This article is an investigation of Large Object Heap fragmentation. We outline a simple coding technique that goes directly to the OS with VirtualAlloc for large objects, avoiding the LOH altogether. We touch on the fact if a developer configures the machine to use Server Garbage Collection in Concurrent mode to reduce freezing of an application caused by garbage collection. We also touched on the fact if a developer were to manually compact the LOH from code; the compaction only occurs on the next blocking garbage collection. As a base starting point, we include a Sample Project implementing code for dealing with several common scenarios that can sometimes lead to excessive fragmentation of the LOH.
Ok, you and your team have just built a large, scalable, rock-solid ASP.NET web portal and it’s a huge success; customers are signing up fast, the portal is growing at break-neck pace and management is extremely pleased. The scalability that IIS and ASP.NET have become known for in the enterprise space is proving itself to be true. Everything is going better than fantastic and before long you find yourself passing over into enterprise scale. And then—bang—from out of nowhere—like a flat tire—your server’s hard drives begin to spin wildly out of control. All the memory on your web server’s been completely consumed and the dreaded eternal paging to the system page file has viciously commenced, sending your server into a tail spin and imminent death. Your server’s disk drives rumbling at full throttle reverberate through your server room like an approaching fleet of B-52 planes on an air-raid mission. Your worker process’s (w3wp.exe) have begun to cycle in a pathetic attempt to recover from this ghastly state of affairs, causing momentary outages for your customers and causing your web portal to appear structurally unsound and unprofessional. You went from the best, to the worst, at the same break-neck pace.
I don’t mean to paint such a depressing illustration, but more often than not, this is the reality in the real world at enterprise scale. If this story sounds shockingly familiar and your IIS Web Server is exhibiting many of these same adoring qualities, the culprit is quite possibly Large Object Heap (LOH) fragmentation.
Sample Project Overview
The Sample Project code is designed to combat LOH fragmentation by simply keeping allocations off the LOH, as shown in Figure 1. It’s not designed to entirely replace the LOH, nor is it designed to keep every type of object off the LOH. Currently, it replaces MemoryStream, string.Split and arrays of integral and floating-point value types, like byte[], int[], long[], double[]. Though it’s worth noting, this same technique could be used to keep many other allocation scenarios off the LOH as well. Pretty much anything that’s blittable or has an explicit layout may be an ideal candidate in most cases. The Sample Project demonstrates this new technique and can be used as a simple template to expand to other allocation scenarios going forward.
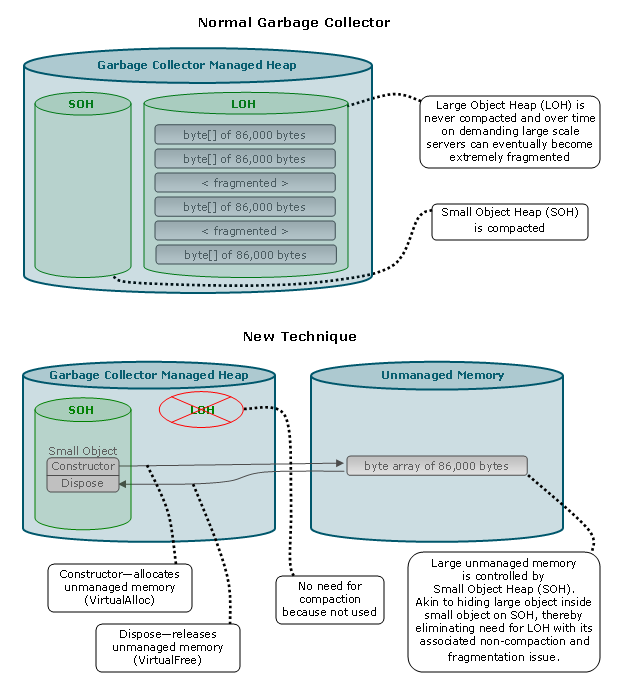
Figure 1 Normal Garbage Collector vs. New Technique
The Sample Project contains two projects; Tester.exe and NoLOH.dll. Tester.exe, shown in Figure 2, contains several tests designed to compare fragmentation of the LOH on your server. The tests are fashioned to simulate a very busy enterprise server experiencing precisely the right scenario to induce massive fragmentation of the LOH, and allow you to easily compare the same scenario using this new technique, making the fragmentation virtually disappear. All the classes implementing this new technique are located in the NoLOH.dll. NoLOH.dll is extremely easy to use—simply reference it in your project. Then, use those classes in place of the equivalent built-in .NET type. That’s it!

Figure 2 Screen shot of Tester.exe
Currently, we implement three main scenarios in NoLOH.dll: ArrayNoLOH<T>, string.SplitNoLOH() and MemoryStreamNoLOH.
ArrayNoLOH<T> can be used in place of an integral value type array as follows:
ArrayNoLOH<byte> bytes = new ArrayNoLOH<byte>(86000); //not on LOH
vs.
byte[] bytes = new byte[86000]; //on LOH
string.SplitNoLOH() can be used in place of string.Split() by merely appending "NoLOH" as follows:
string text = "a large string";
foreach(string part in text.SplitNoLOH(‘^’)) //not on LOH
vs.
foreach(string part in text.Split(‘^’)) //on LOH
using(StringArrayNoLOH parts = text.SplitNoLOH(‘^’)) //not on LOH
vs.
string[] parts = text.Split(‘^’); //on LOH
string.SplitLazyLoad() can be used in place of string.Split() by merely appending "LazyLoad" as follows:
foreach(string part in text.SplitLazyLoad(‘^’)) //not on LOH
vs.
foreach(string part in text.Split(‘^’)) //on LOH
MemoryStreamNoLOH can be used in place of MemoryStream for binary serialization as follows:
public ArrayNoLOH<byte> Serialize(object listOfItems)
{
using(MemoryStreamNoLOH ms = new MemoryStreamNoLOH())
{
new BinaryFormatter().Serialize(ms, listOfItems); //not on LOH
ArrayNoLOH<byte> bytes = ms.ToArray(); //not on LOH
return bytes;
}
}
public object Deserialize(ArrayNoLOH<byte> bytes)
{
using(UnmanagedMemoryStreamEx ms = new UnmanagedMemoryStreamEx(bytes))
{
return new BinaryFormatter().Deserialize(ms);
}
}
vs.
public byte[] Serialize(object listOfItems)
{
using(MemoryStream ms = new MemoryStream())
{
new BinaryFormatter().Serialize(ms, listOfItems); //on LOH
byte[] bytes = ms.ToArray(); //on LOH
return bytes;
}
}
public object Deserialize(byte[] bytes)
{
using(MemoryStream ms = new MemoryStream(bytes))
{
return new BinaryFormatter().Deserialize(ms);
}
}
The first, ArrayNoLOH<T>, is backed by unmanaged memory (not LOH) that’s allocated in its Constructor and released in its Dispose—like putting a large object on the Small Object Heap (SOH), in essence. It implements the IList<T> interface, so it can be accessed by index in your code, similar to a regular value type array. It’s really easy to use—simply use it in place of the built-in value type arrays (i.e. change "int[]" to "ArrayNoLOH<int>", etc.) You can add support for additional value types by following the instructions listed in the comment section in the ArrayNoLOH<T> class. We hope we’ve made it relatively easy to extend and leave that as an exercise for the reader.
Currently, ArrayNoLOH<T> only supports value types, not reference types. Reference types are far more complex and outside the scope of this article. Obtaining the byte size of a reference type is much more complicated, making it a great deal more difficult to implement. Theoretically, if someone were daring and crazy enough with the expertise to calculate the precise byte size of large reference type objects, it might be possible to replace the LOH entirely with this new technique. The GC could change from SOH—LOH to SOH—VirtualAlloc, much closer to the way heaps created with HeapCreate operate with HeapAlloc’s below 512KB using the heap and above 512KB using VirtualAlloc direct to OS, as shown in Figure 8. In other words, GC allocations under ~83KB would use SOH, over ~83KB would use VirtualAlloc direct to OS (i.e. under ~83KB heap-based, over ~83KB non heap-based). We’re not glutton’s for punishment and don’t want to lose what sanity we have left, so we’ll leave that gruesome experiment as an exercise for the readers who are true coding ninja’s.
An integral value type array doesn’t have to be nearly as big as you might think to go on the LOH. A byte[] goes on the LOH at 85,000 bytes. However, an int[] only needs to be roughly a paltry length of 21,250, since each int is 4 bytes. A long[] only needs to be roughly a measly 10,625 in length, since each long is 8 bytes. Wow!
Additionally, we implemented explicit operators for casting to and from the built-in value type arrays (i.e. ArrayNoLOH<byte> to byte[], byte[] to ArrayNoLOH<byte>, etc.), however using them is not recommended. The byte[] will end up going on the LOH, thereby defeating the entire purpose. We included them only for convenience interacting with your existing functions already in your code and simply as a how-to example.
The second, SplitNoLOH() and SplitLazyLoad(), are implemented as extension methods in the System namespace and should automatically show up in Intellisense for the string data type. Both accomplish essentially the same as the built-in string split, without using the LOH, so the LOH won’t become fragmented. They’re extremely easy to use—simply append "NoLOH" or "LazyLoad" on the end of an existing string.Split function call (i.e. change "string.Split" to "string.SplitNoLOH".) That’s it!
SplitLazyLoad() does not return a string[] in memory which can be accessed by index in your code. Instead, it simply enumerates, splitting the string into substrings which can only be used inside that for each loop. In a sense, it’s treated like a number of small string objects, instead of one large string array object. It’s extremely fast and uses minimal memory. If your existing code doesn’t require a string[] be returned, or you can re-architect your code to use this method, it’s by far your best choice.
SplitNoLOH(), on the other hand, returns StringArrayNoLOH (in place of string[]) which can be accessed by index in your code. StringArrayNoLOH is backed by unmanaged memory (not LOH) that’s allocated in its Constructor and released in its Dispose—like putting a large object on the SOH, in essence. It stores the delimiter location and length of each substring in the unmanaged memory, as a pair of int’s. It implements the IList<T> interface, so it can be accessed by index in your code, similar to a regular string[]. The indexer uses these delimiter locations and lengths to return the actual substring from the original string.
A string only has to be more than roughly 42,500 characters to go on the LOH, since it uses a char[] internally for its implementation and the .NET char is 2 bytes for Unicode. However, the internal implementation for string split uses an int[] the length of the string to keep track of the split delimiter locations, see line 984 (int[] sepList = new int[Length];) in string.cs inside the SplitInternal function at (https://referencesource.microsoft.com/#mscorlib/system/string.cs). This causes the string split to put an int[] on the LOH when the string being split is a meager 21,250 characters roughly, since an int is 4 bytes. Not as large as you might think!
The third, MemoryStreamNoLOH, is backed by unmanaged memory (not LOH) that’s allocated in its Constructor and released in its Dispose. There’s an internal list of pointers to segment blocks of unmanaged memory. The stream automatically expands, with new segments automatically allocated and added to the list as necessary, when writing to the stream. The memory segments don’t need to be contiguous and their size can be specified, if tuning is necessary. You can use it pretty much anywhere a stream interface is allowed; serialization, sockets, etc. Pretty cool!
