The purpose of this article is to demonstrate, by example, how to utilize the advanced features of EPPlus and create professional-looking Excels. I will also tackle EPPlus shortcomings, meaning Excel features that EPPlus doesn't implement, and how to overcome them. I will demonstrate all these things by example. The scenario at hand is we take some data from AdventureWorks2014 and make different Excels out of it. Each Excel demonstrates a different feature, or a different aspect, of EPPlus. For this purpose, the article follows the demo closely. Once you downloaded and run the demo, it will create a bunch of Excel files corresponding to the chapters of the article.
Table of Contents
The version of EPPlus that the demo uses is EPPlus 4.1.1. The Excel program that I verified the validity of the files is Excel 2013. There are two points to make here. The first point is that maybe some features, or some techniques shown in the article, might not apply to previous versions of Excel. This means that if you try to open the file with Excel version 2010 or less, it might tell you that the file is corrupt and can't be opened properly. There's also a slight chance that it won't work with future versions of Excel, but that is less likely since Excel has back-compatibility built into it. The second point is that future versions of EPPlus might implement features that are currently not available with EPPlus 4.1.1. The article explains how to circumvent this problem but that might be redundant with future versions EPPlus.
The Excel files, available for download, were not opened by an Excel program. When you run the solution, you will get these same Excel files every time. So, even without the demo, you can test them with your version of Excel program and make sure that they can be opened correctly. If not, the blame is almost surely on Excel and not the demo.
The data is taken from AdventureWorks2014. Don't worry if you don't have a SQL Server running. I added a .csv file with all the data and the demo is configured to read from the .csv file by default. You can change that in the demo very easily.
The data, which we are going to work with, is order details from AdventureWorks2014. This SQL query takes order details for orders that were completed successfully (Sales.SalesOrderHeader.Status = 5) and were ordered by a salesperson, not through the online website (Sales.SalesOrderHeader.OnlineOrderFlag = 0). The order details consist of the salesperson that made the order, the territory of the salesperson, the date of the order, details about the product that was ordered including the product unit price, order discount, and the total that was charged (LineTotal).
select
TerritoryGroup = st.[Group],
TerritoryName = st.Name,
SalesPerson = pp.FirstName + ' ' + pp.LastName,
soh.OrderDate,
ProductCategory = pc.Name,
ProductSubcategory = psc.Name,
Product = p.Name,
sod.OrderQty,
sod.UnitPriceDiscount,
Discount = (sod.OrderQty * sod.UnitPrice * sod.UnitPriceDiscount),
sod.UnitPrice,
sod.LineTotal
from Sales.SalesOrderDetail sod
inner join Sales.SalesOrderHeader soh on sod.SalesOrderID = soh.SalesOrderID
inner join Sales.SalesPerson sp on soh.SalesPersonID = sp.BusinessEntityID
inner join Person.Person pp on sp.BusinessEntityID = pp.BusinessEntityID
inner join Sales.SalesTerritory st on sp.TerritoryID = st.TerritoryID
inner join Production.Product p on sod.ProductID = p.ProductID
inner join Production.ProductSubcategory psc on p.ProductSubcategoryID = psc.ProductSubcategoryID
inner join Production.ProductCategory pc on psc.ProductCategoryID = pc.ProductCategoryID
where soh.OnlineOrderFlag = 0
and soh.Status = 5
The corresponding POCO is DataRow.
public class DataRow
{
public string TerritoryGroup { get; set; }
public string TerritoryName { get; set; }
public string SalesPerson { get; set; }
public DateTime OrderDate { get; set; }
public string ProductCategory { get; set; }
public string ProductSubcategory { get; set; }
public string Product { get; set; }
public short OrderQty { get; set; }
public decimal UnitPriceDiscount { get; set; }
public decimal Discount { get; set; }
public decimal UnitPrice { get; set; }
public decimal LineTotal { get; set; }
public int OrderYear { get { return OrderDate.Year; } }
public int OrderMonth { get { return OrderDate.Month; } }
}
To group, or not to group, that is the question
You can see that the data is selected as raw data or details data. There is no grouping, summation or pivoting done on it. This is important for the latter examples when we're going to create Excel pivot tables. However, if the Excel, that you intend to create, has only static data (static = not Excel pivot table), then you also have the opportunity to perform manipulations on the data in SQL Server and return the results already cooked, instead of doing the same thing on the .NET side (LINQ). If that's the case, then I suggests that you always choose to group and pivot the data in SQL Server because SQL Server is always tenfold faster than .NET in that regard.
AdventureWorks1_SimpleGrouping.xlsx
We start with a simple Excel and do some straightforward grouping on the raw data. We are not going to use any advanced features from EPPlus. This Excel is going to serve as the basis for everything that is going to come next. Each tab sheet is a different territory group (Europe, North America, Pacific) and for every territory group we create a table of order revenues. The rows are group by salesperson, salesperson's territory and order year. The columns are group by order month. We finish by adding a total revenue column and a total revenue row at both ends of the table.
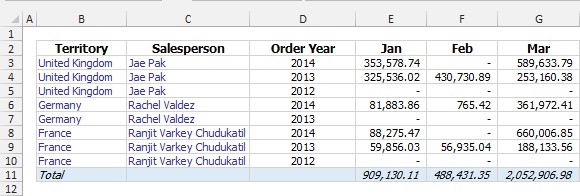
The code in the demo is far more robust than this code snippet. I left all the styling and coloring out from this snippet, but it is all in the demo code. We start by defining the number formatting. Negative numbers are defined by US convention, wrapped in parentheses. The suffix "_)" tells Excel to align all the numbers correctly above one another.
string positiveFormat = "#,##0.00_)";
string negativeFormat = "(#,##0.00)";
string zeroFormat = "-_)";
string numberFormat = positiveFormat + ";" + negativeFormat;
string fullNumberFormat = positiveFormat + ";" + negativeFormat + ";" + zeroFormat;
It is very important that you name the indices. This might seem like a trivial tip but I wouldn't glance over it. It is understandable if you're keeping all the indices in your head while you code on, but things get complicated as you write more robust code and named indices are a life saver in this situation. It is also has the beneficiary of helping when you, or anybody else for that matter, revisit the code months or years later, and all the indices in your mind are long gone.
int startRowIndex = 2;
int territoryNameIndex = 2;
int salesPersonIndex = 3;
int orderYearIndex = 4;
int orderMonthFromIndex = 5;
int orderMonthToIndex = 16;
int totalIndex = 17;
The first grouping is performed on the territory group. For each territory group we create a new worksheet and add it to the workbook.
var ep = new ExcelPackage();
var wb = ep.Workbook;
var territoryGroups = data.GroupBy(d => d.TerritoryGroup).OrderBy(g => g.Key);
foreach (var territoryGroup in territoryGroups)
{
var ws = wb.Worksheets.Add(territoryGroup.Key);
The variable rowIndex holds the current row index and we advance it once we're done working on the current row. The first row is the headers row.
int rowIndex = startRowIndex;
ws.Cells[rowIndex, territoryNameIndex].Value = "Territory";
ws.Cells[rowIndex, salesPersonIndex].Value = "Salesperson";
ws.Cells[rowIndex, orderYearIndex].Value = "Order Year";
ws.Cells[rowIndex, totalIndex].Value = "Total";
CultureInfo enUS = CultureInfo.CreateSpecificCulture("en-US");
for (int month = 1; month <= 12; month++)
{
string value = new DateTime(1900, month, 1).ToString("MMM", enUS);
ws.Cells[rowIndex, month - 1 + orderMonthFromIndex].Value = value;
}
rowIndex++;
The second grouping is performed on salesperson and salesperson's territory.
var salesPersonGroups = territoryGroup
.GroupBy(d => new { d.SalesPerson, d.TerritoryName })
.OrderBy(g => g.Key.SalesPerson);
int fromRowIndex = rowIndex;
foreach (var salesPersonGroup in salesPersonGroups)
{
The third grouping is performed on order year. The years are sorted by descending order because that is the order of their relevance for anyone who is going to read this Excel file.
var orderYearGroups = salesPersonGroup
.GroupBy(g => g.OrderDate.Year)
.OrderByDescending(g => g.Key);
foreach (var orderYearGroup in orderYearGroups)
{
string territoryName = salesPersonGroup.Key.TerritoryName;
ws.Cells[rowIndex, territoryNameIndex].Value = territoryName;
string salesperson = salesPersonGroup.Key.SalesPerson;
ws.Cells[rowIndex, salesPersonIndex].Value = salesperson;
int orderYear = orderYearGroup.Key;
ws.Cells[rowIndex, orderYearIndex].Value = orderYear;
The last grouping is performed on order month. Prior to the grouping, the entire row is set to revenue 0. Remember that some months will not appear in the grouping because they are not present in the raw data in the first place. For those months, the revenue is 0.
ws.Cells[rowIndex, orderMonthFromIndex, rowIndex, orderMonthToIndex].Value = 0;
var orderMonthGroups = orderYearGroup.GroupBy(g => g.OrderDate.Month);
foreach (var orderMonthGroup in orderMonthGroups)
{
decimal total = orderMonthGroup.Sum(d => d.LineTotal);
int orderMonth = orderMonthGroup.Key;
ws.Cells[rowIndex, orderMonth - 1 + orderMonthFromIndex].Value = total;
}
The total column is the summation of revenues over the current row from January to December.
string totalColumnAddress = ExcelCellBase.GetAddress(
rowIndex, orderMonthFromIndex,
rowIndex, orderMonthToIndex
);
ws.Cells[rowIndex, totalIndex].Formula =
string.Format("SUM({0})", totalColumnAddress);
rowIndex++;
}
The number format of all the revenue cells. If the revenue is 0, it will be displayed as "-".
int toRowIndex = rowIndex - 1;
ws.Cells[
fromRowIndex, orderMonthFromIndex,
toRowIndex, totalIndex
].Style.Numberformat.Format = fullNumberFormat;
The last row is the total row. For each column, it is the summation over all the data rows above the total cell. If the total revenue is 0, it will be displayed as 0, not "-".
ws.Cells[rowIndex, territoryNameIndex].Value = "Total";
for (int columnIndex = orderMonthFromIndex; columnIndex <= totalIndex; columnIndex++)
{
string totalMonthAddress = ExcelCellBase.GetAddress(
fromRowIndex, columnIndex,
toRowIndex, columnIndex
);
ws.Cells[rowIndex, columnIndex].Formula =
string.Format("SUM({0})", totalMonthAddress);
}
string totalAddress = ExcelCellBase.GetAddress(
rowIndex, orderMonthFromIndex,
rowIndex, orderMonthToIndex
);
ws.Cells[rowIndex, totalIndex].Formula =
string.Format("SUM({0})", totalAddress);
ws.Cells[
rowIndex, orderMonthFromIndex,
rowIndex, totalIndex
].Style.Numberformat.Format = numberFormat;
}
}
This a little trick that I use to color several tabs by slightly altering the shades from the previous tab. This trick can be useful if you have several batches of tabs that have different business semantics and you would like to distinguish each group by a different predominant color and at the same time give each tab a slightly different color from the other tabs next to it. The whole idea here is to just pick a starting color, the color of the first tab, and then let the other tab colors be determined by the number of tabs in the group.

In the demo, the predominant color is blue and the green will dilute the blue as the green value increases. The starting RGB color is (0, 0, 154). There are three territory groups and their tab colors are Europe (0, 0, 154), North America (0, 85, 187) and Pacific (0, 170, 220).
var territoryGroups = data.GroupBy(d => d.TerritoryGroup).OrderBy(g => g.Key);
int greenStep = 255 / territoryGroups.Count();
int blueStep = (255 - 154) / territoryGroups.Count();
int territoryGroupIndex = 0;
foreach (var territoryGroup in territoryGroups)
{
var ws = wb.Worksheets.Add(territoryGroup.Key);
int green = (territoryGroupIndex * greenStep);
int blue = (territoryGroupIndex * blueStep) + 154;
ws.TabColor = System.Drawing.Color.FromArgb(0, green, blue);
territoryGroupIndex++;
}
AdventureWorks2_SubTotals.xlsx
The next step is to augment the previous Excel with sub totals. We are going to add two kinds of sub total rows. The first would be the total for each salesperson. The second would be for each territory, meaning summation over all the salespeople in each territory.
When it comes to sub totals in Excel, it is preferable to use the SUBTOTAL function rather than the SUM function. SUBTOTAL function ignores nested sub totals or any other aggregated functions. It also ignore cells that are not visible, which is going to come in handy when we add filters later on. The SUBTOTAL function takes two parameters. The first parameter is a code for the calculation method. The second is the calculation range. We need a sum method, which has a code 9, so the function will look like this SUBTOTAL(9, range). This link How to use the SUBTOTAL Function has an overview of the function, a list of all the possible calculation methods and some examples.
Continuing from the previous Excel, we change the code slightly to accommodate a sub total row for each salesperson. Inside the salesperson grouping, we keep track of how many rows we added so far and at the end of the salesperson loop we add a SUBTOTAL function beneath every order month column.
var salesPersonGroups = territoryGroup
.GroupBy(d => new { d.SalesPerson, d.TerritoryName })
.OrderBy(g => g.Key.SalesPerson);
foreach (var salesPersonGroup in salesPersonGroups)
{
int salesPersonFromRowIndex = rowIndex;
var orderYearGroups = salesPersonGroup
.GroupBy(g => g.OrderDate.Year)
.OrderByDescending(g => g.Key);
foreach (var orderYearGroup in orderYearGroups)
{
rowIndex++;
}
int salesPersonToRowIndex = rowIndex - 1;
ws.Cells[rowIndex, territoryNameIndex].Value = salesPersonGroup.Key.TerritoryName;
ws.Cells[rowIndex, salesPersonIndex].Value = salesPersonGroup.Key.SalesPerson;
ws.Cells[rowIndex, orderYearIndex].Value = "S. Total";
for (int columnIndex = orderMonthFromIndex; columnIndex <= orderMonthToIndex; columnIndex++)
{
using (var cells = ws.Cells[rowIndex, columnIndex])
{
string subtotalAddress = ExcelCellBase.GetAddress(
salesPersonFromRowIndex, columnIndex,
salesPersonToRowIndex, columnIndex
);
cells.Formula = string.Format("SUBTOTAL(9,{0})", subtotalAddress);
cells.Style.Numberformat.Format = numberFormat;
}
}
rowIndex++;
}
Now we add sub total rows for each territory. A territory may have several salespeople. For this task we are going to use the SUMIFS function. SUMIFS function perform summation based on criteria. The function syntax is SUMIFS(summation range, 1st criteria range, 1st criteria, [2nd criteria range, 2nd criteria, ...]) An overview of the function in this link How to use the SUMIFS Function.
