Introduction
I’d like to show the experience of our command in implementation of integration testing in a commercial project. The integration testing is not a silver bullet; it has pros and cons. Plenty of details aren’t visible in the beginning of the project.
I hope this article will help those developers who is going to use the integration testing in their project, but don’t know the tasks they might face on that way.
Solution infrastructure
As an example infrastructure of a project I’d like to use a common example that covers the majority of solutions.
Solution architecture:
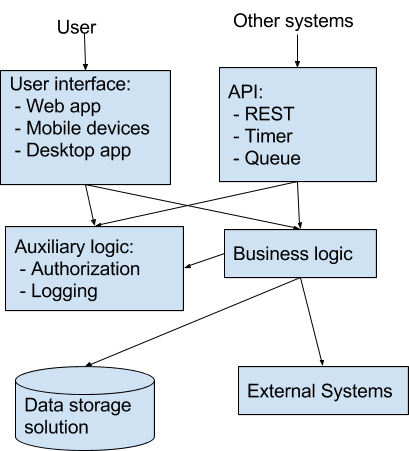
When it comes to testing, we have to check that calls from user interface and external systems are processed by our system as intended. Manual testing is easy for user interfaces. However if behaviour of our system depends on the calls to/from external systems, then the testing process becomes quite laborious. The main problem such system faces that case is retesting after changes in the solution. Such retesting takes the main part of the testing budget.
That case we have to contemplate using of the automatic testing. We can use unit and integration testing approaches.
Unit testing should be used when we develop a complex processing algorithm that is implemented in a simple module and has simple input and output which are easy to intercept in tests.
Here is the scheme of the testing infrastructure for a unit testing:

The blue rectangle shows the code from the solution. The yellow rectangles show the code that is created for the testing purposes.
Here, the upper yellow rectangle is a program code of test, for example, the code of a unit test. In common case it consists of the following parts:
- Container builder that builds the environment for the code to test. Usually the component that aren’t under test are replaced with stubs.
- Test data for the stubs. For example, various mocking frameworks are used to specify the behaviour of the stubs to simulate a desired scenario.
- Test data for the code under test.
- Expected result - the data to compare the actual result with. The actual result it is not only the direct response of the code to test but it might be some data sent by the code to the stubs.
- Code of the test that specifies the behaviour of the test. We can call various methods during the test. Sometimes the sequence of that calls is not simple.
Below I’ll show how Gherkin language can assist you in implementation of this yellow rectangle.
The second yellow rectangle is stubs for the components which aren’t under test now. Nonetheless, you have to spend you time to create those stubs. What is more a new test might require new stubs. So, don’t forget about this “item of expenditure” in your project.
I’d like to mention that unit testing does not ensure that different units correctly implements a same interface. Rough example: first module might send the null value to second module whereas the second module doesn’t consider the null value as correct input.
The problem is that one of the developers wrongly implemented the interface requirements. The unit tests also implemented wrongly. Hence, even though you project is 100% covered by unit tests, it does not not guarantee that you system works correctly.
I’d consider the unit tests as an auxiliary mechanism for a developer to implement an algorithm. I strongly believe that unit tests must not be used to ensure that the whole system works properly.
We need integrational testing to be sure that the system meets all of its requirements.
Testing infrastructure for integration testing:
The blue rectangle shows the code from the solution. The yellow rectangles show the code that is created for the testing purposes. Below I’ll explain this infrastructure in details. However, before we continue, ...
Be Prepared
When you just start development of your system, you should keep in mind that your solution will be a part of integration testing infrastructure. In other words in the beginning of your project you have to decide that some components of your system will be replaced with stubs. Remember, code of a component that is replaced with a stub won’t be automatically tested. You should design that that code as simple as possible. If it is just mapping without conditional and cyclic operators, then it is perfect. That case simple manual testing will be enough to check that such a mapping works correctly. If such code does not have conditional operators then one test case will check the entire code.
Let me show you an example.
A system has to send emails. Below is the part of the component diagram.
In the production configuration the system logic sends emails to users using the standart SmtpClient (https://msdn.microsoft.com/en-us/library/system.net.mail.smtpclient(v=vs.110).aspx) class. The SMTP server here is an external system.
What should be done to make this configuration automatically testable?
First approach is to replace the SMTP server with a stub. The Artezio Fake SMTP server (https://fakesmtp.codeplex.com/), for example. To be honest, it can’t used for automatic testing because it does not’ have an API. However, it provides nice user interface for manual testing.
