An article about the elementary school sum algorithms applied to computer hardware, using different techniques for carry detection.
This article is part of a series of articles:
Multiple Precision Arithmetic: A recreational project
Introduction
A computer operates on numeric values up to a given size. At the time of writing, 64 bit arithmetic can be found on cheap hardware. But there's a fixed limit, if you need to operate above that limit, you must use an algorithm to instruct your computer how to do, it is not “out of the box”.
On this series, I will share my knowledge and also some code. My goal is to write a minimal collection of working arithmetic algorithms and share them with as many fellow programmers as possible. It is not my objective to create a serious library, outstanding MP libraries for many languages exist written by professional mathematicians out there.
The series is divided into four background articles, then the last article will explain how to use my code just in case you want to challenge my "reference" implementation of the simple arithmetic operations.
A real MP library will need to implement a lot more, will handle negative numbers and fractions, polynomials, here I will cover the basic four arithmetic operations.
Long Numbers
To communicate a concept like "there're 12334 stones in that pot" without using Arabic numerals could be hard. Well it's hard using Arabic numerals too, but at least you get an idea of the order of magnitude of number of stones in a pot, better than communicate the concept by sending a picture of stones laid on a table, at least that's my opinion, this is why Arabic numbers are a superior tool; how great were those ancient mathematicians who discovered lot of mathematics without having Arabic numbers.
By the way, without having to dig too much into positional notation, we can observe that "12334" is not a number, it is a string of digits which represent a number in a very compact form, easier to handle for the brain than the picture of 12334 stones laid on a table. We can use that string to compare numbers, and to do arithmetic in a simpler way than using a bunch of stones (stones translate to calculi in ancient-romans-Latin words).
We learned at least four algorithms in our childhood to work on long numbers: long sum, long subtraction, long multiplication and long division, better algorithms do exists but we will start with them.
A Short Note
In this series, I will only focus on UNSIGNED arithmetics.
Background
The sum is one of the basic arithmetic operations. To sum a pair of numbers, you only need to know how to count. To sum 23+98 means to count 98 after 23. But when you have to calculate 100 000 + 133 212 you better use positional decimal notation and an algorithm that requires to count up to 10 (on base 10). We’ll call such algorithm the Long Sum Algorithm, we will use it because it requires less effort than counting.
We will now define a primitive operation, then we'll build the long sum algorithm.
Simple Sum Base 10 (Our Primitive Operation)
Let me define a name for the sum of numbers A and B, where A and B have 1 digit (where digit can have any base, eg: 10, 16, 64, 232): I'll call it simple sum, in base 10, you can compute it by counting up to 9.
Example 1:
3+3 = starting from first number after 3 (it’s 4) keep counting for 3 times: 4,5,6: so, the result is 6
Example 2: (what happens if the result requires more than 1 digit?)
Overflow
8 + 4 = starting from 9 keep counting for 4 times: 9, 10 (overflow: mark on paper that you have carry and continue counting from 1), 1, 2; so, the result is 2 and you have carry, the carry, if present, is always 1.
Some Interesting Properties of the Simple Sum
Regardless of the base b (e.g..: 10), if A + B >= b then:
- we have carry
- the result has 2 significant digits
- the most significant digit being 1
- the least significant digit is less than any of the operands, in other words, if A+B >= b, then result is two digit [1][R] where R<A and R<B (Appendix A1 if you need a proof).
And symmetrically if A + B < b then:
- we don’t have carry
- the result have 1 digit
- that digit will always be greater than or equal to any of the operands (Appendix A1)
Corollaries
- The result of a long sum has 0 or 1 digit more than the longest addend (facilitate allocation of space for the result).
- The leftmost allocated digit which holds the result, will always be 1 or 0 even when you sum 1 to the 2 digits result of a simple sum (means that you can always add carry from the previous operation without having to allocate new digits), let me explain better:
- We said that carry for A+B+1 is 0 for sure if A+B already had carry. For example: 9 is the greatest single digit number in base 10, if we sum 9+9 we get
- 9+9 = 18,
- we had overflow, thus most significant digit is 1
- least significant digit is 8
- you can safely add 1 to 8 without needing to have another overflow, thus leftmost can never be 2.
Caution: 4+5=9 if you add 1 you get a carry there, but the result is still 2 digits, having [1] to the left, that means that you may need to propagate the carry toward left, that makes it difficult to parallelize the sum algorithm.
- Important: If the lowest significant digit is less than any of the operands, then we have carry: if we sum single digits [A] + [B], the result is going to be [carry?] [R], we can infer the value of carry with the following expression:
- if R<A (R<B works too) then
carry = 1
else
carry = 0.
