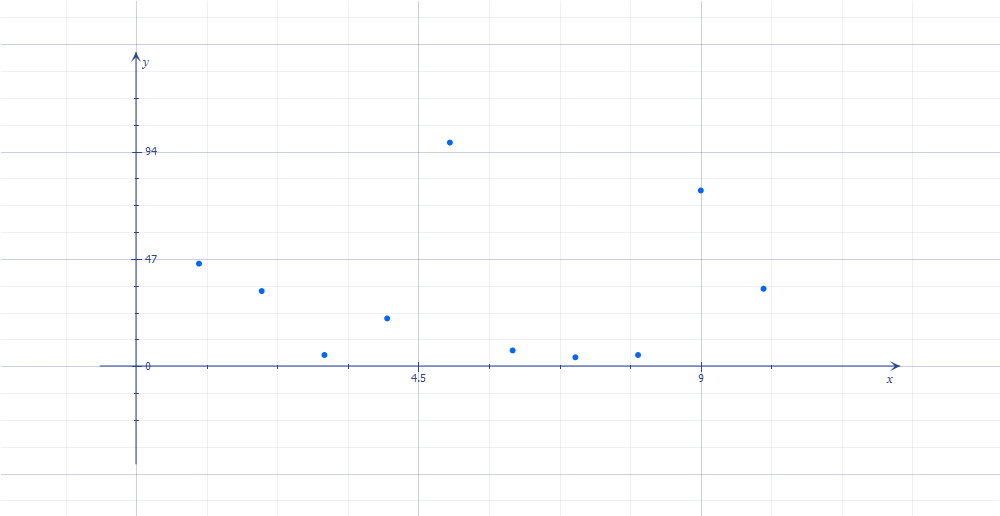
An ordered list of numbers has a graphical representation and that its representation is a strictly increasing line.
For example, the list of successive even numbers is exactly equal to the graphic representation below. It shows that a variation of 1 on the x-axis gives a variation of 2 on the y-axis.
Moreover, the algebraic equation of this line is an application that takes each value x and returns the value y.
y = 2 * x

Now, in a series of ideal numbers, the line is linear, as proposed in linear algebra, I mean that it satisfies these two principal constraints: an operation + and an operation *.
There is a direct relationship between a line and a series of numbers; While the numerical intervals between each number are always equal, the graphical representation is exactly one line, and if the intervals are not equal, the line contains discontinuities.
For example, the list above has several discontinuities on its curve.
Development of an algorithm
This mathematical theory shows a development path for an algorithm.
The first pass of this algorithm is to read all the numbers of the input list (or a subset of this list). It's relatively simpler to create each group in a separate thread.
An arithmetic progression is a series of numbers with a common difference. And, the linear difference equation encapsulates each of the progressions.
The final passage consists of reading all the groups of discontinuities; Then, the result is the sorted list.
Determine the common difference of an arithmetic progression
The common difference d is obtained by dividing the difference with the two ends by the number of elements.
Therefore, the calculation of d is possible during the iteration of the list. For each item, I update the number of items read, the current minimum number and the maximum number.
The data retained are as follows
- an arithmetic progression: the numbers xmin, xmax, n. The term d is computed during execution.
- for each interval, I keep another arithmetic progression
Thus, after some elements read, the data are a tree of several arithmetical progressions. If the memory size increases, this size is a multiple of 3.
Calculate the x-th index on the curve
Suppose that after some elements, I obtained an arithmetic progression with n = 5 numbers and d = 3.
Suppose the xmin is equal to 2 then the list of numbers is
2 5 8 11 14
The value of the following element can be:
- before the first element
- after the last element
- the same item found in the list
- in an interval
For each given value, the arithmetic progression is modified. And the change has no impact on the current data tree and that's why it's great !
Euclidean division
The x-th is given by this formula
When the value x is an integer, I add 1 to the value of n.
When the value x is a rational number and if it already has an arithmetic progression in the hashtable to the integer part of the x value, I have to pass the calculation to this arithmetic progression.
When the value x is a rational number and has no arithmetic progression, I create it and add it to the hashtable with the integer part of the x value.