This stub should support SMTP protocol and provide a managing API to configure the internal state before the test and check it after the test. Don’t forget that this stub has to be hosted some way in the testing infrastructure.
Second approach is to replace the SmtpClient component with a stub component.
This way you don’t have to think about hosting of the Stub due to it is a stub class that replaces the production class in the testing configuration. You also don't’ have to implement the support of the SMTP protocol.
However, the disadvantage of this approach is that the SmtpClient is not automatically tested.
So, in the beginning of the system development you have to design this component as simple as possible. As I said before, the simple component can be tested manually and doesn’t require automatic testing.
Stubs for auxiliary logic
Don’t forget about authorization. You should use a solution that can emulate any user permission on the testing stand. I’d recommend using of the OAuth standard.
And keep in mind that your user interface will be used by a robot. The UI must have some hooks that make it easily for using by robots. For example, use the IDs of the HTML elements in your Web application. These IDs help the robot to find a necessary element on the web page.
Details of testing infrastructure
Fixtures and testing code
The fixtures and code are the crucial nexus of the testing infrastructure. They have to
- Store the test data that will be used in stubs and as an argument of the main algorithm.
- Specify the sequence of the steps for the test. Note that the every step might have the test data as its part (like a function has its arguments).
- Contain the expected data for the test run. Note, that it might be necessary to check not only the direct result of the algorithm. Sometimes we have to check the result data in the stubs or in the data storage. So, the testing has to have the access to data storage or stubs via managing API.
- Has an ability to wipe out the changes made during the test run.
Gherkin language
Here is the place where the Gherkin language shines. It implements the first 3 points of the list above. Its main advantage, in my opinion, is the visual feature. Looks at the texts of the two tests below. They implement the same check.
Implementation with SQL and C#
SQL: Preparation of the Devices table before a test
MERGE INTO [Devices] AS Target
USING (VALUES
(21 ,'76824e68','23sdf123f' ,'1111' ,'TRX9' )
) AS Source
ON (Target.[Id] = Source.[Id])
WHEN MATCHED THEN
UPDATE SET
[StrId] = Source.[StrId],
[SerialNumber] = Source.[SerialNumber],
[IMEI1] = Source.[IMEI1],
[ModelCode] = Source.[ModelCode],
WHEN NOT MATCHED BY TARGET THEN
INSERT([Id],[StrId],[SerialNumber],[ModelCode])
VALUES(Source.[Id],Source.[StrId],Source.[SerialNumber],Source.[IMEI1],Source.[ModelCode])
WHEN NOT MATCHED BY SOURCE THEN
DELETE
;
C#: Second part of the test - updating of the device and performing of the test.
[Test]
public async System.Threading.Tasks.Task CalculateTasksForDevice()
{
EnvironmentStub.UtcNowStub = new DateTime(2017, 06, 08, 0, 0, 0, DateTimeKind.Utc);
var delta = new Delta<DeviceDto>();
delta.TrySetPropertyValue("ModelCode", "beda13");
delta.TrySetPropertyValue("CarrierName", "Carrier1");
delta.TrySetPropertyValue("IMEI1", "1234567890");
delta.TrySetPropertyValue("Manufacturer", "United China");
delta.TrySetPropertyValue("SimOperator", "Carrier1");
delta.TrySetPropertyValue("Platform", (byte?)1);
delta.TrySetPropertyValue("APILevel", (byte?)7);
delta.TrySetPropertyValue("FirmwareVersion", "tz9_1.1.0.7");
var device = await deviceController.PatchDevice("76824e68", delta, 21);
var tfdController = new TasksForDeviceController(new TelemetryClient());
tfdController.InitializeDomainManagerForTest();
var tfdList = tfdController.GetAllTasksForDevices(21).ToList();
Assert.AreEqual(2, tfdList.Count(), "Exactlty two records are expected. Deleted records must be returned as well");
var expectedIds = new List<int> { 38, 39 };
CollectionAssert.AreEqual(expectedIds, tfdList.Select(a => a.TaskId).ToList(), "Expected task wasn't found");
}
This implementation is hard to read. Only the author of the code can easy understand it. For example, without comments it is impossible to understand that the “deviceController.PatchDevice” method is data preparation here and the “tfdController.GetAllTasksForDevices(21)” method is the code under testing.