I'm going to spare you the C# code, it is technically similar in nature to the code above. But lets look at this image and try to understand how this function works for us. The cell in question is F15. For this cell we need to sum all the revenues in February (column F) that are (1) associated with Germany territory (column B) and (2) are not sub totals. The SUMIFS first parameter is the summation range F3:F13. This range includes revenues from other territories than Germany and salesperson sub totals. The next two parameters are the first criteria and its range. The range B3:B13 is the territory range and the criteria is "Germany". This tells the function to take into account only rows that have the value "Germany" for all the cells in the range B3:B13. The last parameters are the second criteria and its range. The range D3:D13 is the order years and "S. Total" header for sub totals. The criteria is "<>S. Total". This tells the function to take into account only rows that don't have the value "S. Total", effectively only picking the actual order years. The final formula for cell F15 is SUMIFS(F3:F13,B3:B13,"Germany",D3:D13,"<>S. Total").
The last thing that we need to do is change the function of the total row from SUM to SUBTOTAL. As I mentioned before, SUBTOTAL ignores other aggregated functions and we need to ignore the salesperson sub totals for the final result. We could have gone another way here and SUM the total of the territories sub totals but I prefer to do the summation over the revenue source cells.
AdventureWorks3_AutoFilter_FreezePane.xlsx
Now that we are done with the content portion of the Excel, we turn our attention to its appearance. The Excel needs to be readable, so we are going to merge cells with repeated values. That way, the Excel won't be cluttered with details and it will be easy on the eye. Then, we'll add auto filter, so anyone reading this Excel can filter rows by values as they please. Finally, we'll add freeze pane, to lock in the header row and the salesperson's columns.
There are duplicate values under the salesperson and territory columns because a salesperson has several rows for order years and sub total. The code is not complicated. We just need to find the range of rows for each salesperson and then merge them for the salesperson and territory columns. EPPlus makes it easy to merge cells. Once you selected the appropriate cells ExcelRange cells = ws.Cells[...], you can enable the Merge property cells.Merge = true.
var salesPersonGroups = territoryGroup
.GroupBy(d => new { d.SalesPerson, d.TerritoryName })
.OrderBy(g => g.Key.SalesPerson);
foreach (var salesPersonGroup in salesPersonGroups)
{
int salesPersonFromRowIndex = rowIndex;
var orderYearGroups = salesPersonGroup
.GroupBy(g => g.OrderDate.Year)
.OrderByDescending(g => g.Key);
foreach (var orderYearGroup in orderYearGroups)
{
rowIndex++;
}
int salesPersonToRowIndex = rowIndex - 1;
int subTotalRowIndex = rowIndex;
using (var cells = ws.Cells[
salesPersonFromRowIndex, territoryNameIndex,
subTotalRowIndex, territoryNameIndex])
{
cells.Merge = true;
cells.Style.VerticalAlignment = ExcelVerticalAlignment.Center;
}
using (var cells = ws.Cells[
salesPersonFromRowIndex, salesPersonIndex,
subTotalRowIndex, salesPersonIndex])
{
cells.Merge = true;
cells.Style.VerticalAlignment = ExcelVerticalAlignment.Center;
}
rowIndex++;
}
To enable auto filter, we need to select the whole table from the top-left cell to the bottom-right cell. Then enable the AutoFilter property on the selected cells.
int startRowIndex = 2;
int territoryNameIndex = 2;
int totalIndex = 17;
int toRowIndex = rowIndex;
using (ExcelRange autoFilterCells = ws.Cells[
startRowIndex, territoryNameIndex,
toRowIndex, totalIndex])
{
autoFilterCells.AutoFilter = true;
}
We would like to freeze the header row and the first three columns territory, salesperson and order year. We need to choose a single cell, of which all the columns to the left of that cell and all the rows above that cell will be frozen. If you look again at the image above, the cell that we want is E3, which is the January revenue of salesperson Jae Pak for 2014.
int startRowIndex = 2;
int orderMonthFromIndex = 5;
ws.View.FreezePanes(startRowIndex + 1, orderMonthFromIndex);
AdventureWorks4_PreselectFilters.xlsx
Our target audience is most likely financial personal, and they would be focused, more likely than not, on the revenues of the current year (2014) and the previous year (2013). They probably don't need to see the revenues of 2012 and earlier. At the same time, we don't want to exclude that information from the Excel on the off chance they might need it here and there. For this sake, we want to preselect the values of the order year filter. The values that we would like to exclude are the years 2012 and earlier. If anybody, who's reading this Excel, do need these revenue figures, they can open the filter and select what they want.
Among many other Excel features that are not implemented, EPPlus doesn't provide any method to preselect filters. However, when EPPlus closes a door, it will open a window. EPPlus provides an access to the underlying Open XML and gives you, the programmer, the opportunity to edit the XML and create your own implementation in places where EPPlus does not. There is an argument to be made that some of the more popular and frequently used Excel features should be implemented but that is really up to the developers of EPPlus.
There are many instances in this article that we are going to reach in and write XML directly. Since this is the first time, I'm going to go into more details how to do that and some strategies to approach such task. The assumption is that you don't know Open XML syntax. Well, I don't know either, at least not off the cuff. But as an experienced programmer, there are some expectations that you can find your way in a MSDN page that you never encountered before, and have some good sensibilities to understand new programming stuff.
The hard part is to understand what the XML should look like. Once you've pinned down the XML snippet, writing it to EPPlus is very much schematic code. To get the XML, we have two tools under our belt, the first is MSDN and the second is your favored file compression program (WinZip, WinRAR, 7-Zip). MSDN is your first go to tool, it holds detailed documentation about Excel Open XML, all the internal hierarchy and some examples for the more important and prominent XML classes. If you are looking for a specific MSDN documentation and don't find it, I suggest that you start from Worksheet class and go deeper down the XML classes from there. Also, in case you need it, every MSDN page lists all the XML classes on the left sidebar.
Lets remind ourselves for a minute what is a .xlsx file. Excel file is a bunch of XML text files (The "x" in .xlsx stands for XML), all wrapped up in a compressed ZIP file and the file extension is renamed from .zip to .xlsx. You can take an Excel file, rename the extension to .zip, unzip it and read the files in a text editor. Sometimes diving into the pages of MSDN might be cumbersome when you quickly need to know how Excel implements a certain feature. I want to lay out for you a strategy how to achieve that.
Start by creating an Excel file without the feature that you want. If you generated that file in EPPlus, then open the file in Excel program, save it again and close Excel. EPPLus generates only the necessary minimum of XML for the Excel program to read it. Excel program will save a more complete XML and whatever else it deems necessary. Once you've done that, make a duplicate of the file in File Explorer. Open the duplicate file in Excel, add the feature that you need, save and close. Now you have two Excel files, identical except for one feature, and we want to know how that difference manifest itself as XML. Rename the two files from .xlsx to .zip and unzip them both to separate folders. The file and folder names are pretty self explanatory, the worksheet files are located under xl\worksheets, the chart files are located under xl\charts and the pivot table files are located under xl\pivotTables and xl\pivotCache. You need to locate the one file that defines your feature. Isolate that file and the other file with same exact name, from the original Excel, without the feature. If you open any of them, you'll see that the XML is flatten to one or two lines. You need to pretty-print the XML - new lines and indentations - before you continue. I usually use one of two editors for that. First editor, open the XML file in Visual Studio and from the toolbar go to Edit -> Advanced -> Format Document (Ctrl+E, D). The second editor is Notepad++. You need to install XML Tools plugin beforehand and from the toolbar go to Plugins -> XML Tools -> Pretty print (XML only - with line breaks). Another option is to pretty-print all the XML files through code. Look for this discussion and code example in the Odds & Ends chapter at the end of the article. Once you are finished with all these preparations, it's time to delve into the XML. By comparing the two XML files, you can find out how the feature, that was created with Excel program, is implemented as Open XML. One file will be missing a chunk of XML and the other won't. That XML snippet is what you're looking for. I think the best recourse is to use a file comparison program (WinMerge, Beyond Compare) that will highlight the relevant XML.
Now that we are done with the preliminaries let's get down to brass tacks. We know that auto filter is defined in the worksheet, so we start with the MSDN page Worksheet class and look for auto filter. In the child elements table we find autoFilter (AutoFilter Settings). Once we get into writing this XML, you'll find out that EPPlus already created the autoFilter XML node when we enabled AutoFilter = true.
From there we go to the MSDN page AutoFilter class. In this page, we take a look in the child elements table and see if there's anything interesting. There is filterColumn (AutoFilter Column), which from its description, i. e. AutoFilter Column, looks just like the thing that we need. Also, at the top of the page, in the one-line description of the class, the description notes the qualified name of this element x:autoFilter. The qualified name includes the namespace (x) and we are going to use that later on.
We move on to MSDN page FilterColumn class. The qualified name is x:filterColumn. There are several interesting child elements that catch the eye. The first is filters (Filter Criteria) and the second is customFilters (Custom Filters). The third is dynamicFilter (Dynamic Filter). The question here is which one to choose. Well, the one that we need is filters (Filter Criteria). The way to know that is to dig into each element on MSDN, or take a look at how Excel implements it. Remember, you can create your own Excel file, change the extension to zip, unzip the content and start reading the XML files inside.
Before we move on to the next element, we need to look at the attributes of FilterColumn class. The attribute colId tells what column is the auto filter. From its description, the value is zero-based and, very important, the counting starts from the start of the auto filter, not from the start of the worksheet. The order year filter is under column D in the worksheet but it is also the third column from start of the auto filter. The first column of the auto filter is column B in the worksheet. The third column, expressed as a zero-based index, is colId="2".
Out partial XML snippet looks like this. It's not much but we are on our way.
<x:autoFilter>
<x:filterColumn colId="2">
</x:filterColumn>
</x:autoFilter>
We move on to MSDN page Filters class. The qualified name is x:filters. This element is just a container for the individual filters but it does have one attribute that we need. The blank attribute indicates whether to enable (Blanks) or not.
If you take another look at the image above, you can see that the blank cells under order year filter belong to the territory sub total rows and the final total row. We want to keep showing these rows even while filtering. That means we need to enable (Blanks). So, the partial XML now looks like this.
<x:autoFilter>
<x:filterColumn colId="2">
<x:filters blank="true">
</x:filters>
</x:filterColumn>
</x:autoFilter>
We end with MSDN page Filter class. The qualified name is x:filter. This element defines each individual filter. The value of the filter is set in the val attribute.
We decided to show only the current (2014) and previous (2013) order years and the sub total rows. So, our filter values are "2014", "2013" and "S. Total". And now the final XML is this.
<x:autoFilter>
<x:filterColumn colId="2">
<x:filters blank="true">
<x:filter val="2014" />
<x:filter val="2013" />
<x:filter val="S. Total" />
</x:filters>
</x:filterColumn>
</x:autoFilter>
Before we start writing the XML that we came up with, I want to show you two extension methods. As their names suggest, AppendElement and AppendAttribute create an XML node or an XML attribute and append it to the parent XML node that they operate on. Since we are going to use these operations repetitively, it was best to encapsulate both of them in extension methods.
namespace System.Xml
{
public static partial class XmlExtensions
{
public static XmlElement AppendElement(this XmlNode parent, string namespace, string name)
{
var elm = parent.OwnerDocument.CreateElement(name, namespace);
parent.AppendChild(elm);
return elm;
}
public static XmlAttribute AppendAttribute(this XmlNode parent, string name, string value)
{
var att = parent.OwnerDocument.CreateAttribute(name);
att.Value = value;
parent.Attributes.Append(att);
return att;
}
}
}
We start by setting some predefined variables. The variable rowIndex was defined previously when we built the entire table and, at this point, is holding the index of the last row of the table. Variable filterColumnIndex is the index of the filter that we want to operate on, in this case the order year filter. Variable filterValues lists the selected filter values. As discussed before, when we built the XML, we need "2014", "2013" and "S. Total". The boolean variable blanks tells whether (Blanks) is selected or not.
int startRowIndex = 2;
int territoryNameIndex = 2;
int orderYearIndex = 4;
int totalIndex = 17;
int toRowIndex = rowIndex;
int filterColumnIndex = orderYearIndex;
string[] filterValues = new string[] { "2014", "2013", "S. Total" };
bool blanks = true;
Select the entire table and enable auto filter.
using (ExcelRange autoFilterCells = ws.Cells[
startRowIndex, territoryNameIndex,
toRowIndex, totalIndex])
{
autoFilterCells.AutoFilter = true;
EPPlus ExcelWorksheet class has a WorksheetXml property. This property is the gateway to the inner Open XML of the worksheet. This XML describes the worksheet and, among other things, defines the worksheet's auto filter and how it operates.