That means we can ignore the hardware carry flag, we can infer the carry comparing the lower digit of the result to any of the operands.
Long Sum in Base 10
To sum numbers with more than 1 digit, we’ll apply a long sum algorithm.
I’m going to use the algorithm we learned at age of 6, to implement Long Sum on the CPU.
That is a serial algorithm, I think it is possible to tweak the above interesting properties to create a parallel algorithm to be used on SIMD hardware such as MMX on x64 CPUs or multi core GPUs, but that should be a new article, if I’ll ever go for it.
CPU Register Digit to Decimal Digit Analogy
To proceed further, we need to get the analogy between a decimal digit and a CPU register digit alias CPU word. From our point of view, a 64 bit word is no different than a decimal digit.
The long sum algorithm is the same for children and computers, the difference is only in the size of digits and the primitive simple sum used, which is counting up to ten for us humans, using the CPU builtin sum instruction for the software implementation.
Long Sum at the Digital Computer (the same as base 10 but using base 2integer_register_size)
The CPU can sum register sized digits (words). A modern CPU can sum 32/64/… bits with 1 clock cycle throughput. Our approach is to use register size digits and the CPU carry flag, or carry detection algorithm, instead.
The Algorithm
The algorithm here proposed is a high level overview of the actual algorithm, the idea is to split the long sum of A+B into a sequence of simple sums An+Bn, starting with the least significant digits of both numbers, we also have to propagate carry at each iteration. Possible optimizations are just plain ignored.
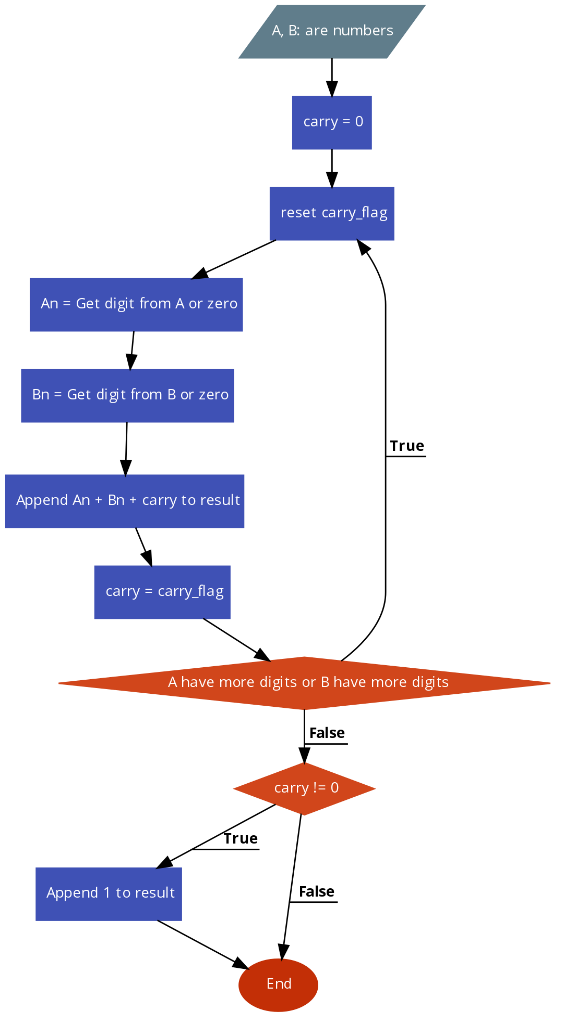
Carry Detection Variants
The above algorithm has a sub algorithm at point carry = carry flag, here we detect the carry from previous simple sum.
CPUs have hardware to detect and bit flag to indicate carry.
That CPU flag is generally not available to higher level languages, but carry can be obtained by using the property we discussed a little earlier.
There are four ways that I know to detect carry.
- Use the hardware carry flag.
- Use the property that (when doing An+Bn) carry is 1 if and only if (R < An or R < Bn) , this is tricky because we are no longer talking about R = An+Bn, we are talking about R = An+Bn+previous_carry. So the actual test is going to be: carry_flag = if(previous_carry = 1) (R <= An ? 1 : 0), else if(previous_carry=0) (R < An) ? 1 : 0, or by doing: carry_flag = (R < An || R < Bn) ? 1 : 0) that option tends to be the most portable and it is my preferred way of dealing with the carry, but performance-wise, we should measure both sub-variants. A hacky method, if the compiler supports it, to avoid branching could be: carry_flag = (R < An | R < Bn); that should work if the compiler produces expected code, unit tests (or look at disassembled code) can tell you if the generated code is actually working.