When serializing a list of customer objects, you’d actually be surprised at how little a count is required to force the memory stream to the LOH. In our tests, it only took serializing a scant 1100 or so customer objects, using a relatively small rudimentary customer object.
Even if you completely disagree with our theory and think our new technique is absolute rubbish, we still thought you might possibly find it somewhat useful to have a very simple example implementing the stream interface (deriving from the base class Stream) with an expandable custom backing store. We thought it might be handy to utilize as a starting template to expand with your own new ideas, replace with your own custom backing store or even perhaps to customize other projects you may have which contain code that expects a stream object. If it sparks some new ideas, it was worth the effort!
Test Results
Tester.exe, shown in Figure 2, contains test cases to reproduce the LOH fragmentation problem—one test case per tab. Each tab allows you to easily compare the .NET GC to our new technique. Each test consists of multiple threads creating transient short-lived objects and one thread simultaneously creating permanent long-lived objects in a list. There are two "Start" buttons—one to start creating the short-lived objects and one to start creating the long-lived objects. Press both "Start" buttons at the same time, with the "LOH" option selected, to run the test using the .NET GC. A "TestResults_LOH_..." file’s generated. Press both "Start" buttons at the same time, with the "No LOH" option selected, to run the exact same test using our new technique. A "TestResults_NoLOH_..." file’s generated. Then, you can simply compare these two test result files.
We ran our tests on a Windows Server 2012 R2 64-bit with 12GB memory, 50GB page file and 8 logical processors (4 cores). The .NET GC was configured in "Server GC" mode (e.g. 8 heaps) and "Background GC (Concurrent)" mode.
Many of our tests began experiencing severe server problems after running for merely twenty-thirty minutes or so—physical memory completely exhausted, disks screaming whilst paging to disk and in some cases our video monitor even died. Not good!
Figure 3 rather clearly illustrates the truly colossal impact fragmentation in the LOH can have on the server’s Working Set (i.e. physical RAM) and size of the LOH. It’s astonishing! The red line is the plotted test results for the .NET GC, utilizing byte[]. The blue line is the plotted test results for our new technique, utilizing ArrayNoLOH<byte>. The gap between each dot on the red line and the corresponding dot on the blue line in the Working Set Comparison chart is almost entirely due to fragmentation in the LOH. Almost beyond belief!
The tests consisted of:
- 80 threads creating transient short-lived objects (randomly sized between 100,000-101,000 bytes)
- Simultaneously 1 thread creating permanent long-lived objects (randomly sized between 100,000-101,000 bytes)
Figure 3 Shows the actual amount of Working Set (physical RAM) and LOH being consumed by the process in order to store an amount of long-lived memory in the list.
Notice in the Working Set Comparison chart, the blue line denoting our new technique tracks very closely to the total actual memory being stored in the list. While on the other hand, the red line denoting the .NET GC reaches double to almost triple the total actual memory being stored in the list. Wow, that doesn’t even seem possible! Wasting memory resources on the server at these kinds of ratios can severely cripple a server in the blink of an eye.
What’s more, notice in the LOH Size Comparison chart, once the LOH Size exceeded the physical RAM on the server and started paging to disk; the server became so sluggish that for all practical purposes it was un-usable. Programs would take forever to open, screens would stay frozen for long periods of time, the mouse would barely move, etc. Moreover, opening any additional programs while it was in this paging state appeared to only intensify the fragmentation problem. On the other hand, our new technique (denoted with the blue line) seemed to function adequately, even all the way up to 40GB. Programs could be opened at will and were actually usable, screens wouldn’t be frozen for long periods, the mouse functioned normally, etc. It appeared as though our new technique was functioning roughly the same at 40GB as 15GB, 20GB, etc. Although we didn’t test past 40GB, it appeared as though our new technique would probably utilize the page file successfully all the way to its’ upper limit, even while being under the intense load. Conversely, it appeared when the LOH utilized any of the page file, under this intense load, it rendered the server virtually un-usable.
We observed in our tests that when there were no short-lived transient objects causing fragmentation in the LOH, the LOH appeared to function well using the page file, basically performing similar to our new technique. However, when a short-lived transient object load was placed on the system, introducing fragmentation, it appeared the LOH algorithms seemed to greatly intensify the paging, rendering the server virtually un-usable. Our new technique was able to function well using the page file, even with this massive short-lived transient object load. Since our new technique doesn’t produce fragmentation in the LOH, the LOH algorithms simply didn’t apply.
What the tests seemed to demonstrate was the LOH can only function well when there’s no short-lived transient objects to cause LOH fragmentation. When there’s no fragmentation, the LOH seemed to function comparably to our new technique. The really important thing to realize here is our new technique functions well, even with these short-lived transient objects. We think it’s pretty safe to conclude from the tests, LOH fragmentation has a severe impact on garbage collection in .NET.
The Working Set Comparison chart also highlights another extremely interesting point—our new technique (essentially VirtualAlloc) appears much closer to linear, since there’s very little fragmentation. We believe this linear nature may in fact be precisely one of the reasons OS designers chose to bypass the heap and go directly to the OS with VirtualAlloc() as well, when a HeapAlloc() is over 1MB (512KB for 32-bit), as shown in Figure 9. We can’t necessarily prove it. However, it sure makes one wonder.
Since HeapAlloc() utilizes the heap handle from either HeapCreate() or GetProcessHeap() and many, if not most, heaps are created with HeapCreate(), we believe it’s probably fair to say this strategy with VirtualAlloc() is rather widely employed. Additionally, as shown in Figure 8, since GlobalAlloc(), LocalAlloc(), malloc() and C++ new all basically utilize HeapAlloc() as well, they too are essentially utilizing this same strategy with VirtualAlloc().
Really makes one stop and think, why we don’t utilize this same strategy for every single allocation over ~83KB (85,000 bytes), instead of using the LOH. If it’s good enough for them above 512KB (1024KB for 64-bit), why isn’t it good enough for us above 83KB? In the old 32-bit days, we had to worry about virtual address fragmentation. However, in the new 64-bit days, the massive virtual address space has almost eliminated that concern entirely. Nevertheless, it’s really interesting to ponder.
In Figure 4 below, we simply measured the time it took to add 10GB worth of long-lived objects to a cache list using one thread, merely to compare raw allocation speed utilizing various size objects. The tests depicted in the red line utilized byte[], while the tests depicted in the blue line utilized ArrayNoLOH<byte>. As you can see, they appeared to be roughly equivalent.
Figure 4 Time it takes to add 10GB of objects to a list using the LOH vs. our new technique.
The following are actual test results, for just a few of the numerous tests we completed, so you too could see what a dramatic impact our new technique made on LOH fragmentation, almost eliminating the problem altogether. We were rather astonished when we observed these results!
1) ArrayNoLOH<byte> test:
We chose to put extra focus on this test, the byte array, since it’s the lowest common denominator and simplest example, showing the memory fragmentation problem clearly and precisely, hopefully making it much easier to observe and appreciate. The other tests also exhibited the same memory fragmentation problem; however, it’s not as glaring and easy to see, since they’re basically just an applied result of utilizing an array internally. We still felt it was extremely important to include them, since they can cause extensive fragmentation in the LOH without the developer even knowing or realizing.
This test consisted of:
- 80 threads quickly creating and destroying large transient short-lived objects (randomly sized between 100,000-101,000 bytes)
- Simultaneously 1 thread quickly creating large permanent long-lived objects (randomly sized between 100,000-101,000 bytes) and storing them in a list
- Test completed when total size of list reached 3GB
This test was attempting to somewhat mimic a busy production server. Running the exact same test with our new technique made the problems virtually disappear. The difference it made was really quite remarkable! Not only did the fragmentation problem virtually disappear, but the server itself ran much smoother, without the GC constantly churning. We we’re amazed!
Figure 5 below shows the test result files generated by Tester.exe for the LOH (GC) test and No LOH (new technique) test, containing the test results for both the byte[] and ArrayNoLOH<byte>, respectively. Notice in the LOH (byte[]) results, the Working Set and Large Object Heap Size are roughly 2.7 times the size of the actual bytes cached in the list, almost entirely due to the fragmentation (free space) in the LOH heaps (see Table 1). As you can see, it took approx. 8GB of Working Set (i.e. physical RAM) to actually store approx. 3GB of memory in the list. Almost triple—roughly 64% fragmentation! While on the other hand in the No LOH (ArrayNoLOH<byte>) results, the Working Set is only slightly higher than the actual memory cached in the list, since there’s virtually no fragmentation (free space) in the LOH heaps (see Table 1). Wow! This can be extremely serious for a server, since both Working Set and Large Object Heap Size represent physical RAM.
Figure 5 Test result files for byte[] vs. ArrayNoLOH<byte> (on 64-bit server).
In Table 1 below it shows the fragmentation (free space) in the LOH heaps, caused by utilizing byte[] versus utilizing our new technique ArrayNoLOH<byte>. It contains the output from the !heapstat command in WinDbg.exe, generated by simply attaching to the running release build of the Tester.exe process and issuing commands ".loadby sos clr" followed by "!heapstat". Notice the massive fragmentation (free space) in the LOH caused by byte[], while ArrayNoLOH<byte> causes basically no fragmentation (free space).
Table 1 output from !heapstat command in WinDbg.exe
| | Byte[] | ArrayNoLOH<byte> |
| Heap 0 (free KB \ total KB) | 575,085 | \ | 742,549 | (77% frag) | .3 | \ | 382 | (0% frag) |
| Heap 1 (free KB \ total KB) | 522,671 | \ | 684,154 | (76% frag) | .1 | \ | 256 | (0% frag) |
| Heap 2 (free KB \ total KB) | 671,429 | \ | 1,082,184 | (62% frag) | 0 | \ | 0 | (0% frag) |
| Heap 3 (free KB \ total KB) | 573,426 | \ | 657,166 | (87% frag) | 0 | \ | 0 | (0% frag) |
| Heap 4 (free KB \ total KB) | 705,100 | \ | 989,703 | (71% frag) | .1 | \ | 1,016 | (0% frag) |
| Heap 5 (free KB \ total KB) | 723,812 | \ | 1,350,811 | (53% frag) | 0 | \ | 0 | (0% frag) |
| Heap 6 (free KB \ total KB) | 798,757 | \ | 1,802,680 | (44% frag) | 0 | \ | 0 | (0% frag) |
| Heap 7 (free KB \ total KB) | 729,127 | \ | 1,138,503 | (64% frag) | 0 | \ | 0 | (0% frag) |
2) string.SplitNoLOH test:
This test consisted of:
- 80 threads splitting a large string of 42,500 characters, which causes large transient short-lived objects to be quickly created and destroyed
- Simultaneously 1 thread quickly creating large permanent long-lived objects (randomly sized between 100,000-101,000 bytes) and storing them in a list
- Test completed when total size of list reached 2GB
Again, this test was attempting to somewhat mimic a busy production server. The transient short-lived objects were caused by the int[] (which is the length of the string) used to keep track of the split delimiter locations down in the internal implementation code of the Split function. Running the exact same test with our new technique (SplitNoLOH) made the problems virtually disappear, as you can see in both Figure 6 and Table 2. Quite a difference!
