Why?
Relational databases are still the most popular store for most applications. They have several advantages including good tool support, long history of performance tuning, guarding data quality by enforcing data structure, data types, consistency and referential integrity, encouraging normalization, transactional behavior,… and lots of developers are acquainted with them.
Document databases (storing XML or JSON documents raw or in binary) have usually much more relaxed schema validation. And though they usually support validation, indexing and transformation, and sometimes store documents as binary graphs, they can be looked at as (B)LOB stores where you can ‘dump’ documents without caring about the structure of the database itself (though this comparison is an insult to the better document databases, sorry).
While I am still a strong adherent of relational databases for their strict structure and consistency, there are times when I also love the flexibility of a document database in which I do not need to create a new table for every multivalued property and define and maintain complex table structures and relations for data that has a complex structure but has no other relations than being aggregate of an owner object.
Take for instance, a ‘Product’. Defining a product in a relational database means creating a table Product with for instance columns Id, Name, Price. I can now register orders in an Order table and have order lines reference products by their Id. I can then easily query which customer has bought products between a given price range in the last 2 weeks.
In a document database, storing customers, products and orders is even easier: they’re just documents. But “cross-document” queries and joins are often tougher matter.
So for a classical ordering system, I’d still stick to a relational database. However, the product may have a lot more properties used to document it (in the web shop, for instance): its specifications (color, size, power,…), user reviews, etc., for which a document format is better suited. Modeling these out in a relational database would result in a huge ERD with lots of tiny tables hiding the core concepts and relations of the model.
So here comes the hybrid model: let’s store relational data in a relational database and add ‘document’ structures to it for the document oriented data. Best of both worlds!
How It Works?
Pretty easy: To all database tables you want to apply hybrid storage, add a “JsonData NVARCHAR(MAX)” column. Then, when materializing objects with Entity Framework, use JSON.NET to read the JsonData and fill entity properties. Later, before saving changes, make sure the JsonData property of the entity is updated to reflect all changes.
The details with an example:
Take the following class diagram:
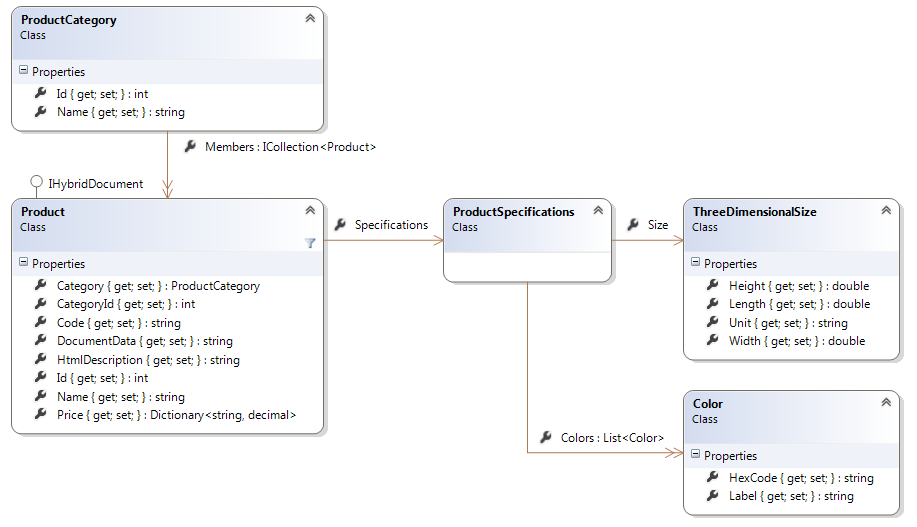
(Forget about the IHybridDocument interface and the DocumentData property for now.)
To map this to a relational database, we would need a database schema similar to this one:

There are “a lot of columns” in the Product table (well OK, it is still a tiny example but imagine the product specifications containing measurements of multiple parts, we’d need multiple Length, Height, Width and maybe Unit columns in the Product table; as specifications become more complex (i.e., also to support different kinds of product), we would need a lot more columns).
