Due to the nature of my current development projects, I have gotten away from heavy SQL programming, which I did quite often when working in the many corporations I was employed by during my long career in professional development as a software engineer. As a result, with one of my new development efforts, I was somewhat at a loss at trying to remember how I had implemented a complex tree structure with a SQL Server database for a project I was developing back in 2010.
To the rescue for that effort came Joe Kelko who was kind enough to correspond with me regarding some of the tree-based SQL code he had developed and I had picked up from one of the public, technical sites it had been posted to. Joe is often seen by many development professionals as the last word in database query\action SQL code. Using his work, I was able to complete my project, which implemented a very complex hierarchy of my client company’s organization that was so large that the graphical output I was using for the interface blew the then current memory constraints of the machinery. To get around this issue, I simply forced the user to select a portion of the organization for display.
Most development projects do not require such extensive complexity to be applied to their database projects but when it does crop up, it is usually in regard to the loading of a tree-view control’s data as well as its manipulation. To this end, I believe I have come up with a basically primitive but easy-to-implement solution that incorporates some of the complexities that are often provided in the various documents and solutions that can be found on the Internet, without the more difficult SQL coding involved.
A Key-Sequence Table
Solutions that can be found to this perplexing type of implementation are often of two schools; some suggest the use of two tables while others rely on a single parent\child node table, the former probably suggested for more complex scenarios than the needs of populating a tree-view component. As a result, my solution uses two tables but not for the complexity such solutions refer to but instead one table is used for key sequencing while the other manages the parent\child nodes.
One could ask why would a table be required for key-sequencing when database engines provide for using identity keys, auto increment functionality, or even in some cases, sequences? This would be a very good question but in the case of the Firebird Database Engine, which I am using in its embedded version for two of my projects, such key sequencing features do not seem to work or at the very least, no amount of tinkering on my part could get such a feature to function properly.
As I have written in other pieces on the subject, Firebird is a very idiosyncratic engine for several reasons. On the one hand, there appears to be quite a bit of European influence on this engine’s development considering that it is supposedly quite popular on the other side of the Atlantic from the States. One will find the same with PostgreSQL even though it is based on the US developed Ingress Engine. So what we in the States would see as idiosyncrasies would merely be the European way of doing things. This is all fine and good.
The other issue, which has nothing to do with what continent has influenced Firebird’s development is the rather poor support for such a well designed database engine. There are no community forums on the Firebird site, though the site does provide the older style of email lists as its form of community. As I have mentioned in other pieces, the Firebird developers have taken the Open Source concept just a little too far, in which they are of the belief that Open Source projects really do not need support since the code is always available. To take this a step further, with the exception of a single well documented PDF manual for their database, there is little really good written material on this engine outside of the Helen Borrie manuals, which were updated in 2013.
So why even bother with Firebird? Because in lieu of anything else available to desktop application developers, it is the best desktop database engine currently available for which the code can be just as easily used against its server version with the only requirement being for a change to the connection string.
So if a desktop database engine is what you require and you do not want to use SQLite, Firebird is it and if you can work with the inherent difficulties in understanding how to use this engine, it will provide you with far more capabilities than SQLite can.
But again, right now, no key-sequencing capabilities. In our case then, we need a sequence table that will provide unique keys for every level of a hierarchy you may require in your tree-view display. As a result, our sequence table will look somewhat like the following…
CREATE TABLE RI_CATEGORY_KEY_SEQUENCES (
CKS_CATEGORY_SEQ_KEY_1 BIGINT NOT NULL,
CKS_CATEGORY_SEQ_KEY_2 BIGINT NOT NULL,
CKS_CATEGORY_SEQ_KEY_3 BIGINT NOT NULL,
CKS_CATEGORY_SEQ_KEY_4 BIGINT NOT NULL,
CKS_CATEGORY_SEQ_KEY_5 BIGINT NOT NULL);
In this table definition, I have defined 5 sequence keys because the project I am developing will be limited to only five hierarchical levels. You may add as many levels as you may require without any concern for any amount of records since only one record will be required to maintain unique key- sequence counters.
Despite the perceived primitiveness of such a design, it does in fact work quite well. You can manage such a table in two ways…
- You may use ADO.NET with the Firebird .NET Provider, which you can easily avail yourself of by using my Firebird Data Access layer, which can be freely downloaded from the following link… https://blackfalconsoftware.com/software/
- Or you may use a stored procedure, which Firebird provides for, even with its embedded database engine, providing it an unprecedented level of capability.
In both cases, for each key sequence\level you require, you will have to do the following…
- Select the key-sequence field for the hierarchical level you require a new key for
- Add
1 to this sequence number - Update the key-sequence field with the new sequence number
- Return the new sequence number to the calling process
In both cases, you should wrap this process within a transaction even though it is being processed on an embedded database. Transactional processing “single threads” the complete session, queuing up other requests until the transaction has completed. This then will allow you to safely move such processes to a server-based database engine if need be, irregardless of the engine brand.