Figure 6 is the results of this test in graphical form; PerfMon.exe and the memory graphic from the Performance tab in Task Manager. Notice for string.Split (on the left), the Large Object Heap Size (red line) and Working Set (blue line) ended up being roughly 3.7 times the size of the "Actual Bytes Cached" in the list (green line), while for the string.SplitNoLOH (on the right), the Working Set (blue line) almost matches the "Actual Bytes Cached" in the list (green line). Also, notice in the memory graphic from Task Manager, how much more actual memory (RAM) is being consumed with the string.Split compared to the string.SplitNoLOH. Pretty shocking! Almost unbelievable!
Figure 6 PerfMon.exe output and Memory graphic from Performance tab in Task Manager for string.Split (left) and string.SplitNoLOH (right).
It’s extremely important to note just how easy it is to accidentally have lots of short-lived transient objects end up on the LOH, without even realizing, simply due to a large scale server splitting strings. As you can see in Table 2, it can have a rather dramatic impact on server resources. An extremely busy production server may be splitting massive numbers of strings during normal standard operation which can have a huge impact on server resources without even realizing.
Table 2 shows the results of this test for string.Split() vs. string.SplitNoLOH():
| | .Split() | .SplitNoLOH() |
| "Actual Bytes Cached" in list (KB) | 2,097,164 | | 2,097,161 |
| Large Object Heap Size (KB) | 7,721,790 | (3.7 times actual) | 722 |
| Working Set (KB) (RAM) | 7,847,308 | (3.7 times actual) | 2,298,332 |
| | | | | | | | | |
| Heap 0 (free KB \ total KB) | 1,096,227 | \ | 2,988,031 | (36% frag) | .2 | \ | 196 | (0% frag) |
| Heap 1 (free KB \ total KB) | 617,839 | \ | 674,750 | (91% frag) | .1 | \ | 83 | (0% frag) |
| Heap 2 (free KB \ total KB) | 646,795 | \ | 660,019 | (97% frag) | 200 | \ | 570 | (35% frag) |
| Heap 3 (free KB \ total KB) | 643,059 | \ | 659,226 | (97% frag) | 0 | \ | 0 | (0% frag) |
| Heap 4 (free KB \ total KB) | 672,808 | \ | 691,919 | (97% frag) | 0 | \ | 0 | (0% frag) |
| Heap 5 (free KB \ total KB) | 708,372 | \ | 735,176 | (96% frag) | 0 | \ | 0 | (0% frag) |
| Heap 6 (free KB \ total KB) | 567,386 | \ | 593,267 | (95% frag) | 0 | \ | 0 | (0% frag) |
| Heap 7 (free KB \ total KB) | 669,752 | \ | 719,399 | (93% frag) | 0 | \ | 0 | (0% frag) |
3) MemoryStreamNoLOH test:
This test consisted of:
- 10 threads quickly serializing a list of 1400 Customer objects into a memory stream and returning an array of bytes, which causes large transient short-lived objects to be quickly created and destroyed
- Simultaneously 1 thread quickly creating large permanent long-lived objects (randomly sized between 100,000-101,000 bytes) and storing them in a list
- Test completed when total size of list reached 5GB
Once again, this test was attempting to somewhat mimic a busy production server. The transient short-lived objects were caused by the memory stream utilized by the binary serializer, as well as the array being returned. Running the exact same test with our new technique (MemoryStreamNoLOH) made the problems virtually disappear, as you can see in Table 3. The difference it made was amazing!
It’s extremely important to note just how easy it can be to accidentally have lots of short-lived transient objects end up on the LOH, without even realizing, simply due to a large scale server serializing objects. As you can see in Table 3, something as simple as this can have a somewhat colossal impact on server resources. We really wanted to show you these test results since a busy server may be doing lots of serializing in its’ normal day-to-day operations that can become crippling to your server in no time.
Table 3 shows the results of this test for MemoryStream vs. MemoryStreamNoLOH:
| | MemoryStream | MemoryStreamNoLOH |
| "Actual Bytes Cached" in list (KB) | 5,242,970 | | 5,242,970 |
| Large Object Heap Size (KB) | 9,531,594 | (1.8 times actual) | 7,504 |
| Working Set (KB) (RAM) | 9,751,416 | (1.9 times actual) | 5,599,128 |
| | | |
| Heap 0 (free KB \ total KB) | 518,734 | \ | 1,358,347 | (38% frag) | 1,802 | \ | 2,071 | (87% frag) |
| Heap 1 (free KB \ total KB) | 511,303 | \ | 1,418,457 | (36% frag) | 2,403 | \ | 3,115 | (77% frag) |
| Heap 2 (free KB \ total KB) | 499,866 | \ | 1,906,318 | (26% frag) | 72 | \ | 314 | (23% frag) |
| Heap 3 (free KB \ total KB) | 563,613 | \ | 793,743 | (71% frag) | .1 | \ | 200 | (0% frag) |
| Heap 4 (free KB \ total KB) | 547,767 | \ | 858,495 | (63% frag) | .1 | \ | 200 | (0% frag) |
| Heap 5 (free KB \ total KB) | 590,589 | \ | 989,587 | (59% frag) | 0 | \ | 0 | (0% frag) |
| Heap 6 (free KB \ total KB) | 516,068 | \ | 1,062,992 | (48% frag) | 1,602 | \ | 2,002 | (80% frag) |
| Heap 7 (free KB \ total KB) | 536,236 | \ | 1,143,649 | (46% frag) | 0 | \ | 0 | (0% frag) |
In Table 4 below it shows the output from the !dumpheap command on the LOH starting address on a 64-bit Windows Server 2012 R2 configured in Workstation GC mode (i.e. only 1 heap). As you can see, it confirms a byte[] being added to the LOH after the call to the Serialize function, and a second byte[] being added to the LOH after the call to the ToArray function (both are highlighted in red boxes). Then, the bottom half of the table simply confirms no byte[]’s are added using our new technique.
Our MemoryStreamNoLOH class only keeps these two byte[]’s specifically generated by the regular MemoryStream and ToArray function off the LOH. The additional Int64[] and Object[] created after the call to the Serialize function are coming from somewhere down in the Serialize function, outside of our control, and may be what’s contributing to the minimal disturbance we see in the heaps for the MemoryStreamNoLOH column in Table 3.
It’s easy to do "!dumpheap", simply attach WinDbg.exe to the running process and issue the commands ".loadby sos clr" followed by "!eeheap –gc" followed by "!dumpheap 0x????????????????" (replacing ?’s with LOH starting address). That’s it!
Table 4 output from !dumpheap command on LOH
using(MemoryStream ms = new MemoryStream())
{
new BinaryFormatter().Serialize(ms, list);
return ms.ToArray();
}
using(MemoryStreamNoLOH ms = new MemoryStreamNoLOH())
{
new BinaryFormatter().Serialize(ms, list);
return ms.ToArray();
}
4) ArrayNoLOH<byte> test (on 32-bit server):
We included this test on a 32-bit server as well, purely for informational purposes. We still wanted you to see the same LOH fragmentation problem exists on 32-bit servers as well, even though our technique isn’t designed for 32-bit servers, due to their limited virtual address space.
Figure 7 Test result text files for byte[] vs. ArrayNoLOH<byte> (on 32-bit server).
As you can see in all four of the above tests, the LOH can be an extremely inefficient use of server resources. By merely avoiding the LOH altogether, utilizing our new technique which goes direct to the OS with VirtualAlloc instead of using a heap, your server can achieve much better resource utilization.
Even if your server isn’t experiencing this massive LOH fragmentation problem; we found our new technique actually made the server run far better in our tests. The entire server was much more stable. Memory usage was far less and the increase was much closer to linear. Disks weren’t red-lining like the tachometer in a race car, due to paging. It was rather astonishing and somewhat shocking!
So…to heap or not to heap really is the large object question?????
One of the prime compelling benefits of a managed language like C# is the managed memory and GC, shielding us from pointers and unmanaged memory, eliminating the potential memory leaks associated with forgetting to free a pointer. You may be concerned thinking pointers to unmanaged memory in C# is dangerous, going against what the authors of C# were trying to accomplish. However, freeing the pointer to the unmanaged memory in the Dispose of the managed object, guarantees there won’t be a memory leak. That’s why we describe our new technique as more or less a way of putting a large object on the SOH, as shown in Figure 1.
We really wanted you to be able to surgically and elegantly utilize this new technique in your existing code base, with absolutely minimal changes and virtually no modification to your existing logic. If your server’s experiencing problems with the LOH due to splitting large strings, we wanted you to be able to simply append "NoLOH" to the existing string.Split and voila, your problems disappear. Or, simply append "LazyLoad" and bang, problem solved! No redesign, no change to logic—simply problem gone. Serializing large collections of objects causing problems in the LOH? No problem, simply change MemoryStream to MemoryStreamNoLOH—problem solved. Or, is it hordes of large int[] objects wreaking havoc on your server’s LOH? No problem, simply replace int[] with ArrayNoLOH<int>. Problem gone!
Moreover, we wanted to give you a good base starting point to experiment with going forward, creating your own new theories and techniques. In our research over the years, we always found it somewhat difficult to get a really simple, clear picture of the memory system in the OS, as it relates to heaps and the .NET GC. So, we created this article as an extremely simplified basic overview for reference.
The Concept
For ordinary usage scenarios encountered during standard scale IIS Web Server operation, you may never witness any significant LOH fragmentation. However, when an IIS Web Server is pushed to its limits at enterprise scale, often, unusual memory usage patterns can inadvertently emerge, leading to LOH fragmentation. As .NET programmers we generally don’t think much about fragmentation, or even realize there can be a significant risk of fragmentation. We tend to believe that somehow we are magically shielded from all those gory details.
Generally speaking, fragmentation is the result of mixing transient short-lived objects with permanent long-lived objects, in a heap. When it comes to fragmentation, it’s not really the size of the object, as much as it’s the duration of the object, which can severely affect fragmentation. If we always had a completely separate heap for transient short-lived objects, and a completely separate heap for permanent long-lived objects, essentially fragmentation would not occur. Memory for the short-lived objects would constantly be reclaimed and readily available for the next short-lived object, without leaving this memory trapped between two long-lived objects. Long-lived objects would simply be appended to the end of their heap, in consecutively order, because they will never need to be reclaimed. Fragmentation would not occur for long-lived objects, because there would be no transient short-lived objects to produce gaps in memory between the long-lived objects.