XmlDocument xdoc = autoFilterCells.Worksheet.WorksheetXml;
When we built the XML, we saw that the XML elements had namespace prefix "x". The namespace was part of the XML element qualified name. We need to register that namespace. Most times you don't have to write the namespace URI literal string, it is already provided by XmlDocument.DocumentElement.NamespaceURI. If the namespace is not present with the namespace manager XmlNamespaceManager, you have to register it with the namespace prefix. For this case, we register the prefix "x" with namespace "http://schemas.openxmlformats.org/spreadsheetml/2006/main".
var nsm = new System.Xml.XmlNamespaceManager(xdoc.NameTable);
var schemaMain = xdoc.DocumentElement.NamespaceURI;
if (nsm.HasNamespace("x") == false)
nsm.AddNamespace("x", schemaMain);
When we enabled auto filter before, EPPlus created the x:autoFilter XML node. This is the XML node that we need to edit so we find it with XPath. The XPath string is short and simple "/x:worksheet/x:autoFilter".
var autoFilter = xdoc.SelectSingleNode("/x:worksheet/x:autoFilter", nsm);
We add x:filterColumn node. As discussed before, the colId attribute is calculated from the start of the auto filter table, not from A column.
var filterColumn = autoFilter.AppendElement(schemaMain, "x:filterColumn");
int colId = filterColumnIndex - autoFilterCells.Start.Column;
filterColumn.AppendAttribute("colId", colId.ToString());
Next, we add x:filters node and enable the blank attribute.
var filters = filterColumn.AppendElement(schemaMain, "x:filters");
if (blanks)
filters.AppendAttribute("blank", "true");
Finally, we add the individual x:filter nodes.
foreach (var filterValue in filterValues)
{
var filter = filters.AppendElement(schemaMain, "x:filter");
filter.AppendAttribute("val", filterValue);
}
So far we only preselected the filters but didn't hide the rows that need to be hidden. We have to iterate across all the rows that do not match any of the filters and manually hide them ExcelWorksheet.Row(rowIndex).Hidden = true.
All the order year cells under column D, excluding the header cell at D2, and their cell values.
var filterCells = ws.Cells[
autoFilterCells.Start.Row + 1, filterColumnIndex,
autoFilterCells.End.Row, filterColumnIndex
];
var cellValues = filterCells.Select(cell => new
{
Value = (cell.Value ?? string.Empty).ToString(),
cell.Start.Row
});
Determine for each cell if its value is not one of the possible filters. If it is not, that cell's row should be hidden.
var hiddenRows = cellValues
.Where(c => filterValues.Contains(c.Value) == false)
.Select(c => c.Row);
If we include (Blanks) filter, we have to remove all the rows with empty cell values from our list of hidden rows.
if (blanks)
{
hiddenRows = hiddenRows
.Except(cellValues.Where(c => string.IsNullOrEmpty(c.Value))
.Select(c => c.Row));
}
Due to merge cells, we have to iterate from the bottom row to the top row. If we hide the first row of a merged cell, it will hide all the rows that are included in that cell.
hiddenRows = hiddenRows.OrderByDescending(r => r);
Hide the rows that do not match any filter.
foreach (var row in hiddenRows)
ws.Row(row).Hidden = true;
}
That's it. Here's the complete code.
int startRowIndex = 2;
int territoryNameIndex = 2;
int orderYearIndex = 4;
int totalIndex = 17;
int toRowIndex = rowIndex;
int filterColumnIndex = orderYearIndex;
string[] filterValues = new string[] { "2014", "2013", "S. Total" };
bool blanks = true;
using (ExcelRange autoFilterCells = ws.Cells[
startRowIndex, territoryNameIndex,
toRowIndex, totalIndex])
{
autoFilterCells.AutoFilter = true;
XmlDocument xdoc = autoFilterCells.Worksheet.WorksheetXml;
var nsm = new System.Xml.XmlNamespaceManager(xdoc.NameTable);
var schemaMain = xdoc.DocumentElement.NamespaceURI;
if (nsm.HasNamespace("x") == false)
nsm.AddNamespace("x", schemaMain);
var autoFilter = xdoc.SelectSingleNode("/x:worksheet/x:autoFilter", nsm);
var filterColumn = autoFilter.AppendElement(schemaMain, "x:filterColumn");
int colId = filterColumnIndex - autoFilterCells.Start.Column;
filterColumn.AppendAttribute("colId", colId.ToString());
var filters = filterColumn.AppendElement(schemaMain, "x:filters");
if (blanks)
filters.AppendAttribute("blank", "true");
foreach (var filterValue in filterValues)
{
var filter = filters.AppendElement(schemaMain, "x:filter");
filter.AppendAttribute("val", filterValue);
}
var filterCells = ws.Cells[
autoFilterCells.Start.Row + 1, filterColumnIndex,
autoFilterCells.End.Row, filterColumnIndex
];
var cellValues = filterCells.Select(cell => new
{
Value = (cell.Value ?? string.Empty).ToString(),
cell.Start.Row
});
var hiddenRows = cellValues
.Where(c => filterValues.Contains(c.Value) == false)
.Select(c => c.Row);
if (blanks)
{
hiddenRows = hiddenRows
.Except(cellValues.Where(c => string.IsNullOrEmpty(c.Value))
.Select(c => c.Row));
}
hiddenRows = hiddenRows.OrderByDescending(r => r);
foreach (var row in hiddenRows)
ws.Row(row).Hidden = true;
}
Previously, we saw that, before writing XML to EPPlus, we needed to register a namespace prefix. You may encounter a situation which you may not be able to utilize XmlDocument.DocumentElement.NamespaceURI and you are going to need to figure out what namespace URI goes with what namespace prefix. There is no easy answer except to search for it on the web or go through the whole process of finding out how Excel does it. However, I do want to list here three namespaces that we are going to use in this article.
The default namespace of Excel is "http://schemas.openxmlformats.org/spreadsheetml/2006/main" and the prefix is "x". We already encountered that. Namespace for drawing - color, transparency, size, distance, effect, all that stuff - is "http://schemas.openxmlformats.org/drawingml/2006/main" and its prefix is "a". Namespace for chart is "http://schemas.openxmlformats.org/drawingml/2006/chart" and its prefix is "c".
string schemaMain = "http://schemas.openxmlformats.org/spreadsheetml/2006/main";
string schemaDrawings = "http://schemas.openxmlformats.org/drawingml/2006/main";
string schemaChart = "http://schemas.openxmlformats.org/drawingml/2006/chart";
AdventureWorks5_ColumnClusteredChart.xlsx
No professional excel is complete without a chart or two. In this chapter and the next one we are going to add a column chart and a pie chart. With your own work, you may not need these exact type of charts. However, the chart modifications and the principle work that we are going to do is just the same for all charts. EPPlus has quite extensive abilities when it comes to charts but it doesn't implement everything. The best approach is to set the chart properties, through EPPlus, as much as you can and then make modifications through Open XML.
For every worksheet (territory group), we would like to add a column clustered chart to compare the revenues between territories during time. The bars are the territories in the territory group, the X axis is the months and the Y axis is the revenues. For each territory group we create a new worksheet and start to build the table. The main focus will be when we reach the territories total rows.
int startRowIndex = 2;
int orderMonthFromIndex = 5;
int orderMonthToIndex = 16;
var territoryGroups = data.GroupBy(d => d.TerritoryGroup).OrderBy(g => g.Key);
foreach (var territoryGroup in territoryGroups)
{
var ws = wb.Worksheets.Add(territoryGroup.Key);
int rowIndex = startRowIndex;
Add the chart to the worksheet with ExcelWorksheet.Drawings.AddChart(). The return type of this method is the base class of all charts ExcelChart, but every type of chart has its own special properties and they are implemented within their own types - again, all inherit from ExcelChart - so it is important that you cast it down the inheritance tree. In this case we create eChartType.ColumnClustered chart type and cast it to ExcelBarChart. The interesting property of this type is ExcelBarChart.GapWidth which determines the size of the gap between two adjacent bars.
The code below creates the chart and sets its appearance. It is pretty straightforward but I would like to focus on the display unit of the Y axis. If we don't set the display unit, Excel will set the Y values at steps of 200,000. So, the values will be 0; 200,000; 400,00; ... 1,800,000. It doesn't look appealing. By setting the display unit to a 1000, Excel will divide each Y value by 1000, thus removing the last three zeroes of each value. By adding the letter "K" to the Y value, we give out an indication that the Y values are in fact multiples of 1000.
string chartTitle = territoryGroup.Key;
ExcelBarChart chart = ws.Drawings.AddChart(
"crt" + chartTitle.Replace(" ", string.Empty),
eChartType.ColumnClustered
) as ExcelBarChart;
chart.SetSize(1100, 500);
chart.Title.Text = chartTitle;
chart.Title.Font.Size = 18;
chart.Title.Font.Bold = true;
chart.Legend.Position = eLegendPosition.Bottom;
chart.YAxis.Font.Size = 9;
chart.YAxis.Border.Fill.Style = eFillStyle.NoFill;
chart.YAxis.DisplayUnit = 1000;
chart.YAxis.Format = "#,##0 K" + ";" + "(#,##0 K)";
chart.XAxis.MajorTickMark = eAxisTickMark.None;
chart.XAxis.MinorTickMark = eAxisTickMark.None;
chart.YAxis.MajorTickMark = eAxisTickMark.None;
chart.YAxis.MinorTickMark = eAxisTickMark.None;
For every territory total row, we add it to the chart as a chart series. A series is comprised of X & Y axis ranges. In this case, the X axis is the months row (Jan, Feb, Mar, ...) and the Y axis is the total revenues of the territory.
var territoryNameGroups = territoryGroup.GroupBy(d => d.TerritoryName).OrderBy(g => g.Key);
foreach (var territoryNameGroup in territoryNameGroups)
{
string serieHeader = territoryNameGroup.Key;
string serieAddress = ExcelCellBase.GetFullAddress(
ws.Name,
ExcelCellBase.GetAddress(
rowIndex, orderMonthFromIndex,
rowIndex, orderMonthToIndex
)
);
string xSerieAddress = ExcelCellBase.GetFullAddress(
ws.Name,
ExcelCellBase.GetAddress(
startRowIndex, orderMonthFromIndex,
startRowIndex, orderMonthToIndex
)
);
chart.Series.Add(serieAddress, xSerieAddress).Header = serieHeader;
rowIndex++;
}
Set the position of the chart below the table. This is only possible after the table is completely built and we know what is the last row of the table.
int toRowIndex = rowIndex - 1;
int chartRow = toRowIndex + 3;
int chartRowOffsetPixels = 0;
int chartColumn = orderMonthFromIndex - 1;
int chartColumnOffsetPixels = 20;
chart.SetPosition(chartRow, chartRowOffsetPixels, chartColumn, chartColumnOffsetPixels);
}
The chart looks like this.
EPPlus doesn't provide any interface to enable a chart data table so we are going to enable it through Open XML. The entry point for the chart Open XML, regardless of the type of chart, is ExcelChart.ChartXml. The namespace for chart XML objects is "http://schemas.openxmlformats.org/drawingml/2006/chart" and its prefix is "c". The XML hierarchy goes from ChartSpace class at the root, then Chart class, then PlotArea class. There are all kinds of properties under ChartSpace class and Chart class but we won't need them for this article, so the XPath will go directly to c:plotArea like this "/c:chartSpace/c:chart/c:plotArea".
The XML node that governs the data table is DataTable class, its qualified name is c:dTable. The child node that determines whether to show the data table keys or not - in our case the territory names - is ShowKeys class, its qualified name is c:showKeys. This XML node has a val attribute with possible values of 0 to hide and 1 to show the keys. Here's the XML.
<c:dTable>
<c:showKeys val="1">
</c:showKeys>
</c:dTable>
And the C# code. The method's chart argument is of type ExcelChart, that is the base class for all chart types, meaning, this code is not limited to any specific type of chart.
EnableChartDataTable(chart, true);
public void EnableChartDataTable(ExcelChart chart, bool showLegendKeys)
{
var xdoc = chart.ChartXml;
var nsm = new System.Xml.XmlNamespaceManager(xdoc.NameTable);
var schemaChart = xdoc.DocumentElement.NamespaceURI;
if (nsm.HasNamespace("c") == false)
nsm.AddNamespace("c", schemaChart);
var plotArea = xdoc.SelectSingleNode("/c:chartSpace/c:chart/c:plotArea", nsm);
var dTable = plotArea.AppendElement(schemaChart, "c:dTable");
var showKeys = dTable.AppendElement(schemaChart, "c:showKeys");
showKeys.AppendAttribute("val", (showLegendKeys ? "1" : "0"));
}
This is the chart with the data table.
AdventureWorks6_PieExploded3DChart.xlsx
This 3D pie chart shows what percentage of the total revenues each territory constitutes. As we did with the previous chart, we are going to do as much as we can with EPPlus and then embellish it, using Open XML, by adding some shadow to it, make it a metal material and make its bevels (edges) rounded. That way the chart won't look dull.
The sum revenues are located in the total column (the last column) of the territories total rows. Because we only need just one data serie for this chart, we will register the starting row index (territoryNameFromRowIndex) and the ending row index (territoryNameToRowIndex) of the territories total rows before and after they are built.
int startRowIndex = 2;
int territoryNameIndex = 2;
int orderMonthFromIndex = 5;
int totalIndex = 17;
var territoryGroups = data.GroupBy(d => d.TerritoryGroup).OrderBy(g => g.Key);
foreach (var territoryGroup in territoryGroups)
{
var ws = wb.Worksheets.Add(territoryGroup.Key);
int rowIndex = startRowIndex;
var territoryNameGroups = territoryGroup.GroupBy(d => d.TerritoryName).OrderBy(g => g.Key);
int territoryNameFromRowIndex = rowIndex;
foreach (var territoryNameGroup in territoryNameGroups)
{
rowIndex++;
}
int toRowIndex = rowIndex - 1;
int territoryNameToRowIndex = rowIndex - 1;
Now we add the chart and set its appearance.
ExcelPieChart chart = ws.Drawings.AddChart(
"crtRevenues",
eChartType.PieExploded3D
) as ExcelPieChart;
chart.SetSize(700, 500);
chart.Title.Text = "Revenues";
chart.Title.Font.Size = 18;
chart.Title.Font.Bold = true;
chart.Legend.Remove();
As mention before, this chart has only one data serie, the total revenues of the territories. The interesting part is the ability to change the appearance of the serie itself. The returned instance of ExcelPieChartSerie lets you to change the appearance of the data labels (content, position) and to change the distance between the pies by setting the data member Explosion to a specific percentage.
string serieAddress = ExcelCellBase.GetFullAddress(
ws.Name,
ExcelCellBase.GetAddress(
territoryNameFromRowIndex, totalIndex,
territoryNameToRowIndex, totalIndex
)
);
string xSerieAddress = ExcelCellBase.GetFullAddress(
ws.Name,
ExcelCellBase.GetAddress(
territoryNameFromRowIndex, territoryNameIndex,
territoryNameToRowIndex, territoryNameIndex
)
);
ExcelPieChartSerie pieChartSerie =
chart.Series.Add(serieAddress, xSerieAddress) as ExcelPieChartSerie;
pieChartSerie.DataLabel.ShowCategory = true;
pieChartSerie.DataLabel.ShowPercent = true;
pieChartSerie.DataLabel.ShowLeaderLines = true;
pieChartSerie.DataLabel.Position = eLabelPosition.OutEnd;
pieChartSerie.Explosion = 10;
Finally, we set the position of the chart beneath the previous Column Clustered chart.
int chartRow = toRowIndex + 30;
int chartRowOffsetPixels = 0;
int chartColumn = orderMonthFromIndex + 1;
int chartColumnOffsetPixels = 30;
chart.SetPosition(chartRow, chartRowOffsetPixels, chartColumn, chartColumnOffsetPixels);
}
This is how the chart looks like so far.