Implementation with Gherkin
@DBSetup @DeviceContainer @MobServiceBDD.ComplexTaskGeneration
Scenario: Generation of tasks for device
Given following records were added into the "Devices" table
| Id | StrId | SerialNumber | ModelCode | APILevel | Platform | TestDevice |
| 1000 | 6ee0ab01 | 00001234567890 | VSTD | 6 | 1 | 0 |
And following records were added into the "Tasks" table
| Id | Deleted | ActionType | StartDate | FinishDate | ExecType |
| 1000 | 0 | 1 | 2017-01-01 | 2027-01-01 | 2 |
| 1001 | 1 | 1 | 2017-01-01 | 2027-01-01 | 2 |
When device updates its properties at "2017-06-09 23:45:34"
| Property | Value |
| IntId | 1000 |
| Id | 6ee0ab01 |
| ModelCode | beda13 |
| CarrierName | Carrier1 |
| IMEI1 | 1234567890 |
| Manufacturer | United China |
| SimOperator | Carrier2 |
| Platform | 1 |
| APILevel | 7 |
| FirmwareVersion | tz9_1.1.0.7 |
Then The device gets the following list of the tasks
| TaskId |
| 1000 |
As you see the Gherkin implementation is much more visual. It contains the steps of the test along with the test data. It is easy to distinguish the test preparation steps and the test steps.
Of course there is a C# code that interprets the strings of Gerkin tests. That C# code is hard to read. But that code is hidden and don’t hamper to understand the test.
What is more, the strings of Gherkin test are used in various test with different arguments - test data. For example, in our project a developer created one Gherkin test and filled it with an example test data. The developer also implemented the C# code for every Gherkin string. Then a tester made the copy/paste of this test and designed various test data. The testers made all they test scenarios run automatically. This way we got an assurance that our system works correctly after every build.
Let me summarise the advantages of the tests written in Gherkin:
- They are visual. It is easy to read the summary of an action and its arguments.
- They contains the steps along with the test data as use-cases do. So it is quite easy to create a Gherkin test that form a use-case from the analysis.
- They might be composed not only developers but by testers and analysts.
Interpretation of the Gherkin language
Let's look deeper under the hood of the Gherkin tests. Technically such tests do all the unit tests do - build the container, specify the stubs with test data, call the main methods in necessary sequence, confront the expected and actual results.
I’ll describe my SpecFlow using experience. You can find more information about the SpecFlow here: http://specflow.org/getting-started/ . It has implementation for Visual Studio.
Ghirkin strings and test context
The main approach of the SpecFlow is implementation of the every Gherkin string as a C# method. For example the following Gherkin string
And following records were added into the "Tasks" table
| Id | Deleted | ActionType | StartDate | FinishDate | ExecType |
| 1000 | 0 | 1 | 2017-01-01 | 2027-01-01 | 2 |
| 1001 | 1 | 1 | 2017-01-01 | 2027-01-01 | 2 |
Is implemented as the following C# implementation:
[Binding]
public class DatabaseSteps
{
public DeviceSteps(ScenarioContext scenarioContext) : base(scenarioContext)
{
}
protected int SomeValue
{
get { return (int)scenarioContext["DatabaseSteps_SomeValue"]; }
private set { scenarioContext["DatabaseSteps_SomeValue"] = value; }
}
[Given(@"following records were added into the ""(.*)"" table")]
public void GivenFollowingRecordsWereAddedIntoTheTable(string tableName, Table table)
{
TableSaver.ProcessQuery(tableName, table);
}
}
We will discuss the TableSaver.ProcessQuery() method later.
The main thing I want point to is that a Gherkin string is a method in a C# class. And there is a feature - the strings from one Gherkin scenario (test) might be implemented as methods in different C# classes. So, we have the context problem. The methods in different classes must have the access to the context of the current scenario.
SpeckFlow uses a simple solution - the scenario context is used as the constructor argument. Here is the place to store the necessary data. You see the simple implementation in the code example above. The SomeValue is stored in the context and can be accessed by the method of this class and its descendants.
So we have a place to store the common data, for example the dependency injection container.
We also use the context in the following situation. The algorithm under test takes a table as argument and returns a table result. It looks like we have to specify two tables for a Gherkin string. Unfortunately, Gherkin syntax allows specifying only one table per string. The work around is to specify the argument table in the first string and save the result in the context. The second string, that specifies the expected result table, just get the saved result from the context and compares it with the expected data.
Some tricks in implementation of the C# methods
First, the class hierarchy. SpecFlow doesn’t put any valuable restrictions to the classes that have the methods for the Gherkin strings. The only requirement is the Binding attribute for the class. As I found the SpecFlow test runner just creates the instances of every class with the Binding attribute and uses their methods for the Gherkin strings.
