This is the second in a series of articles demonstrating how to build a .NET AI library from scratch. This article gives an introduction to machine learning.
Series Introduction
This is the second article of creating .NET library. Below is link for Part 1:
My objective is to create a simple AI library that covers a couple of advanced AI topics such as Genetic algorithms, ANN, Fuzzy logics and other evolutionary algorithms. The only challenge to complete this series would be having enough time to work on code and articles.
Having the code itself might not be the main target however, understanding these algorithms is. Wish it will be useful to someone someday.
The series will be published in a couple of parts, I am not sure how many yet. Anyways, each part will focus on a single key topic trying to cover for good.
Please, feel free to comment and ask for any clarifications or hopefully suggest better approaches.
Article Introduction - Part 2 "Machine Learning Introduction"
I thought that it would be more beneficial to introduce separate article for basic definitions used in machine learning as we will use such definitions later in following articles.
Most of this article will be dedicated to the concept of ML and different terms, there are tons of online resources that can be referenced for further information.
What AI Really Means
Before discussion of ML, let's first define what AI really means and to consider AI definition as a starting point for way forward.
There are many definitions for AI based on application or problem being resolved, however the simplest definition to fit all could be "AI is the ability of creating machines that could take decisions without being explicitly programmed for" in other words "Building machines (or applications) that have some kind of self intelligence in form of taking decisions".
Here is a Wiki article about that.
The need for AI started when humans started to face very complicated problems that are very hard to be programmed in advance. For example, consider self driven vehicles. This is a very complicated task if the only approach is to program each and every scenario that a vehicle may face. Practically, this would be almost impossible.
Hence, clearly we need more special approaches (algorithms) that could impose some kind of intelligence to a vehicle's main processor.
Consider raising a baby, of course, at the beginning, you would explicitly guide and provide instructions however at some stage, due to human intelligence; the baby will start to learn from experience (whether good or bad experience), so learning is a very essential component to intelligence, and hence, an ML term is always associated with AI.
What Machine Learning Means
Simply, ML is an AI field that studies one problem "How machines or applications can auto-learn from experience?"
ML is a set of techniques, algorithms and/or tools used to form learning process and eventually AI portion of any machine.
Back to baby analogy, one way to teach a baby is by giving examples or putting him into an experience. same in ML, that is called "Supervised Learning" which means that we train a machine first by giving training sets.
Each training set shall be composed of the same set of inputs along with the correct answer (called label). Utilizing different algorithms, a machine can iterate through all training sets and start to learn and build AI then; shall be ready to predict (provide estimated output) for any similar number of inputs or take a decision.
But this is not the only type of ML, there are other two common types:
Unsupervised learning - in which there is no training set available, this is used for specific type of problems that will mention laterReinforced learning - is another type of ML, there is no training set, however machine will receive feedback based on accomplished target. for example, for AI application playing chess, feedback could be wining or losing the game.
Let's go through the details of each type and how it could be used.
Supervised Learning
Again, this is when we do have available training set that we use to train our machine (this is where term supervised is coming from). Maybe, this is the time to have real case example such as classical example of Building an application to estimate price of an apartment based on area.
This is a very classical example used in many AI references to explain the concept and I will use the same.
So, to build such an application, we will need a set of combinations representing flat area against price. Of course, real scenario price will have multiple factors, as location, number of rooms. However, for simplicity, we will consider other factors as constants and have no impact on price.
This is a supervised learning because we start with available data, and our target would be creating an application to learn from this data and even get more intelligent by having further experience (getting further combinations of area vs price).
Eventually, this application would expect inputs (flat area, single input) and predict output (price) which is a continuous number, these are the kinds of problems that are called "Regression" in AI.
You may think of regression as an optimization function or finding best-fit function mapping inputs to output. In algebra, there is a term called "Interpolation" which is mainly the same concept, finding a best-fit function for given set of inputs and outputs.
Of course, this mapping could be in linear or no-linear forms (based on complicity of problem). Linear regression is the simplest and it represents mapping function as linear or straight line. For AI terms, mapping function is called hypothesis or h function in form of h(x) = a + b * x where:
X is the input(s)a & b are slope of the lineh(x) is the hypothesis function of inputs, or simply estimated output
Let's name the correct answer of any given training set as y, then error would be simply the difference between estimated answer (hypothesis) and correct answer e = h(x) - y.
Logically, this error shall be minimized as much as possible to ensure fulfilling best-fit part. Error minimization is a whole study area with many algorithms that I will continue discussion later at this article.
Now back to supervised learning, we have seen that regression is one application of supervised learning but it i s not the only one. Remember, regression works with continuous (or real) outputs. what about discrete outputs cases, for example, if we do have training set for couple of inputs and output is simply grouping the inputs to pre-defined groups or namely Classification which the second major utilization of supervised learning.
UnSupervised Learning
On the other hand, unsupervised learning does not have pre-given training set, just a set of inputs without labels (remember label is the correct answer) this kind of ML is used for specific set of problems where we cannot really label inputs or pre-program it. Let's have an example from social media. for example, recommendation list from YouTube or recommended friends from Facebook.
Unsupervised ML could be behind this kind of AI, where for each user; watch history or friend list are reviewed and sorted. This is called Clustering problems in AI. You can imagine that there is no way to program these recommendations for each user in advance.
Reinforced Learning
For the third type, it is some kind of special supervised version where machine learns from the outcome or simply its own experience. It is learning from the feedback of the output (as winning or loosing a game or reach a destination).