We also have a few extra tables and relations and here also: the more complex the product definition, the more tables and relations we get. This makes our database harder to manage and harder to maintain. And can make our ERD diagrams huge.
Maybe you need that complexity. Maybe these are the core entities you need to work with and your database should reflect this. Then it’s fine of course. But if the product’s price, size and colors are only details of importance for a very limited set of use cases, then the complexity of this schema is standing in the way for the other use cases and it could be better to get rid of it.
The solution? Add a JsonData column in the Product table, and put all product information you don’t need to be structured in the data model in there. That keeps your database schema lean & mean:
Now, declare your Product class to be a hybrid document by letting it implement the interface IHybridDocument. This interface includes a DocumentData property which you should map to the JsonData column in the database:
[Column("JsonData")]
public virtual string DocumentData { get; set; }
Then, mark all members that we want to be serialized in the JsonData column as [DataMember] to be serialized and as [NotMapped] by Entity Framework:
[NotMapped, DataMember]
[AllowHtml, UIHint("Html")]
public string HtmlDescription { get; set; }
[NotMapped, DataMember(EmitDefaultValue = false)]
public Dictionary<string, decimal> Price { get; set; }
[NotMapped, DataMember(EmitDefaultValue = false)]
public ProductSpecifications Specifications { get; set; }
In addition, I strongly advise to add a Json Extension Data field:
[JsonExtensionData]
private IDictionary<string, JToken> _additionalData;
This is the JSON.NET equivalent of IExtensibleDataObject (it’s a shame JSON.NET does not support IExtensibleObject but so it is, at least there’s an equivalent). This ensures that you will not lose parts of the JSON when roundtripping (loading, updating and saving back to database) a record using an entity class that misses one or more of the JSON mapped properties.
Next, I need to mark the Product class as a [DataContract]:
[DataContract]
public class Product : IHybridDocument
{
...
}
And finally, we need to mark the classes ProductSpecifications, ThreeDimensionalSize and Color as [DataContract]s and all of their properties as [DataMember]s. Consider adding the EmitDefaultValue = false property on the [DataMember] attributes if you want null/empty/0 values to be stripped from the JSON serialization.
For instance:
[DataContract]
public class ProductSpecifications
{
[DataMember(EmitDefaultValue = false)]
public List<Color> Colors { get; set; }
[DataMember(EmitDefaultValue = false)]
public ThreeDimensionalSize Size { get; set; }
}
So far however, this ain’t gonna do nothing. What we need is an additional touch of Magic!
In the constructor(s) of the DbContext subclass, add a call to the UseHybridStorage() extension method. This is the complete context class for our product catalog:
public class CatalogContext : DbContext
{
public CatalogContext()
: base()
{
this.UseHybridStorage();
}
public CatalogContext(string nameOrConnectionString)
: base(nameOrConnectionString)
{
this.UseHybridStorage();
}
public virtual DbSet<Product> Products { get; set; }
public virtual DbSet<ProductCategory> ProductCategories { get; set; }
}
And that’s it! Really!
So what’s the witchcraft behind it ?
The UseHybridStorage extension method enlists handlers to the ObjectMaterialized and SavingChanges events of the DbContext’s ObjectContext. Thanks to the ObjectMaterialized event, we can intercept when an object is materialized and deserialize the JSON data:
private static void OnObjectMaterialized(object sender, ObjectMaterializedEventArgs e)
{
var doc = e.Entity as IHybridDocument;
if (doc != null && doc.DocumentData != null)
{
JsonConvert.PopulateObject(doc.DocumentData, doc);
}
}
To the inverse, when an entity is about to be saved, we serialize the object and store the JSON string in the DocumentData property:
private static void OnSavingChanges(object sender, EventArgs e)
{
var context = new DbContext(sender as ObjectContext, false);
foreach (var entry in context.ChangeTracker.Entries())
{
if (entry.State == EntityState.Added || entry.State == EntityState.Modified)
{
var doc = entry.Entity as IHybridDocument;
if (doc != null)
{
var newDocData = JsonConvert.SerializeObject(doc);
if (!newDocData.Equals(doc.DocumentData)) doc.DocumentData = newDocData;
}
}
}
}
There is no more to it. It is all pretty straightforward, thanks to the power of JSON.NET and the use of DataContract/DataMember attributes.