The .NET Garbage Collector (GC) focuses much more on the size of the object, as opposed to the duration of the object, with its Small Object Heap (SOH) and Large Object Heap (LOH). The SOH doesn’t have to worry about fragmentation due to its’ compacting design, however, the LOH essentially allows mixing of transient short-lived objects with permanent long-lived objects, which can lead to severe fragmentation. In all probability, it might have been much better, as far as fragmentation is concerned, designing the GC with a Short-lived Object Heap (SOH) and Long-lived Object Heap (LOH), instead of its current Small Object Heap (SOH) and Large Object Heap (LOH). Without even knowing it, you can cause severe fragmentation in the LOH. Doing something as simple as continuously splitting large strings over long periods of time or as insignificant as serializing a collection of objects to a memory stream, while at the same time, adding large objects to a permanent cache list that will exist for the life of the program, can many times lead to significant LOH fragmentation without even realizing it. Scary!
In this article we’ve put forth a theory that will explore the question of whether it would be better to employ a heap or not employ a heap, when dealing specifically with large objects. For regular standard heaps, which handle both small and large objects (like the CRT Heap), the answer is pretty straight forward—you need a heap. You can’t afford to waste entire pages of memory for small objects that are several bytes in length. However, for large objects, that consume many, many pages of memory, the answer gets rather fuzzy. We’ve developed a simple technique (shown in Figure 1) that doesn’t use the LOH for large objects, but instead goes directly to the OS. The sample project that’s included has the code implementing this new technique.
There’s essentially two ways for a process to get memory from the OS; heap-based (HeapCreate\HeapAlloc), or non heap-based (VirtualAlloc), as shown in Figure 8. Heap-based should generally be utilized for the smaller sizes in order to avoid massive waste; while utilizing non heap-based should generally be reserved for only large sizes.
Figure 8 How process obtains its memory from OS, using Heap-Based allocation or Non Heap-Based allocation
The smallest allocation granularity allowed for VirtualAlloc is a 64KB block of virtual addresses and 4KB page of physical memory. That’s precisely why computer science developed the concept of a heap; to take care of everything under the size of a page, so full memory pages aren’t being wasted for several bytes. Our technique is designed only for large objects over roughly 83KB—greater than the size of a page. Consequently, we use non heap-based allocation with VirtualAlloc direct to the OS. We’re not the only ones. Interestingly, when HeapAlloc is greater than 512KB, the OS itself uses non heap-based allocation with VirtualAlloc direct to the OS, as shown in Figure 9.
Figure 9 The two ways to obtain Heap required for allocating memory with HeapAlloc() function
Thus, a somewhat compelling argument can be made—to not heap—when answering the large object question. Not employing a heap, for large objects, somewhat flies in the face of conventional wisdom. Nevertheless, we ask you to bear with us and have an open mind, because the sample code quite possibly could help your server that’s experiencing a crippling LOH fragmentation problem, or just may spark new ideas that lead to unconventional solutions for enterprise servers experiencing severe LOH fragmentation. Even if you completely disagree, exploring this subject matter from a completely different angle is an extremely interesting journey, nonetheless.
Heaps, memory allocation and virtual memory are an extremely complex subject matter that simply can’t be properly covered within the scope of a single article. We are not attempting to provide an exhaustive coverage of this subject matter, but rather an extremely simplified overview, that hopefully makes it easy to visualize and understand. You can refer to the documentation on the Microsoft Web site for all the gruesome detail.
Why do we care about LOH fragmentation?
Well, for a 32-bit process running on a 32-bit OS, LOH fragmentation can very quickly lead to an "Out of Memory" exception, terminating the process entirely. For a 64-bit process running on a 64-bit OS, LOH fragmentation can very quickly lead to extremely large memory consumption, severely impairing the performance of the process and crippling your application. That excessive memory consumption can result in substantial paging to the system page file, burying your hard drives under a never-ending phony workload. With 64-bit, fear of the dreaded "Out of Memory" exception terminating the process is all but eliminated; however, the affects of this massive memory consumption can often bring even the most robust servers to a grinding halt. Whether its IIS continuously cycling the application pool processes (w3wp.exe) due to "Out of Memory" exceptions or the server grinding to a halt, in the end the result is fundamentally the same; your application appears structurally unsound and unprofessional.
Our new technique avoids LOH fragmentation, by avoiding the LOH altogether, as shown in Figure 1. Our technique is by no means a permanent replacement for the LOH, and is intended to be used merely as an alternative way of dealing with large objects in .NET. It should only be employed as a last resort, when your server is experiencing the rare symptoms of LOH fragmentation caused by this atypical behavior.
Most experts recommend some sort of buffer pooling technique (be it your own custom buffer pool implementation or an existing .NET buffer pool implementation), reusing the same buffers from the pool, over and over again, to keep from fragmenting the LOH. That technique works well, however it places the responsibility on the developer to code their program in a precise style, so their program utilizes the LOH without causing fragmentation, instead of simply allowing the GC to handle everything for us. We wanted to provide you an alternative technique that’s extremely simple, going directly to the OS with VirtualAlloc, to avoid the complexities of creating and maintaining your own enterprise level, production quality, buffer pool design.
Creating a production quality buffer pool design is no easy task—it can dramatically increase the complexity of your code. Additionally, it can be somewhat burdensome for new developers coming in at a later date to maintain your code, when they must learn to use a custom buffer pooling style and must remember to closely adhere to that custom coding style to keep from fragmenting the LOH. Moreover, one of the main benefits promised, enticing us to use the .NET Framework over C++ was no longer being required to manually manage our own memory. Consequently, to say the programmer needs to manually build a pool of buffers along with the infrastructure to manage them or strictly adhere to specialized custom rules for an existing .NET buffer pool implementation, simply to utilize the LOH without failure, seems to go against what was enticing to convert to the .NET Framework in the first place. If we’re having to manually manager our own memory again, wouldn’t it be better to use C++, where we have full control of the memory? We’re not advocating going back to C++, we’re simply saying, pushing it out so it’s the developer’s responsibility to manually manage memory as the solution for fragmentation is kind of weak. All things the same, building a buffer pool as the solution to LOH fragmentation, in a language whose flagship selling point is to shield developers from memory management, seems to be a rather weak argument for using the .NET Framework over C++, where there’s total control over the memory.
32-Bit vs. 64-Bit
Our new technique is solely designed for a 64-bit process running on a 64-bit OS. A 64-bit process running on a 64-bit OS (Windows Server 2012 R2) has an impressive 128TB of virtual address space for user mode code (128TB for user and 128TB for system), as shown in Figure 10. While a process running on a 32-bit OS by default has a meager 2GB of virtual address space for user mode code (2GB for user and 2GB for kernel). The massive 128TB of virtual address space for user mode code all but eliminates the repercussions of virtual address space fragmentation, which can sometimes potentially arise using our technique. Simply put, we’re basically trading memory fragmentation in the LOH, for virtual address fragmentation. Memory fragmentation in the LOH matters a great deal, while on the other hand, virtual address fragmentation doesn’t matter much because the actual physical memory is being released back to the OS and the address space is so large it takes a long time to run out of addresses. Even with excessive rapid allocations, quite some time must pass before you are at risk of exhausting virtual address space to the extent you are unable to obtain a contiguous block of virtual addresses required for the next allocation request.
Figure 10 Virtual Address Space layout of 64-bit process (Windows Server 2012 R2)
Although there’s no technical reason our technique can’t be used on servers running a 32-bit OS, in most cases, it’s much more affective to simply upgrade to a 64-bit OS and employ our technique, rather than working within the constraints imposed by the very limited virtual address space devoted to user mode code (2GB makes virtual address fragmentation an immediate concern).
In most cases, merely upgrading to a 64-bit OS alone (without our technique) can make a world of difference to a server experiencing LOH fragmentation. On the surface, the upgrade alone seems to completely resolve the problem—"Out of Memory" exceptions go away and IIS Application Pool’s (w3wp.exe) stop cycling. However, with closer analysis we see the process may actually be suffering from excessive memory consumption, which in some cases, can be more than double or even triple the true actual memory the process has been explicitly instructed to consume in its code; due entirely to LOH fragmentation. If we’re only talking about several gigabytes, for example, there won’t be a problem. However, for 50GB, 100GB or even 200GB there may now be some significant implications. If your process is only using 50GB, but the OS thinks it’s using 150GB—not good!
Our technique virtually eliminates LOH fragmentation; keeping a process’s memory consumption more inline with the true actual memory it’s been explicitly instructed to consume. For example, let’s say a process has been explicitly instructed in its code to cache objects which amount to a total of 50GB of true actual memory. With our technique, the process may be running at 51GB. However, absent our technique, the process may be running at 100GB or more. The process is using only 50GB in actuality, but the OS thinks it’s using more than 100GB, due to LOH fragmentation. On even an extremely robust server, with lots of physical memory and a large page file, this can still become a serious, possibly fatal problem as the cache continues to increase.
How Technique Works
Keep everything off the LOH and keep it on the SOH. If nothing’s ever allocated on the LOH, memory for the LOH can’t become fragmented, and the need to compact the LOH is eliminated. Problem solved—life is good. However, keeping everything on the SOH is easier said than done when you’re an enterprise scale web portal, dealing with large arrays, parsing and splitting large strings, large XML, large JSON and scores of large HTML files. It may surprise you to know array objects don’t need to be all that large to end up on the LOH. A byte[] must be greater than 85,000 bytes. However, an int[] only needs over roughly 21,250 elements and a long[] only needs over roughly 10,625 elements. You say, so what? What does that have to do with me? I don’t use many arrays in my web portal code. Once more, you may be surprised to know that splitting a large string causes an additional int[] to go on the LOH, once the string reaches over roughly 21,250 characters in length. So without even realizing it, you may indeed be using lots of arrays in your web portal code. And, as a result, generating multitudes of large transient objects on the LOH, which is one of the key ingredients in the recipe for fragmentation. As soon as you sporadically mix in a dash of permanent cached objects, you have a perfect recipe for disaster. Yikes!
We use a regular managed class in C#, but don’t use managed memory to back it. Instead, in the Constructor, we allocate unmanaged memory with the VirtualAlloc() function. Then, in the Dispose, we release the unmanaged memory back to the OS with the VirtualFree() function. Since we allocate unmanaged memory in the unmanaged world with the VirtualAlloc() function, the .NET Garbage Collector (GC) is unaware of the memory. It thinks the C# class is simply a small object on the SOH, where it gets garbage collected and compacted regularly. When the C# class is disposed, it immediately releases the unmanaged memory back to the OS. The ensuing compaction eliminates any fragmentation in the SOH. Figure 1 illustrates the technique.
For the large arrays you can use this technique. Allocate unmanaged memory for the large array inside a regular managed C# class (to keep it off the LOH). Then, free the unmanaged memory in the dispose of the regular managed C# class (SOH compacts, so no fragmentation in SOH). You can also use this technique simply as a general way to keep large allocations off the LOH (using unmanaged memory), purely to avoid LOH fragmentation.