- Use a number system where you reserve the highest bit instead of the carry (e.g.: on 32 bits CPU, represent numbers as strings of 31 bits, which may also be useful if language does not provide unsigned types) but that's useless complication.
- If the high level language offers an integer type that is at least 1 bit larger than the register size, we can use this type to store R, the higher level language will automatically move the carry flag into the lowest bit of the higher word, I give two examples in C language of using that third variant:
#include <stdio.h>
typedef
union _reg_long {
dword_t DW;
struct _reg_words
{
word_t Lower;
word_t Higher;
} words;
} reg_long;
int main()
{
reg_log rl;
word_t R;
short prev_carry = 1;
short carry;
word_t An = ((word_t)-1);
word_t Bn = 0;
rl.DW = (dword_t)An + Bn + prev_carry;
carry = rl.words.Higher;
R = rl.words.Lower;
printf("New carry: %d, Result:%x", carry, R);
return 0;
}
dword_t rl;
word_t R;
short prev_carry = 1;
short carry;
word_t An = ((word_t)-1);
word_t Bn = 0;
rl = (dword_t)An + Bn + prev_carry;
carry = rl >> (8*sizeof(word_t)) ;
R = rl & ((word_t)-1);
printf("New carry: %d, Result:%x", carry, R);
Using Understanding the Code
For completeness, I am going to provide a C implementation of the algorithm, note how overflow (carry) can be detected when using high level languages without having to use carry flag. Interface is coarse, the idea is to have a primitive to construct more complex stuff; it needs to be as fast as possible so does not waste time on input checking or create nice data structures, that's not the responsibility of the primitive function. This may be wrapped by other code to generate a cleaner interface:
typedef unsigned long long reg_t;
reg_t LongSum(reg_t* A, reg_t ASize, reg_t * B, reg_t BSize, reg_t* R)
{
reg_t carry;
reg_t i;
reg_t min_a_b = ASize > BSize ? BSize : ASize;
carry = i = 0;
while (min_a_b > i)
{
R[i] = A[i] + B[i] + carry;
carry = R[i] < A[i] + carry ? 1 : 0;
++i;
}
while (ASize > i)
{
R[i] = A[i] + carry;
carry = R[i] == 0 ? 1 : 0;
++i;
}
while (BSize > i)
{
R[i] = B[i] + carry;
carry = R[i] == 0 ? 1 : 0;
++i;
}
if (carry)
R[i] = 1;
return i;
}
The slightly optimized “reference” version:
numsize_t LongSumWithCarryDetection
(reg_t* A, numsize_t ASize, reg_t * B, numsize_t BSize, reg_t* R)
{
register reg_t carry;
register numsize_t i;
reg_t min_a_b = ASize > BSize ? BSize : ASize;
carry = i = 0;
while (min_a_b > i)
{
R[i] = A[i] + B[i] + carry;
carry = R[i] < A[i] + carry ? _R(1) : _R(0);
++i;
}
while (ASize > i && carry == 1)
{
R[i] = A[i] + carry;
carry = R[i] == _R(0) ? _R(1) : _R(0);
++i;
}
while (ASize > i)
{
R[i] = A[i];
++i;
}
while (BSize > i && carry == 1)
{
R[i] = B[i] + carry;
carry = R[i] == _R(0) ? _R(1) : _R(0);
++i;
}
while (BSize > i)
{
R[i] = B[i];
++i;
}
if (carry)
{
R[i] = _R(1);
++i;
}
return (numsize_t)i;
}
I also attempted to do the same in Assembly x64, I am not good at assembler, but here’s my x64 code:
.data
.code
LongSumAsm proc
push rbp
mov rbp, rsp
push rbx
mov r11, rdx
cmp rdx, r9
mov [rbp + 20o], rdx
mov [rbp + 30o], r9
cmova r11, r9
clc
lahf
mov r10, qword ptr [rbp + 60o]
xor r9, r9
lea r11, [r11*8]
A_And_B_Loop:
cmp r11, r9
jle A_And_B_Loop_Ends
mov rbx, qword ptr [rcx + r9]
mov rdx, qword ptr [r8 + r9]
sahf
adc rbx, rdx
lahf
mov qword ptr [r10+ r9], rbx
add r9, 8
jmp A_And_B_Loop
A_And_B_Loop_Ends:
xor r11, r11
mov rdx, [rbp + 20o]
lea rdx, [rdx*8]
A_Only_Loop:
cmp rdx, r9
jle A_Only_Loop_Ends
mov rbx, qword ptr [rcx + r9]
sahf
adc rbx, 0
lahf
jnc A_NoCarry_Loop
mov qword ptr [r10 + r9 ], rbx
add r9,8
jmp A_Only_Loop
A_NoCarry_Loop:
mov qword ptr [r10+ r9], rbx
add r9, 8
cmp rdx, r9
mov rbx, qword ptr [rcx + r9]
jle A_Only_Loop_Ends
jmp A_NoCarry_Loop
A_Only_Loop_Ends:
mov rdx, [rbp + 30o]
lea rdx, [rdx*8]
B_Only_Loop:
cmp rdx, r9
jle B_Only_Loop_Ends
mov rbx, qword ptr [r8 + r9]
sahf
adc rbx, r11
lahf
jnc B_NoCarry_Loop
mov qword ptr [r10 + r9], rbx
add r9, 8i
jmp B_Only_Loop
B_NoCarry_Loop:
mov qword ptr [r10+ r9], rbx
add r9, 8i
cmp rdx, r9
