Introduction
The algorithm is described in the published paper "Concave Hull: A k-nearest neighbours approach for the computation of the region occupied by a set of points" by A. Moreira and M. Santos, 2007, University of Minho, Portugal.
I achieved significant performance gains over the unoptimised algorithm. I recognised that the algorithm would benefit from a C++ implementation using the Flann library for the k-nearest neighbour searches and OpenMP parallelism for point-in-polygon checks. This article demonstrates my findings such as what affects the computation time.
My curiosity is on performance when the datasets get large. I use ground point datasets such as those from aerial Lidar scans as test datasets. My program is lightweight and depends only on Flann.
Examples
The examples below each show a set of points where the blue polygon is the computed concave hull.
Example 1: 771 input points, 166 concave hull points, 0.0 seconds to compute.
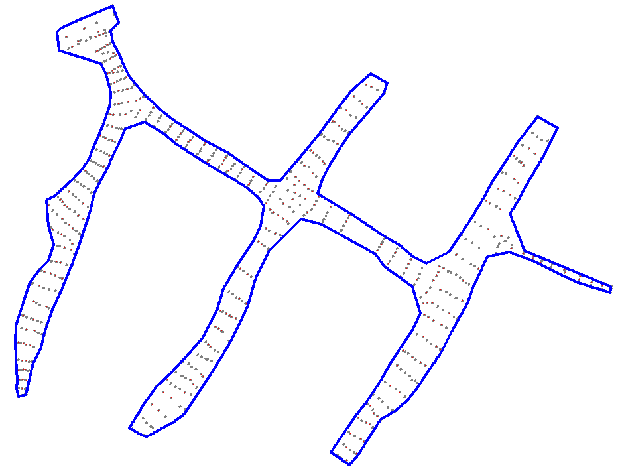
Example 2: 4726 input points, 406 concave hull points, 0.1 seconds to compute

Example 3: 54323 input points, 1135 concave hull points, 0.4 seconds to compute
Example 4: 312428 input points, 1162 concave hull points, 26.0 seconds to compute (see section Analysis below)
How it works
The Moreira-Santos algorithm is an iterative solution, where an initial nearest neighbour K-value is set to 3 and iteratively increased until a polygon is found that encloses all the points. That is the concave hull. Increasing K further will smooth out the hull but perhaps making it less aesthetically correct.
When K=3 is used by the k-nearest neighbour search it means the three closest points to any test point are found. Too small a K means an enclosing hull doesn't get found. Too large a K might mean important concavities in the hull are smoothed over.
The algorithm stops on the first K that produces a valid concave hull. My program has a command line parameter to pass a higher K to produce a smoother polygon if so desired. Ideally there would be some visual inspection to determine whether the first K which determines the hull is sufficient, or whether an increased K gives a more pleasing result.
See the section Finding Performance below on where I achieved performance gains over the unoptimised algorithm.
Analysis
The time to compute the hull starting with K=3 increases fairly linearly with the number of input points. However other factors do affect the absolute running time. Because of these factors, one dataset of n points will not compute in the same time as another set of n points.
The number of input points
All the points need to pass a point-in-polygon test for the iteration to stop. Therefore the more input points there are, the slower this test will be. I try minimise this by parallelising the input to the point-in-polygon test.
The point spacing near the edge, whether uniform or having large variations
The geometry of the points near the edge has an impact on the K iteration. If the edge is "messy", more neighbouring points (K) will need to be inspected than if the edge has little variation in point density and spacing. A regular grid of points will have a faster computation time than a disordered and irregular point set. Example 4 above is an example where K needs to reach 50+ before completion because of very irregular point spacing.
The number of iterations of K needed to reach a solution
The more iterations there are as a result of (2) above, the more times the point-in-polygon test probably has to be done, this being one of two iteration step criteria. (See a possible optimisation in the section Finding Performance below.)
The size of the hull polygon
The point-in-polygon test will be slower for hull polygons with many vertices than if the polygon is smaller, though this is less important than the number of points passed to the test.
The bottleneck
In my code, after many performance gains (see section Finding Performance below), profiling shows the biggest bottleneck to be the point-in-polygon check. This test is the stopping condition for the iteration. If any points in the dataset are not inside the polygon computed in that iteration, then K is incremented. So the point-in-polygon test is crucial, but expensive.
Benchmarks of large examples
My emphasis is on large input datasets. Here follows three examples where I have test cases in increments of 100,000 up to one million. This is to compare the affect of input point size and the number of iterations of K have on computation time.
Large Example 1: 995165 input points, 5221 concave hull points, 10.7 seconds to compute.
Large Example 2: 984119 input points, 4907 concave hull points, 16.8 seconds to compute.
Large Example 3: 998817 input points, 8787 concave hull points, 31.1 seconds to compute.