The key measurement unit of Open XML (specifically DrawingML) is English Metric Unit or EMU for short. EMU is defined as 1/360000 cm. So, 1 cm is equals to 360000 EMUs. There are some very insightful explanations why this unit was chosen in this article Why EMUs? and this Wikipedia entry DrawingML - Office Open XML file formats. I'll try to give the bullet points. EMU is very small compare to real life measurement units (cm, inch), thus allow an integer arithmetic (avoids fractions). It is divisible by multiple of divisors 2, 3, 4, 5, 6, 8, 9, 12, 18, 24, 32, 36, 72, 96, so there are a lot of conversion possibilities from various measurement units that are not cm and inch. Any fractions, caused when converting from one measurement unit to EMUs, are small enough to be redundant.
The bottom line for us is this code:
int EMU_PER_CM = 360000;
int EMU_PER_INCH = 914400;
int EMU_PER_PIXEL = 9525;
int EMU_PER_POINT = 12700;
We are going to use these constants to convert various values, given to us by points or inches, to EMU values. This is the mathematical explanation how these values came about.
cm:
1 EMU = 1/360000 cm (definition) ⇒
1 cm = 360000 EMUs
inch:
1 inch = 2.54 cm = 2.54 * 360000 EMUs = 914400 EMUs
A modern screen monitor is set to a default display of 96 ppi. That is also equals to 72 dpi. There is a nice explanation and a bit of history why it is like that in this Wikipedia entry Dots per inch.
pixel:
96 ppi (pixels per inch) ⇒
96 pixels = 1 inch = 914400 EMUs ⇒
1 pixel = 914400 / 96 EMUs = 9525 EMUs
point:
72 dpi (dots per inch) ⇒
72 points = 1 inch = 914400 EMUs ⇒
1 point = 914400 / 72 EMUs = 12700 EMUs
When you are prompted to enter an angle or a percentage in Excel program, you will usually enter a whole number in the text box. But these values are expressed differently in Open XML. One of the key goals, for the people who designed Open XML, is to express numeric values, in the XML, as integers and not as fractions. How can that be achieved for angles? Surely the user can enter any number between 0 degrees and 360 degrees with any accuracy (read: fraction) that he wants. The solution to this problem is to limit the allowed precision of an angle. In the next section, we'll see that the angle precision is measured in 60000th of a degree (1/60000 degree). This is a trade-off, an angle cannot be expressed with a precision less than 1/60000 degree, however the angle can be expressed as an integer number by multiplying it with 60000. The product of the multiplication expresses how many 1/60000 degrees there are in the given angle. Let's look at some examples.
1/60000°: 1/60000 = (1/60000 * 60000) * 1/60000 = 1 * 1/60000 ⇒ XML: 1
1°: 1 = (1 * 60000) * 1/60000 = 60000 * 1/60000 ⇒ XML: 60000
5.5°: 5.5 = (5.5 * 60000) * 1/60000 = 330000 * 1/60000 ⇒ XML: 330000
360°: 360 = (360 * 60000) * 1/60000 = 21600000 * 1/60000 ⇒ XML: 21600000
Remember that you can't express an angle that is not divisible by 1/60000°.
(1 + 1/80000)°: 1.0000125 = (1.0000125 * 60000) * 1/60000 = 60000.75 * 1/60000
and 60000.75 is not divisible by 60000 and it is not an integer.
The same goes for percentage. The percentage precision is measured in 1000th of a percent (1/1000%)
1/1000%: 1/1000 = (1/1000 * 1000) * 1/1000 = 1 * 1/1000 ⇒ XML: 1
1%: 1 = (1 * 1000) * 1/1000 = 1000 * 1/1000 ⇒ XML: 1000
5.5%: 5.5 = (5.5 * 1000) * 1/1000 = 5500 * 1/1000 ⇒ XML: 5500
100%: 100 = (100 * 1000) * 1/1000 = 100000 * 1/1000 ⇒ XML: 100000
It is important to note that these are not universal precisions across Open XML. For every element, you'll need to consult the documentation to find out what the precision of the element type. In the next chapter, when we add a shadow to the chart, we are going to use a percentage element of type ST_PERCENTAGE and an angle of type ST_POSITIVE_FIXED_ANGLE. The prefix "ST" means "simple type".
int ST_PERCENTAGE = 1000;
int ST_POSITIVE_FIXED_ANGLE = 60000;
Next, we add shadow beneath the chart. I think it gives the chart some extra depth on top of the 3D pies. Before we even start to code, we need to pin down the actual values of all the shadow parameters. The best place to do that is of course Excel program. Open the file that you generated so far and edit the serie shadow. Make sure to take note of all the parameters and their values.
The shadow properties are related to a chart serie, so first we need to pin that serie down. That will be the entry point to the whole XML. As with the previous chart, we start from PlotArea class. This class lists all kinds of chart types as child XML descendents, among other things, and since our chart is a 3D pie chart, we move on to Pie3DChart class. The shadow properties are specific to a chart serie, they are not global of the whole chart (see the image above), so the next XML node is PieChartSeries class.
The XML node that we are looking for is ChartShapeProperties class, this is where the shadow properties will be, but before we continue, we need to make sure that we pick the correct serie out of all the chart series. In our case, we only added one serie to the chart so there isn't much choice here, but I would like to generalize the code a little bit and pick a chart serie based on a index parameter. One of the child XML nodes is Index class. This XML simply holds the index of the serie among all the chart series. If the parameter is serieIndex, then the XPath from PieChartSeries class is "c:ser[c:idx[@val='serieIndex']]". In plain words, this XPath picks PieChartSeries class (c:ser) that has a child Index class (c:idx) which has an attribute val (@val) with a value of serieIndex. If any of this goes over your head, you need to brush on your XPath. Here's a quick peek to the C# code.
var ser = xdoc.SelectSingleNode(
"/c:chartSpace/c:chart/c:plotArea/c:pie3DChart/c:ser[c:idx[@val='" + serieIndex + "']]",
nsm
);
The xml node ChartShapeProperties class has several child nodes and each of them define a different visual aspect of the chart such as filling colors, gradients, outline. Its child XML node EffectList class is a container for various visual effects. One of these effects is OuterShadow class and this one defines the chart (outer) shadow.
If we take a look at the XML so far, we can see that we are actually using two different namespaces. The "c" namespace is the chart namespace and the "a" namespace is the schema namespace. EffectList class is not specific to charts, it can be used in other objects that involve drawing, which is why it doesn't exist under the "c" chart namespace.
<c:pie3DChart>
<c:ser>
<c:idx val="0" />
<c:spPr>
<a:effectLst>
<a:outerShdw>
</a:outerShdw>
</a:effectLst>
</c:spPr>
</c:ser>
</c:pie3DChart>
The OuterShadow class has sx and sy attributes that are the horizontal and vertical scaling factors. These attributes define the shadow size, in our case it is 90%. The percentage accuracy is measured in 1000th of a percent (1/1000%), so the XML value is 90 * 1000 = 90000. The attribute blurRad sets the blur radius of the shadow, in our case it is 8 points. We need to multiple this value with 12700 EMUs per point, so the XML value is 8 * 12700 = 101600. The attribute dist sets how far to offset the shadow, in our case it is 25 points. We need to multiple this one too with 12700, so the XML value is 25 * 12700 = 317500. The attribute dir sets the direction to offset the shadow, in our case it is an angle of 90 degrees. The angle accuracy is measured in 60000th of a degree (1/60000 degree), so the XML value is 90 * 60000 = 5400000.
<c:pie3DChart>
<c:ser>
<c:idx val="0" />
<c:spPr>
<a:effectLst>
<a:outerShdw sx="90000" sy="90000" blurRad="101600" dist="317500" dir="5400000">
</a:outerShdw>
</a:effectLst>
</c:spPr>
</c:ser>
</c:pie3DChart>
We still need to set the color and the transparency. In OuterShadow class we add RgbColorModelHex class and in that one we add Alpha class. The RgbColorModelHex class sets the color of the shadow, in our case it is a dark olive color #7F6000 (Red 127, Green 96, Blue 0). The val attribute is the Hex value of the color. The Alpha class sets the opacity of the color in percentages. The alpha value is calculated as alpha = 100% - transparency = 100% - 70% = 30%, and that is the value of the val attribute.
<c:pie3DChart>
<c:ser>
<c:idx val="0" />
<c:spPr>
<a:effectLst>
<a:outerShdw sx="90000" sy="90000" blurRad="101600" dist="317500" dir="5400000">
<a:srgbClr val="7F6000">
<a:alpha val="30%">
</a:alpha>
</a:srgbClr>
</a:outerShdw>
</a:effectLst>
</c:spPr>
</c:ser>
</c:pie3DChart>
That's it for the XML. Now for the implementation. The code starts with initializing some variables that correspond to the shadow parameters. You can see that their values are the same as the ones in the serie shadow editing menu. The rest of the code is in vain with what we did before.
int serieIndex = 0;
int red = 127;
int green = 96;
int blue = 0;
int transparencyPer = 70;
int sizePer = 90;
int blurPt = 8;
int angleDgr = 90;
int distancePt = 25;
int EMU_PER_POINT = 12700;
int ST_PERCENTAGE = 1000;
int ST_POSITIVE_FIXED_ANGLE = 60000;
var xdoc = chart.ChartXml;
var nsm = new XmlNamespaceManager(xdoc.NameTable);
var schemaChart = xdoc.DocumentElement.NamespaceURI;
if (nsm.HasNamespace("c") == false)
nsm.AddNamespace("c", schemaChart);
var schemaDrawings = "http://schemas.openxmlformats.org/drawingml/2006/main";
if (nsm.HasNamespace("a") == false)
nsm.AddNamespace("a", schemaDrawings);
var ser = xdoc.SelectSingleNode(
"/c:chartSpace/c:chart/c:plotArea/c:pie3DChart/c:ser[c:idx[@val='" + serieIndex + "']]",
nsm
);
var spPr = ser.SelectSingleNode("./c:spPr", nsm);
if (spPr == null)
spPr = ser.AppendElement(schemaChart, "c:spPr");
var effectLst = spPr.AppendElement(schemaDrawings, "a:effectLst");
var outerShdw = effectLst.AppendElement(schemaDrawings, "a:outerShdw");
outerShdw.AppendAttribute("sx", (sizePer * ST_PERCENTAGE).ToString());
outerShdw.AppendAttribute("sy", (sizePer * ST_PERCENTAGE).ToString());
outerShdw.AppendAttribute("blurRad", (blurPt * EMU_PER_POINT).ToString());
outerShdw.AppendAttribute("dist", (distancePt * EMU_PER_POINT).ToString());
outerShdw.AppendAttribute("dir", (angleDgr * ST_POSITIVE_FIXED_ANGLE).ToString());
var srgbClr = outerShdw.AppendElement(schemaDrawings, "a:srgbClr");
srgbClr.AppendAttribute("val", string.Format("{0:X2}{1:X2}{2:X2}", red, green, blue));
var alpha = srgbClr.AppendElement(schemaDrawings, "a:alpha");
alpha.AppendAttribute("val", (100 - transparencyPer) + "%");
This is the chart with a shadow.
Finally, we set the material of the chart and make its edges more rounded. The material is going to be metal and the top and bottom bevels will be set to 10 points, width and height.
As with the shadow, this 3D format targets a specific serie and all the important stuff comes with what XML goes in ChartShapeProperties class, so I'm just going to skip right to it. The xml node Shape3DType class sets the 3D appearance and its prstMaterial attribute sets the material from a list of predefined materials, that can be found in PresetMaterialTypeValues enumeration. We want a Metal material, so the attribute value is "metal".
The xml node Shape3DType class has two children BevelTop class and BevelBottom class that set the appearance of the top and bottom bevels respectively. They both have the same attributes. The w attribute sets the width of the bevel and the h attribute sets the height of the bevel. We want to set both to 10 points, so the XML value is 10 * 12700 = 127000.
<c:pie3DChart>
<c:ser>
<c:idx val="0" />
<c:spPr>
<a:sp3d prstMaterial="metal">
<a:bevelT w="127000" h="127000" />
<a:bevelB w="127000" h="127000" />
</a:sp3d>
</c:spPr>
</c:ser>
</c:pie3DChart>
Same with the shadow, the code starts with initializing variables that correspond to the 3D format parameters and the rest of it is the same formulaic code.
int serieIndex = 0;
string material = "metal";
int topBevelWidthPt = 10;
int topBevelHeightPt = 10;
int bottomBevelWidthPt = 10;
int bottomBevelHeightPt = 10;
int EMU_PER_POINT = 12700;
var xdoc = chart.ChartXml;
var nsm = new XmlNamespaceManager(xdoc.NameTable);
var schemaChart = xdoc.DocumentElement.NamespaceURI;
if (nsm.HasNamespace("c") == false)
nsm.AddNamespace("c", schemaChart);
var schemaDrawings = "http://schemas.openxmlformats.org/drawingml/2006/main";
if (nsm.HasNamespace("a") == false)
nsm.AddNamespace("a", schemaDrawings);
var ser = xdoc.SelectSingleNode(
"/c:chartSpace/c:chart/c:plotArea/c:pie3DChart/c:ser[c:idx[@val='" + serieIndex + "']]",
nsm
);
var spPr = ser.SelectSingleNode("./c:spPr", nsm);
if (spPr == null)
spPr = ser.AppendElement(schemaChart, "c:spPr");
var sp3d = spPr.AppendElement(schemaDrawings, "a:sp3d");
sp3d.AppendAttribute("prstMaterial", material);
var bevelT = sp3d.AppendElement(schemaDrawings, "a:bevelT");
bevelT.AppendAttribute("w", (topBevelWidthPt * EMU_PER_POINT).ToString());
bevelT.AppendAttribute("h", (topBevelHeightPt * EMU_PER_POINT).ToString());
var bevelB = sp3d.AppendElement(schemaDrawings, "a:bevelB");
bevelB.AppendAttribute("w", (bottomBevelWidthPt * EMU_PER_POINT).ToString());
bevelB.AppendAttribute("h", (bottomBevelHeightPt * EMU_PER_POINT).ToString());
This is the final appearance of the chart. Better than what we started with.