jle B_Only_Loop_Ends
mov rbx, qword ptr [r8 + r9]
jmp B_NoCarry_Loop
B_Only_Loop_Ends:
sahf
jnc Prepare_to_return
mov r11, 1
mov qword ptr[r10 + r9], r11
add r9, 8
Prepare_to_return:
mov rax, r9
shr rax, 3
pop rbx
mov rsp, rbp
pop rbp
ret
LongSumAsm endp
end
Aftermath
Here is some speed comparison of assembly x64 vs C second “reference” version, my CPU is a 2011 quad core i7 3Ghz
C version compiled in release mode seems to be quite good, in sum of small vs big numbers is faster than assembly, but all other tests ASM is faster than C: numbers must be taken with a grain of salt because I am not sure I have everything under control here nor that the C algorithm is exactly the same as assembler because I wrote assembler from scratch not translating C code:
ASM 50% faster than C here (0,0125 secs vs 0,018 secs) VC++2019 on i7(2011)

But changed compiler (VC++2022) and computer (i9 2021), and now ASM slower than C on same test:
Here, they are almost equals, (0,64 seconds ASM vs 0,56 seconds C) but C version looks good on small number vs big one.
VC++2019 on i7(2011)
Same test on VC++2022 on i9(2021), the difference is even smaller, they are at par, no picture but... trust me.
Last test here below, this is serious because now we sum 2 very large numbers (33 million bits each).
This test ASM version is 4 times faster than C (VC++2019, i7 2011), maybe I forgot to start optimizer before that run, I no longer have that CPU so... I'll never know.
Same test on VC++2022, (i9 2021), huge improvement of the C version due to new compiler leveraging newer CPU.
Points of Interest
Some things are worth noting, ASM language seems to be faster when using hardware instruction which is not available in higher level languages such as C. These advantages are difficult to measure, because the C compiler is usually smart in creating machine code that tweaks CPU out of order execution and stuff. For arbitrary long numbers when long sum/sub/mu/div are involved, ASM is superior to C, but the interesting thing to note is that C is not that bad, it's quite good, I'd say that with new vc2022, the compiler is faster than ASM considering the fact that I am guessing the carry and not using the hardware carry flag.
The second thing to note is that I think a good C compiler, for a given platform, could provide a library of function that maps to hardware instructions (intrinsic), so can expose to developer the same hardware as ASM and, if the compiler is smart, that's enough to beat most of handwritten ASM implementation, in particular, if the ASM implementor is me.
Appendix A1
If we have an overflow in A+B, (A and B are single digits) in any base b, Result will be less than any of the operands
Doing the simple sum of A+B we obtain two digits result: Result (the least significant digit) and Carry (carry can only be equal to 1 or equal to 0 and it’s the most significant digit).
We want to show that when \(A+B \geq b\) then the least significant digit is less than both A and B, we can say it in other words as:
\begin{equation} A + B \geq b \Leftrightarrow A > (A+B)\; MOD\; b \end{equation}
The intuitive idea to demonstrate the right arrow is that, if we start to count from \(A\) for \(B\) times, as we reach \(b\), we have consumed at least 1 unit of \(B\), so \(B\) will be greater than \(Result\), and the same for \(A\), vice versa if A + B <b we move units from A to B without restart counting from 0, then result will be greater than both.
My intuitive idea for the left arrow is to think of digits as two buckets capable of contain b-1 water molecules, if you want to pour in the bth molecule into a digit, but the digit is full, you must empty the bucket, and the remaining molecule must be added to the bucket on his left. So with that metaphor, try to think what happens to bucket Result , which is initially empty, as you pour in A molecules + B molecules, since Result has not been emptied (because it can contain all the molecules in A and B) then the water level on Result is higher than the level on A and B.