However, I recommend using the following approach.
- Create the class hierarchy. The root class comprises the properties and methods that can be used in all of the scenario implementation. For example, the root class has the container property. This way any class can register and resolve necessary classes in the container. It is also a good place for the methods that cleans the environment after each scenario.
- The child classes comprises the properties and methods that should be used for a particular Gherkin features.
Second, the blocks of a Gherkin test. For example every scenario has a Given, When and Then blocks. Using the attributes like “BeforeScenarioBlock” you can register methods that will be called in the beginning of the every block.
That is a proper place to build the dependency injection container.
For example, Gherkin strings in the Given block just register mocked instances in the container. When it come to the When block, you build the container in first turn and then the main algorithm resolves the mocked instances from the built container.
If we are talking about integration testing then we have to put the real implementation of necessary classes into the container. In my case I put the real DAL classes into the container. This way the algorithm under test had access to the real database that had data prepared in the Given block of the test.
Here is the example of the building of the container in the beginning of the first When block:
[BeforeScenarioBlock(Order = 0)]
private void BuildContainer()
{
if (ScenarioContext.Current.CurrentScenarioBlock == ScenarioBlock.When)
{
if (InitializationComplete != true)
{
Mock.ReplayAll();
Container = Builder.Build();
InitializationComplete = true;
}
}
}
Third, the Scenario tags. In the example of the Gherkin test above you can see the following tags:
@DBSetup @DeviceContainer @MobServiceBDD.ComplexTaskGeneration
First tag - @DBSetup - specifies that test uses the data base that should be prepared before test and cleaned after test. I’d like to mention that we are talking about integrational test. So, we use a testing stand that uses a real SQL database and we need a way to revert the DB after each test.
We have the following methods in the root class to implement it:
[BeforeScenario("DBSetup")]
private void DBSetup()
{
DbSetup.DbBackup();
}
[AfterScenario("DBSetup")]
private void DBCleanUp()
{
DbSetup.DbRestore();
}
See the details of the implementation in the “Data storage solution” topic below.
The second tag - @DeviceContainer - specifies that the test requires some classes related to the Device entity in the injection container which are required in this scenario. WeI have the following method in a child class:
[BeforeScenario("DeviceContainer")]
private void ContainerSetupForDeviceTests()
{
Builder.RegisterType<DeviceController>();
}
The third tag - @MobServiceBDD.ComplexTaskGeneration - used for the test explorer in the Visual Studio. SpecFlow adds all of the tags as a test category attribute:
[TestCategory ("MobServiceBDD.ComplexTaskGeneration")]
This way we mark all of the necessary scenarios into a one group.
Calling of main algorithm and comparing of results
In the test example above, the main algorithm consists of two methods: update some device and get the tasks for this device. You can see the two strings in the Gherkin test above: “When device updates its properties...” and “Then The device gets the following list of the tasks...”
When I implemented the first string I just called a corresponding method in the DeviceController. The second string gets the result from other method of the controller.
This way I implemented the integration tests of the WebAPI. However, the Web UI can be tested too. That case we have to get access to the UI from the C# methods. A possible solution is to use the Selenium project. This way the Gherkin string could be like “User specifies ‘User1’ and ‘Pass1’ on the login form and press the Login button”. The corresponding C# method calls the Selenium driver to get access to the control elements on the Web page.
I strongly believe that there are such ways for desktop applications.
Stubs of external systems
When you are just starting the development of your system, you should think how to test the interaction with third party systems. On the one hand, it is possible to use a second instance of the third party system. However this solution leaks important features:
- It is not quite easy to setup the system into a desired state before each test. It is also hard to wipe out changes after each test
- Usually there is no managing API to check the internal state of the third party system. In other words you can’t get the detailed log of call to that system to check that your system made correct calls during the interaction.
I already described the solutions for the stubs of the external systems in the “Be prepared...” paragraph above.
Data storage
The same requirements should be applied to your data storage. I’m going to describe the solution we used for the MS SQL server. I don’t have a recipe for various noSQL databases.
For the testing purposes we uses a dedicated instance of the MSSQL server. It might be a part of a testing stand or an instance on the developer’s machine.
Setup before test
We used two steps to fill the DB with data before tests.
First, TestData scripts in the Database project. Of course we used the Visual Studio Database Project to store the DDL statements for database. The database project has such a remarkable feature as PostDeployment Scripts. That is the place where we put the first bunch of data into DB.