To decide when x is an integer or a rational number, I just have to use the div () function. This function returns the quotient part and the remaining part. This is clearly the Euclidean division.
Using an affine equation
The main task consists in calculating the coefficients a and b of an affine equation such that:
y = a * x + b
With respect to this function, two pairs of coordinates are required to identify exactly the coefficients.
If it is a more complicated equation, for example, a polynomial, we need a larger number of coordinate pairs.
This is an online algorithm. This means several things :
- You can start the sorting calculation at any point in the list,
- At each step, all the given elements are sorted,
- At each step, you ask the algorithm to process a new number,
- If you exchange items in the list, the work order is exchanged,
- The algorithm has a memory in time; If you delete the memory, the algorithm works as if it were starting.
First number
I define the first element with the coordinates (k1, p1).
Second number
I define the second element with the coordinates (k2, p2). Make sure p2 is greater than p1. If not, exchange them.
Since I have two coordinates, I can calculate the coefficients a and b. They are given by two formulas. These formulas are the equations of the solution of a system of two equations with two unknowns. A substitution or a more complicated method (Gauss) can obtain them.
Third number
From this chronology of the algorithm, I define each element with the coordinates (ki, pi).
I must determine the value of ki by isolating this term in the affine equation.
There are two options left.
Option 1
When ki gives an integer z, it is the index number where the pi will certainly be placed if there is already a total number of elements z-i.
This result can be expressed with the sum of each element, the sum of all the i-th indexes and the common difference.
Option 2
When ki gives a rational number, I have to cut the line into two parts.
These two parts are obtained by the framing of ki by default and by excess.
The first line starts at k1 and ends with E[ki] (E is the integer part function) and the second line starts at E[ki]+1 and ends with k2. The first line is the one you keep at the top and the second line is placed to be inside a hash table.
Improvement of the algorithm
What is the real problem with a computer ?
In other words, what is the difference between a human and a computer to sort integers ?
I answer: a human has an eye. So to allow a computer to see, what is better than a graphical representation ?
The algorithm aligns all points along the same vertical line.
To sort the items, first select each pointer in the row from bottom to top.
Take the minimum amount of time and minimum memory size
Since time takes a constant proportion of n, the size of the memory must also be the smallest. To get this minimum, I have to understand something about the actual difficulties in sorting the list.
A sorted list can take three generating forms :
- A continuous line which means a single common difference from the lowest number to the highest number seen in the list,
- Several discontinuous lines, this means that there are several slopes as a sequence of smaller sorted lines which may also have discontinuities,
- There are duplicates in the list.
So the important thing is to count discontinuities and duplicates first. Once completed, an iterative counter will automatically organize all discontinuities as multiple sequences without internal recurrence by adding each account to the counter and indicating the exact locations of each number.
When this second step is completed, I only need permutations to sort the entire list.
Thus, the maximum time is always 3 * n, where the value of n is the number of elements in the input list.
Except that there is still a problem with the evolution of the line.
Calculations during the progressive iteration of the list
For any list size, but relatively large, a ten-digit base (as a vector-space has is 10 for its kernel value) helps to quickly preview the nearest size.
With a size less than or equal to ten, the rank is ten. Sorting takes 2 turns of list. This is already less than
10 * log2 (10) ≈ 3 * 10. But this is equivalent to 10 * log10 (10).
But we must draw attention to the fact that a logarithm of 1 is equal to 0. This means that the complexity of the algorithm is not an exact value when n is a small number because of the complexity of zero (Then infinite?).
With a size less than or equal to one hundred, the rank could be 10 or 100. This could reach 100 if the numbers in the list are high. But, if the numbers in the list are less than 100, the ranking will not progress.
With a size greater than or equal to a thousand, the ranking could be from 10 to 100 because we will always divide each big growth by 10.
The method works well as described by these small formulas
0 < i < 10, m=0, yi = ki * m + ri
y > 10, 0 < i < 100, m=10, yi = ki * m + ri
y > 100, i >= 100, m'=10 * m, yi/10 = ki * m/10 + ri / 10
yi' = ki' * m' + ri', yi' = yi / 10, ki' = ki / 10, ri' = ri / 10, m' = 10 * m
Each ten elements of ki are added to form the number of elements at n ° 0. Remember that the size chart to store the counters is double; One when the remainder of the Euclidean division is equal to 0 and the other when the latter is not zero.