AdventureWorks7_DataTable.xlsx
This Excel will be the preparation for the next stage when we add pivot tables. Before we can do any analysis on the data, first we need to upload it completely to Excel. The important thing to note is that we don't do any work (groupings, summations) on the data from the .NET side. Rather, the data is loaded as it is, lock, stock and barrel.
Lets say that the data has 50K records and the record type has 10 data members. These data members might be the properties of a POCO or might be the columns of a DataTable. The simple solution is to iterate over 50,000 records and for each record iterate 10 times to plug each data member into its Excel cell, making it a total of 500,000 iterations. If you actually tried that, you would have found that it is very time consuming and not acceptable in any kind of production environment. EPPlus has several methods with the sole purpose of loading data with lots of records very quickly and efficiently.
ExcelRangeBase.LoadFromCollection<T>(IEnumerable<T> Collection)
ExcelRangeBase.LoadFromDataTable(DataTable Table)
ExcelRangeBase.LoadFromText(FileInfo TextFile)
ExcelRangeBase.LoadFromArrays(IEnumerable<object[]> Data)
Apart from loading the data quickly, these methods will create an Excel Table from the data and set column filters if there is a header row. You can choose to have a header row or not from one of these method overloads.
This snippet is the key part of the code. The data is given as a collection of DataRow, which we already read before from SQL or from a file. Then, we pick the starting cell (top-left corner of the table) and load the data to it with LoadFromCollection. We pass two more parameters to LoadFromCollection. The parameter printHeaders tells whether to add a header row to the table with the property names of DataRow. The parameter tableStyle sets the style of the table from a fixed list of possible styles. After the collection is loaded, EPPlus will give the table some generic name and we want to change that by accessing the tables collection, located in ExcelWorksheet.Tables, picking the last table from it and then changing its name.
IEnumerable<DataRow> data;
bool printHeaders = true;
var tableStyle = OfficeOpenXml.Table.TableStyles.Medium2;
using (ExcelRangeBase range = ws.Cells[2, 2]
.LoadFromCollection<DataRow>(data, printHeaders, tableStyle)) { }
OfficeOpenXml.Table.ExcelTable tblData = ws.Tables[ws.Tables.Count - 1];
tblData.Name = "tblData";
This is the full code with all the styling. Remember that the header row will be populated with the names of DataRow properties, and they are not formatted in title case. So, we need to go over every cell in the header row and put the right title to it.
int startRowIndex = 2;
int territoryGroupIndex = 2;
int territoryNameIndex = 3;
int salesPersonIndex = 4;
int orderDateIndex = 5;
int productCategoryIndex = 6;
int productSubcategoryIndex = 7;
int productIndex = 8;
int orderQtyIndex = 9;
int unitPriceDiscountIndex = 10;
int discountIndex = 11;
int unitPriceIndex = 12;
int lineTotalIndex = 13;
int orderYearIndex = 14;
int orderMonthIndex = 15;
IEnumerable<DataRow> data;
bool printHeaders = true;
var tableStyle = OfficeOpenXml.Table.TableStyles.Medium2;
using (ExcelRangeBase range = ws.Cells[startRowIndex, territoryGroupIndex]
.LoadFromCollection<DataRow>(data, printHeaders, tableStyle))
{
range.Style.Border.Top.Style = ExcelBorderStyle.Thin;
range.Style.Border.Bottom.Style = ExcelBorderStyle.Thin;
range.Style.Border.Left.Style = ExcelBorderStyle.Thin;
range.Style.Border.Right.Style = ExcelBorderStyle.Thin;
range.Style.Border.Top.Color.SetColor(System.Drawing.Color.LightGray);
range.Style.Border.Bottom.Color.SetColor(System.Drawing.Color.LightGray);
range.Style.Border.Left.Color.SetColor(System.Drawing.Color.LightGray);
range.Style.Border.Right.Color.SetColor(System.Drawing.Color.LightGray);
}
OfficeOpenXml.Table.ExcelTable tblData = ws.Tables[ws.Tables.Count - 1];
tblData.Name = "tblData";
ws.Cells[startRowIndex, territoryGroupIndex].Value = "Territory Group";
ws.Cells[startRowIndex, territoryNameIndex].Value = "Territory";
ws.Cells[startRowIndex, salesPersonIndex].Value = "Salesperson";
ws.Cells[startRowIndex, orderDateIndex].Value = "Order Date";
ws.Cells[startRowIndex, productCategoryIndex].Value = "Product Category";
ws.Cells[startRowIndex, productSubcategoryIndex].Value = "Product Subcategory";
ws.Cells[startRowIndex, productIndex].Value = "Product";
ws.Cells[startRowIndex, orderQtyIndex].Value = "Quantity";
ws.Cells[startRowIndex, unitPriceDiscountIndex].Value = "Unit Price Discount";
ws.Cells[startRowIndex, discountIndex].Value = "Discount";
ws.Cells[startRowIndex, unitPriceIndex].Value = "Unit Price";
ws.Cells[startRowIndex, lineTotalIndex].Value = "Revenue";
ws.Cells[startRowIndex, orderYearIndex].Value = "Order Year";
ws.Cells[startRowIndex, orderMonthIndex].Value = "Order Month";
using (var cells = ws.Cells[startRowIndex, territoryGroupIndex, startRowIndex, orderMonthIndex])
{
cells.Style.Font.Bold = true;
cells.Style.Font.Size = 11;
cells.Style.HorizontalAlignment = ExcelHorizontalAlignment.Center;
}
AdventureWorks8_PivotTables.xlsx
A pivot table allows you to analyze a large data set by extracting summarized data and displaying it in a visual-concise manner. EPPlus supports pivot tables but up to a point. The features that are missing are all the little finishing touches, at the end, after you created the pivot table. With this Excel, we are going to create six different pivot tables, each will emphasize a different aspect of it and different ways to overcome EPPlus shortcomings. We are going to employ the same strategy when did the charts in the previous Excels, we will let EPPLus do all the work that it can do and then make some changes here and there with Open XML.
This pivot table shows a list of all the salespeople and their total revenues. The pivot table will be ordered by revenue in a descending order. We are also going to add a chart next to it and whenever the pivot table changes, the chart will change too accordingly.
First, we get the data cells. These are all the cells that comprise the data table that we built in the previous Excel. The data table is in another worksheet, so we start by picking the "Data" worksheet, then the data table from that worksheet, then the data table cells.
ExcelWorksheets wsData = ep.Workbook.Worksheets["Data"];
ExcelTable tblData = wsData.Tables["tblData"];
ExcelRange dataCells = wsData.Cells[tblData.Address.Address];
Next, we create the pivot table. The method ExcelWorksheet.PivotTables.Add() takes three parameters. The first parameter is location of the upper-left corner of the pivot table. The second parameter is the data cells for the pivot table. The third parameter is the name of the pivot table. There are also some aesthetic choices, such as enabling grand total row, setting headers and table styling.
ExcelRange pvtLocation = ws.Cells["B4"];
string pvtName = "pvtSalesBySalesperson";
ExcelPivotTable pivotTable = ws.PivotTables.Add(pvtLocation, dataCells, pvtName);
pivotTable.ShowHeaders = true;
pivotTable.RowHeaderCaption = "Salesperson";
pivotTable.ColumGrandTotals = true;
pivotTable.GrandTotalCaption = "Total";
pivotTable.DataOnRows = false;
pivotTable.TableStyle = OfficeOpenXml.Table.TableStyles.Medium9;
When we created the pivot table, with ExcelWorksheet.PivotTables.Add(), EPPlus looked at all the columns from the "tblData" data table and added them to the pivot table ExcelPivotTable.Fields collection. This property is a collection of all the possible fields that we can work with. If you happened to create a data table without a header row, meaning the columns don't have proper name, you could still choose a field by its column index.
A pivot table has four sections, Filters, Rows, Columns, Values. The behavior of the pivot table depends on what fields we put in each section. The corresponding ExcelPivotTable properties are PageFields (Filters), RowFields (Rows), ColumnFields (Columns), DataFields (Values). In our case and in SQL terms, we want to group Salesperson and for each one sums up its Revenue. We also want to set up a filter for Territory Group, which will display only Salesperson that belong to the Territory Group value selected from the filter. This code does all that by simply adding the right pivot table fields to the right sections. Also, please note that we do not sort the Salesperson field because our objective is to sort by revenues, however EPPlus doesn't implement sorting on data fields. We are going to achieve that next through Open XML.
ExcelPivotTableField territoryGroupPageField = pivotTable.PageFields.Add(
pivotTable.Fields["Territory Group"]
);
territoryGroupPageField.Sort = eSortType.Ascending;
ExcelPivotTableField salesPersonRowField = pivotTable.RowFields.Add(
pivotTable.Fields["Salesperson"]
);
ExcelPivotTableDataField revenueDataField = pivotTable.DataFields.Add(
pivotTable.Fields["Revenue"]
);
revenueDataField.Function = DataFieldFunctions.Sum;
revenueDataField.Format = "#,##0_);(#,##0)";
revenueDataField.Name = "Revenue";
This is the initial appearance of the pivot table.
We would like to see the top earners at the top of the pivot table. To do so, we need to sort the pivot table by the revenues in descending order. In order to achieve it, we need to sort the Salesperson field based on the Revenue field. The field that is getting sorted is the Salesperson field and the criteria for sorting is the Revenue field. So the first task is to locate this field inside the XML. The entry point for pivot table Open XML is ExcelPivotTable.PivotTableXml. The first XML element is PivotTableDefinition class. This XML element contains all the other XML elements that together define the pivot table, such as the row fields, column fields, data fields, filter and more. The XML element PivotFields class is a collection all the fields that take part of the pivot table. In our case, we have only three such fields Territory Group, Salesperson and Revenue. A pivot field is defined by the XML element PivotField class and we find the one that we want by its location in the collection. EPPlus provides the location of the pivot field with the property ExcelPivotTableField.Index. This is a snippet code that implements all that. I would like to remind you that XPath position() is a 1-based index.
ExcelPivotTableField field = salesPersonRowField;
var pivotField = xdoc.SelectSingleNode(
"/x:pivotTableDefinition/x:pivotFields/x:pivotField[position()=" + (field.Index + 1) + "]",
nsm
);
Now that we picked the right pivot field we can start manipulate its sortation. The attribute sortType sets the sort direction. Its possible values are "ascending" and "descending", so we just going to set it to "descending". Next, the element AutoSortScope class handles the pivot table sorting scope. Then, the element PivotArea class defines what part of the pivot table to handle. Then, the element PivotAreaReferences class defines a set of referenced fields. This is where we are going to put a reference to the Revenue data field. The count attribute specifies how many references there are, so for us it is just "1". The element PivotAreaReference class defines the field reference and its field attribute is the index of that referenced field. However, if the referenced field is a data field, the attribute value must be set to -2. From the specifications in the MSDN page, you can read that the data type of the field attribute is an unsigned int. What is the conversion from int to unsigned int for a negative number? The calculation is ((2^32)-2) = 4294967296-2 = 4294967294. The value 4294967294 is what we put in the attribute to indicate the referenced field is a data field. The XML element FieldItem class defines an index of a field. The field index is set in the v attribute. We need to find the index of the data field among all the data fields. Since we have only one data field - Revenue - that index will simply be 0.
<x:pivotField sortType="descending">
<x:autoSortScope>
<x:pivotArea>
<x:references count="1">
<x:reference field="4294967294">
<x:x v="0" />
</x:reference>
</x:references>
</x:pivotArea>
</x:autoSortScope>
</x:pivotField>
The sorting is performed on ExcelPivotTableField salesPersonRowField, which is the Salesperson column that we added to the pivot table Rows section. The sorting criteria is based on the data field ExcelPivotTableDataField revenueDataField, which is the Revenue column that we added to the pivot table Values section.
ExcelPivotTableField field = salesPersonRowField;
ExcelPivotTableDataField dataField = revenueDataField;
bool descending = true;
var xdoc = pivotTable.PivotTableXml;
var nsm = new XmlNamespaceManager(xdoc.NameTable);
var schemaMain = xdoc.DocumentElement.NamespaceURI;
if (nsm.HasNamespace("x") == false)
nsm.AddNamespace("x", schemaMain);
var pivotField = xdoc.SelectSingleNode(
"/x:pivotTableDefinition/x:pivotFields/x:pivotField[position()=" + (field.Index + 1) + "]",
nsm
);
pivotField.AppendAttribute("sortType", (descending ? "descending" : "ascending"));
var autoSortScope = pivotField.AppendElement(schemaMain, "x:autoSortScope");
var pivotArea = autoSortScope.AppendElement(schemaMain, "x:pivotArea");
var references = pivotArea.AppendElement(schemaMain, "x:references");
references.AppendAttribute("count", "1");
var reference = references.AppendElement(schemaMain, "x:reference");
reference.AppendAttribute("field", "4294967294");
var x = reference.AppendElement(schemaMain, "x:x");
int v = 0;
foreach (ExcelPivotTableDataField pivotDataField in pivotTable.DataFields)
{
if (pivotDataField == dataField)
{
x.AppendAttribute("v", v.ToString());
break;
}
v++;
}
The pivot table is sorted by revenues in descending order.
Now we add the pivot table chart. The code is very similar to adding a regular chart except the last parameter is the pivot table as the chart data source. This will connect the pivot table and the chart together. If you change the pivot table - in Excel, not in the code - the chart will change too to reflect the pivot table.