Having this unmanaged memory outside the control of the GC may raise some concern. However, one could argue most web servers today have more than enough memory to handle this level of fluctuation in memory usage. Since the C# class that releases the unmanaged memory when it’s disposed is simply a regular small C# object that gets garbage collected and compacted on a regular basis (on the SOH), the unmanaged memory shouldn’t continue to accumulate until it’s exhausted. There may be spikes in memory usage, but it shouldn’t continue to accumulate until server failure. Moreover, to further alleviate concern, there’s always the option of giving the GC knowledge of the unmanaged memory using GC.AddMemoryPressure and GC.RemoveMemoryPressure.
A Scary Thought
By its very design, the LOH will always eventually fail over time when the application mixes hordes of large transient objects with hordes of large permanent objects. The LOH will eventually run out of contiguous memory, due to fragmentation and no compaction, and will fail on the next allocation needing that contiguous memory.
It’s not if it will fail, it’s when it will fail.
This could mean there are currently a large number of web portals running at enterprise scale that are extensively using large arrays and splitting large strings, which are guaranteed to fail over time. It’s simply a matter of how long it will take. Scary! The problem could be far more prevalent and wide spread than we think. It’s entirely possible we don’t hear much about the problem, simply because the Web servers are continuously cycling the worker processes, or the LOH is being manually compacting from code on a regular basis. Both of these mask the true nature of the problem. They seem like reasonable solutions, however both can cause significant delays and freezing in your application, making it appear unprofessional.
Moreover, the robust recovery mechanisms built into IIS and ASP.NET make troubleshooting the problem rather insidious. When memory consumption for the worker process (w3wp.exe) reaches an unacceptable level or an "Out of Memory" exception is encountered, the worker process terminates, and the server simply starts a new worker process in its place. This functionality makes it rather difficult to troubleshoot. Most developers don’t even know where to start when it comes to troubleshooting this type of problem.
We suspect there may be a large number of enterprise production Web portal’s possibly experiencing this problem without even realizing it. Or, they’re aware it’s occurring, but aren’t sure what to do about it. Out of desperation, many may be simply letting the worker processes continuously cycle, or may even be changing the web server’s configuration to cycle the worker processes on an even earlier schedule. This doesn’t fix the problem; it simply masks the problem. Ever noticed pauses and freezing at various times while navigating a public enterprise Web portal? It could be that some of those pauses are quite possibly due to these worker processes cycling. Not good!
Wrapping Up
In this article we explore a theory; would it be better to not utilize a heap construct when dealing with very large objects in .NET, in order to avoid LOH fragmentation? Better to trade memory fragmentation for address fragmentation, with the massive 64-bit address space of today? Trade LOH fragmentation for VAS fragmentation? To heap or not to heap, that really is the million dollar question…
In this Part 1, we gave you an overview of the code and test results for our new technique, based on our new theory, presenting you a possible solution to the LOH fragmentation problem, in essence.
In Part 2, we’ll take a much deeper dive into the computer science behind this new theory, explaining the problem itself and why a solution’s even necessary in the first place. We hope you’ll join us. It will be exciting; if you love low-level gory details and are a glutton for mental punishment that is…
Part 2 – A Deeper Dive
In Part 1, we gave you an overview of the code and test results for a new technique, based on a new theory exploring whether it’d be better to not utilize a heap when dealing with very large objects in .NET. We chose to present you a possible solution to the problem first, in order to peak your curiosity and hopefully get you excited about the notion.
In Part 2, we’ll take a much deeper dive into the science behind this new theory, explaining the low-level gory details of the problem itself and why a solution’s even necessary in the first place. So, let’s jump right in…
Garbage Collector (GC)
The .NET GC is an amazing feat of engineering! It’s quite remarkable how well it handles such a diverse range of memory demands without fail, spanning from one end of the spectrum all the way to the other end of the spectrum. Moreover, with the advent of Background Workstation garbage collection using a dedicated background garbage collection thread and Background Server garbage collection using multiple background garbage collection threads (typically one per processor) starting in .NET Framework 4.5, coupled with support for manual compaction of the LOH from code starting in .NET Framework 4.5.1; the GC has become a truly astounding workhorse.
Conceptually, the GC’s managed heap is split into two parts; the Small Object Heap (SOH) and the Large Object Heap (LOH). The SOH is dedicated for objects below 85,000 bytes, and is compacted on a regular basis during garbage collections. When an object is destroyed in the SOH, leaving an empty spot in SOH memory, the SOH memory copies and moves (i.e. compacts) the remaining live objects to remove the gap, as shown in Figure 11.
Figure 11 Small Object Heap (SOH) – Example of Compaction after Full Garbage Collection (all generations)
The LOH, on the other hand, is dedicated for objects 85,000 bytes or more, and by design is never compacted. Any object that’s destroyed in the LOH permanently leaves an empty spot in LOH memory (causing fragmentation), unless the empty spot can be reused when a subsequent object is created, as shown in Figure 12.
Figure 12 Large Object Heap (LOH) - Example of Non-Compaction after Full Garbage Collection (LOH collected along with Generation 2), somewhat similar to more traditional style heap
The GC is primarily a generational garbage collector. The SOH consists of three generations: Gen0, Gen1 and Gen2. Gen0 is dedicated to short-lived objects, Gen2 is dedicated to long-lived objects and Gen1 acts as a bridge between short-lived and long-lived objects.
When Gen0 becomes full, a garbage collection occurs on Gen0. Surviving live objects in Gen0 are promoted to Gen1 by compacting the objects (removing the gaps in memory left from the dead objects) and adjusting the Gen1 boundary. When Gen1 becomes full, a garbage collection occurs on Gen1 and the younger Gen0. Surviving live objects in Gen1 are promoted to Gen2, Gen0 promoted to Gen1, by compacting the objects and adjusting the Gen2 and Gen1 boundaries, respectively. When Gen2 becomes full, a garbage collection occurs on Gen2, the younger generations (Gen1 and Gen0) and additionally the LOH. This is also known as a full collection. Surviving live objects in Gen2 stay in Gen2, Gen1 are promoted to Gen2, Gen0 promoted to Gen1, by compacting the objects and adjusting the Gen2 and Gen1 boundaries. Figure 11 illustrates an example of this process.
The LOH is not compacted. Designers of the GC made this architectural decision for the LOH, due to the inherent overhead involved in memory copying and moving very large objects when they’re compacted. Rather than compacting and incurring this overhead, the LOH instead maintains a list of free gaps left in memory after an object’s been destroyed, which can be reused to fulfill future allocation requests. It uses a highly-optimized algorithm that aggressively attempts to reuse of these blank spots in memory when allocating new objects. An extremely simplified illustration depicting this functionality is shown in Figure 13.
Figure 13 Large Object Heap (LOH) - Example of large object allocations after Full Garbage Collection (LOH collected along with Generation 2)
The concept of reusing these blank spots left in memory after an object’s been destroyed, instead of removing these blank spots by compacting the objects, is what can lead to excessive fragmentation of the LOH in situations where abnormal memory allocation patterns materialize. Basically, unless all objects are exactly the same size, so every blank spot can be perfectly reused, fragmentation in the LOH will inevitably occur. By compacting and thereby removing blank spots in the SOH, objects can be all different sizes without causing fragmentation.
Small Object Heap (SOH)
The designers of the GC hit an out of the park home run when architecting the SOH! Its compacting design allows it to handle tons of allocations and de-allocations, all at varying times and varying sizes, while at the same time producing virtually no fragmentation and maintaining object locality. It can service a staggering number of allocations with almost no noticeable impact to your application, despite the additional memory copying overhead required for compacting. It’s literally amazing!
Although compacting essentially removes fragmentation, it’s still worth noting the SOH is not impervious to fragmentation. Pinning small objects (under 85,000 bytes) in memory disrupts the compaction process of the SOH. The SOH is not allowed to move these pinned objects around in memory—they’re pinned where they are and can’t be moved. The SOH is still free to move and compact the objects immediately following the pinned object, as long as they aren’t pinned themselves. Objects which are pinned for very short periods of time and quickly destroyed rarely cause any serious fragmentation. However, objects which are pinned for extremely long durations can sometimes lead to extensive fragmentation of the SOH.
Be extremely careful and give due consideration to architectural designs where managed code extensively uses system functionality of the OS. These system API calls work with unmanaged memory and may require managed memory to be pinned when using them. Not done properly, significant fragmentation can inevitably occur.
Large Object Heap (LOH)
On the other hand, designers of the GC chose a completely different architecture for the LOH. The LOH is closer to some of the more traditional style heap designs that have been around since the beginning of computer science, essentially trying to reuse the free memory spots left from dead objects, instead of the compacting paradigm of the SOH. We say closer to the more traditional style heap designs, with one critical difference, many of the traditional style heap designs go directly to the OS with VirtualAlloc once an allocation exceeds a certain size—the LOH does not. It’s this design of reusing the free memory spots, instead of compacting, that makes the LOH more susceptible to fragmentation. If you have lots of large transient objects, constantly changing in size, mixed with lots of large permanent cached objects, you have a recipe for disaster, which can sometimes lead to massive fragmentation in the LOH.
The designers decided to never compact the LOH. Never compacting the LOH can many times lead to your process consuming massive amounts of memory, simply as an unfortunate side-effect of fragmentation. Although it’s rather unusual, it may indeed occur from time to time in very large scale enterprise environments. It’s kind of like winning the Lottery, only the prize is the server using all its memory, paging to disk and grinding to a crawl. Many times memory for the process can be much higher than actual memory being consumed by all the objects in the process, simply as a result of the fragmentation caused by never compacting the LOH. If you don’t compact—you will fragment—no matter how well you reuse free memory blocks, since not all allocations are exactly the same size.
LOH Fragmentation
Neither half of the GC is impervious to fragmentation. Essentially, fragmentation can be caused in the SOH by pinning memory, while fragmentation can be caused in the LOH by no compaction. Mixing tons of large transient objects, with tons of large permanent cached objects, while not employing compaction, can many times lead to massive LOH fragmentation.
Although there are many conditions on an enterprise scale web server that may cause it to perform poorly or even crash—many times it’s directly attributed to LOH fragmentation. By design, objects on the LOH are collected far less often, and when collected are never compacted, simply because it’s too costly. In many cases, this eventually leads to fragmentation of the LOH. Each new large object allocation tries to reserve contiguous memory. However, due to the fragmentation, these new allocations force the memory consumption of the process to increase dramatically. This excessive memory consumption eventually exhausts the server’s physical memory, leading to excessive paging to disk. At that point, it’s only a matter of time before the server starts to perform unsatisfactorily and inevitably crash.
Several recent features have been added to the .NET Framework to assist in dealing with these problems. First, you can do manual compaction of the LOH from code as shown:
GCSettings.LargeObjectHeapCompactionMode = GCLargeObjectHeapCompactionMode.CompactOnce;
GC.Collect();
However, it requires a full blocking garbage collection for the compaction to be initiated, which results in pauses for your application and end users during much of the garbage collection and compaction. Second, to reduce the pausing in your application caused by garbage collection, your server can be configured to use Background Server garbage collection as shown:
<configuration>
<runtime>
<gcConcurrent enabled="true"/> ("true"=Background GC, "false"=Foreground GC)
<gcServer enabled="true"/> ("true"=Server GC, "false"=Workstation GC)
</runtime>
</configuration>
Note:
Background GC: Does GC on background thread\threads (one thread per CPU).