You will find the source code associated with this sort method in this article.
POC (Proof Of Concept) : grid 2D
In FIG. 1, you can see successive points increased by 1 on each cell from the beginning of the left corner.
FIG. 1
This point configuration means that the successive elements are sorted when each is increased by 1. If it is not the exact configuration selected, It could be a number less than or greater than i.
These two changes are presented below in Fig. 2 and FIG. 3.
FIG. 2 FIG. 3
We can conclude that after the first pass with the maximum and minimum number, a list of the values ki annotated with their count in the list will reasonably give a sequence of several arithmetic progressions with its minimum, number and common difference.
Therefore, the complexity of this algorithm is 2 * n for any mixed number list. This is called O (n).
But...
Since I can use a grid to show that an ordered list is just a line with an increasing slope, or successive lines and a specific slope.
Does this make one think of the Bresenham algorithm[2]?
Suppose I can model in terms of probabilities either to go left, or to move left and up with a movement of 1.
Moreover, I give a name for one, A and B for the second.
For example, this sequence makes it possible to move along a line :
BABBAAABABBAAAA
I interpret this sequence as a sorted list. Is it possible to find a different sequence where the list is not sorted and to transform this sequence into its corresponding sequence when this list is sorted?
An example
Suppose I have this list to sort:
3 9 4 7 8
By each sequential difference, if a number is less than its successor, I say A+ and if a number is greater than its successor, I say A-. And if they are equal, I say B.
A+ A- A+ A+
With this example, I obtain
3 9 4 7 8
A+ A+ A- A+ A+
An another example
As I said above, the risks for unsorted lists are insertions and discrepancies.
So I can try to put such a risk with this list
4 42 48 55 18 37 27 71 80
A+ A+ A+ A- A+ A- A+ A+
Conclusion
The Brezenham algorithm traces a line in a grid with sorted numbers. Since the sorted numbers have different slopes, these slopes coincide with a Euclidean number. In such a drawn line, the size and value of the kernel indicate that I can define a vector space, so that the number of elements in the list must be equal to the grid of an equivalent size.
Thus, after this paragraph, the letters give way to the slopes.
If I find a size large enough to receive the items, is it necessary to make insertions or resize?
And if the size is too large, can I just calculate the positions?
And if I can just calculate the positions, can I simply iterate the slopes?
I answer yes; But, the problem are duplicates. So I do not classify any value, no slope, I do not create a grid and I only count the number of duplicates.
Using the code
The IntegerList class handles the list of numbers.
The numbers in the list can be read from a file or generated by chance or iterated with a slope.
Then, the Indexer class helps iterate the list. Thus, an additional class must be created to compute each step of the numbers by the maximum value of the integer (if, the data type of each item in the list is an integer).
Then, the algorithm requires a class to calculate the couple (row, column), the main calculation.
The end of the algorithm consists of iterating each row by row and column by column on a dictionary of duplicate numbers. To avoid a long iteration of the grid size, translate the rows and columns into a grid with a slope (1,s) and a size equal to the number of elements in the list.
It lacks a dictionary class for duplicates.
Examples
Example of an algorithm that mimics the sorting of integers
Here is an example that uses slopes to sort the given input list.
Why do I think of a slope to sort whole numbers?
I think of a slope for two reasons:
1) the sum of the integers may overflow when the integers are high.
In fact, if a subset of an ordered list has a single slope, the sum of elements is proportional to the sum of an arithmetic progression of 1.
2) a single slope is not so close to the list of integers. The different slopes mean that the list has a different progression.
Notes
[1] https://en.wikipedia.org/wiki/Distance (Go To Link)
[2] https://en.wikipedia.org/wiki/Bresenham (Go To Link)
[3] https://en.wikipedia.org/wiki/Fundamental_theorem_of_arithmetic (Go To Link)