ExcelBarChart chart = ws.Drawings.AddChart(
"crtSalesBySalesperson",
eChartType.BarClustered,
pivotTable
) as ExcelBarChart;
chart.SetPosition(1, 0, 4, 0);
chart.SetSize(600, 400);
chart.Title.Text = "Sales by Salesperson";
chart.Title.Font.Size = 18;
chart.Title.Font.Bold = true;
chart.GapWidth = 25;
chart.DataLabel.ShowValue = true;
chart.Legend.Remove();
chart.XAxis.MajorTickMark = eAxisTickMark.None;
chart.XAxis.MinorTickMark = eAxisTickMark.None;
chart.YAxis.DisplayUnit = 1000;
chart.YAxis.Deleted = true;
ExcelBarChartSerie serie = chart.Series[0] as ExcelBarChartSerie;
serie.Fill.Color = System.Drawing.Color.FromArgb(91, 155, 213);
There are two things that we need to fix. Remove the vertical gridlines and sort the chart in descending order. The reason the chart is not sorted in descending order right from the start is because we made the previous changes through Open XML, not with EPPlus.
We previously saw that the interesting chart stuff is defined in PlotArea class, so we're just going to start from there. The plot area has two axis XML elements. The first is ValueAxis class and the second is CategoryAxis class. Roughly speaking, the first one handles the X axis and the second handles the Y axis. For our pivot chart, we need to change the X axis. The vertical gridlines are the X axis because the direction of eChartType.BarClustered is vertical. Both axis have major and minor gridlines, The major is defined by MajorGridlines class and the minor is defined by MinorGridlines class. A gridline existence in the chart depends on whether the corresponding gridline XML element exists. So what we need to do is simply delete the X axis major gridlines XML element.
This code do more than delete the gridlines. It can also be used to add X & Y axis, major & minor gridlines.
bool isXAxis = true;
bool isMajorGridlines = true;
bool enable = false;
var xdoc = chart.ChartXml;
var nsm = new XmlNamespaceManager(xdoc.NameTable);
var schemaChart = xdoc.DocumentElement.NamespaceURI;
if (nsm.HasNamespace("c") == false)
nsm.AddNamespace("c", schemaChart);
var axes = xdoc.SelectNodes(
string.Format("/c:chartSpace/c:chart/c:plotArea/{0}", (isXAxis ? "c:valAx" : "c:catAx")),
nsm
);
if (axes != null && axes.Count > 0)
{
foreach (XmlNode axis in axes)
{
var gridlines = axis.SelectSingleNode(
(isMajorGridlines ? "c:majorGridlines" : "c:minorGridlines"),
nsm
);
if (gridlines != null)
{
if (enable)
{
if (gridlines == null)
{
axis.AppendElement(
schemaChart,
(isMajorGridlines ? "c:majorGridlines" : "c:minorGridlines")
);
}
}
else
{
if (gridlines != null)
axis.RemoveChild(gridlines);
}
}
}
}
This is the chart without the X axis gridlines.
All that's left to do is reverse the order of revenues from high to low. As we saw before, the CategoryAxis class handles the Y axis and our Y axis is the revenues. Within it, the XML element Scaling class handles more settings regarding the axis, for example minimum and maximum values. The element that we need is the Orientation class. In the context of an axis, this element determines if the category will be sorted from minimum to maximum or from maximum to minimum. The possible orientation values, for the val attribute, are "minMax" and "maxMin".
<c:catAx>
<c:scaling>
<c:orientation val="maxMin">
</c:orientation>
</c:scaling>
</c:catAx>
This code sets the order of the categories (Y) axis.
bool maxMin = true;
var xdoc = chart.ChartXml;
var nsm = new XmlNamespaceManager(xdoc.NameTable);
var schemaChart = xdoc.DocumentElement.NamespaceURI;
if (nsm.HasNamespace("c") == false)
nsm.AddNamespace("c", schemaChart);
var catAxs = xdoc.SelectNodes("/c:chartSpace/c:chart/c:plotArea/c:catAx", nsm);
if (catAxs != null && catAxs.Count > 0)
{
foreach (XmlNode catAx in catAxs)
{
var scaling = catAx.AppendElement(schemaChart, "c:scaling");
var orientation = scaling.AppendElement(schemaChart, "c:orientation");
orientation.AppendAttribute("val", (maxMin ? "maxMin" : "minMax"));
}
}
The final appearance of the pivot table chart.
This pivot table shows the total revenues per product subcategory and is filtered to show only the top 5 revenues.
The main code is essentially the same as the Sales by Salesperson pivot table. The key difference is the column Product Subcategory is added as row pivot table field instead of Salesperson column. The chart is also created in the same manner as the Sales by Salesperson chart, so I won't go into details about it.
ExcelWorksheets wsData = ep.Workbook.Worksheets["Data"];
ExcelTable tblData = wsData.Tables["tblData"];
ExcelRange dataCells = wsData.Cells[tblData.Address.Address];
ExcelRange pvtLocation = ws.Cells["B4"];
string pvtName = "pvtSalesByProductSubcategory";
ExcelPivotTable pivotTable = ws.PivotTables.Add(pvtLocation, dataCells, pvtName);
pivotTable.ShowHeaders = true;
pivotTable.RowHeaderCaption = "Subcategory";
pivotTable.ColumGrandTotals = true;
pivotTable.GrandTotalCaption = "Total";
pivotTable.DataOnRows = false;
pivotTable.TableStyle = OfficeOpenXml.Table.TableStyles.Medium14;
ExcelPivotTableField territoryGroupPageField = pivotTable.PageFields.Add(
pivotTable.Fields["Territory Group"]
);
territoryGroupPageField.Sort = eSortType.Ascending;
ExcelPivotTableField productSubcategoryRowField = pivotTable.RowFields.Add(
pivotTable.Fields["Product Subcategory"]
);
ExcelPivotTableDataField revenueDataField = pivotTable.DataFields.Add(
pivotTable.Fields["Revenue"]
);
revenueDataField.Function = DataFieldFunctions.Sum;
revenueDataField.Format = "#,##0_);(#,##0)";
revenueDataField.Name = "Revenue";
ExcelPivotTableField field = productSubcategoryRowField;
ExcelPivotTableDataField dataField = revenueDataField;
bool descending = true;
pivotTable.SortOnDataField(field, dataField, descending);
The list of product subcategories is pretty long, 33 subcategories to be exact, but that might not be useful to anyone who's reading it. We want to focus only on the top subcategory revenues and not care who is at the bottom of the list. In Excel, you can enable the Top 10 values filter but EPPlus doesn't provide any kind of filters on data fields.
The element PivotFilters class is a container of all the filters. The count attribute is how many pivot filters there are. The element PivotFilter class is the pivot filter. The id attribute is an unsigned int that identify the filter. This means the id attribute values, for all the filters, is just a running number starting from 1. The type attribute set the type of the filter. The possible values are "count", "percent" and "sum". The "count" type sets the pivot filter to "Items" in the popup (see image above). The fld attribute tells the pivot filter which field to sort. The iMeasureFld attribute tells the pivot filter which data field to sort by. In our case, fld attribute is the index of the Product Subcategory pivot field and the iMeasureFld attribute is the index of the Revenue data field. If you look again at the Data worksheet, you can see that the Product Subcategory is the 6th column, so the value of the fld attribute is 5. There is only one data field, that's the Revenue column, so the value of the iMeasureFld attribute is 0.
<x:filters count="1">
<x:filter id="1" type="count" fld="5" iMeasureFld="0">
</x:filter>
</x:filters>
The element AutoFilter class defines the filter criteria. We've already encountered this element in Preselect Filters. The FilterColumn class identifies the auto filter column that the filtering would be applied to and the colId attribute specify its index. If you look again at the pivot table, you can see that the only auto filter column is the first column of the pivot table. So, the value of colId attribute is 0. The element Top10 class defines the Top 10 filter. The val attribute sets how many items (or how much percentage) to show. The top attribute determines whether to show the top items ("1") or the bottom items ("0"). The percent attribute determines whether to filter by percent values ("1"), otherwise filter by number of items ("0").
<x:filters count="1">
<x:filter id="1" type="count" fld="5" iMeasureFld="0">
<x:autoFilter>
<x:filterColumn colId="0">
<x:top10 val="5" top="1" percent="0">
</x:top10>
</x:filterColumn>
</x:autoFilter>
</x:filter>
</x:filters>
The code checks if there are other filters to the pivot table, and if so, keeps them and appends the Top 10 filter to the end of the filters collection.
ExcelPivotTableField field = productSubcategoryRowField;
ExcelPivotTableDataField dataField = revenueDataField;
int number = 5;
bool bottom = false;
bool percent = false;
var xdoc = pivotTable.PivotTableXml;
var nsm = new XmlNamespaceManager(xdoc.NameTable);
var schemaMain = xdoc.DocumentElement.NamespaceURI;
if (nsm.HasNamespace("x") == false)
nsm.AddNamespace("x", schemaMain);
var filters = xdoc.SelectSingleNode("/x:pivotTableDefinition/x:filters", nsm);
int filtersCount = 0;
if (filters == null)
{
var pivotTableDefinition = xdoc.SelectSingleNode("/x:pivotTableDefinition", nsm);
filters = pivotTableDefinition.AppendElement(schemaMain, "x:filters");
filtersCount = 1;
}
else
{
XmlAttribute countAttr = filters.Attributes["count"];
int count = int.Parse(countAttr.Value);
filtersCount = count + 1;
}
filters.AppendAttribute("count", filtersCount.ToString());
var filter = filters.AppendElement(schemaMain, "x:filter");
filter.AppendAttribute("id", filtersCount.ToString());
filter.AppendAttribute("type", (percent ? "percent" : "count"));
int fld = 0;
foreach (ExcelPivotTableField pivotField in pivotTable.Fields)
{
if (pivotField == field)
{
filter.AppendAttribute("fld", fld.ToString());
break;
}
fld++;
}
int iMeasureFld = 0;
foreach (ExcelPivotTableDataField pivotDataField in pivotTable.DataFields)
{
if (pivotDataField == dataField)
{
filter.AppendAttribute("iMeasureFld", iMeasureFld.ToString());
break;
}
iMeasureFld++;
}
var autoFilter = filter.AppendElement(schemaMain, "x:autoFilter");
var filterColumn = autoFilter.AppendElement(schemaMain, "x:filterColumn");
filterColumn.AppendAttribute("colId", "0");
var top10 = filterColumn.AppendElement(schemaMain, "x:top10");
top10.AppendAttribute("val", number.ToString());
top10.AppendAttribute("top", (bottom ? "0" : "1"));
top10.AppendAttribute("percent", (percent ? "1" : "0"));
This pivot table shows the revenues breakdown for each product subcategory. The revenues breakdown consists of the average unit price, how many units were sold and how many times the item was ordered (one order can consists of several units). The pivot table is sorted by number of orders in descending order. All these metrics are indicative to how items are sold. The average unit price can increase if the number of units per order is increasing (bulk purchasing) or the number of orders is increasing or both. This kind of information is very useful for sales analysis and a pivot table can show sales trends in a clear and concise way.
The beginning of the code is simple enough. The Territory Group column goes to the Filters section, the Product Subcategory column goes to the Rows section, the Revenue column is added as a data field, just like we did with the previous pivot tables.
ExcelWorksheets wsData = ep.Workbook.Worksheets["Data"];
ExcelTable tblData = wsData.Tables["tblData"];
ExcelRange dataCells = wsData.Cells[tblData.Address.Address];
ExcelRange pvtLocation = ws.Cells["B4"];
string pvtName = "pvtOrders";
ExcelPivotTable pivotTable = ws.PivotTables.Add(pvtLocation, dataCells, pvtName);
pivotTable.ShowHeaders = true;
pivotTable.RowHeaderCaption = "Subcategory";
pivotTable.ColumGrandTotals = true;
pivotTable.GrandTotalCaption = "Total";
pivotTable.DataOnRows = false;
pivotTable.TableStyle = OfficeOpenXml.Table.TableStyles.Medium10;
ExcelPivotTableField territoryGroupPageField = pivotTable.PageFields.Add(
pivotTable.Fields["Territory Group"]
);
territoryGroupPageField.Sort = eSortType.Ascending;
ExcelPivotTableField productSubcategoryRowField = pivotTable.RowFields.Add(
pivotTable.Fields["Product Subcategory"]
);
ExcelPivotTableDataField revenueDataField = pivotTable.DataFields.Add(
pivotTable.Fields["Revenue"]
);
revenueDataField.Function = DataFieldFunctions.Sum;
revenueDataField.Format = "#,##0_);(#,##0)";
revenueDataField.Name = "Revenue";
Up till now, all the data fields were set for summation calculation over the data. We did that by setting the data field Function property with DataFieldFunctions.Sum. Now, we need add the Unit Price column as data field but we need it to be calculated as the average price and for that we set the Function property with the function DataFieldFunctions.Average.
ExcelPivotTableDataField unitPriceDataField = pivotTable.DataFields.Add(
pivotTable.Fields["Unit Price"]
);
unitPriceDataField.Function = DataFieldFunctions.Average;
unitPriceDataField.Format = "#,##0_);(#,##0)";
unitPriceDataField.Name = "Unit Price";
The number of units sold is a summation of the Quantity column.
ExcelPivotTableDataField quantityDataField = pivotTable.DataFields.Add(
pivotTable.Fields["Quantity"]
);
quantityDataField.Function = DataFieldFunctions.Sum;
quantityDataField.Format = "#,##0_);(#,##0)";
quantityDataField.Name = "Quantity";
Each line in the data represents a single order, so to find how many orders were ordered for a given product subcategory, we simply need to count the lines. For this data field, we set the Function property with the function DataFieldFunctions.Count. I would like to point out that it doesn't matter what column we use to count the number of lines. You can see in the code that we use the Quantity column as the source of the data field, however since we don't need the actual quantity value, we can replace it with any other column that we like and still get the right results.