: Helps latency (good for UI).
Foreground GC: Helps throughput (good for services with no UI).
Server GC: Should be faster when >2 CPU.
Workstation GC: Should be faster when 1 CPU.
However, this still doesn’t address the fragmentation of the LOH. It merely addresses the pausing symptom.
On the surface, having the ability to manually compact the LOH from code, along with reducing the pausing impact to your application during this compaction, appears to solve the problem. However, in reality, we’re only trading one problem for another different problem. If your web portal freezes for many seconds while the LOH is manually compacted from code, how is that any different from the web portal freezing while the worker processes cycle? Whether it’s automatically cycling the worker processes continuously on a schedule or manually compacting the LOH from code, the result’s the same—momentary pauses and freezing in your web portal that appears unprofessional to your end users.
The designers chose to never compact the LOH and still to this day never compact the LOH, even after the new feature was introduced allowing us to manually compact the LOH from code. They give developers the ability to compact the LOH from code at their own risk, letting them deal with the consequences of the costly impact on performance and the negative impact it may possibly inflict on their application. It really makes you stop and wonder when, or even if, it’s a good idea for a developer to manually compact the LOH from code.
An easy way to visual fragmentation is to think of your hard drive and disk fragmentation. Deleting files leaves blank spots on the disk, causing disk fragmentation. As the drive becomes more fragmented, your disk performance diminishes due to that fragmentation. When you manually execute the disk defrag command, the remaining files are compacted (copied and moved) to be more contiguous, eliminating the blank spots on the disk.
Similarly, when you manually compact the LOH from code, the live objects are compacted to be more contiguous, eliminating the blank spots in memory of the LOH. However, the only drawback is a full blocking garbage collection is required for the compaction to take place. If the LOH is not heavily fragmented and minimal memory copying is required for the compaction, you may get away with only a slight pause that isn’t even noticeable to your end users. Then again, if the LOH happens to be heavily fragmented and excessive memory copying is required for the compaction, your end users may experience significant pauses which are not only noticeable, but unacceptable. When you really stop and think about it, if it actually was the best thing to do and there were no significant downsides, wouldn’t the designers have chosen to automatically compact the LOH on a regular basis in order to avoid the fragmentation? Not just leave it to us developers to manually compact from our code?
We believe Microsoft chose to design the .NET GC this way, with two different architectures (SOH and LOH), so it would essentially be able to handle a majority of all general cases. Our technique is simply an alternative way to handle one specific case in the LOH. In a sense, we’re trading major external fragmentation, due to the entire segments of virtual address space the LOH is unable to give back to the OS in some cases when it’s fragmented, as shown in Figure 14, for minor internal fragmentation of virtual address space, inside the final 64KB block.
SOH Fragmentation
The SOH is not completely immune to fragmentation. Pinning memory for extended periods of time can lead to excessive fragmentation of the SOH, in some cases. Microsoft experts recommend pinning objects for very short periods of time and quickly destroying them, as the primary strategy to avoid this SOH fragmentation.
System functionality like asynchronous I/O or overlapped I/O generally requires you to pass in a buffer that will be used by the system to process the I/O request. Pinning’s required so the managed memory buffer won’t be moved while the I/O request is being processed by the system. If the managed buffer isn’t pinned, the garbage collector may possibly move the managed buffer in memory, causing the managed buffer to no longer be at the original location when the system tries to utilize the managed buffer after the asynchronous I/O operation is complete. Not a good thing!
Asynchronous I/O or overlapped I/O that’s pending for an extended period of time may result in a managed buffer being pinned for a lengthy duration. On a very busy, large scale server this could quite possibly cause mayhem in the SOH. Scary!
To see an extremely interesting example of what can happen to the SOH, take a look at the conversation in the following issue item being tracked at the Microsoft source code repository at (https://github.com/dotnet/coreclr/issues/1236). It has a great discussion regarding fragmentation in the SOH and even contains a print of an output screen from a memory profiling tool illustrating the problems which can arise in the SOH as a result of pinning memory for too long.
We’ve include an additional utility library called NoPin.dll to combat the problem of pinning in the SOH. NoPin.dll utilizes heap-based allocation with HeapAlloc, as shown in Figure 8. NoPin.dll allocates buffers in unmanaged memory from an unmanaged heap, which essentially eliminates the need for pinning. The unmanaged memory can’t be moved by the GC, so it doesn’t need to be pinned. You can utilize NoPin.dll to handle the buffer allocations we mentioned earlier that are simply too small to efficiently utilize our new technique in NoLOH.dll. Essentially, NoPin.dll utilizes heap-based allocation (HeapAlloc) and NoLOH.dll utilizes non heap-based allocation (VirtualAlloc). Figure 8 has an illustration showing heap-based and non heap-based allocation.
Places where managed buffers are pinned can now be replaced to eliminate the pinning, altogether. Instead of doing something like this (which pins the managed buffer, bytes, with the fixed statement):
fixed(byte* p = bytes)
{
r=Win32Native.ReadFile(h,p,count,IntPtr.Zero,overlapped);
}
You can now do something like this (which uses an unmanaged buffer that doesn’t need pinning):
using(NoPin.Buffer p = new NoPin.Buffer(bytes.GetLength(0)))
{
r=Win32Native.ReadFile(h,(byte*)p.Ptr,count,IntPtr.Zero,overlapped);
bytes=(byte[])p; //optional
}
Or, instead of doing this (which pins the managed buffer, bytes, with GCHandle.Alloc and GCHandleType.Pinned):
GCHandle h = default(GCHandle);
try
{
h = GCHandle.Alloc(bytes,GCHandleType.Pinned);
byte* p = (byte*)Marshal.UnsafeAddrOfPinnedArrayElement(bytes,0);
r=Win32Native.ReadFile(h,p,count,IntPtr.Zero,overlapped);
}
finally
{
if(h.IsAllocated) h.Free();
}
You can do this (which uses an unmanaged buffer that doesn’t need pinning):
using(NoPin.Buffer p = new NoPin.Buffer(bytes.GetLength(0)))
{
r=Win32Native.ReadFile(h,(byte*)p.Ptr,count,IntPtr.Zero,overlapped);
bytes=(byte[])p; //optional
}
What’s a Heap?
Simply speaking, the Virtual Memory Manager (VMM) of the OS is a paging memory system. Essentially, this means the VMM thinks of memory in 4KB pages; virtual address space (VAS) in 4KB pages called pages, and physical memory (RAM) in 4KB pages called page frames, as shown in Figure 15. Hence, the minimum granularity of memory is a 4KB page. However, it’s worth noting, for systems with large-page support, page sizes can optionally be configured to be considerably larger. A memory address is really nothing more than simply a number comprised of the page number and offset into that page (or physical page frame number and offset into that physical page frame). The VMM thinks of virtual addresses in 64KB blocks. The minimum allocation granularity of virtual addresses from virtual address space is a 64KB block (16 - 4KB pages), also shown in Figure 15.
Thus, when someone requests one byte of memory from the VMM of the OS using VirtualAlloc, they actually get a 64KB block of virtual addresses from virtual address space, since the minimum allocation granularity is 64KB. Then, when that one byte is actually accessed the first time, causing it to be mapped to physical memory, it’s actually using a 4KB page of physical memory, since the VMM thinks of physical memory in 4KB pages. Wasting a whole 64KB block of virtual address space and 4KB page of physical memory for just one byte would be extremely inefficient. So, computer science came to the rescue, introducing the concept of a heap, to efficiently handle allocation requests which are smaller than the minimum allocation granularity (64KB), smaller than the size of a page (4KB), or not precisely on a page boundary (4KB). In effect, heaps allow allocation requests that are smaller than a page, which can essentially eliminate the waste. With a heap, we can now get the one byte we want without wasting memory. If we always requested memory in multiples of exactly 64KB, everything would be great—there’d be no waste. Virtual address space wouldn’t be wasted and physical memory wouldn’t be wasted. It’d be perfect! Since that’s not really feasible, heaps are here to stay.
A heap is a mechanism that essentially changes memory allocation requests from page granularity to byte granularity by getting full pages of memory from the VMM of the OS and handing out individual bytes of memory to an application. In essence, it changes the smallest granularity from a page, to several bytes. This allows your application to make memory allocation requests smaller than one page or not precisely on page boundaries, without wasting memory. A really simple way of thinking about heaps is the VMM of the OS talks in full pages of memory, while an application talks in individual bytes of memory—the heap merely acts like a translator between the two, converting pages to bytes, in a sense. The heap acts as a sort of middle-man between the VMM of the OS and the application requesting the memory. You can think of it somewhat like a retail store. The retail store buys memory in bulk from the wholesaler (pages of memory from the VMM of the OS), then sells individual bytes of that memory to a retail consumer (individual bytes to the application) as a middle-man. It’s like buying one carton of strawberries from a retail grocery store (HeapAlloc), versus an entire truck-load of strawberries from the wholesale food distribution warehouse (VirtualAlloc). It’s like buying something individually retail (bytes), versus wholesale in bulk (pages). If you’re only going to eat several strawberries, buying an entire truck-load will sure waste a lot of strawberries.
If your allocation request is a small allocation request, that’s smaller than the size of a page or not precisely on a page boundary, it’s much more efficient to go to a heap as a middle-man in most cases. However, for larger allocation requests, like 1MB for example, you can go directly to the VMM of the OS yourself with VirtualAlloc. In fact, even heaps created with HeapCreate decide to go directly to the VMM of the OS with VirtualAlloc, when an allocation request is over 1MB (64-bit), as shown in Figure 9.
Why do we need heaps? Simple, heaps can make small allocation requests far more efficient. The heap’s able to give you the one byte you asked for, while internally managing the pages of memory. Cool! This seems to solve the problem, however it sometimes comes at a cost—fragmentation. Fragmentation’s no secret. It’s a rather well known problem in heaps. Since practically the beginning, programmers have been required to employ all sorts of mitigation strategies when allocating memory, in order to combat heap fragmentation.
The question’s not if a heap will fragment—it’s how much it’ll fragment.
The Low-Fragmentation Heap (LFH) in the Windows OS is a good example of heaps which do a great job keeping fragmentation to an absolute minimum, almost eliminating heap fragmentation in many cases. However, simply by the vary nature of what heaps are doing, there’ll most likely be some sort of fragmentation. Anytime you get a large block of something and attempt to pass out smaller chunks of it without compacting, you are somewhat destined for fragmentation, depending on the algorithm or construct you utilize to make that happen. Many heaps utilize the rather well-known design of attempting to refill blank spots left behind from dead objects with matching size allocation requests, rather than compacting like the SOH. This design will inevitably fragment, unless every allocation request is always the exact same size. It’s really just the degree of fragmentation that’ll vary. If you don’t compact, you can almost bet on some sort of fragmentation.