Ok, let's give a rigorous proof for the right arrow, I will produce the left arrow demonstration if asked.
I start by showing the following equality
$A + B = A \color{gray}{+ (b - A)} + B \color{gray}{- (b - A)}$
As you may argue by just looking at the above expression the equality is true, now we'll reorder things a bit:
$ A + B = \color{gray}{A} + b \color{gray}{- A} + B - b + A$
$ A + B = b + B - b + A$
(2) \begin{equation} A + B = b + \color{gray}{B + A - b} \label{eq:aplusb} \end{equation}
Ok, (2) is exactly telling us that, when \( A + B > b \) then the result is 2 digit long, we can rewrite (2) to evidence its positional notation as
(3) \begin{equation}\label{positional1}
A + B = (1)\color{blue}{b^{1}} + \color{gray}{(B + A - b)}\color{blue}{b^{0}}
\end{equation}
Note that the gray part of (3) \(\color{gray}{B + A - b} \geq 0\), because the hypothesis was \(B + A \geq b\), but we also want it to be less than b, otherwise it will not fit into a single digit.
So we want \(\color{gray}{B + A - b}< b\) (in other words, we want \(\color{gray}{B + A - b}\) to fit into a single digit); let me show that \(0 \leq \color{gray}{B + A - b} < b\)
Let's again rewrite A and B as the difference on b
\begin{align} B = b-b+B = b-\color{gray}{(b-B)} = b - \color{gray}{i}\\ A = b-b+A = b-\color{gray}{(b-A)} = b - \color{gray}{j} \end{align}
so, after renaming (b - B) as i and (b - A) as j, we can say that
\begin{align} B = b - \color{gray}{i}\\ A = b - \color{gray}{j}\end{align}
that's correct, now the grayed part is a positive number (because both \(A\) and \(B\) are single digits, thus they live in the integer interval \([0, b-1]\)) ... in simple words \(0 < i \leq b\) and that \(0 < j \leq b\)
but we need also that \(i + j \leq b \), luckily that is true because
\begin{align} A + B \geq b\\ (b - i) + (b - j) \geq b\\ b - i \color{gray}{+b} - j \color{gray}{- b} \geq 0\\ b - i - j \geq 0\\ b \geq i + j\\i+j \leq b \end{align}
Ok, now the fact that all those three expressions are true \(0 < i \leq b\) and that \(0 < j \leq b\) and that \( i + j \leq b \) is equivalent to
(11) \begin{equation} 0 < i + j \leq b \end{equation}
By using (11), next we will show that
(12)\begin{equation} 0 \leq B + A - b < b \end{equation}
let's do it by substituting A and B with (b-j) and (b-i)
\begin{align} 0 \leq (b-i) + (b-j) - b < b \\ 0 \leq b - i \color{gray}{+ b}- j \color{gray}{- b}< b\\ 0 \leq -i + b - j < b\\ 0 \leq b - (i + j) < b \;\;(16) \end{align}
Being (11) true, then (16) is also true, and thus we unveiled that (12) is true
Ok, let's resume from the equation (3)
(3) \begin{equation} A + B = (1)\color{blue}{b^{1}} + \color{gray}{(B + A - b)}\color{blue}{b^{0}} \end{equation}
\(\color{gray}{(B + A - b)}\)is the least significant digit of \(A + B\), while \(1\) is the most significant: we'd relabel the most significant digit as \(carry\) (we also know its value is always \(1\) now), then we label \(\color{gray}{(B + A - b)}\) as \(Result\).
Originally, we wanted to show that \(Result\) is less than both \(A\) and \(B\), when the hypothesis stands true (the hypothesis were that \(A + B \geq b\)).
To proof thesis, it suffices to show that (17) \(B + A - b < A\) and that (18) \(B + A - b < B\), the method is the same, let's see the case (18) \(B + A - b < B\)
Since \(b > A\), by definition of a digit, we can then say that \(A - b < 0\)
So the expression (18) is true, because \(A - b < 0 \) quod erat demostrandum
Now we must show that (17) \(B + A - b < A\), just let me reorder it \(A + B - b < B\)
\(b - B\), by definition of a digit, we can then say that \(B - b < 0\)
So the expression (17) \(B + A - b < A\) is true, because \(B - b < 0\) quod erat demostrandum
History
- 2017: Started writing
- 4th February, 2019: Almost ready to publish
- 11th June, 2022: Published online