ExcelPivotTableDataField ordersCountDataField = pivotTable.DataFields.Add(
pivotTable.Fields["Quantity"]
);
ordersCountDataField.Function = DataFieldFunctions.Count;
ordersCountDataField.Format = "#,##0_);(#,##0)";
ordersCountDataField.Name = "# Orders";
We finish with sorting the product subcategories by their number of orders in descending order.
ExcelPivotTableField field = productSubcategoryRowField;
ExcelPivotTableDataField dataField = ordersCountDataField;
bool descending = true;
pivotTable.SortOnDataField(field, dataField, descending);
This pivot table breaks downs the total revenues for each product subcategory and further more for each salesperson under each category. The product subcategories are ordered in descending order of revenues and the salespeople are ordered in ascending order of revenues. This view of the data emphasis the salespeople who are slacking in their sales. The product subcategories that are at the top of revenue list are being sold easily. Salespeople with less percentage of those product category revenues, can't blame their lack of sales on the product itself, meaning they are slacking on the job or they are less competent as salespeople overall. Apart from the total revenues, the pivot table also shows the percentage of the revenues out of the grand total and the percentage out of the parent product subcategory for each salesperson.
This code builds the backbone of the pivot table. It doesn't yet add the percentage columns. We add two columns to the Rows section, Product Subcategory and Salesperson, but the order is important. The order determines which one will be the parent and which one will be the child. As said before, the outer sort of the product subcategories is in descending order and the inner sort of the salespeople is in ascending order.
ExcelWorksheets wsData = ep.Workbook.Worksheets["Data"];
ExcelTable tblData = wsData.Tables["tblData"];
ExcelRange dataCells = wsData.Cells[tblData.Address.Address];
ExcelRange pvtLocation = ws.Cells["B4"];
string pvtName = "pvtRevenuePercentage";
ExcelPivotTable pivotTable = ws.PivotTables.Add(pvtLocation, dataCells, pvtName);
pivotTable.ShowHeaders = true;
pivotTable.RowHeaderCaption = "Subcategory";
pivotTable.ColumGrandTotals = true;
pivotTable.GrandTotalCaption = "Total";
pivotTable.DataOnRows = false;
pivotTable.TableStyle = OfficeOpenXml.Table.TableStyles.Medium11;
ExcelPivotTableField territoryGroupPageField = pivotTable.PageFields.Add(
pivotTable.Fields["Territory Group"]
);
territoryGroupPageField.Sort = eSortType.Ascending;
ExcelPivotTableField productSubcategoryRowField = pivotTable.RowFields.Add(
pivotTable.Fields["Product Subcategory"]
);
ExcelPivotTableField salesPersonRowField = pivotTable.RowFields.Add(
pivotTable.Fields["Salesperson"]
);
ExcelPivotTableDataField revenueDataField = pivotTable.DataFields.Add(
pivotTable.Fields["Revenue"]
);
revenueDataField.Function = DataFieldFunctions.Sum;
revenueDataField.Format = "#,##0_);(#,##0)";
revenueDataField.Name = "Revenue";
pivotTable.SortOnDataField(productSubcategoryRowField, revenueDataField, true);
pivotTable.SortOnDataField(salesPersonRowField, revenueDataField, false);
EPPlus doesn't support "Show Value As" feature for pivot data fields. Again, we need to hack our way into Open XML. The pivot column % Revenue shows the revenue as a percentage, for each product subcategory and for each salesperson, of the total revenues. The total of percentages for salespeople, under any given product subcategory, will sum up to the sub category percentage of the total revenues.
We start by adding the Revenue column as a pivot data column, but we also set the display format to percentage format 0.00%.
ExcelPivotTableDataField revenuePercentageDataField = pivotTable.DataFields.Add(
pivotTable.Fields["Revenue"]
);
revenuePercentageDataField.Function = DataFieldFunctions.Sum;
revenuePercentageDataField.Format = "0.00%";
revenuePercentageDataField.Name = "% Revenue";
As before, we start with PivotTableDefinition class. It contains the XML element DataFields class which is a collection of the individual data fields. A data field is defined with the XML element DataField class. The attribute name sets the name of data field and through this attribute we find the data field that we need to manipulate.
<x:pivotTableDefinition>
<x:dataFields>
<x:dataField name="% Revenue" showDataAs="percentOfTotal">
</x:dataField>
</x:dataFields>
</x:pivotTableDefinition>
The attribute showDataAs sets how the data field will be displayed. The possible values are defined in ShowDataAsValues enumeration. Our intent is to set this data field to show as % of Grand Total and for that purpose, the correct value, for this attribute, is "percentOfTotal".
ExcelPivotTableDataField dataField = revenuePercentageDataField;
string showDataAs = "percentOfTotal";
var xdoc = pivotTable.PivotTableXml;
var nsm = new XmlNamespaceManager(xdoc.NameTable);
var schemaMain = xdoc.DocumentElement.NamespaceURI;
if (nsm.HasNamespace("x") == false)
nsm.AddNamespace("x", schemaMain);
var dataFieldNode = xdoc.SelectSingleNode(
"/x:pivotTableDefinition/x:dataFields/x:dataField[@name='" + dataField.Name + "']",
nsm
);
dataFieldNode.AppendAttribute("showDataAs", showDataAs);
This pivot column shows the revenues of each salesperson as percentage of the its parent product subcategory.
As with the previous pivot column, we add the Revenue column as a pivot data column and set its display to a percentage format.
ExcelPivotTableDataField parentRowPercentageDataField = pivotTable.DataFields.Add(
pivotTable.Fields["Revenue"]
);
parentRowPercentageDataField.Function = DataFieldFunctions.Sum;
parentRowPercentageDataField.Format = "0.00%";
parentRowPercentageDataField.Name = "% Parent";
Lets take a second look at the ShowDataAsValues enumeration. There are only 9 possible values and non of them indicates show value as percentage of parent row. In fact, there are many other options that are missing from this enumeration which are available from the pivot data column edit popup in the Excel program. So, where exactly are they defined? The first version of Open XML, way back when, didn't list these options and they simply didn't exist. They were defined in a subsequent version of Open XML (Excel 2010) with an Open XML extension.
Open XML has extensibility mechanism to define future features. It does so with extensions. Extensions define a future version of the Open XML markup. A collection of extensions is defined with the element ExtensionList class. A single extension is defined with the element Extension class. Every extension has an uri attribute which acts as an identifier to indicate information about the extension. It is up to the XML consumer (for example Excel program), which reads the XML, to decide if it knows how to process the extension, based on the uri value. The actual functionality is defined inside the extension XML element.
The extensions for pivot tables are listed in this MSDN page Pivot Table Extensions. The extension that we need extends a pivot field and its uri is {E15A36E0-9728-4e99-A89B-3F7291B0FE68}. The XML element dataField is the actual implementation of this extension. The namespace, this element is defined under, is "http://schemas.microsoft.com/office/spreadsheetml/2009/9/main" with prefix "x14". The element dataField is of type CT_DataField, which is a complex type. There is an documentation about this type in this link CT_DataField. The attribute of this type, that we are interested of, is the pivotShowAs attribute. The pivotShowAs attribute can be set to one of these PivotShowAs enumeration values. This enumeration lists all the parent-of options and the ranking options. The option that we need is the percentage of the parent row and its value is "percentOfParentRow".
Lastly, the XML element PivotTableDefinition class has an attribute updatedVersion which, as MSDN puts it, "Specifies the version of the application that last updated the PivotTable view". The version that you put for this attribute relates to the version of Excel and without setting this attribute the Open XML extension won't work. For Excel 2013 and above, I would recommend that you set this attribute to "5" or higher.
<x:pivotTableDefinition updatedVersion="5">
<x:dataFields>
<x:dataField name="% Parent">
<x:extLst>
<x:ext uri="{E15A36E0-9728-4e99-A89B-3F7291B0FE68}">
<x14:dataField pivotShowAs="percentOfParentRow">
</x14:dataField>
</x:ext>
</x:extLst>
</x:dataField>
</x:dataFields>
</x:pivotTableDefinition>
The implementation of the above XML.
ExcelPivotTableDataField dataField = parentRowPercentageDataField;
string pivotShowAs = "percentOfParentRow";
var xdoc = pivotTable.PivotTableXml;
var nsm = new XmlNamespaceManager(xdoc.NameTable);
var schemaMain = xdoc.DocumentElement.NamespaceURI;
if (nsm.HasNamespace("x") == false)
nsm.AddNamespace("x", schemaMain);
var schemaMainX14 = "http://schemas.microsoft.com/office/spreadsheetml/2009/9/main";
if (nsm.HasNamespace("x14") == false)
nsm.AddNamespace("x14", schemaMainX14);
var pivotTableDefinition = xdoc.SelectSingleNode("/x:pivotTableDefinition", nsm);
pivotTableDefinition.AppendAttribute("updatedVersion", "5");
var dataFieldNode = xdoc.SelectSingleNode(
"/x:pivotTableDefinition/x:dataFields/x:dataField[@name='" + dataField.Name + "']",
nsm
);
var extLst = dataFieldNode.AppendElement(schemaMain, "x:extLst");
var ext = extLst.AppendElement(schemaMain, "x:ext");
ext.AppendAttribute("uri", "{E15A36E0-9728-4e99-A89B-3F7291B0FE68}");
var x14DataField = ext.AppendElement(schemaMainX14, "x14:dataField");
x14DataField.AppendAttribute("pivotShowAs", pivotShowAs);
With the previous pivot column, we pointed to the parent row (product subcategory) as the total value for all its child rows (salespeople). When we pointed to the parent row, we implicitly pointed to the product subcategory. With this pivot column we aim to achieve the same column but we are going to explicitly point to the product subcategory as the parent.
Like before, we add the Revenue column as a pivot data column and set its display to a percentage format.
ExcelPivotTableDataField subcategoryPercentageDataField = pivotTable.DataFields.Add(
pivotTable.Fields["Revenue"]
);
subcategoryPercentageDataField.Function = DataFieldFunctions.Sum;
subcategoryPercentageDataField.Format = "0.00%";
subcategoryPercentageDataField.Name = "% Subcategory";
Look again at the image above and you'll see that the Base Field list is enabled and the product subcategory field is selected. The Base Field list is enabled because the value is set to be shown as % of Parent Total and the user is prompted to select which field is the parent.
The XML is the same as the one we did before apart from two changes. The value of the pivotShowAs attribute is set to "percentOfParent", which is part of the PivotShowAs enumeration. The baseField attribute is the index of the pivot table field among all fields. As it so happens, EPPlus provides an index attribute for every pivot table field in ExcelPivotTableField.Index property, like this:
ExcelPivotTableField baseField = pivotTable.Fields["Product Subcategory"];
int index = baseField.Index;
This is the XML.
<x:pivotTableDefinition updatedVersion="5">
<x:dataFields>
<x:dataField name="% Subcategory" baseField="5">
<x:extLst>
<x:ext uri="{E15A36E0-9728-4e99-A89B-3F7291B0FE68}">
<x14:dataField pivotShowAs="percentOfParent">
</x14:dataField>
</x:ext>
</x:extLst>
</x:dataField>
</x:dataFields>
</x:pivotTableDefinition>
And the implementation. I highlighted the main differences from the previous pivot column.
ExcelPivotTableDataField dataField = subcategoryPercentageDataField;
string pivotShowAs = "percentOfParent";
ExcelPivotTableField baseField = pivotTable.Fields["Product Subcategory"];
var xdoc = pivotTable.PivotTableXml;
var nsm = new XmlNamespaceManager(xdoc.NameTable);
var schemaMain = xdoc.DocumentElement.NamespaceURI;
if (nsm.HasNamespace("x") == false)
nsm.AddNamespace("x", schemaMain);
var schemaMainX14 = "http://schemas.microsoft.com/office/spreadsheetml/2009/9/main";
if (nsm.HasNamespace("x14") == false)
nsm.AddNamespace("x14", schemaMainX14);
var pivotTableDefinition = xdoc.SelectSingleNode("/x:pivotTableDefinition", nsm);
pivotTableDefinition.AppendAttribute("updatedVersion", "5");
var dataFieldNode = xdoc.SelectSingleNode(
"/x:pivotTableDefinition/x:dataFields/x:dataField[@name='" + dataField.Name + "']",
nsm
);
dataFieldNode.AppendAttribute("baseField", baseField.Index.ToString());
var extLst = dataFieldNode.AppendElement(schemaMain, "x:extLst");
var ext = extLst.AppendElement(schemaMain, "x:ext");
ext.AppendAttribute("uri", "{E15A36E0-9728-4e99-A89B-3F7291B0FE68}");
var x14DataField = ext.AppendElement(schemaMainX14, "x14:dataField");
x14DataField.AppendAttribute("pivotShowAs", pivotShowAs);
This pivot table breaks down the monthly sales, that each salesperson did, for each year. On the horizontal axis, it shows the progression in sales per month. On the vertical axis, you can compare the revenues of the current & previous years on a monthly basis. The key point with this pivot table is to take the Order Date and group it by months.
Except for the Month pivot column, we build this pivot table just like we did before. Territory Group column goes to the Filters section. Salesperson & Order Year columns go to the Rows section and the Year pivot column is sorted in descending order. Revenue column goes to the Values section.
The code is pretty straightforward and does what we planned for this pivot table.
ExcelWorksheets wsData = ep.Workbook.Worksheets["Data"];
ExcelTable tblData = wsData.Tables["tblData"];
ExcelRange dataCells = wsData.Cells[tblData.Address.Address];
ExcelRange pvtLocation = ws.Cells["B4"];
string pvtName = "pvtMonthlySales";
ExcelPivotTable pivotTable = ws.PivotTables.Add(pvtLocation, dataCells, pvtName);
pivotTable.ShowHeaders = false;
pivotTable.ColumGrandTotals = true;
pivotTable.GrandTotalCaption = "Total";
pivotTable.DataOnRows = false;
pivotTable.TableStyle = OfficeOpenXml.Table.TableStyles.Medium6;
ExcelPivotTableField territoryGroupPageField = pivotTable.PageFields.Add(
pivotTable.Fields["Territory Group"]
);
territoryGroupPageField.Sort = eSortType.Ascending;
ExcelPivotTableField salesPersonRowField = pivotTable.RowFields.Add(
pivotTable.Fields["Salesperson"]
);
salesPersonRowField.Sort = eSortType.Ascending;
ExcelPivotTableField yearRowField = pivotTable.RowFields.Add(
pivotTable.Fields["Order Year"]
);
yearRowField.Sort = eSortType.Descending;
yearRowField.Name = "Year";
ExcelPivotTableDataField revenueDataField = pivotTable.DataFields.Add(
pivotTable.Fields["Revenue"]
);
revenueDataField.Function = DataFieldFunctions.Sum;
revenueDataField.Format = "#,##0_);(#,##0)";
revenueDataField.Name = "Revenue";
We need to add Month pivot column to complete the pivot table. If we did this directly in Excel, we would drag the Order Date column to the Columns section, right-click on the dates and click on Grouping. The Grouping popup would let us choose what groups to enable and in our case we would choose Months.