Since a heap’s acting as a middle-man, it can be a rather serious problem when it experiences fragmentation, because it may never give that fragmented memory back to the OS, as shown in Figure 14. However, on the other hand, going directly to the VMM of the OS with no middle-man (VirtualAlloc) is much less concerning, since the memory is actually being returned to the OS (VirtualFree). In this case, it’s usually just the address space that may become fragmented, not the memory.
Many of the well-known heaps, even all the way back to the beginning, utilize somewhat similar algorithms that more or less attempt to reuse blank spots left behind from dead objects for future allocation requests. For example, the Default Process Heap, CRT Heap (C-Runtime), .NET Large Object Heap (LOH), private heaps created in a process with HeapCreate, all operate with this somewhat similar algorithm. They don’t use compaction. This makes sense when you stop and think about it for a moment. The managed memory world has the luxury of the compaction paradigm, as a kind of by-product. Since the managed memory world doesn’t have pointers to raw memory addresses, we are in essence, allowed to move objects around in memory without wreaking havoc. Essentially, that’s what allows the SOH to use a compaction design. In the unmanaged memory world, we don’t have that luxury. The pointers are pointing at raw memory addresses. If we were to move an object, all the pointers pointing at that raw address are now invalid, pointing at something else in memory or just plain garbage memory. So, it’s quite understandable why these traditional style heaps don’t employ compaction.
One could argue—compaction beats all. You could argue it’d be better for heaps in the OS to use a compaction design similar to the SOH. However, that argument would be futile, since the unmanaged memory world really doesn’t have that luxury. The SOH is taking full advantage of a benefit it inherits from its place in the managed memory world. However, the LOH is not so lucky. The inherent overhead of compacting very large objects in memory, lead the designers of the LOH to stick with the more traditional heap design for the LOH, even with its inherent fragmentation. That’s why our new technique aims to eliminate using the LOH altogether. We wanted to eliminate utilizing a traditional style heap design entirely. No traditional style heap—no fragmentation—was our thought. Our new technique replaces using the LOH, by retrieving memory directly from the system for large objects and essentially utilizing the SOH to control releasing that memory. Instead of a traditional style heap (LOH) retrieving memory from the system on our behalf as a middle-man, we go directly to the system retrieving our own memory (VirtualAlloc). Thereby, eliminating the heap and its’ intrinsic fragmentation. The middle-man suffers from fragmentation, so we simply remove the middle-man to eliminate the fragmentation. It’s clean and simple.
Skipping the middle-man (LOH) and going directly to the system to retrieve our own memory (VirtualAlloc) may at first glance seem a bit unorthodox and risky. However, after closer review, you’ll notice many of the traditional style heaps internally employ similar functionality, when the size of a large allocation request exceeds a certain threshold. For example, a heap created with HeapCreate, of which there are plenty, will actually bypass the heap and go directly to the system with VirtualAlloc, when an allocation request exceeds 512KB (32-bit) and 1024KB (64-bit), as shown in Figure 9. Therefore, you could potentially make the case that our new technique isn’t merely a risky hack using unproven techniques which are far too dangerous, but on the contrary is simply a logical progression of a rather well-known, proven technique which has been extensively used in heap implementations for quite some time.
Not to Heap - The Argument
It’s understandable why the traditional style heap design was created back in the original days of the computer and generally considered a good idea. Even with its rather well-known fragmentation problem, the need to efficiently hand out small amounts of memory (like four bytes, for example), without wasting an entire page of memory (when resources were so limited), greatly outweighed the concern and inherent risk of fragmentation in the heap. The 32-bit OS, coupled with limited memory on the machine, made utilizing a heap as a middle-man essential. You needed a middle-man to hand out smaller allocations of memory in the most efficient manner possible to stay within these limited constraints. One couldn’t afford to waste memory by using a whole page of memory for only a small allocation of several bytes. Furthermore, the total virtual address space for a process was very limited because of the 32-bit OS. This is what ultimately renders our technique not feasible on a 32-bit OS, due to virtual address space fragmentation (fragmentation of the available address numbers themselves in virtual address space, not fragmentation of the heap memory).
Our technique does in fact release the memory back to the OS (so the memory doesn’t become fragmented), however the available address numbers themselves increase (as the virtual address space becomes fragmented), until in the end, no more address numbers are available to utilize for a new allocation. In essence, our technique eliminates heap memory fragmentation and running out of memory, trading it for virtual address space fragmentation and running out of virtual addresses. We don’t run out of heap memory receiving an out of memory exception—instead we run out of address numbers in virtual address space receiving an allocation failed exception. Not so cool! With the 64-bit OS, we don’t run out of available address numbers for quite some time, since the virtual address space is so large (128TB), as shown in Figure 10. For all practical purposes, the virtual address space fragmentation problem we received in trade is all but eliminated. Thus, in a sense, we’ve now tackled both the heap memory fragmentation problem, along with the virtual address space fragmentation problem. This is the reason our technique is designed only for servers running a 64-bit OS, not a 32-bit OS.
In the modern day, where the 64-bit OS is rather ubiquitous and 100’s of gigabytes of memory in an enterprise level production server is somewhat commonplace; you could argue it’s not only feasible now, but technically possible, to eliminate the use of a middle-man (heap), in order to escape its rather well-known inherent fragmentation problem. However, the consequence of eliminating the use of the middle-man (heap) comes at the cost of utilizing memory inefficiently. If you only need four bytes—you don’t want to waste a whole page of memory! Yikes! That’s one reason heaps are still here to stay. It doesn’t make sense to eliminate them altogether. Nevertheless, the LOH only applies to large objects (85,000 bytes or more), never just several bytes. Several bytes will end up on the SOH. So, one could argue, wasting a portion of only the final page for each very large object in small quantities is far less concerning than wasting a whole page on each small object (several bytes) in massive quantities. This, in essence, only renders the argument compelling if you’re utilizing our new technique to replace a traditional style heap which happens to deal exclusively in very large objects. The LOH appears to fit that bill nicely. Pretty cool!
Fittingly, our technique seeks to eliminate using the LOH altogether by going directly to the VMM of the OS, eliminating the middle-man. Avoid fragmentation—by doing away with the fragmentation causer—in essence. There may still be minor waste on the final page of memory (kind of like internal fragmentation in a heap caused by using a free spot that’s bigger than the object), but in our testing, it was negligible compared to the massive external fragmentation of the LOH. Ironically, the reasons making this argument compelling are the same reasons our technique can only be used for this specific scenario—not as a general replacement for all heaps.
Today, most experts advise to merely upgrade to a 64-bit OS and magically your OOM exception problems will simply vanish. It’s a miracle! You need to be careful you’re not tricked into thinking the problem is completely solved. Sure, the OOM exception problems appear to be solved. However, in reality, you merely traded the OOM exception problems for another more insidious problem—your process using far more memory than in fact it’s truly utilizing. On the surface, this doesn’t appear to be a very serious problem. However, in reality, the OS actually thinks your process is in fact utilizing that much memory, which can quickly become an extremely serious problem. When your process’s memory consumption reaches monumental levels, it can eventually cause the OS to spiral into a catastrophic state, showing your process some real vengeance. Switching to a 64-bit OS really doesn’t solve the problem—it simply masks it. Switching to a 64-bit OS coupled with our new technique can actually solve the problem in some cases. Table 5 below is a summary:
32-bit process
| Problem | Result |
| Heap memory fragmentation (LOH) | OOM exception |
| Virtual address space fragmentation / Running out of virtual addresses | OOM exception |
64-bit process (without technique)
| Problem | Result |
| Heap memory fragmentation (LOH) | no OOM exception anymore—but still fragmented (which is a serious problem since OS thinks process is utilizing far more memory than in fact it’s truly utilizing; leading to excessive memory consumption, excessive paging to disk and eventually resulting in server death) |
| Virtual address space fragmentation / Running out of virtual addresses | not fragmented |
64-bit process (with technique)
| Problem | Result |
| Heap memory fragmentation (LOH) | not fragmented (LOH not used anymore) |
| Virtual address space fragmentation / Running out of virtual addresses | fragmented (however not really a problem anymore since address space is so large and actual physical memory is being released back to OS) |
By and large, it’s almost as though the mere concept of contiguous-ness is what actually causes fragmentation. Virtual address space is contiguous—physical memory (RAM) doesn’t have to be contiguous, due to the mapping of virtual addresses to physical addresses in a virtual memory system, as shown in Figure 14. A heap uses virtual address space, so consequently, it’s also contiguous. Heaps and virtual address space must largely contend with fragmentation, due to their contiguous nature. Essentially, heaps fragment memory—virtual address space fragments virtual addresses. Nowadays, with the 64-bit address space being so large, we don’t need to concern ourselves too much about virtual address space fragmentation. However, we do need to concern ourselves a great deal about memory fragmentation. Memory fragmentation can have severe consequences on your server. Memory fragmentation can lead to your process consuming far more memory than in fact it’s truly utilizing. This can eventually lead to excessive memory consumption, excessive paging to disk and may ultimately result in your server dying a fiery death. Not good!
Figure 14 Simplified overview comparing Virtual Address to Physical Address mapping flow, fragmentation and memory usage for LOH vs. New Technique
Not going to the heap, going directly to the OS with VirtualAlloc, may still cause virtual address fragmentation in some cases. However, with the massive 64-bit virtual address space of 128TB, we don’t have to be too concerned. Then again, on the positive side, going directly to the OS with VirtualAlloc, all but eliminates the heap’s inherent memory fragmentation problem. In a sense, you’re really just trading one problem (heap memory fragmentation) for another problem (running out of virtual addresses); only the later is much less catastrophic and doesn’t really matter a great deal anymore with the advent of 64-bit. The advent of 64-bit is really what made our new technique become compellingly feasible.
Server OS’s prior to Windows Server 2012 R2 (like Windows Server 2008 R2, for example) only supported 8TB (44-bits) of user mode virtual address space for a process, since they didn’t support the CPU instruction CMPXCHG16B. Even though 8TB of user mode virtual address space is extremely large, virtual address space fragmentation could eventually lead to running out of virtual addresses when running over extended periods of time, depending on the memory usage patterns on the server. Windows Server 2012 R2 and above, now support the CMPXCHG16B instruction, which increases the user mode virtual address space to a whopping 128TB (47-bits). For more details, take a look at the following: (https://en.wikipedia.org/wiki/X86-64).