This algorithm could still be useful for a large dataset if it is first downsampled to a more manageable size, and only then the concave hull computed. This would only be an option though if the concave hull needn't be accurate to the original dataset's edge.
Above timings were made on a Core i7-2600 @3.4 GHz, 16GB RAM, Windows 10.
Finding performance
Perfomance gains I found listed in order of impact:
- Using Flann for the nearest neighbour point searches gave me the most immediate performance boost.
- The algorithm in the paper requires frequent deletions of points from the dataset. Initially, by doing the same using
std::vector::erase I found to be a major bottleneck. I did away with that storage entirely as the Flann way is already storing points and capable of marking points as deleted. - Testing whether any points fail a point-in-polygon check is an ideal candidate for parallelising. I used an OpenMP parallel implementation of
any_of. - Along with the 2D coordinate I also store a unique ID for each point which stays sorted and allows me to binary-search for a point ID rather than searching by value semantics.
Optimisations I foresee as being possibly worthwhile, but were not attempted:
- The final K could be found faster by instead of incrementing K only by 1, a bigger increment could be chosen to find a valid, but overly smoothed polygon quicker, and then K decremented to converge in a binary-search type manner.
- Keep a count of the number of times each point has passed the point-in-polygon test and then sort by this number to first test those that have never passed in a previous iteration. The idea being that if it has passed before, it'll probably pass again.
Using the code or program
Building the code
Other than the Flann library calls and a little OpenMP, the code is standard C++ with a heavy reliance on STL algorithms. Flann also needs to be separately installed, but thereafter it is just a header-only include. I built this with Visual Studio but it will build with any C++11 compliant compiler.
Running the executable
If you get a system error stating the program can't start because VCOMP140.dll, MSVCP140.dll or VCRUNTIME140.dll is missing, then you need to download and install the Microsoft Visual C++ 2015 Redistributable.
The command line usage of is as follows:
Usage: concave.exe filename [-out arg] [-k arg] [-field_for_x arg] [-field_for_y arg] [-no_out] [-no_iterate]
filename (required) : file of input coordinates, one row per point.
-out (optional) : output file for the hull polygon coordinates. Default=stdout.
-k (optional) : start iteration K value. Default=3.
-field_for_x (optional) : 1-based column number of input for x-coordinate. Default=1.
-field_for_y (optional) : 1-based column number of input for y-coordinate. Default=2.
-no_out (optional) : disable output of the hull polygon coordinates.
-no_iterate (optional) : stop after only one iteration of K, irrespective of result.
The only required parameter is filename of input coordinates. The fields in the input file can be comma, tab or space delimited. Adjacent spaces are treated as one. By default the first two fields are used for x and y, but this can be changed with the -field_for_x and -field_for_y parameters. Output of the hull coordinates is by default to stdout, but can be directed to a file with the -out parameter. In this case output is space delimited unless the filename has a .csv extension to make it comma delimited. The parameters of -k, -no_out and -no_iterate are mostly for analysis/testing purposes but are self explanatory.
Comparison with alpha-shapes
Alpha-shapes are the usual mentioned way of determining concave hulls. C++ implementations of alpha-shapes are available in CGAL, PCL (Point Cloud Library) and LASLib. However these either have commercial unfriendly licensing requirements, or very onerous build dependencies that are prohibitive if otherwise not needed.
I still did compare the performance of my program with PCL's alpha-shape implementation pcl::ConcaveHull<>. I found the Moreira-Santos algorithm to compute the concave hull mostly faster than PCL alpha-shape. I did not attempt to look for speed optimisations with the PCL code, and perhaps better performance could be had with more experience with PCL.
Just like with this algorithm, the alpha-shape computation is also an iterative solution where an initial guess for α is increased or decreased repeatedly until one polygon is found and that is the concave hull. A fair comparison between the two should therefore be a single iteration only for both. i.e. a final K-value vs. a final α value. That is what I show here for the above three large examples:
Conclusion
- The Moreira-Santos algorithm is very attractive especially if the dataset size is fairly small, say in the tens of thousands.
- When datasets are in the order of many hundreds of thousands or millions as is typical with Lidar data, then the algorithm will need further optimisations over and above what I achieved.
- The bottleneck is the iteration criteria of all points passing a point-in-polygon test. A faster point-in-polygon test, or more selective use of it, would improve performance.
- My implementation of the algorithm is lightweight and depends only on Flann. It doesn't really satisfy my requirements of large datasets, but it might prove useful to others.
References
- The Moreira-Santos paper: Concave Hull: A k-nearest neighbours approach for the computation of the region occupied by a set of points.
- FLANN - Fast Library for Approximate Nearest Neighbors
- PCL - Point Cloud Library
- Civil Designer was used for the screenshots.
History
Aug 2017: Initial post.