We start by adding the Order Date column to the pivot table Columns section. Then, we set it to group the dates on months with this method ExcelPivotTableField.AddDateGrouping(eDateGroupBy groupBy). The eDateGroupBy enumeration is attribute-marked as [Flags], meaning you can choose several types of groupings. We'll see how that works in the next pivot table. For this pivot column we only need eDateGroupBy.Months.
monthColumnField.AddDateGrouping(eDateGroupBy.Months);
When EPPlus creates the grouping items, it creates two more items apart from the groupings that you specified. These are below & above items. Their meaning is below & above the range of dates that we specified as data. Sometimes they will not be of use, depending of the grouping, because they have no actual meaning, but EPPlus creates them nonetheless. So, we grouped on months and in ascending order, so the group items, in index order, are: below min date (index 0), 1 (index 1), ..., 12 (index 12), above max date (index 13). Clearly below & above items don't make any sense and therefore are not in use.
Finally, we need to rename the month items from their numerical values (1, 2, ...) to their English abbreviated names (Jan, Feb, ...). EPPlus lets you access the grouping items through ExcelPivotTableField.Items property. We iterate over the items and make use of an en-US culture to set the month names.
ExcelPivotTableField monthColumnField = pivotTable.ColumnFields.Add(
pivotTable.Fields["Order Date"]
);
monthColumnField.AddDateGrouping(eDateGroupBy.Months);
monthColumnField.Sort = eSortType.Ascending;
monthColumnField.Name = "Month";
var enUS = System.Globalization.CultureInfo.CreateSpecificCulture("en-US");
monthColumnField.Items[0].Text = "<";
for (int month = 1; month <= 12; month++)
monthColumnField.Items[month].Text = enUS.DateTimeFormat.GetAbbreviatedMonthName(month);
monthColumnField.Items[13].Text = ">";
This pivot table shows the quarterly revenues for each salesperson and ordered in descending order of years and quarters.
The point of this pivot table is to show how to group a date column on more than one grouping. But first, we start with the rest of the pivot columns. Territory Group column goes to the Filters section, Salesperson column goes to the Rows section and Revenue column goes to the Values section.
And the code that builds this pivot table.
ExcelWorksheets wsData = ep.Workbook.Worksheets["Data"];
ExcelTable tblData = wsData.Tables["tblData"];
ExcelRange dataCells = wsData.Cells[tblData.Address.Address];
ExcelRange pvtLocation = ws.Cells["B4"];
string pvtName = "pvtQuarterlySales";
ExcelPivotTable pivotTable = ws.PivotTables.Add(pvtLocation, dataCells, pvtName);
pivotTable.ShowHeaders = false;
pivotTable.ColumGrandTotals = true;
pivotTable.GrandTotalCaption = "Total";
pivotTable.DataOnRows = false;
pivotTable.TableStyle = OfficeOpenXml.Table.TableStyles.Medium1;
ExcelPivotTableField territoryGroupPageField = pivotTable.PageFields.Add(
pivotTable.Fields["Territory Group"]
);
territoryGroupPageField.Sort = eSortType.Ascending;
ExcelPivotTableField salesPersonRowField = pivotTable.RowFields.Add(
pivotTable.Fields["Salesperson"]
);
salesPersonRowField.Sort = eSortType.Ascending;
ExcelPivotTableDataField revenueDataField = pivotTable.DataFields.Add(
pivotTable.Fields["Revenue"]
);
revenueDataField.Function = DataFieldFunctions.Sum;
revenueDataField.Format = "#,##0_);(#,##0)";
revenueDataField.Name = "Revenue";
What remains is to create the Quarter & Year pivot columns.
So what happens when we group a date column on two or more date groupings? EPPlus creates several group fields for each date group. These groups have a hierarchy relationship between them of which the least-granularity date group is the parent group and the most-granularity date group is the child group. With our pivot table, the Years date group will be the outset pivot column because it is the least-granularity date group and the Quarters date group will be the inset pivot column because it is the most-granularity date group.
EPPlus will create as many pivot columns as many eDateGroupBy enumeration values that you specify when you call AddDateGrouping method. The ExcelPivotTableField that we use to perform the date grouping upon will become the most-granularity date group. In our case, that would be the Quarter pivot column.
ExcelPivotTableField quarterColumnField = pivotTable.ColumnFields.Add(
pivotTable.Fields["Order Date"]
);
quarterColumnField.AddDateGrouping(eDateGroupBy.Years | eDateGroupBy.Quarters);
This method ExcelPivotTable.Fields.GetDateGroupField(eDateGroupBy grouypBy) will retrieve any pivot column in the date groups. We use it to get the Year pivot column.
ExcelPivotTableField yearColumnField = pivotTable.Fields.GetDateGroupField(eDateGroupBy.Years);
We can also retrieve the Quarter pivot column by using GetDateGroupField method, but that will be the same object as quarterColumnField.
bool areSame = (quarterColumnField == pivotTable.Fields.GetDateGroupField(eDateGroupBy.Quarters));
To finish off, we need to rename the quarters from their default text (Qtr1-Qtr4) to this format Q1-Q4. The Quarter pivot column's group items, in index order, are: below min date (index 0), Q1 (index 1), ..., Q4 (index 4), above max date (index 5). We iterate over the items and rename them.
ExcelPivotTableField quarterColumnField = pivotTable.ColumnFields.Add(
pivotTable.Fields["Order Date"]
);
quarterColumnField.AddDateGrouping(eDateGroupBy.Years | eDateGroupBy.Quarters);
quarterColumnField.Sort = eSortType.Descending;
quarterColumnField.Name = "Quarter";
ExcelPivotTableField yearColumnField = pivotTable.Fields.GetDateGroupField(eDateGroupBy.Years);
yearColumnField.Sort = eSortType.Descending;
yearColumnField.Name = "Year";
quarterColumnField.Items[0].Text = "<";
for (int quarter = 1; quarter <= 4; quarter++)
quarterColumnField.Items[quarter].Text = "Q" + quarter;
quarterColumnField.Items[5].Text = ">";
You might run into a situation where you need to generate 2 or more Excels with slight (or maybe not) differences between them. If they are time-consuming to generate, you'll want to create just one of them and then clone it as many times as you need and make modifications to the clones.
It is important to understand how EPPlus treats ExcelPackage. While ExcelPackage is open, you can edit it but you can't get the underlying Excel stream or Excel bytes array. Once you finalized ExcelPackage, by calling one of these methods ExcelPackage.Save, ExcelPackage.SaveAs or ExcelPackage.GetAsByteArray, you can't make any further changes to it but you can get the stream or bytes array and use them for cloning. You'll notice that you can't make a clone and then continue make changes to the original. Once the original ExcelPackage is finalized, it's closed for good.
This example does everything in memory. The ExcelPackage receives a MemoryStream in the constructor and when the ExcelPackage.Save method is called, ExcelPackage will write the excel bytes into it. Now that the original Excel is written into the MemoryStream, it is used again to load two clones from it with ExcelPackage.Load method.
using (var ms = new MemoryStream())
{
using (var ep = new ExcelPackage(ms))
{
var wb = ep.Workbook;
var ws = wb.Worksheets.Add("Original");
ws.Cells[1, 1].Value = "Value from original workbook";
ws.Column(1).AutoFit();
ep.Save();
}
using (var ep = new ExcelPackage())
{
ep.Load(ms);
var wb = ep.Workbook;
var ws = wb.Worksheets[1];
ws.Name = "Copy 1";
ws.Cells[2, 1].Value = "Copy 1";
using (var file = System.IO.File.OpenWrite("Copy 1.xlsx"))
{
ep.SaveAs(file);
}
}
using (var ep = new ExcelPackage())
{
ep.Load(ms);
var wb = ep.Workbook;
var ws = wb.Worksheets[1];
ws.Name = "Copy 2";
ws.Cells[2, 1].Value = "Copy 2";
using (var file = System.IO.File.OpenWrite("Copy 2.xlsx"))
{
ep.SaveAs(file);
}
}
}
This example assumes that you already got excel bytes array and you need to make clones out of it. The example uses ExcelPackage.GetAsByteArray to get the bytes array of the original Excel but you can get them by any other means, such as reading the bytes of an existing Excel file. The point being, is that you already hold the byte[] before cloning.
byte[] excel = null;
using (var ep = new ExcelPackage())
{
var wb = ep.Workbook;
var ws = wb.Worksheets.Add("Original");
ws.Cells[1, 1].Value = "Value from original workbook";
ws.Column(1).AutoFit();
excel = ep.GetAsByteArray();
}
using (var ep = new ExcelPackage())
{
using (var ms = new MemoryStream(excel))
{
ep.Load(ms);
}
var wb = ep.Workbook;
var ws = wb.Worksheets[1];
ws.Name = "Copy 1";
ws.Cells[2, 1].Value = "Copy 1";
using (var file = System.IO.File.OpenWrite("Copy 1.xlsx"))
{
ep.SaveAs(file);
}
}
using (var ep = new ExcelPackage())
{
using (var ms = new MemoryStream(excel))
{
ep.Load(ms);
}
var wb = ep.Workbook;
var ws = wb.Worksheets[1];
ws.Name = "Copy 2";
ws.Cells[2, 1].Value = "Copy 2";
using (var file = System.IO.File.OpenWrite("Copy 2.xlsx"))
{
ep.SaveAs(file);
}
}
You might need to open an existing .xlsx Excel file in memory for reading and writing. As you recall, this file is nothing more than a zip file of an XML files. For this purpose you are going to need a zip library that handles zip files. I opt to use DotNetZip because EPPLus itself uses this zip library internally but that doesn't mean that other zip libraries can't open EPPLus-generated Excels: a zip file is a zip file.
PM> Install-Package DotNetZip -Version 1.10.1
The next two examples assume there is an existing byte[] excel but this file doesn't necessarily have to generated with EPPlus. It can be created from Excel program or by other .NET Excel library (ClosedXML). The point is, these examples work regardless of EPPLus.
This is a template code to modify an existing Excel in memory. It is important to note that the original Excel (byte[] excel) stays intact. When the file is loaded to Ionic.Zip.ZipFile, it essentially creates a new zip file in memory. Any further modifications are solely performed on the new zip file.
byte[] excel;
byte[] excelNew = null;
using (var zipStream = new MemoryStream(excel))
{
using (Ionic.Zip.ZipFile zipFile = Ionic.Zip.ZipFile.Read(zipStream))
{
using (var outStream = new MemoryStream())
{
zipFile.Save(outStream);
excelNew = outStream.ToArray();
}
}
}
System.IO.File.WriteAllBytes(@"C:\excelNew.xlsx", excelNew);
This code opens an Excel file in memory, extract each XML file to XmlDocument and pretty-print it to an output folder with System.Xml.XmlTextWriter. The XML will be indented by a single tab character and the XML file will be UTF-8 encoded.
byte[] excel;
string outputFolder = @"C:\";
using (var zipStream = new MemoryStream(excel))
{
using (Ionic.Zip.ZipFile zipFile = Ionic.Zip.ZipFile.Read(zipStream))
{
foreach (Ionic.Zip.ZipEntry zipEntry in zipFile)
{
XmlDocument xdoc = new XmlDocument();
using (var ms = new MemoryStream())
{
zipEntry.Extract(ms);
ms.Position = 0;
xdoc.Load(ms);
}
string outputPath = Path.GetFullPath(
Path.Combine(outputFolder, zipEntry.FileName)
);
string directory = Path.GetDirectoryName(outputPath);
if (Directory.Exists(directory) == false)
Directory.CreateDirectory(directory);
using (var writer = new System.Xml.XmlTextWriter(outputPath, System.Text.Encoding.UTF8))
{
writer.Formatting = Formatting.Indented;
writer.Indentation = 1;
writer.IndentChar = '\t';
xdoc.Save(writer);
}
}
}
}
If you need to send .xlsx Excel file to the client, it is important that you set the right content-type and content-disposition response headers. Mind that these headers are different if you send other excel types such as .xls file (EPPlus doesn't create that) or .xlsm (Excel with VB code. The "m" stands for macro). This is a short but certainly not exhaustive list of Excel file types and their content type.
- .xlsx application/vnd.openxmlformats-officedocument.spreadsheetml.sheet
- .xlsm application/vnd.ms-excel.sheet.macroEnabled.12
- .xltx application/vnd.openxmlformats-officedocument.spreadsheetml.template
- .xls application/vnd.ms-excel
byte[] excel;
string excelFileName = "MyExcel.xlsx";
string contentType = "application/vnd.openxmlformats-officedocument.spreadsheetml.sheet";
string contentDisposition = string.Format("attachment; filename=\"{0}\"",
System.Uri.EscapeDataString(excelFileName)
);
System.Web.HttpResponse response = Page.Response;
response.ContentEncoding = System.Text.Encoding.Unicode;
response.ContentType = contentType;
response.AddHeader("content-disposition", contentDisposition);
response.BinaryWrite(excel);
response.Flush();
response.End();
This article should serve only as a jumping point to create your own Excels. You have to bend it to your needs and that takes work. Not everything is possible with EPPlus but I tried to cover the scenarios that you are more likely to encounter. I also tried to show in details the process of hacking with Open XML, how to look for it on MSDN and then rewrite the Excel accordingly. Some hacks are going to be obsolete as newer versions of EPPlus are released but you still have to roll up your sleeves and dig in.