Sure, our technique can suffer from virtual address space fragmentation in some cases, but with this massive 64-bit virtual address space of 128TB, it’s no longer much of a concern. It’ll take quite some time before all the virtual addresses are consumed. This somewhat extinguishes the concern for running out of virtual addresses, now making our technique not only much more viable, but a great deal more compelling as well. Furthermore, since we immediately release the memory back to the OS when our C# object is disposed (so the virtual address space is no longer mapped to physical memory), as far as the OS is concerned, our process is no longer consuming physical memory, regardless of this virtual address space fragmentation, as shown in Table 6 below:
Table 6 Summary
| | Memory Fragmentation | VAS Fragmentation | CommitSize | WorkingSet | PrivateWorking Set |
| Process(with LOH) | High | | high | high | high |
| Process(with technique) | | High | high | | |
With process (with LOH), we’re losing full pages of memory that aren’t being reused because of fragmentation—external fragmentation. With process (with technique), we’re only wasting memory on the last final page of memory when the object isn’t on the exact page boundary—internal fragmentation. For extremely large objects, the significance of internal fragmentation becomes minimal.
What’s a Page Table?
In very simple terms, a Page Table is the data structure used to map virtual memory addresses to physical memory addresses, or more specifically, virtual page numbers to physical page frame numbers, as shown in Figure 15. Each process has a Page Table data structure that resides in the kernel. A process utilizes virtual memory addresses from its virtual address space (VAS) when it allocates its objects. The Page Table simply maps those virtual memory addresses from VAS for those objects to the actual physical memory (RAM) or Page File that backs them, also shown in Figure 15. The whole thing becomes surprisingly simple to visualize and understand when you break it down to its basic building blocks like this.
Figure 15 Simplified example of single level linear Page Table mapping Virtual Address to Physical Address
The Memory Management Unit (MMU) is basically the hardware mechanism that actually does the translation of the virtual addresses (virtual page numbers) to the physical addresses (physical page frame numbers). Every time a virtual address is accessed, it must pass through the MMU to map that virtual address to a physical address. The MMU uses the Page Table to map the virtual pages to physical page frames. In a simple single level linear Page Table there’s one Page Table Entry (PTE) for each page, as shown in Figure 15.
The Translation Lookaside Buffer (TLB) is a hardware cache of recent PTE’s for the MMU that’s extremely efficient. The Page Table isn’t nearly as efficient because it’s in memory, as opposed to hardware. The MMU first looks in the TLB for the PTE, if found (TLB hit), it bypasses looking in the Page Table altogether. If not found (TLB miss), the MMU will resort to the Page Table (Page Table walk) for the PTE, and update the TLB for future lookups.
Each PTE contains a flag (Valid bit) indicating whether the page is currently in RAM, or in the Page File on disk. If the page isn’t in RAM (Valid bit = 0) a "hard page fault" will occur, causing the OS to swap the page frame from the Page File back into RAM, updating the PTE with that new Page Frame Number.
A 32-bit server, with its reasonable size virtual address space, can get away with using a simple single level linear Page Table, like the one shown in Figure 15. However, a modern 64-bit server, with its massive size virtual address space, requires a much more advanced multilevel hierarchical Page Table with four levels. It’d be far too inefficient to use a simple single level linear Page Table for virtual address space that large.
The VirtualAlloc function allocates a range of pages (virtual addresses) in the VAS of the process. Pages are created zero filled (initialized with all zeros on the entire page). Allocating can be accomplished in one individual step, or broken into two separate steps.
VirtualAlloc with MEM_RESERVE, reserves a contiguous range of pages (virtual addresses) in the process’s VAS, by creating a Virtual Address Descriptor (VAD) in the process’s VAD tree. At that point, the pages (virtual addresses) are simply reserved in the process’s VAS and haven’t been mapped to physical storage (RAM or Page File) yet. Thus, they don’t show up in the Working Set, Private Working Set, or Commit Size of your process yet.
VirtualAlloc with MEM_COMMIT, reserves space in physical storage (RAM or Page File) for the reserved pages (virtual addresses), so the OS can guarantee the required memory will be available when it’s actually needed. At this point, it simply reserves the space, but doesn’t actually use any real space yet. The committed pages (virtual addresses) don’t actually consume any physical storage (RAM or Page File) until they’re accessed the first time. Hence, it only shows up in the Commit Size of your process, not in the Work Set or Private Working Set yet. The amount’s added to the system wide "Commit Charge", which must not exceed the "Commit Limit" (the total amount of RAM and Page File in the system), so the OS will be able to honor its commitment to provide that memory at a later time. The amount’s also added to the "Process Page File Quota", which represents the amount your individual process’s adding to the system wide "Commit Charge". However, as an optimization, it holds off on creating the PTE until the committed page is actually accessed the first time in your program, somewhat similar to "lazy-loading". Accessing a committed page of memory the first time, triggers what’s called a "demand-zero page fault". For extremely large allocations, immediately creating a PTE for every page would be a slow, heavy operation. Instead, this "lazy-loading" optimization defers that overhead until it’s actually necessary, even escaping it altogether for pages that are never accessed. What’s really cool is the amount only shows up in the Commit Size of your process, it’s not until the virtual address is actually accessed the first time that it will count in the Working Set or Private Working Set of your process. Pretty handy optimization!
VirtualAlloc with both MEM_RESERVE | MEM_COMMIT simultaneously, does it all in one step. Figure 14 and Figure 15 attempt to assist somewhat in visualizing what VirtualAlloc is doing conceptually.
An important detail to remember; virtual address space (VAS) is contiguous, physical memory (RAM) isn’t contiguous. The requirement to be contiguous, when you stop and think about it, is really what seems to make the occurrence of fragmentation so serious. Fragmentation essentially means, not contiguous. On the reverse side of the coin, when something doesn’t need to be contiguous, the concept of fragmentation becomes somewhat irrelevant.
Heaps generally utilize VirtualAlloc to obtain VAS that’s contiguous, thereby inheriting the problem of fragmentation. Physical memory (RAM), on the other hand, doesn’t have to be contiguous, which makes the problem of fragmentation become somewhat immaterial. It’s almost as if the mere act of swapping pages out of RAM to the Page File and vice versa, operates somewhat like an automatic defragmenter for the RAM, to some extent. Pretty cool!
Future Enhancement
Theoretically, you may be able to add support for ArrayNoLOH<char>, which could possibly be utilized as the internal backing store of the .NET string, thereby keeping large strings off the LOH. This could come in really handy for large JSON strings. The .NET char is 2 bytes for Unicode, so the string only has to become greater than roughly 42,500 characters to end up on the LOH.
For this to work, it would most likely require some modification to the .NET string class. In string.cs line 60 (https://referencesource.microsoft.com/#mscorlib/system/string.cs) there’s a private member variable (m_firstChar) which appears to hold the first char of the char[] backing the string. Much of the code appears to perform operations simply on the address of that first char. If you somehow added the ability to assign the address property of the ArrayNoLOH<char> instance to (m_firstChar), remembering to release it in an implementation of dispose on the string, you just might be successful backing the string with unmanaged memory without the managed string even realizing.
We haven’t attempted this and it’s purely theoretical at this point. It may in fact anger the GC! The GC may not be able to keep the string alive, since it has no knowledge of the unmanaged memory, we aren’t really sure. We leave this experiment as a thought-provoking exercise for the reader.
Further Study
Memory management in a modern OS is an extremely complicated subject, covering a broad range of complicated computer science concepts. A full explanation of all the intricate details encompassing the design of the .NET Garbage Collector and the Virtual Memory Manager for the OS is outside the scope of this article. However, a general understanding of them can go along way when trying to understand the concepts put forth in this article. We tried our best to explain them in an extremely simplified and practical way, so it’s easy to visualize the actual problem and the concepts involved in our simple solution technique.
Ironically, explaining the solution’s actually the easy part—it’s explaining the problem that’s difficult. The solution technique’s simple—it’s the problem that’s complicated. Most of the article’s spent giving you background into the nature of the problem, in order to explain why a solution technique’s even necessary. Nevertheless, we hope it also serves as a simple, clear overview giving you a better understanding of the GC and memory and hopefully sparking some new ideas of your own along the way.
For an extensive detailed overview of the inner-workings of the .NET GC see the Garbage Collection topic under the Memory Management and Garbage Collection in the .NET Framework section in the .NET Framework Development Guide located in the Microsoft Developer Network online documentation (https://msdn.microsoft.com/en-us/library/hh156531(v=vs.110).aspx).
Wrapping Up
In this article (Part 1 and Part 2) we explored a theory; would it be better to not utilize a heap construct when dealing with very large objects in .NET, in order to avoid LOH fragmentation? Better to trade memory fragmentation for address fragmentation, with the massive 64-bit address space of today? Trade LOH fragmentation for VAS fragmentation? To heap or not to heap, that really is the million dollar question…
We outlined a simple coding technique that goes directly to the OS with VirtualAlloc for large objects, avoiding the LOH altogether, somewhat similar to the way traditional unmanaged heaps created with HeapCreate go directly to the OS with VirtualAlloc when an allocation exceeds a certain size. In essence, the technique allows you to house a large object inside a small managed object, so it’s placed on the SOH instead of the LOH, in order to avoid LOH fragmentation. The unmanaged memory backing the large object’s allocated in the constructor and released in the dispose of the small managed object, preventing memory leaks, while still continuing to receive the benefits of garbage collection. The large unmanaged memory is essentially controlled by the SOH. Basically, it’s demonstrating how to utilize large unmanaged memory inside a small managed object, so the memory will be released in gen0 (that’s fast and compacted), instead of going in the LOH. Pretty cool!
This coding technique’s probably not best practices and shouldn’t be utilized in production, unless you’re experiencing a catastrophic server problem. It’s merely a workaround that may provide a practical solution for servers experiencing LOH fragmentation, in some cases; however it’s still interesting to ponder nevertheless.
Since many, if not most, heaps are created with HeapCreate() where allocations greater than 512KB (32-bit) and 1024KB (64-bit) are already in fact bypassing the heap directly to the OS with VirtualAlloc, our technique’s utilization of VirtualAlloc for allocations greater than roughly 83KB really isn’t as unconventional as it first seems.
Even if you don’t utilize our new technique, we still wanted you to have our memory stream class implementing the stream interface with an expandable custom backing store, to utilize as a simple template to modify for your own projects. You can put your own custom backing store by simply replacing the VirtualAlloc code.
We touched on the fact if a developer configures the machine to use Server Garbage Collection in Concurrent mode to reduce freezing of an application caused by garbage collection; it still doesn’t address fragmentation of the LOH.
We also touched on the fact if a developer were to manually compact the LOH from code; the compaction only occurs on the next blocking garbage collection, which means an application may still be subject to pausing and freezing during the garbage collection, while memory of the surviving objects is being moved.
We tried to take this complex subject matter and explain it in the simplest possible way. All in the hopes it may inspire the brave-at-heart to think outside-the-box and come up with some innovative new idea that has the potential to become a true long term solution that solves the problem, instead of merely optimizations and workarounds masquerading as a permanent fix. Regardless, exploring this subject matter is an extremely interesting journey, nonetheless.
As a base starting point, we included a Sample Project implementing code for dealing with several common scenarios that can sometimes lead to excessive fragmentation of the LOH; we leave the rest of the fun for you to experiment going forward…happy coding!