As an example, consider building application to play chess. from one end, there is no way to program all possible moves at any given time. and on the other end, if we managed to build the application to play each game and learn from winning or losing the game, then this is reinforced learning type.
What is Next
Above are mainly the fundamentals about ML and based on that, tons of algorithms and techniques are built to establish each type and solve different problems accordingly.
It is important to understand it as that will help in understanding any further advanced topics related to AI.
The next way forward would be exploring different algorithms and approaches, hopefully to understand AI further.
So this would be time to build our first AI algorithm with code.
Linear Regression Example
Let's create one application to solve a simple linear regression problem. Regardless of the technical background of the application or exact problem we are trying to resolve, the algorithm is always the same. Hence, we will not worry much about what this data is, but assume we got it somehow. Here is the data in hand:
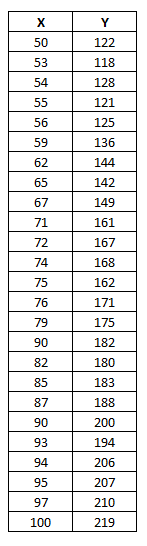
Where X is the input (could be any real variable) and Y is the correct target or label. Plotting this data set will result in:

The objective of the application is to predict let's say output incase x is 70 based on given training set.
Based on the given data set, looks like linear regression would be an acceptable solution for this problem. Hence, the application will mainly resolve the hypothesis function h(x) = a + b * x , in other words, to find the values of a and b that yields to best fit line.
Let's build the algorithm for that, first will start with any random values of a and b.
Now, we need to minimize error to the lowest possible value but first, let's get rid of -ve errors, errors can be in both directions positive or negative. One way to do so is by squaring the summation of error.
Some errors are higher than others based on the difference between correct answer and h(x) to ensure that most of the errors are targeted, let's take the average or mean of squared error which equals squared error/size of training set.
As per Statistics terms, this method is called "Mean Squared Error" or MSE and it tells you how close a regression line is to training set.
Some references, may refer to MSE as cost function which is a broader definition
Where m is the size of training set (how many training combinations)
As this is 2nd order polynomial equation (assuming one variable) so in 2D coordinates, this is the graph
From the above graph, clearly this function has only one min (we cannot tell by now where this min is). In other words, the above graph tells us that if we started with any random values for a and b, we will have an error anywhere on the above graph and from there, we need to move to min.
At the below graph, Blue point represents min error value, for any random a & b values we may end on right side (as red circle) or left side (as green circle).
The question is how to determine which side we are on the curve? right or left?
One way to determine direction is to draw a straight line that is touching with curve at the starting point and then calculate the slope of this line.
For example, a red line in the above graph has +ve slope (as moving to right, value on line increases) however green line has a -ve slope.
Let's revisit our pseudo algorithm:
Above is a very common and handy algorithm that is called Gradient Descent. However, the above version is valid mainly for linear regression, for nonlinear functions other considerations shall be taken.
So, how can we calculate the slope of a straight line?
Slope of line touching the function (curve) at certain point is exactly the definition of derivative of function. In our case, as we are having two variables (a & b), this is called a partial derivative.
Gradient Descent
So far, we have the following:
Let's start to resolve a:
To cut a long story short, here is the final partial derivative for a:
and here is for b:
Then:
To further control the step taken, let's add a small number representing the step size to take as fraction of slope. this is called "Learning Rate". Having improper value for learning rate can impact final behavior for our algorithm and we shall examine different values in our code.
Anyways, let's mark it as r:
similarly for b:
Above last 2 equations represent the final conclusion from applying Gradient Descent to linear regression.
Using the Code
To demonstrate the above, I have created a simple program:
The main function is Train, it accepts two 1D matrices representing training set:
Public Sub Train(_Inputs As Matrix1D, _Labels As Matrix1D)
Dim m As Integer = _Inputs.Size
Dim Err As Matrix1D
Dim Counter As Integer = 0
Dim Best_a, Best_b As Single
If _Inputs.Size <> _Labels.Size Then
Throw New Exception("Both Inputs and Labels Matrices sizes shall match.")
End If
Randomize()
Do While Counter < 100
Dim h_Matrix As New Matrix1D(m)
Err = New Matrix1D(m)
For I As Integer = 0 To m - 1
h_Matrix.SetValue(I, Hypothesis(_Inputs.GetValue(I)))
Next
Err = h_Matrix.Sub(_Labels)
If CalcCostFunction(Err) < min_MSE OrElse Counter = 0 Then
min_MSE = CalcCostFunction(Err)
Best_a = a
Best_b = b
End If
a = a - r * (1 / m) * Err.Sum
Err = Err.Product(_Inputs)
b = b - r * (1 / m) * Err.Sum
Counter += 1
Loop
a = Best_a
b = Best_b
End Sub
It implements pseudo algorithm of gradient descent.
There are different ways to terminate the iteration, I have selected one technique by setting max counter of 100 while keeping recording minimum MSE in each iteration along with Best_a and Best_b variables.
Lastly, I need to mention that sample software has reference to CommonLib which is added at the beginning of the article (the attached version is the most updated one).
Recap
We defined three types of ML:
Supervised learning - with available training set, mainly used for regression and classification problemsUnsupervised learning - no training set is available and is typically used for clustering problemsReinforced learning - where there is no training set, but the machine learns by outcome or feedback of every experience
Then, we have detailed one key Algorithm of Gradient Descent typically for linear regression giving 1 sample software.
I am not sure if the above was clear enough, please let me know.
Next Article
Mostly, it will be about the second use of supervised learning which is classification, typically using Perceptron.
History
- 10th September, 2017: Initial version