But be aware there are also a few important issues.
Entity State Handling Issue
Note that the OnSavingChanges handler only looks at entities that have the Added or Modified state. Now, if I change the Name or the Code of a product, Entity Framework, when using proxies, detects those changes and marks the entity as Modified.
However, if we change a price or specification of the product, those properties being [NotMapped], Entity Framework does not change the state of the entity.
We could in the OnSavingChanges handle ALL entities, also those that are not Added or Modified, and this would solve the problem. We would change the DocumentData property if the JSON serialized form has changed, and since DocumentData is a mapped property, this would set the state to Modified.
But the risks of creating a performance monster is huge! It would mean we would serialize to JSON all entities loaded in the context just to see if maybe one of them has changed. Serialization is a costly process. The impact can be huge.
Therefore, if we want changes to JSON mapped properties to be saved, we need to mark the entity as ‘changed’ explicitly. To ease that, I have added an Update extension method to DbContext that allows to mark an entity as modified. Here is a simplified version of the code:
public static void Update(this DbContext context, object entity)
{
if (context.Entry(entity).State != EntityState.Added)
{
context.Entry(entity).State = EntityState.Modified;
}
}
This way, we can now easily change a price with the following code:
using (var context = new SampleContext())
{
var prod = context.Products.Find(3);
prod.Price["USD"] = 1999.95m;
context.Update(prod);
context.SaveChanges();
}
The JsonData column could now contain for instance (here indented for readability):
{
"HtmlDescription": "<p>Great product!</p>",
"Price": {
"EUR": 1699.95,
"USD": 1999.95
},
"Specifications": {
"Colors": [
{
"HexCode": "FF0000",
"Label": "Red"
},
{
"HexCode": "00FF00",
"Label": "Green"
},
{
"HexCode": "0000FF",
"Label": "Blue"
}
],
"Size": {
"Unit": "inch",
"Length": 6.0,
"Height": 8.0,
"Width": 12.0
}
}
}
Thanks to the native JSON support in SQL Server 2016, you could also query products by JSON serialized properties using SQL as in:
SELECT Id, Code, Name, CAST(JSON_VALUE(JsonData, '$.Specifications.Size.Length') AS float) AS Length
FROM Products
WHERE CAST(JSON_VALUE(JsonData, '$.Price.USD') AS decimal(18,4)) > 1000
For more, see for instance:
https://msdn.microsoft.com/en-us/magazine/mt797647.aspx
Linq Querying Issue
There’s another important limitation. Remember in Entity Framework you cannot query entities by properties that are not mapped. Though you can in SQL, as the above example shows, query product by one of its prices, you cannot do so in Linq to Entities !
You could probably work around this by adding a computed column in the Product table, if desired, add an index on it, then map that column to an additional property on your entity which you can then use in Linq query expressions. But then you end up with two entity properties for the same value…
Or you could create a database view (that does not necessarily expose the JsonData but) that does expose computed columns and use a separate Product entity class mapped to that view to perform the querying.
Redundant Storage
So let’s recap. As usual with Entity Framework, to have an entity property stored as regular column value, simply define the property. Add a [Column] attribute to it if you want to override the default mapping or mapping properties. Or define your mapping in OnModelCreating.
To have an entity property stored as a JSON value, disable its regular mapping with a [NotMapped] attribute, and enable serialization to JSON with a [DataMember] attribute.
You could choose to add a [DataMember] attribute to a property, without adding a [NotMapped] property. The result would be the value to be stored both in a database column and in the JSON serialization.
This can come in handy if you want to easily access the value from within SQL, but have the JSON be more self-contained knowing about its records Id, Name, Code, etc. (according to our product example). This would allow you to use only the JSON form in some situations and can come in handy.
I would not discourage this practice, but be aware that whenever this entity is loaded, the OnObjectMaterialized event will overwrite the database mapped values with the JSON serialized ones. JSON will take precedence. For instance, if you map the Name property to both a column and JSON, an update of the column value in the database only, will be undone the next time you load the row using Entity Framework and call SaveChanges.