We created a TestSet parameter in the publish profile of our DB project (see more about Variables for Database Projects). For the each test stand we creates a publish.xml file that sets the TestSet variable to a name of a test set (See Vadim’s answer for example of the variable usage). The post deployment script checked the value of a TestSet publishing parameter and executed the merge scripts for all of the tables included into the test set. Hence the test set is a set of SQL scripts. Each script fills one table with fixed set of data. You can see the example of the merge script in the “Implementation with SQL and C#” paragraph above. Notice, the PreDeployment scripts clears the data from all of the tables in DB.
We used the merge script generator to create such scripts. After a developer manually filled a necessary table with data, he or she extracted the data into the merge script and added it into the database project.
This is also a good solution to fill a new stand with some data. For example, testers usually want to get a test stand that already has some correctly specified data. Using this approach we can easily deploy a test set to a stand.
What is more, the integration tests can use this data and skip the phase of the data initialization. Nonetheless, if a test requires some additional data we have an easy solution:
Tables in Gherkin tests can be used to add necessary data to tables.
See the example of the “following records were added into the ‘Devices’ table” string in the Gherkin test above. We created a special TableSaver class (see the source code in the attachment) that inserts the values from the SpecFlow Table class into the SQL table. The main feature of this table saver that it doesn’t requires that all of the table columns are specified in the Gherkin table. The table saver read the list of the table columns from the DB and generates values for every column. In first turn it uses values from the Gherkin table. If a column is not specified in the Gherkin table, then table saver tries to use the null value. If column is not nullable, the table saver uses default value, for instance, 0 for int column, empty string for varchar column.
Notice, table saver has one issue now. It can’t insert the empty string into nullable varchar column. The empty value from Gherkin table is converted into null value.
This approach allow making of the Gherkin test as visual as possible. There is no data for the columns that aren’t necessary for a particular test.
Wiping out after test
The restoring of a system after test is a necessary task in integration testing.
As I mentioned above, the stubs of the external system must have a managing API to setup the initial data. It is obvious that this API should allow restoring of the internal state of the stub after each test.
We developed a simple DBSetup class (see the source code in the attachment) that restores the SQL database after a test (see the source code in the attachment). It uses the snapshot backups. See here how to create a database snapshot that and how to restore a database from a snapshot.
The main advantage of the database snapshots is that it is the fastest mechanism for database backup/restore. For example, average test time is 7 seconds on our test stand. This time comprises Db backup/restore time.
The database snapshots are available in the MSSQL developer edition and in the MSSQL 2017 sp3 express edition. Both editions are free for development.
At the moment I can’t advise you an instrument for other data storage systems like Azure storage or DocumentDB.
Cost of integration tests
Above I mentioned a lot that integrational testing requires creating of additional components. Here I’d like to list them in one place.
This picture shows the components of testing infrastructure in yellow rectangles.
Before we start talking about yellow rectangle it is necessary to mention that a dedicated stand is necessary for integration testing. In addition to the testing stand, it is necessary to configure new jobs in your continuous integration server. This is DevOps’ expenses for integration testing.
First yellow rectangle in the picture above is a test project. It includes:
- MSTest or nUnit test project (actually it might be any testing framework you prefer). The testing report feature of these frameworks is quite helpful thing.
- Gherkin tests that defines behavior, test data and expected results.
- SpecFlow components to support Gherkin tests.
- Additional API to call your components under test. If your system has only API methods you can call them directly from tests, for example, call the controllers of the WebAPI. However, if your system has UI then you have to write some API to programmatically interact with UI. The Selenium project is an example for a Web application.
- Managing API for your data storages. It is a backdoor into the storages that allows initialise the storage with data before test; check data in storage after test; wipe out data after test.
- Managing API for the stubs of external system. For example, if you implemented a stub for external system as a separate service with REST interface (that includes the managing API for the stub), then you have to create some C# proxy classes in the test project to interact with managing API of the stub via REST interface.
Second yellow rectangle is auxiliary logic that should be replaced during tests. It is necessary to test your system using all of the existing roles. Hence, you need a way to replace the standard authentication system with a stub that provides necessary roles.
What about logging system, it is would be perfect if all of your logs for every tests are gathered in the test report.
The third yellow rectangle is stubs of external system. The development of stubs for external systems must be included into to your development process. They also have to be built on a continuous integration server and deployed to the test stand.
Conclusion
The integration tests is a powerful tool to ensure the quality of your system. However, with great power comes great responsibility. You have to design and implement the components of the integration testing system as thoroughly as the main system. Otherwise, it will become a useless budget eater.