The Hierarchy Table
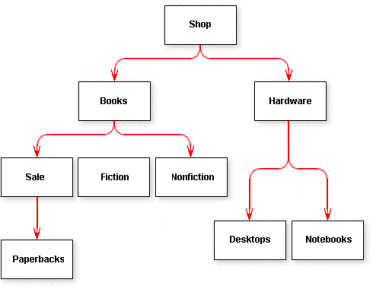
If you are going to use the Firebird Database Engine for your requirements, then as described previously, a key-sequenced table will at this point be required to provide you with unique keys for each level of your hierarchy. With that completed, we can now move into the design of a simple hierarchical keyed table that will allow you to get complete sections of a hierarchy for each master key-sequence level in the table. With this table design, we will also use a field entitled, “Depth”, in order to keep track of where each set of records in a hierarchy belong. So for example, the “Depth” field will depict segments of a hierarchy as the following graphic illustrates…

The resulting table definition will then look as follows (You may define the table with table and field name to your preference.)…
CREATE TABLE RI_CATEGORY_NODES (
CN_KEY BIGINT NOT NULL,
CN_PARENT_KEY BIGINT NOT NULL,
CN_ROOT_KEY BIGINT NOT NULL,
CN_DEPTH INTEGER NOT NULL,
CN_CATEGORY VARCHAR(500) NOT NULL);
Each field in this table is used for the following…
CN_KEY
- A unique key for each record
CN_PARENT_KEY
- A key that represents the parent record for any record in the table; The parent key of a master record will always be zero, or if you prefer,
NULL
CN_ROOT_KEY
- The key that represents the top-most record in any hierarchy set of records; This allows for the easy selection of hierarchy segments through the use of a single master record key
CN_DEPTH
- The number that defines where in the hierarchy the record falls
CN_CATEGORY
- The name of the hierarchy item\level
Manipulating The Hierarchy Database
At each point in your processes, you will know what you are inserting into the hierarchy\nodes table just described. So for example, if you are going to add a master record, you would follow the pseudo-process outlined in the section, “A Key-Sequence Table”, which in this case you would request a new master level key from the field, “CKS_CATEGORY_SEQ_KEY_1” and insert it into the hierarchy\nodes table with the following sample values…
CN_KEY = Newly derived key-sequence number (“CKS_CATEGORY_SEQ_KEY_1”)CN_PARENT_KEY = Always zero(0) for a master level key-sequence numberCN_ROOT_KEY = The same number as placed into the “CN_KEY” fieldCN_DEPTH = Always zero(0) for a master level key-sequence numberCN_CATEGORY = Whatever description\name you want to provide to your level
This is all well and good for master level node records but what about when you begin inserting records that are moving down in the hierarchy; let’s say in this case, level 2 or a depth of 1?
CN_KEY = Newly derived key-sequence number “CKS_CATEGORY_SEQ_KEY_X”CN_PARENT_KEY = The key of the immediate parent record that the level will fall underCN_ROOT_KEY = The same number as placed into the “CN_KEY” field of the corresponding master level recordCN_DEPTH = The number of the level the record is being inserted for (i.e.: 1)CN_CATEGORY = Whatever description\name you want to provide to your level
You will have to provide the processes that will store (in memory) and retrieve (from the database table) the key-sequence numbers you require to populate subsequent levels in your hierarchy.
You will also have to provide processes that will both modify and delete varying levels in your hierarchy. Modification (if you are moving records around in the hierarchy) will require that you delete and re-insert the selected record into the hierarchy since the “CN_KEY” field should be denoted as a primary-key field. Deletions can be easily done by “CN_KEY” for a specific record or by “CN_ROOT_KEY” and “CN_DEPTH” for groups of records in a hierarchy.
Retrieving such data has always been the most difficult aspect of such development and the more complex the SQL code for a solution, the fewer the database calls you will have to make. In this case, we are trading ease of retrieval for difficulty in implementation. This solution is just the opposite which provides for simplicity of implementation while making database access less efficient.
However, in most cases, you will always be working with sections of a hierarchy so we can break down the database call types to the following…
- Retrieve all master level records and store their “
CN_KEY” sequence numbers in an array or array-list
- Retrieve all records for each master level by rolling through the master level key-sequence array\array-list with the following SQL code…
SELECT RICN1.CN_KEY,
RICN1.CN_PARENT_KEY,
RICN1.CN_ROOT_KEY,
RICN1.CN_DEPTH,
RICN1.CN_CATEGORY
FROM RI_CATEGORY_NODES RICN1
WHERE RICN1.CN_KEY = @MASTER_KEY_PARAMETER
OR RICN1.CN_ROOT_KEY = @MASTER_KEY_PARAMETER
ORDER BY RICN1.CN_DEPTH,
RICN1.CN_KEY
As you retrieve each major section of your hierarchical data, you can then populate your tree-view control\component using the depth indicator to determine, which records data goes where but always using the master record with a parent-key of zero(0) or NULL as the record that is inserted directly under the embedded root in a tree-view control.
As a result, using the above query will provide data from the following table…
… in the following manner for the master “CN_KEY” of 3…
Conclusion
No matter how you implement hierarchical data for your applications, you are going to have some work to do since we tend to use relational database engines and not hierarchical ones that would make such implementations significantly easier. A good example of this is the underlying database for Microsoft’s Exchange Server, which uses such a database.
My presented solution here is by no means considered an optimal solution in any case. However, it is somewhat simplistic to implement and if you have been away from hardcore SQL coding for a while, it will take some of the pain out of having to relearn such complexities.
In any event, if you have any suggestions, comments, or criticisms on this presentation, I would be more than happy to hear them. And alternative solutions that you may provide can be viewed as an addendum to a future piece on the subject with credit going to the person who submitted the solution…