Also, I haven’t tried it out, but I think you will get in serious trouble if you map the autogenerated Id both in database (as the primary key) and in JSON (to have self-contained JSON). The thing is, when you create a new entity, it’s Id = 0. When it is saved, it’s Id is still 0 and 0 gets serialized in JSON. Once saved, the Id is determined. But since the JSON contains the value 0 and since JSON takes precedence, every time you try to load the entity, its Id tends to change back into 0…
This problem too has a solution (https://stackoverflow.com/questions/31731320/serialize-property-but-do-not-deserialize-property-in-json-net) but it makes the whole more complex again.
Performance
Obviously, in situations where you only need the Id and Name of a product, dragging the whole JSON string over the network and deserializing it will incur a performance overhead.
On the other hand, in situations where you do need all or most of the product data, loading a single record will be faster than eager loading and/or lazy loading the whole database graph.
Therefore, the performance impact will depend on which properties you choose to serialize as JSON, how often you can gain performance by not having to load related database rows and how large the JSON string can get.
My advise here is to carefully craft your entity, choosing which properties to map to columns, and which ones to JSON. Take into account the performance impact as well as the Linq querying limitations I described in the previous point.
Then, if desired, add one or more views. For instance, add a view that lists only Id, Name and Code of the product. With this view, you will be able to load products without the overhead of deserializing the JSON string on each row. As this view would be updatable, it could very well become your main Product entity while the real table would be mapped to a ProductWithDetails entity used only to manage the product details and specifications.
Why JSON?
In my first implementation, in 2015, I had chosen XML. XML is a more complete and mature format with powerful features as schemas (and the ability to mix multiple schemas in a document such that for instance an object can have two properties with the same name without interference) and declarative transformations.
More important: since SQL Server version 2012, there’s a pretty good native support of XML by the database. Choosing XML ensured me that I could still retrieve individual values using SQL queries (I was not locking me in into only being able to retrieve individual values by using my .NET entities).
Since the hybrid storage concept means we must be able to serialize only some properties (those that are not already mapped to a separate column) to XML, my only option seemed to be the DataContractSerializer, where properties to be serialized can be marked as [DataMember]s.
But the serialization creates ‘complex’ XML with different schemas, and though schemas are a cool and a powerful feature, I don’t really need them here. They make my XML overly complex, superfluously large and hard to query. And I would not really be able to have two properties with the same name (but different schema) anyway because I don’t really have control of the schemas.
Also, the deserialization could not be done on the entity directly, when deserializing I get another object and I needed to copy the datamember properties to the real entity. This required quite some code lines involving reflection (and caching).
So though XML is a powerful format, and I would probably choose XML over JSON when focusing on a real document oriented solution, in this case, I cannot monetize its power and I only get the inconveniences.
I was therefore thrilled to find out that SQL Server 2016 introduced native support for JSON:
I can now choose for the simpler JSON format without fear of being locked in. And both serialization and deserialization work (using [DataMember]) as a charm!
It is also nice that you can start right away, with any version of SQL Server as even SQL Server 2016 stores JSON in a mere NVARCHAR(MAX) field. So this solution works with any SQL Server version, only, to be able to do SQL queries involving individual fields of the JSON data, you will need the 2016 version (or find an alternative solution).
What About .NET Core?
To be able to do the same with EF Core, we need equivalents to the ObjectMaterialized and SavingChanges events. As far as I can see today, this feature did not make it in .NET 2.0 and is scheduled for .NET 2.1 (if it makes it):
You could probably find a way to do it with EF Core today, i.e., by handling stuff in the set accessors of DocumentData and the JSON mapped properties, but you won’t then be able to use automatic properties.
I found this great overview of what is already supported by EF Core and what isn’t:
The Code
You find the code including a simple console based example here:
I have also integrated this hybrid storage feature in my “common” class library that can be found on:
You will find my latest version of the Hybrid Store in the Arebis.Data.Entity library. You can also obtain this component as a Nuget from:

